Hilt는 제가 처음으로 접한 의존성 주입 라이브러리 입니다.
[Solid 원칙 ~ Hilt 연관성 ~ 클린아키텍처(구글권장과 반대개념)]
아래에서 설명하는 내용은 클린아키텍처 관점에서 인터페이스와 인퍼페이스 구현체를 활용하여 코드 플로우를 결정하는데 해당 관점에 대한 설명입니다.
시작
-
정리
객체간의 의존성을 외부에서 주입해줌으로서 코드간의 결합도는 낮추고 확장성은 높여주기 때문에 SOLID 개념을 코드에 효과적으로 녹아내리게 할 수 있습니다. 또한 인터페이스의 구현체를 통한 주입이 아니라 인터페이스를 통해 의존성을 주입하므로 기존의 코드 수정 없이 새로운 의존성을 주입 할 수 있게 도와줍니다.
-
SRP 단일 책임 원칙
각각의 클래스가 자신의 필드에서 의존성을 직접적으로 생성하는 대시에 , 필요한 의존성을 외부에서 주입받아 사용하므로 하나의 책임에 주입할 수 있습니다.
-
OCP 개방-폐쇄 원칙
Hilt를 사용하여 의존성을 주입하기 때문에 코드의 확장성은 높이고 변경(수정)은 닫혀있습니다. 이는 새로운 기능이 추가 될 때 기존의 코드(의존성 주입과 관련된 코드)는 유지 한채로 새로운 의존성만 주입받아서 사용 할 수 있다는 의미입니다.
-
LSP 리스코프 치환 원칙
구현재를 통해 주입하는 것이 아니라 인터페이스를 통해 의존성을 주입하기 때문에 하위 클래스(Interface)가 상위 클래스(Imterface Impl)를 대체하여도 의존성 주입이 가능하다.
-
ISP 인터페에스 분리 원칙
클래스가 자신이 사용하는 인터페이스를 직접구현하는 것이 아니라 구현체에 대한 의존성을 주입받아 사용합니다. 이를 통해 의존성을 주입받는 클래스가 구현체에 직접적으로 의존하지 않게 됩니다.
-
DIP 의존성 역전 원칙
상위 개층과 하위계층간에 인터페이스를 넣어 1 > 3의 관계에서 1 > 2 < 3의 관계로 의존성을 역전 시킬 수 있다. 이는 Hilt를 사용하여 의존성을 주입할 때는 추상화를 사용 하기 때문이다. (아래 코드 참고)
@Provides
fun provideGetStringRepository(impl : GetThingOnRepositoryImpl) : GetThingOnRepository = impl
// GetThingOnRepositoryImpl 객체를 GetThingOnRepository 타입으로 반환한다. 따라서 UseCase에서 GetThingOnRepository를
// 주입 받을 때 GetThingOnRepositoryImpl 객체를 사용 할 수 있는거야.의존성 주입의 의미
일단 Hilt , Koin , Dagger2 이런 것들을 의존성 라이브러리라고 하는데 의존성을 주입한다는 것이 어떠한 의미일까요 ?
제가 생각하는 의존성이란 객체를 생성하는 것 이라고 생각합니다.
일단 임의의 대장 클래스가 있다고 가정했을 때 외부에서 대장 클래스를 사용하기 위해서는 대장 클래스의 객체를 생성하여야 합니다.
이때 외부 클래스를 부하 클래스라고 가정하면 부하 클래스에서 대장 클래스의 객체를 생성하여 코드를 작성하는 것을 "의존성을 수동으로 주입하였다"라고 합니다.
즉, "대장 클래스를 사용하기 위해 대장 클래스의 분신인 객체를 생성하는 것을 의존성을 수동으로 주입하였다" 라는 의미입니다.
