1) 다중 블록 스토리지를 이용한 RAID 구성
1-1. 추가 블록 스토리지 생성 및 연결

NHN Cloud 웹 콘솔에서 블록 스토리지 3개를 추가로 생성한 후 동일한 인스턴스에 연결
lab-raid-disk1(10GB) → /dev/vddlab-raid-disk2(10GB) → /dev/vdelab-raid-disk3(10GB) → /dev/vdf
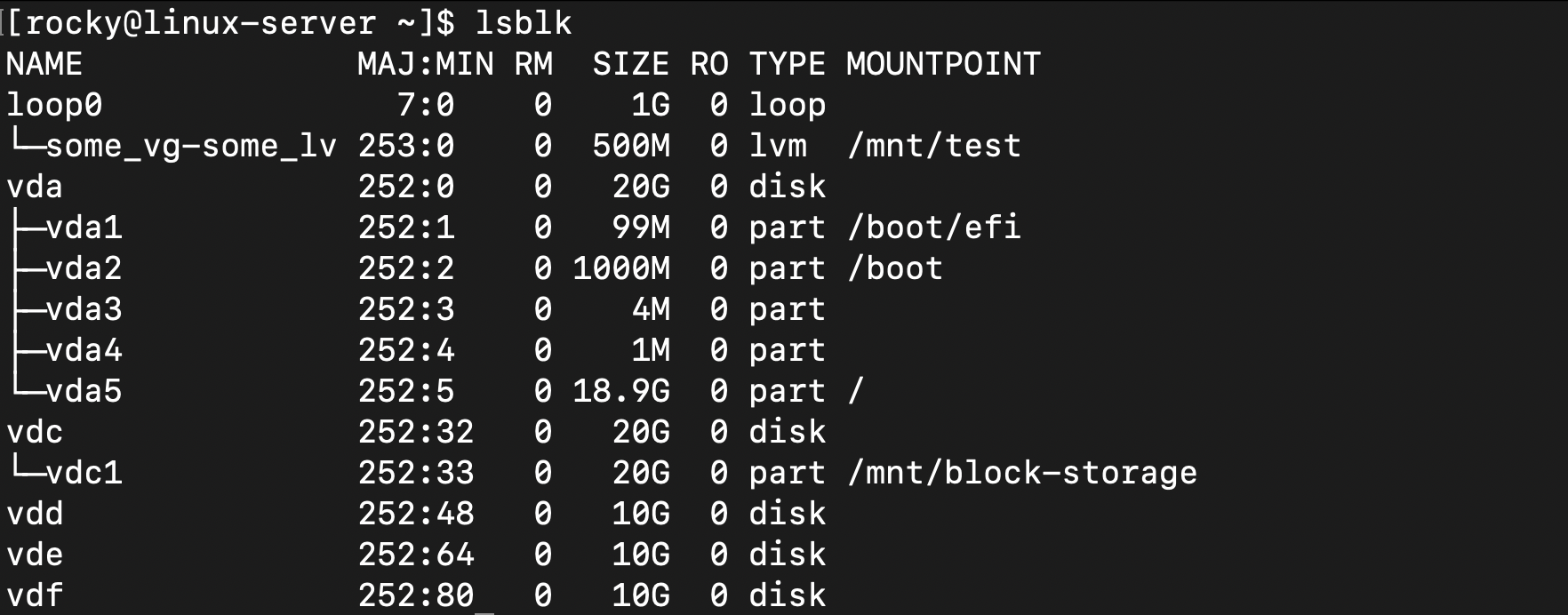
/dev/vdc 는 이미 다른 용도로 사용 중(/mnt/block-storage에 마운트)이므로 /dev/vdd, /dev/vde, /dev/vdf 가 실제 RAID 구성용 디스크
1-2. RAID. 관리 도구 설치
mdadm이란?
