
● 오늘의 공부
- BeautifulSoup
- 개발자 도구
♟️BeautifulSoup
♟️Beautifulsoup 설치
conda에서 vscode 입력 후 conda install -c anaconda beautifulsoup4 를 입력해서 beautifulSoup를 설치한다.
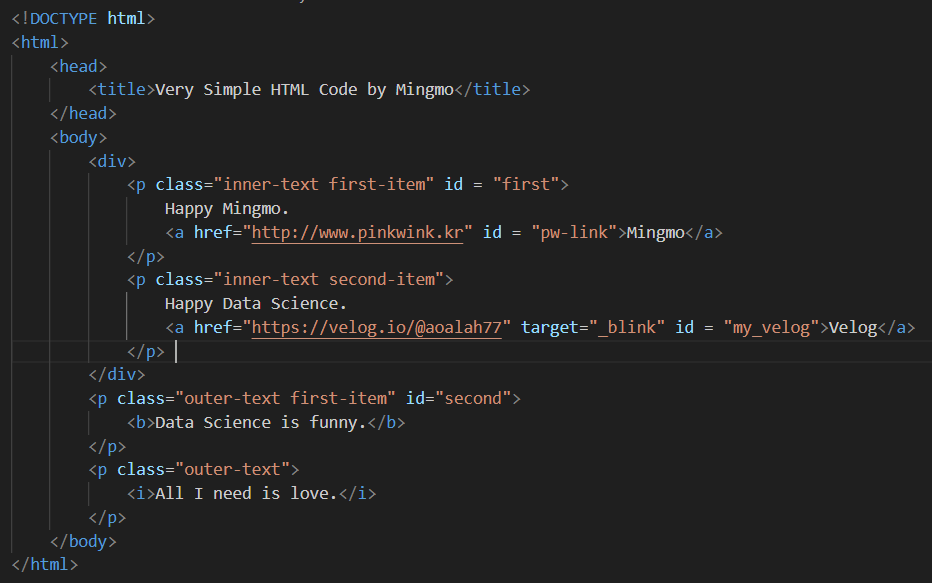
♟️Beautifulsoup Basic
본격적으로 하기전에 html을 작성해서 임의로 홈페이지를 하나 만든다.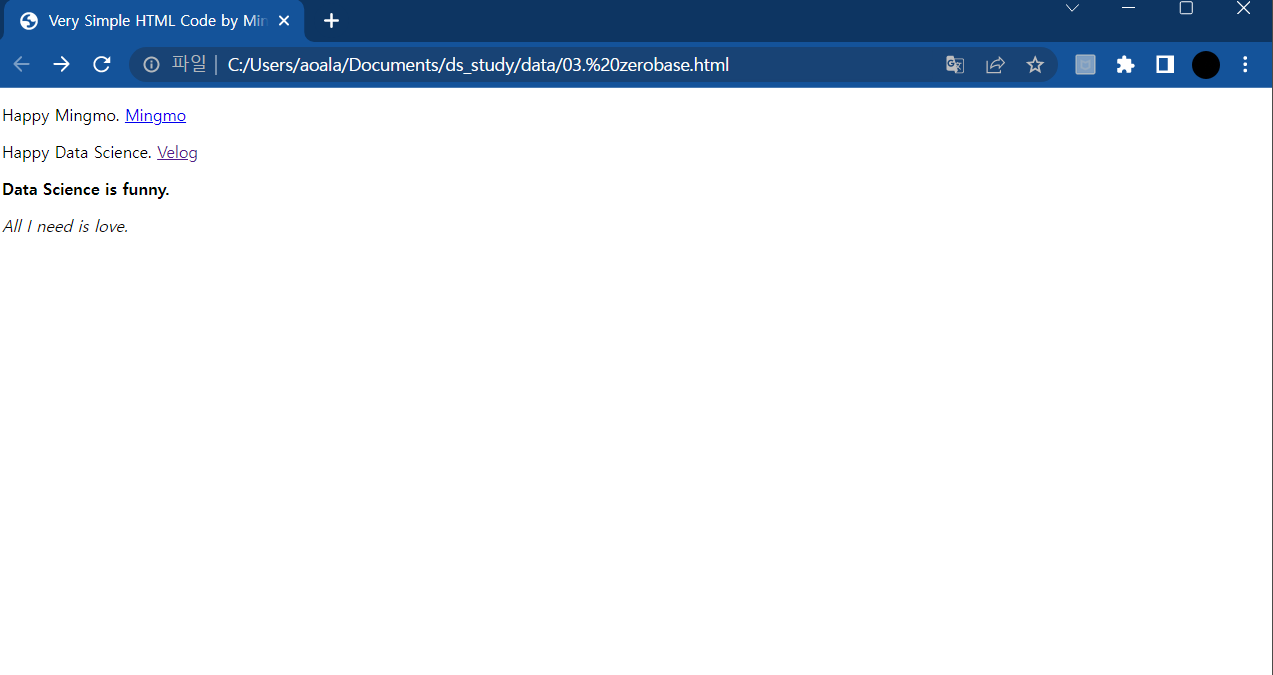
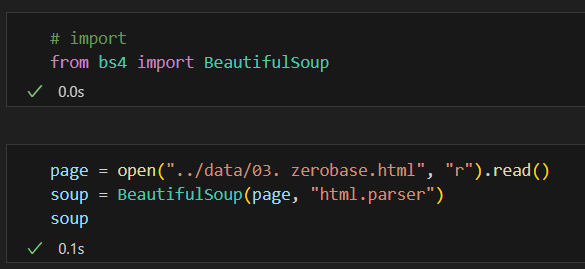 bs4에서 BeautifulSoup를 import 한 뒤 page라는 변수에 아까 만들어준 html 파일 읽기로 하나 할당해준다. 그리고 soup 라는 변수에 BeautifulSoup() 에 html이 들어간 파일이랑 html.parser 이라는 엔진을 넣어주면