이때 객체를 생성하는 방식에는 첫째 : 파라미터를 통해서 생성 , 둘째 : 함수를 사용해서 생성 이런 두가지 방식이 있습니다.
class 떄짱() {
}
// 파라미터를 통한 의존성 수동 주입
class 부하(private val 대장 : 떄짱) {
또는
private lateinit var 대장 : 떄짱
fun 의존성 수동주입(대장 : 떄짱) {
this.대장 = 대장
}
}
위와 같은식으로 의존성을 주입하면 일단 , 동일한 코드를 반복적으로 사용해야 하는(보일러플레이트)문제점이 있고 , 협업을 진행할 때 개발자들마다 다른 방식의 의존성 관리가 진행된다는 단점이 존재하게 됩니다.
HILT를 공부하게 되면서 저는 의존성이라는 것에 대한 개념이 너무 헷갈렸습니다. 따라서 그냥 쉽게 임의의 클래스를 사용하기 위해서 객체를 생성 할 때 이루어지는 일련의 과정을 의존성 주입이라고 생각하였습니다.
이러한 개념을 잡고 HILT에 대해서 학습하기 시작하니 조금 더 이해하기가 쉬었습니다.
그렇다면 Hilt를 사용하는 이유가 이러한 의존성주입을 자동으로 관리해주기 때문에 사용하고 싶을때 마다 객체를 생성할 필요가 없다는 장점이 있을텐데 Hilt가 도대체 무엇이길래 라는 궁금증도 들었습니다.
Hilt 설정
우선 Hilt를 사용하기 위해서는 다음과 같은 과정들이 필요합니다.
(링크 참조 : https://velog.io/@antking/%E3%85%87%E3%85%87-37nnbxx8)
제가 생각하는 Hilt를 잘 다루는 사람은 특정 어노테이션이 있을 때 Hilt가 어노테이션에 따라 어떠한 작업을 실행하는지 아는 사람이라고 생각하기 때문에 Hilt의 어노테이션을 중심으로 Hilt에 대해서 설명하도록 하겠습니다.
(참고)
Hilt가 의존성을 주입해주니 사용자가 느끼기에는 자동으로 주입한다고 느끼는데 밑에 부터 작성된 "의존성 주입"이라는 단어는 Hilt가 의존성을 주입해줍니다. 라는 의미입니다.
(참고)
1. @HiltAndroidApp를 Application에 선언해주는 이유
일단 Hilt는 컴파일이 실행되는 동안에 의존성 주입을 설정합니다.
Hilt에는 여러 어노테이션들이 있는데 해당 어노테이션을 활용하여 의존성 주입을 진행하는데 필요한 여러 코드들을 Hilt 스스로 작성합니다.
(참고)
이러한 과정들을 의존성 주입 그래프 생성 및 관리라고 부르기도 합니다.
제가 구글링하면서 제일 헷갈렸던 부분...
(참고)
위에서 생성된 코드들을 사용하여 실제로 의존성이 주입되는 과정은 앱이 최초 실행 될때 와 앱이 실행되는 동안에 발생합니다.
즉 , Hilt가 의존성을 주입하기 위한 준비과정은 컴파일 단계에서 발생하고 , 실제로 의존성을 주입하는 과정은 어노테이션(아래 나옴)에 따라 앱의 최초 실행부터 필요에 따라 반복적으로 발생합니다.
따라서 컴파일 타임에 Hilt가 의존성 설정이 올바르지 않을 때 컴파일 할 때 에러를 발견할 수 있게 해줍니다.
2. @AndroidEntryPoint란 무엇일까 ?
우선 Hilt를 사용 할 수 있는 안드로이드 구성요소는 다음과 같습니다.
즉, Hilt를 통한 자동 의존성 주입이 가능한 클래스들에 대한 종류를 의미합니다.
[ Activity , Fragment , View , Service , BroadcastReceiver ]
(참고 : ViewModel의 경우 @HiltViewModel 어노테이션을 사용합니다.)
(참고 : @HiltViewModel을 사용함으로서 Hilt가 ViewModel에도 의존성을 주입 할 수 있게 됩니다. 이때 @Inject 어노테이션을 사용하게 되는데 설명은 아래에 있습니다.)