- Multiple Device Administrator의 줄임말
- 리눅스에서 소프트웨어 RAID를 관리하는 핵심 도구
sudo apt-get update # Ubuntu/Debian
sudo apt-get install mdadm -y
sudo yum install mdadm -y # CentOS/RHEL1-3. 디스크 초기화
sudo dd if=/dev/zero of=/dev/vdd bs=1M count=10
sudo dd if=/dev/zero of=/dev/vde bs=1M count=10
sudo dd if=/dev/zero of=/dev/vdf bs=1M count=10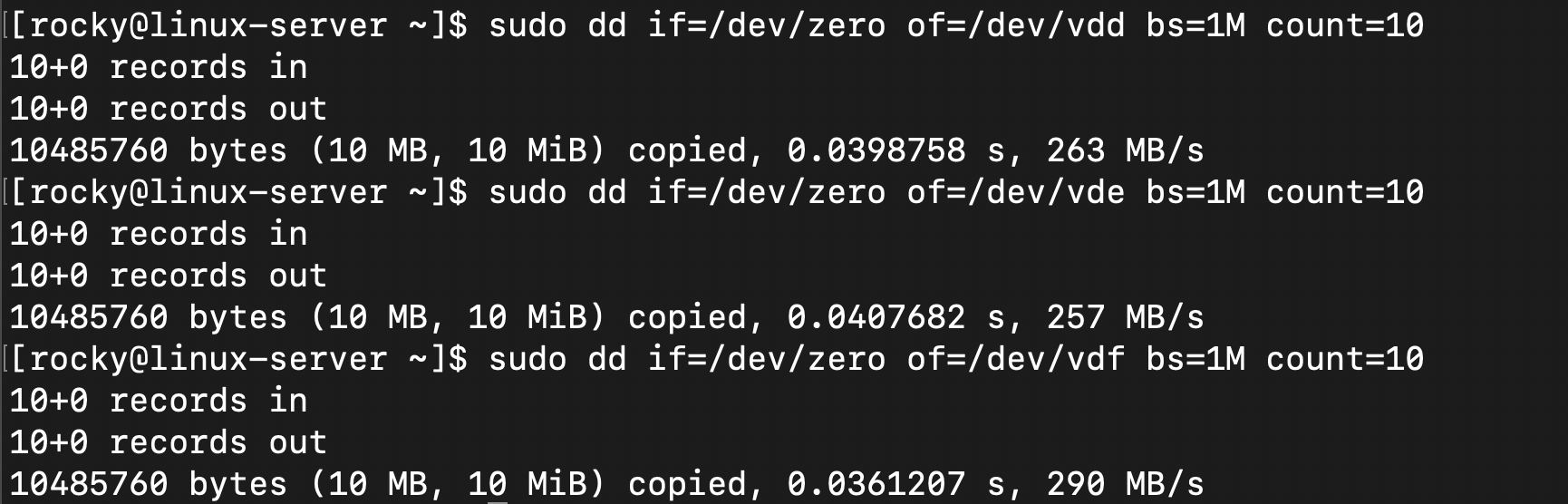
if=/dev/zero는 입력 파일 (=0으로 채워진 무한한 데이터 소스)of=/dev/vdd는 출력 파일 (=대상 디스크)bs=1M은 블록 크기 1MB를 의미count=10으로 10번 반복하여 총 10MB 초기화
여기까지 RAID 구성을 위한 클린 디스크 3개 준비 완료
1-4. RAID 0 구성
1) RAID 0 배열 생성
