
대용량 트래픽 & 데이터 처리
이번 주차는 현재 프로젝트에 분산 환경을 대응하기 위한 Kafka에 대한 개념을 학습하는 과정이었습니다.
Kafka 구조 및 동작 정리
기능 역할
Cluster:Kafka Broker로 이루어진 집합Producer: 메세지를Topic/Broker에Partition으로 발행하는 서비스Consumer:Topic의Partition에 적재된 메세지를 소비하는 서비스 → ex) DB에 실제 저장하는 로직, 서드 파티 호출offset:Partition에서 어디까지 읽었는 지 나타내는 위치 포인터
Broker: 클러스터 내에 존재하는 카프카 서버 프로세스Topic: 메세지를 논리적으로 묶는 카테고리, 하나 이상의Partition을 보유Partition:Topic을 분할한 단위,key값을 이용해 같은Partition내에서만 순서가 보장 → ex) User 여러명의 데이터는 한번에 처리해도 되지만, 한 User의 충전/차감은 같은 Partition에 존재하여 순차 보장Segment: 각Partition로그 파일을 일정 크기/시간 단위로 분할된 조각, 보존/삭제가 동작되는 단위
Controller:Cluster메타데이터를 관리하고, Broker/Partition 상태를 감시해, 장애가 발생한 Broker 내에 리더가 존재한다면 다른 Partition을 리더로 선출/재할당 수행Coordinator:Cousumer Group상태를 보면서, 장애 발생 시 다른Consumer에게 재할당,Consumer,Partition수 변경 시Rebalancing역할
실행 흐름
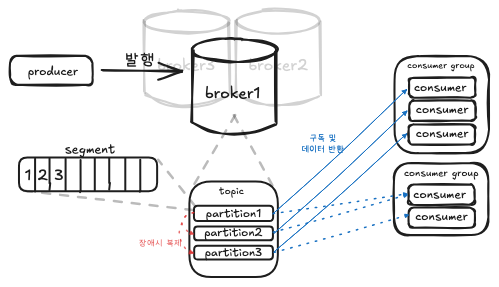
Producer 발행/생산 → 각 Partition 적재 → Consumer Group별 소비
Producer가 메세지 발행
Topic의 어떤Partition으로 적재할 지key를 통해 확인
- 리더
Broker파티션이 디스크에 기록, 다른 부가Broker로 복제
- 기록되면 소비의 대상이되고, 장애가 나도 복제본에 전가
- 리더
Concumer가 메세지를 읽어 처리
- DB에 영속화하거나, 외부 API를 호출하는 등의 최종 로직 수행
- 하나의
Partition에는 동시에 하나의Consumer만 소비(Consumer Group내에서)
Kafka 장단점
-
장점
- 병렬처리로 높은 처리량을 발휘, 확장성이 뛰어남
- 디스크에 기록되어 소실 위험이 없음, 내구성 높음, 재처리 쉬움
- 생산하는 쪽과 소비하는쪽의 분리, 장애 격리
-
단점/주의
- 전역 순서 미보장, 파티션 단위만 순서 보장됨
- 리밸런싱이 발생한 동안 소비기 일시 중단됨
환경 세팅
- docker-compose-kafka.yml
services:
kafka:
image: apache/kafka:4.0.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_LISTENERS: CONTROLLER://localhost:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://localhost:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT
KAFKA_NODE_ID: 1 # 노드 수
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_LOG_DIRS: /var/lib/kafka/data
volumes:
- ./kafka-data:/var/lib/kafka/data
- 실행
docker compose -f docker-compose-kafka.yml up -dCLI 예제 토픽 생성 및 소비
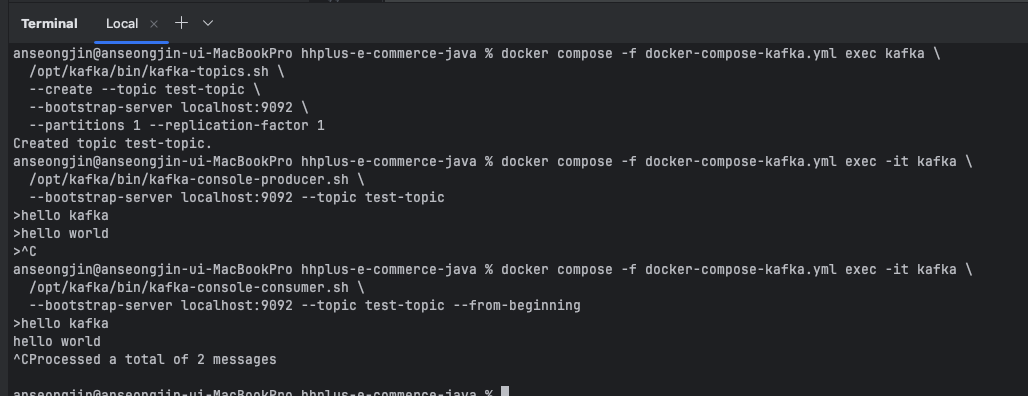
docker실행 후kafka라이브러리에 포함된 예제 토픽 발행kafka-console-producer.sh:hello kafka메세지 발행kafka-console-consumer.sh: 적재된hello kafka메세지 소비
# 생성
docker compose -f docker-compose-kafka.yml exec kafka \
/opt/kafka/bin/kafka-topics.sh \
--create --topic test-topic \
--bootstrap-server localhost:9092 \
--partitions 1 --replication-factor 1
# Producer 메세지 발행
docker compose -f docker-compose-kafka.yml exec -it kafka \
/opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 --topic test-topic
# 후 입력
# Consumer 메세지 소비
docker compose -f docker-compose-kafka.yml exec -it kafka \
/opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic test-topic --from-beginning
# 삭제
docker compose -f docker-compose-kafka.yml exec kafka \
/opt/kafka/bin/kafka-topics.sh \
--delete --topic test-topic \
--bootstrap-server localhost:9092피드백
- 현업에서 사용한다면, Redis에서 DECR과 ZADD가 동작할 때의 실제 DB와의 정합성을 고려해야한다.
회고
- 이번주 초에 건강상의 이유로 과제를 할 시간이 많이 부족하여, 심화 과정으로 내주신 부분을 하지 못한 것이 아쉬웠습니다.
- 한주밖에 안남은 과정에서 최대한 주어진 것들을 완성해보고, 추후에 한개의 샘플 프로젝트를 구성하여 완전히 체득하는 과정이 절실하다고 느꼈습니다.