(참고 : 만약 @HiltViewModel이 작성된 ViewModel을 불러오려면 hiltViewModel()을 꼭 작성해줘야 합니다)
위의 클래스들에 @AndroidEntryPoint를 작성하게 되면 , 의존성 주입의 시작점을 Hilt에게 알려주는 역할을 하며 , 해당 클래스에 필요한 의존성 주입을 Hilt가 하게 해준다.. 그러나 최초의 시작점은 @HiltAndroidApp을 작성한 Application() 에서 시작되는 것이다.
(리팩토링 과정 발생한 에러)
리팩토링 과정중에 @AndroidEntryPoint를 Fragment에 작성하였는데도 에러가 발생하였다. 구글링을 해보니 androidx의 fragment를 사용해야만 Hilt를 사용 할 수 있다는 사실을 발견하
(리팩토링 과정 발생한 에러)
다시 @AndroidEntryPoint로 돌아오겠습니다.
@AndroidEntryPint가 해당 클래스에서 Hilt를 사용하기 위한 진입점으로 사용된다고 말씀드렸는데요. 부가적으로 설명을 드리자면은 @AndroidEntryPoint가 마킹된 클래스에 알맞는 "DI Container"라는 것을 Hilt가 생성하는데요 바로 이 DI Container가 실제로 "의존성 관리 및 주입 및 객체의 생성 및 해당 클래스의 생명주기 관리"를 합니다.
@AndroidEntryPoint가 마킹된 클래스의 생명주기에 따라서 의존성을 주입하기도 하고 제거하기도 합니다. 예를 들면은 만약에 Activity에 마킹되었다면 Activity가 생성될 때 의존성을 주입하고 , 파괴된다면 의존성 주입을 하지 않는 다는 것을 의미합니다.
또한 @AndroidEntryPoint가 마킹된 클래스에서 Hilt는 계층적으로 구성되기 때문에 만약 상위 클래스에 @AndroidEntryPoint가 적용되어 있으면 하위 클래스에서도 상위 컴포넌트가 가지고 있는 의존성에 접근해서 사용 할 수 있습니다. (주의!!!!!여기에서 의미하는 컴포넌트는 Andoroid Class를 의미하고 @Module에서 설명하는 Hilt 컴포넌트는 DI Container를 의미합니다.)
3. @Inject
@Inject 어노테이션을 마킹되었다는 것은 Hilt에가 "Hilt 사장님 저 의존성 주문했어요"라고 말하는 것과 같다.
쉽게 말하면 위에서 설명한 DI Container(@AndroidEntryPoint가 마킹된 클래스에 해당하는 실제 의존성 주입 과정을 실행하는 행동대장 형님 : Hilt의 오른팔 느낌이라고 생각하시면 됩니다. : Hilt Component를 의미합니다.)가 "으어~ 배달목록 확인 좀 해볼까~ 음.. 이 친구는 @Inject 인증마크가 없고.. 어헛 저 친구는 @Inject 인증마크가 있구나 기다려라 친구야 내가 의존성 가져다 줄게" 라는 느낌입니다.
즉, @AndoroidEntryPoint 또는 @HiltAndroidApp이 마킹된 클래스의 내부 또는 하위 컴포넌트에서만 @Inject를 사용 할 수 있습니다. (@Inject는 의존성 주입 받을 수 있는 증표이기 때문입니다.)
좀 더 딮하게 들어가면 @Inject가 사용되는 방식은 크게 두가지의 방식으로 나누어지게 됩니다.
첫째 , 필드 주입 (위에서 의존성 수동 주입을 설명 할 때 작성했던 메서도를 통한 주입을 생각하시면 편합니다.)
둘째 , 생성자 주입 (위에서 의존성 수동 주입을 설명 할 때 작성했던 생성자를 통한 의존성 주입을 생각하시면 편합니다.)
우선 필드 주입이라는 단어가 저는 생소했는데 여러분들도 생소하셨을 것이라고 생각합니다. 일단 필드를 그냥 쉽게 임의의 클래스의 {}의 내부를 필드라고 생각하시면 될 것 같습니다. 즉 , { 필드 } 라는 의미입니다.