/dev/vdd 와 /dev/vde 로 /dev/md0 이라는 가상 블록 장치 생성

- 데이터를 512KB 단위로 두 디스크에 번갈아 저장
- 두 디스크가 동시에 읽기/쓰기 가능 (약 2배 속도 향상)

이제 시스템에서 /dev/md0 을 하나의 큰 디스크처럼 사용할 수 있다.
(물리적인 2개의 디스크가 논리적인 1개의 고속 디스크로 변환)
2) RAID 상태 확인
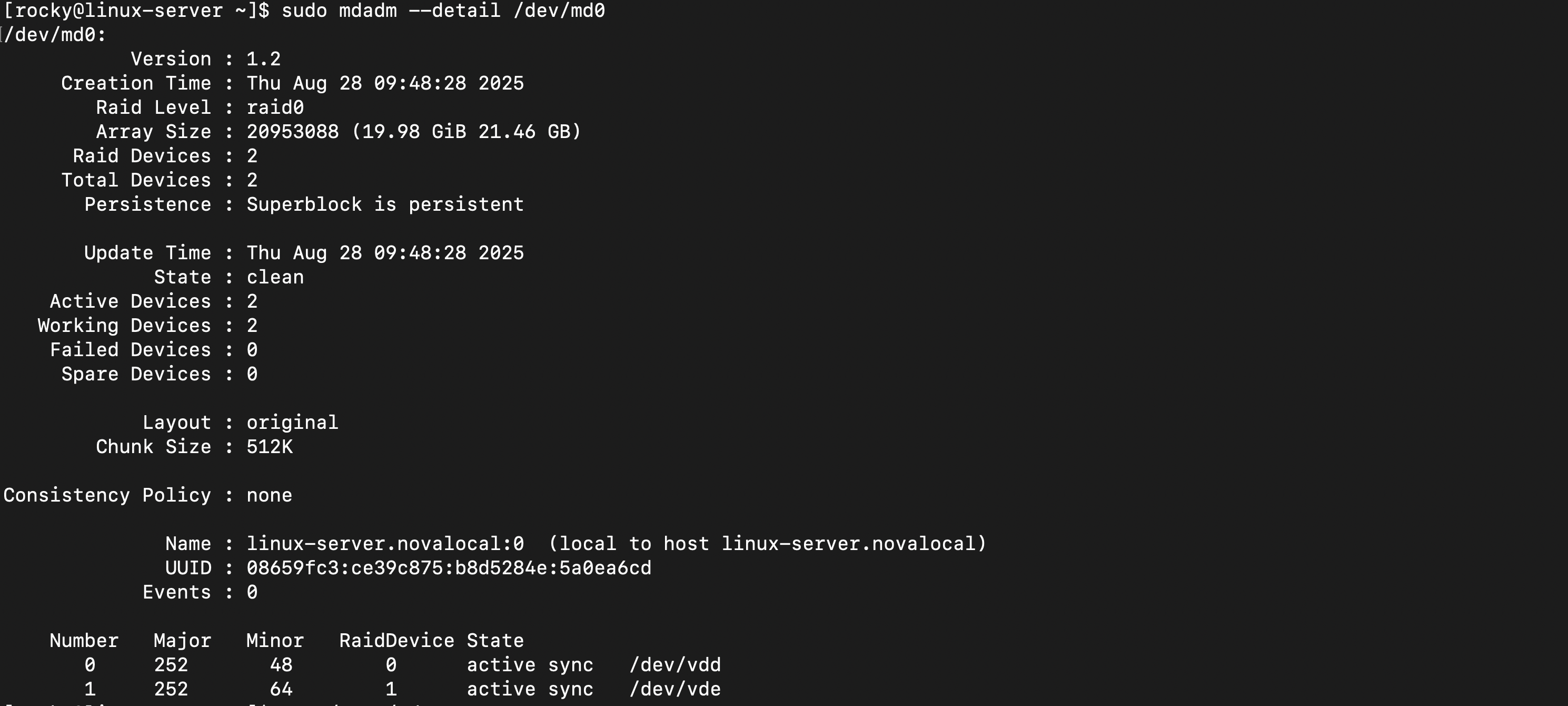
- 고장난 디스크 없이 모든 디스크 정상 작동
- 20GB 용량으로 사용 준비 완료
- 512KB 청크로 성능 설정 최적화
3) 파일시스템 생성
빈 RAID 장치에 파일을 저장할 수 있는 관리 시스템(XFS)을 설치하여 실제 사용 가능한 고속 스토리지로 만들어주는 과정
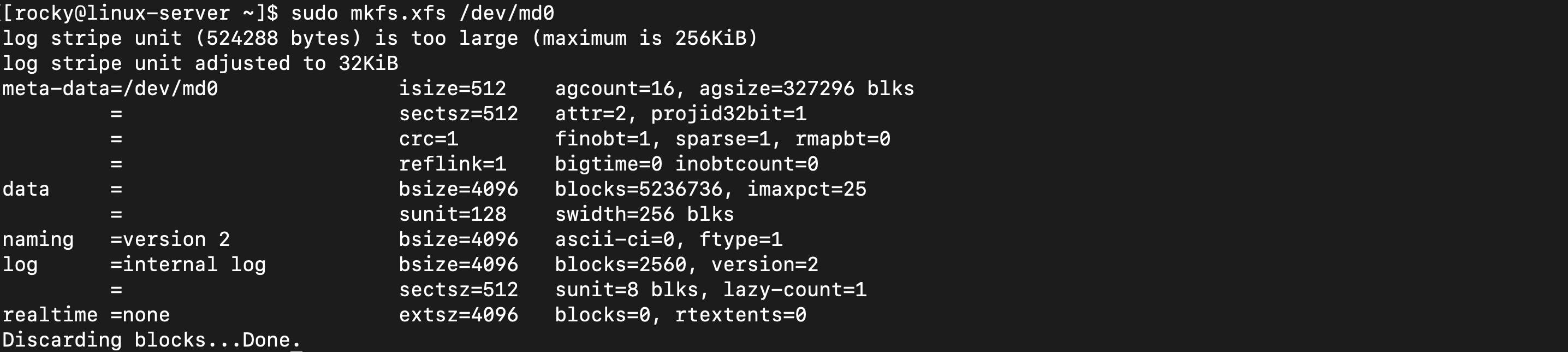
- 물리적 저장공간을 논리적 파일 관리 시스템으로 변환
- 파일 저장을 위한 메타데이터 구조 생성
- 폴더, 파일명, 권한 정보 관리 시스템 구축
/dev/md0에 XFS 파일시스템이 생성됨- 자동으로 RAID 청크 크기(512KB) 감지
이제 마운트하면 실제 파일 저장/읽기가 가능하다.