(필드 주입 예시코드) : lateinit 키워드와 함께 사용되는데 , 이는 컴파일 단계에서 Hilt가 의존성 주입을 위한 코드를 작성하기 때문에 일단 해당 코드를 작성하고 , DI Container(HiltComponent)가 실제로 주입 하는 것은 런타임 (앱이 실행되기 시작할 때 또는 실행 중)이기 때문입니다.
@Inject
lateinit var workerFactory: HiltWorkerFactory
override val workManagerConfiguration: Configuration
get() = Configuration.Builder()
.setWorkerFactory(workerFactory)
.build()
(필드 주입 예시코드)
둘째 : 생성자 주입시 사용되는 @Inject입니다.
약간 이해하기 쉽게 규격화 해보자면 일단 A클래스가 B클래스에 대한 의존성을 주입받고 싶다면 A @Inject constructor(B) 라는 개념으로 생각하시면 됩니다.
즉 , 의존성 주입받을 친구 @Inject constructor(의존성 주입용 아바타 또는 분신) 이런식으로 생각하셔도 괜찮습니다.
이렇게 작성하게 된다면 "의존성 주입받을 친구"가 "의존성 주입용 아바타 또는 분신"을 "의존성 주입받을 친구"의 필드에서 맘껏 사용 할 수 있게 됩니다.
만약 Hilt 가 없었다면 수동으로 객체를 생성해서 만들어야 했겠죠..?
(생성자 주입 예시코드)
class ExcerciseGetAllUseCase @Inject constructor(
private val excerciseGetAllRepository : ExcerciseGetAllRepository
) {(생성자 주입 예시코드)
하지만 모두 다 @Inject를 사용한다고 의존성을 주입 받을 수 있는 것은 아닙니다. 생성자 주입 예시코드를 보시면 ~~Repository를 주입받고 있는데 해당 Repository는 interface입니다. 이러한 interface를 주입받을 때에는 @Module이 마킹된 클래스가 필요합니다.
4. @Module @InstallIn "DiContainer"
@Module은 단순히 @Inject를 사용하였다고 의존성 주입의 대상이 될 수 없는 특별한 친구들에게 의존성 주입의 대상이 될 수 있도록 도와주는 착한 친구입니다.
@Module이 마킹된 클래스를 사용해야만 의존성 주입의 대상이 되는 친구들은 다음과 같습니다.
[ interface , 외부 라이브러리(Retrofit) , 빌더패턴이 있는 경우(RoomDB) , 외부 SDK (파이어베이스)] 의 경우에는 해당 의존성을 주입하기 위해서는 @Module의 필드 내부에 의존성을 제공하는 메서드를 정의하여 사용해야 합니다.
이때 정의된 메서드를 DI Container가 활용하여 객체생성과 의존성 주입 작업을 진행합니다. 비유하자면 DI Container가 오지로 배달을 떠날 때 @Module이 마킹된 클래스가 제공된 함수로부터 도움을 받는다고 생각하시면 됩니다.
(헷갈림 방지)
DIContainer(HiltComponent)
둘다 같은 역할을 하지만 호칭만 다릅니다. 별명은 여러개 라는 노래 가사처럼 호칭만 다를 뿐 Hilt에서는 다양한 생명주기를 가지는 HiltComponent라는 DI Container를 생성하여 여러 종류의 AndroidClass의 생명주기에 맞춰서 의존성을 주입 및 관리합니다.
비유해보자면 , DI Container가 의존성을 주입 할 때에 자신의 생명주기를 알아야지만 치고 빠지고 할 수 있기 때문에(Hilt는 생명주기가 시작될때 주입하고 파괴될때 주입을 하지 않기 때문에) HiltComponet에 이러한 정보들을 @Module이 마킹된 클래스로 부터 얻어서 의존성을 관리합니다.
결론적으로 , @Module을 마킹한 후에는 해당 메서드가 어느 생명주기에 해당하는 DI Container(HiltComponent)인지 어노테이션을 통해서 마킹해주어야 합니다. 해당 어노테이션은 다음과 같습니다.
즉 , @Module이 마킹된 클래스는 HiltComponent에게 의존성 주입을 어떡해 하는지 아는 함수를 제공해주고 , @InstallIn(어떤 HiltComponent에게 해당 함수를 알려줄지 작성)을 활용하여 생명주기에 관한 정보도 제공해줍니다.
뭔가 위의 글이 뒤죽박죽인 것 같아서 예시코드와 함게 설명드리겠습니다.
(참고)
추상메서드의 경우 @Binds 어노테이션을 사용합니다.
(참고)
(@Module 예시코드)
@InstallIn(SingletonComponent::class)
@Module
object NetworkModule {
@Provides
fun provideProductApi() : ProductAPI
{
return Retrofit.Builder()
.baseUrl("https://api.jsonbin.io/v3/")
.addConverterFactory(GsonConverterFactory.create())
.build()
.create(ProductAPI::class.java)
}
}위의 코드는 Retrofit이 빌더 패턴이기 때문에 @Module을 활용하여 HiltComponent에게 ProductAPI 객체를 생성하여 의존성을 주입하는 메서드를 제공해줍니다.
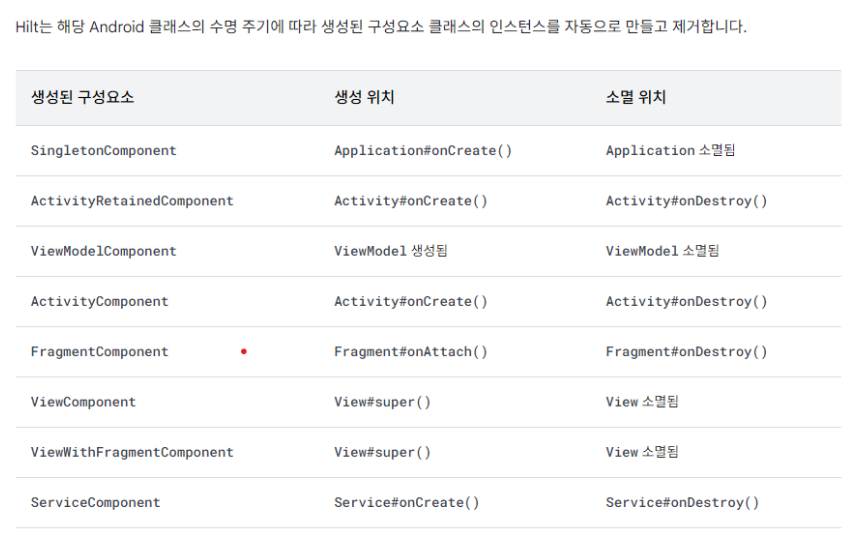
HiltComponent의 종류는 커스텀하지 않는 이상 아래와 같이 정해져있습니다.
[ SingletonComponent , ActivityRetainedComponent , ViewModelComponent , ActivityComponent , FragmentComponent , ViewComponent , ViewWithComponent , ViewEithFragmentComponent , ServiceComponent]
따라서 @InstallIn 어노테이션의 역할은 다음과 같습니다.
위의 HiltComponent의 종류중 하나를 파라미터로 받아서 해당 HiltComponent에 @Module이 마킹된 클래스에 정의된 "특정 객체를 생성하고 의존성을 주입하는 메서드"를 해당 HiltComponent에게 제공해줍니다.
그러면 해당 HiltComponent는 @Module 로부터 "특정한 객체를 생성하고 의존성을 주입하는 방법"에 대한 정보를 받았기 때문에 [ interface , 외부 라이브러리(Retrofit) , 빌더패턴이 있는 경우(RoomDB) , 외부 SDK (파이어베이스)]이러한 특별한 친구들에 대한 의존성을 @Inject("의존성 주입해줘야 할 대상이 지닌 증표)가 표시된 임의의 클래스에 제공합니다.