4) 파일시스템 마운트
파일 시스템을 실제 사용 가능한 폴더에 연결

/dev/md0을/mnt/raid0에 마운트 완료/mnt/raid0에서 20GB 고속 RAID 0 스토리지 사용 가능
5) 성능 테스트

- 1000개 블록 읽기/쓰기 성공 (오류 없음)
- RAID 0 실제 속도는 약 275MB/s (성능 약 1.4 ~ 1.8배 정도 개선)
1-5. RAID 1 구성
RAID 1은 같은 데이터를 두 디스크에 동시에 저장 (미러링)
/dev/vdd: [A][B][C][D] ← 원본
/dev/vde: [A][B][C][D] ← 완전한 복사본중요한 문서를 복사기로 복사해서 두 곳에 보관하는 것과 같음
1) 기존 RAID 0 정리
$ sudo umount /mnt/raid0
$ sudo mdadm --stop /dev/md02) RAID 1 생성
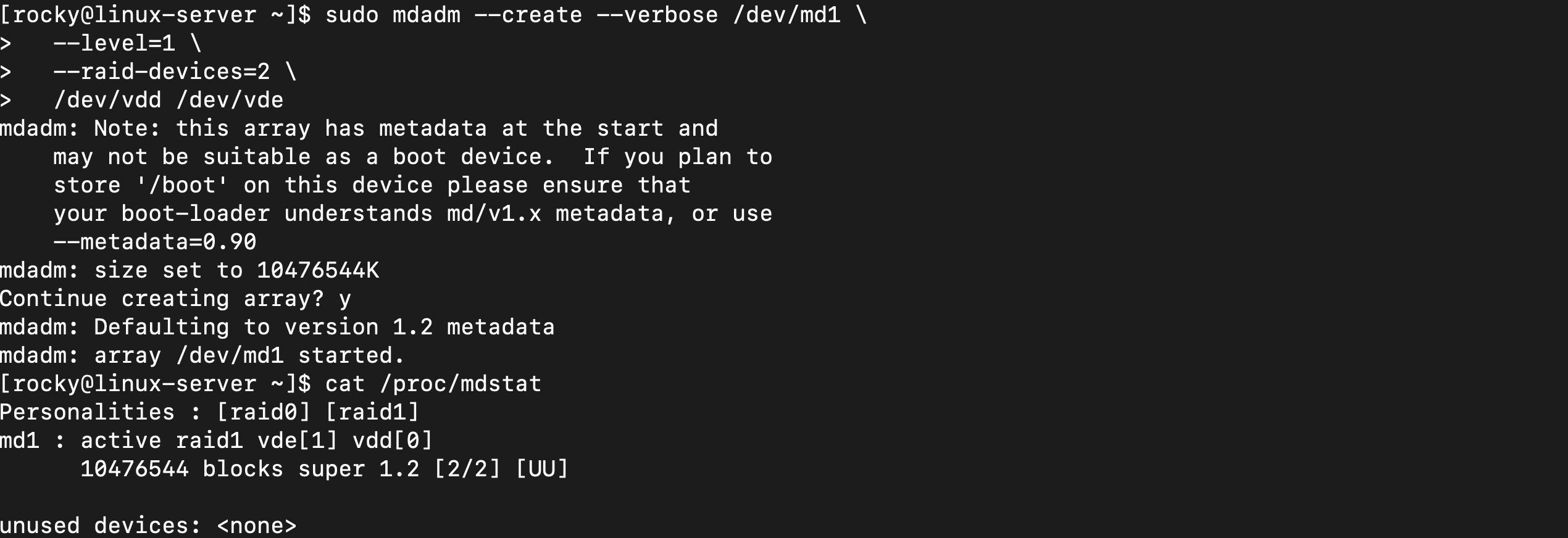
- vde[1] vdd[0] 두 디스크 모두 정상적으로 인식
- 10476544 blocks는 약 10GB 용량을 의미
- 현재 같은 데이터가 두 디스크에 복사된 상태 (미러링)
- 하나의 디스크가 고장나더라도 데이터 보존
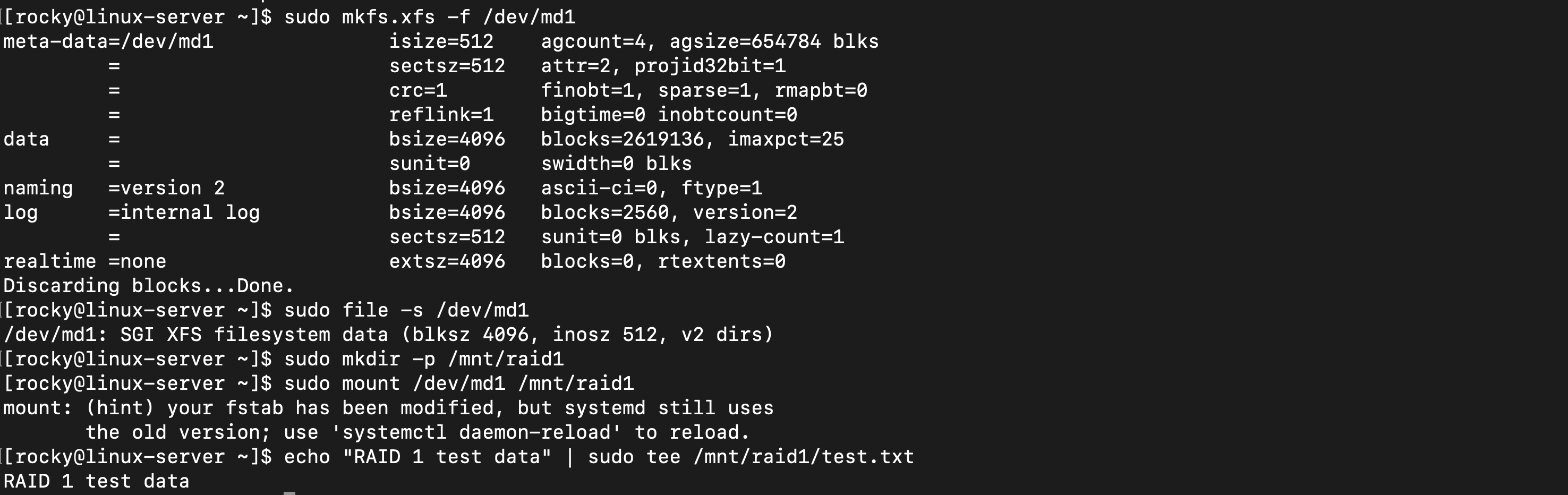
sunit=0 swidth=0: RAID 1은 미러링이라 스트라이프 최적화 불필요- 정상적인 XFS 파일시스템 생성
- 테스트 데이터를 생성하면 test.txt 파일이 두 디스크에 동시 저장됨
1-6. RAID 5 구성
1) RAID 5 생성

Left-Symmetric은 RAID 5의 패리티 배치 방식- 패리티 블록이 각 디스크에 순환하며 분산 저장
- 데이터를 512KB 단위로 분할하여 저장 (각 디스크에 저장되는 최소 데이터 블록 크기)
- 각 디스크의 유효 용량은 약 10GB이며, 전체 사용 가능 용량은 20GB (10GB × 2개 데이터 디스크)
- 1개 디스크는 패리티 정보 저장용
3개의 디스크가 하나의 스토리지로 통합된 상태.
2) 파일시스템 생성 및 마운트
RAID 0, RAID 1과 마찬가지로 XFS 파일시스템을 생성
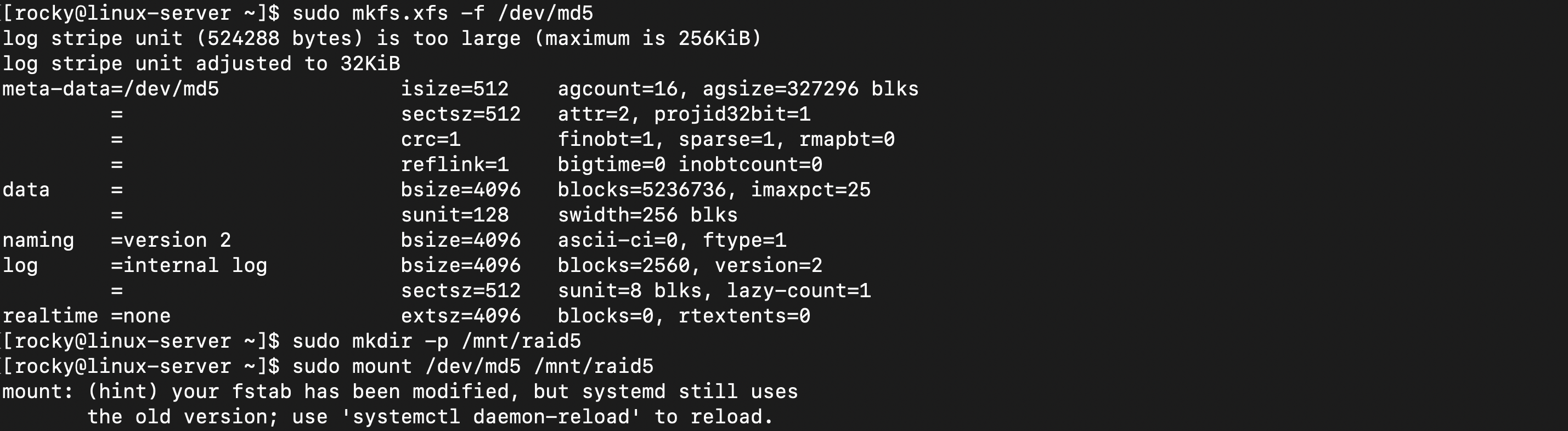
- XFS가 RAID 5의 512KB 청크 크기를 감지
- 로그 시스템은 최대 256KB까지만 지원
결과적으로 /mnt/raid5 에서 20GB 고성능 안전 스토리지를 사용할 수 있게 되었다.