또한 , 각각의 HiltComponent는 고유의 생명주기를 나타내므로 해당 정보를 사용하여 HiltComponent는 적절한 치고 빠지기를 할 수 있습니다.
또한 , 메서드를 작성 할 때에는 @Provides를 마킹하여야 합니다.
아래 사진을 참고해서 보면 될 것 같습니다.
아래 사진은 공식문서에서 캡쳐한 사진으로 각각의 HiltComponent의 생명주기에 대해서 작성된 내용입니다.
(참고)
@Provides가 마킹된 메서드에는 "파라미터"와 "반환값타입" "반환값" 이 세종류가 있을텐데 해당 메서드의 의미는 다음과 같습니다.
--> 파라미터의 객체를 반환되는 값의 타입에서도 사용 할 수 있다.
--> 생성된 객체를 반환값의 타입으로 주입한다.
(예시코드)
@Provides
fun provideKakaoLoginRepository(impl: KakaoLoginRepositoryImpl) : KakaoLoginRepository = impl-> RepositoryImpl 객체를 Repository 타입으로 주입한다. 즉, Repository를 사용하는데서는 RepositoryImpl도 사용 할 수 있게 Hilt가 인스턴스를 제공해주는거야. 실제로는 KakaoLoginRepository가 사용되는 것이 아니라 KakaoLoginRepositoryImpl를 사용한다는 의미입니다.
(예시코드)
(참고)
(@Module 예시코드)
(헷갈림 방지)
5. HiltComponent의 Scope(범위)
또한 Scope라는 개념도 Hilt에는 존재합니다.
여기서 말하는 스코프는 코루틴 스쿱을 의미하는것은 아닙니다.
@Provides를 통해서 의존성을 주입할 때 생성하는 객체의 생성 범위를 의미합니다. 만약 Scope Annotation을 작성하지 않으면 의존성을 주입할 때마다 새로운 객체를 생성해서 제공합니다.
따라서 주로 ScopeAnnotation이 사용되는 이유는 "동일한 인스턴스를 반환하고 싶을 때(RoomDB) , 특정한 인스턴스를 공유하고 싶을 때(ImageCounter)"입니다.
아 다음은 ScopeAnnotaion의 종류와 역할에 대한 설명입니다.
@Singleton : 앱의 생명주기 동안 하나의 인스턴스 유지
--> 앱의 전체 생명주기에서 공유되는 의존성을 관리하기 위해서 사용합니다.
@ActivityScoped : 각각의 Activity의 생명주기동안 하나의 인스턴스 유지
-->특정 Activity에서만 공유되는 의존성을 관리하기 위해서 사용합니다.
@FragmentScoped : 각각의 Fragment 생명주기동안 하나의 인스턴스 유지
-->특정 Fragment에서 공유되는 의존성을 관리하기 위해서 사용합니다.
@ViewModelScoped : 각각의 ViewModel의 생명주기 동안 인스턴스를 유지합니다
--> 특정 ViewModel에서 공유되는 의존성을 관리하기 위해서 사용합니다.
@ServiceScoped : 각각의 Service 생명주기 동안 인스턴스를 유지합니다
--> 특정 Service에서 공유되는 의존성을 관리하기 위해서 사용합니다.
나만의 운동루틴에 힐트 적용기
-
우선 힐트를 사용하기 위한 설정들을 진행하였다.
-
현재 나만의 운동루틴에서 사용되는 RoomDB와 UseCase에 RepotisoryImpl을 주입하고 싶었따.
-
둘다 모듈에서 @provides를 마킹하여 의존성을 주입해주어야 하기 때문에(RoomDB : 빌더패턴 , RepositoryImpl : 인터페이스 구현체) 모듈을 만들어서 각각에 대한 객체를 생성하는 방법과 어느 HiltComponent에 어떠한 Scope로 설정할 것이지에 대한 정보를 대상 HiltComponent에게 전달하였습니다.