1-7. RAID 영구 설정
RAID 5 배열을 시스템 레벨에서 영구적으로 통합하여 재부팅 후에도 자동으로 작동하도록 설정해 보았다.
1) mdadm 설정 저장
sudo mdadm --detail --scan | sudo tee /etc/mdadm/mdadm.conf- 현재 활성화된 RAID 배열의 UUID와 구성 정보를 수집하여
/etc/mdadm/mdadm.conf파일에 저장한다. - 이렇게 하면 저장된 정보를 통해 시스템이 부팅할 때마다 UUID를 기반으로 RAID 배열을 자동으로 재구성할 수 있게 된다.
2) 초기 램 디스크 재구성
sudo dracut -f- 부팅 초기 단계에서 사용되는
initramfs이미지를 강제로 재생성하여 mdadm과 RAID 관련 드라이버들을 포함시킨다. - 이를 통해 루트 파일시스템이 마운트되기 이전 단계에서도 RAID 배열이 정상적으로 활성화될 수 있도록 지원한다.
3) 파일시스템 자동 마운트 설정
부팅할 때마다 RAID 5를 자동으로 /mnt/raid5 에 연결하도록 시스템에 등록하는 과정
echo '/dev/md5 /mnt/raid5 xfs defaults 0 2' | sudo tee -a /etc/fstab이렇게 하면 재부팅 후에도 별도의 마운트 명령 없이 바로 RAID 스토리지를 사용할 수 있게 된다.
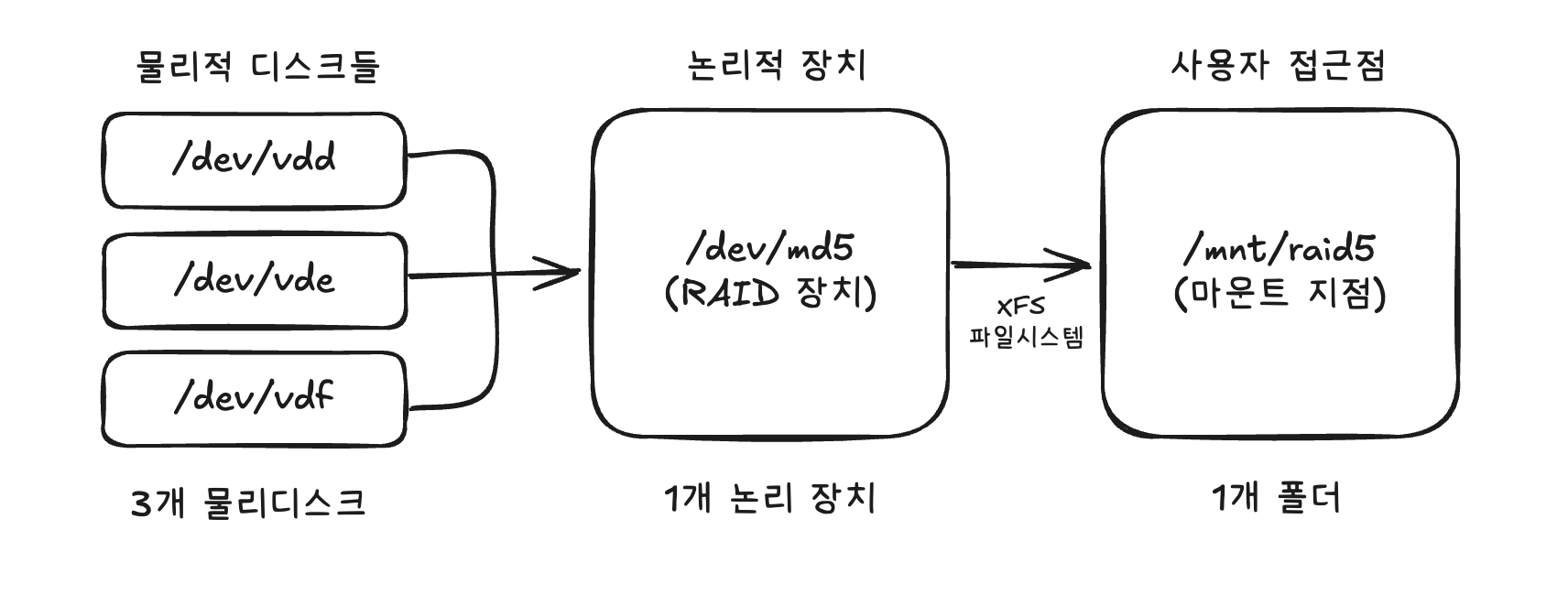
개념적 관계도
- 3개의 물리 디스크가 1개의 논리 장치로 통합되고, RAID 장치가 중간 추상화 계층 역할
/dev/md5의 원시 블록 데이터가 XFS를 통해 파일과 디렉토리로 관리되어/mnt/raid5에서 접근 가능하게 됨- 최종적으로 사용자는 1개의 폴더(/mnt/raid5)로 접근
- 사용자는
/mnt/raid5에 저장하는 것처럼 보이지만, 실제로는/dev/md5논리 장치를 통해 물리 디스크들(vdd,vde,vdf)에 RAID 5 방식으로 분산 저장
2) RAID 장애 시뮬레이션 및 복구
디스크가 물리적으로 고장나서 작동하지 않는 상황을 시뮬레이션
고장난 디스크를 제거하고 새 디스크로 교체하는 과정을 통해 서비스 중단 없이 데이터 복구가 가능한가?
2-1. 테스트 데이터 생성
RAID 5 볼륨에 데이터 파일을 만들어서 장애 복구 후에도 데이터가 보존되는지 확인하고자 함.
$ echo "Important RAID data" | sudo tee /mnt/raid5/important.txt$ sudo mdadm --manage /dev/md5 --fail /dev/vdf
mdadm: set /dev/vdf faulty in /dev/md5--fail옵션은 특정 디스크를 강제로 장애 상태로 만듦- 장애를 처리할 디스크를
/dev/vdf로
RAID 배열의 상세 상태 확인
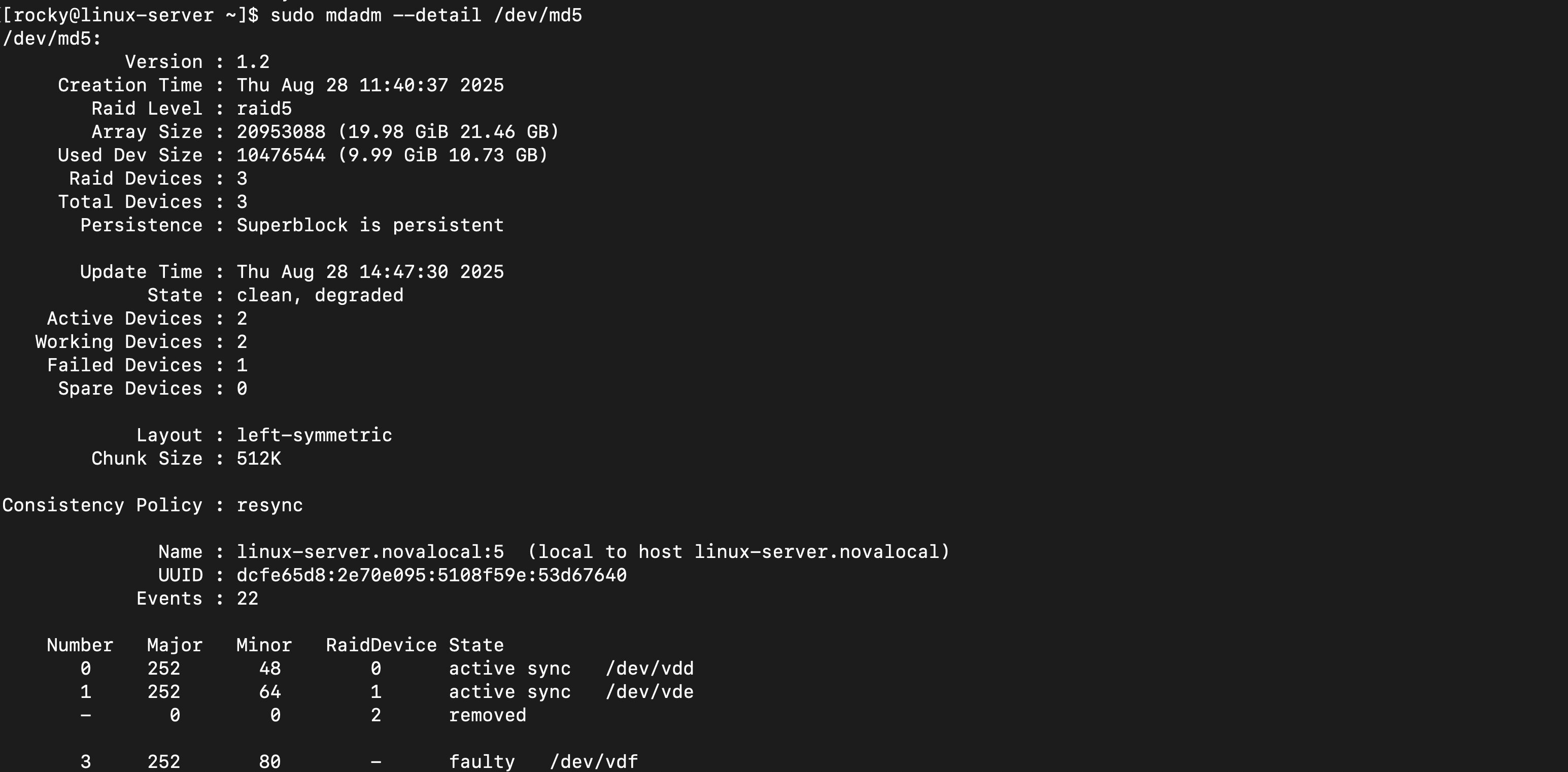
- RAID 5 용량은 디스크 3개 x 10GB = 30GB (사용 가능한 용량은 패리티 디스크 1개를 제외한 20GB)
- 데이터 손실 없음
/dev/vdf는 장애 상태로 표시됨(faulty)
현재 상태
Disk 1: [Data A] [Data C] [Parity] 정상 Disk 2: [Data B] [Parity] [Data F] 정상 Disk 3: [FAILED] [FAILED] [FAILED] 장애
장애 디스크 제거 및 핫 스왑
RAID 5의 핵심 기능인 장애 허용성(Fault Tolerance)과 무중단 복구(Non-disruptive Recovery)를 실제로 검증하는 과정이다.
1) 장애 디스크 제거
/dev/vdf 디스크를 RAID 5 배열에서 강제로 분리
$ sudo mdadm --manage /dev/md5 --remove /dev/vdf
- 이 과정 이후 RAID 5 배열은
Degraded(성능 저하)상태로 전환 - 패리티 정보를 이용해 데이터 접근은 계속 가능하다.
RAID 5에서는 1개 디스크 제거까지만 안전하기 때문에 실제 실무 상황에서는 디스크가 고장나면 제거 후 가능한 빨리 새 디스크로 교체하는 것이 중요하다.
2) 새 디스크로 교체 (핫 스왑)
제거된 디스크 자리에 동일한 명령어를 사용하여 새로운 /dev/vdf 디스크를 추가하는 이 과정을 핫 스왑(Hot Swap)이라고 하는데, 서버를 끄지 않고(=서비스 중단 없이) 디스크를 교체할 수 있음을 의미한다.
$ sudo mdadm --manage /dev/md5 --add /dev/vdf
mdadm: added /dev/vdf
/dev/vdf디스크를/dev/md5RAID 배열에 추가- 시스템은 자동으로 해당 디스크를 배열의 새 멤버로 인식한다. 따라서 추가하는 즉시 복구 프로세스가 자동으로 시작된다.
- 디스크 추가 후에는 mdadm이 패리티 정보를 이용해 누락된 데이터를 자동으로 재구성하기 시작한다.
3. 복구 진행 상황 모니터링

- 새 디스크가 추가되면
mdadm은 자동으로 복구 프로세스를 시작한다. (백그라운드)- 기존 디스크들의 데이터와 패리티 정보를 이용해 새로운 디스크에 누락된 데이터를 재구성
cat /proc/mdstat명령어를 통해 복구 진행률을 실시간으로 확인 가능
[3/3]과[UUU]처럼 모든 디스크가 정상임을 다시 확인할 수 있게 되면 복구가 완료된 것 (Healthy)