bs4에서 BeautifulSoup를 import 한 뒤 page라는 변수에 아까 만들어준 html 파일 읽기로 하나 할당해준다. 그리고 soup 라는 변수에 BeautifulSoup() 에 html이 들어간 파일이랑 html.parser 이라는 엔진을 넣어주면
 들여쓰기가 되지 않은 채로 출력이 된다. 여기서 print(soup.prettify())를 입력하면
들여쓰기가 되지 않은 채로 출력이 된다. 여기서 print(soup.prettify())를 입력하면 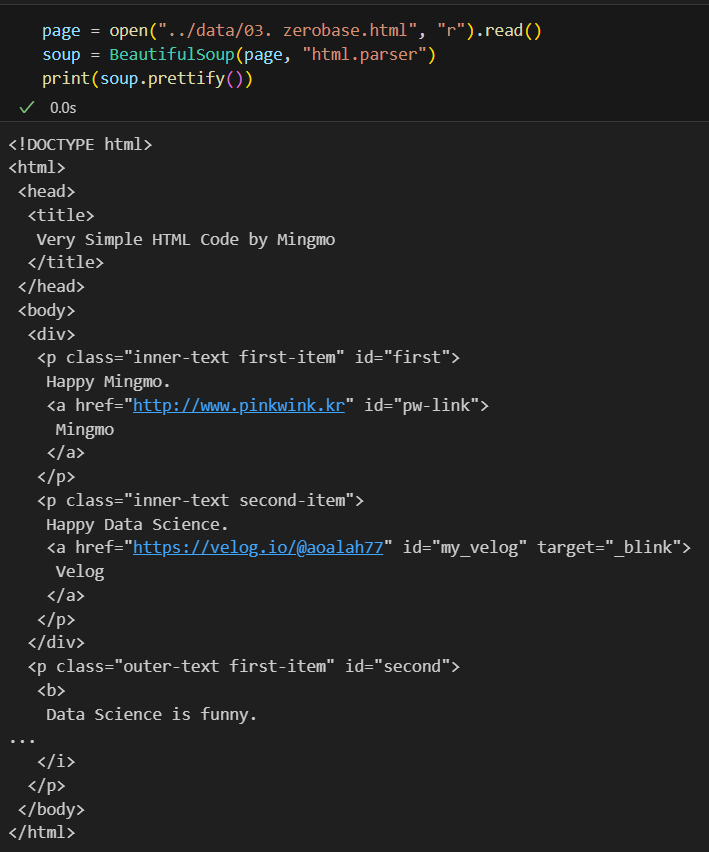 들여쓰기가 된 상태로 출력이 된다. 이쁘게 출력이 된다는건지 모르겠지만 아무튼 잘 나온다.
들여쓰기가 된 상태로 출력이 된다. 이쁘게 출력이 된다는건지 모르겠지만 아무튼 잘 나온다.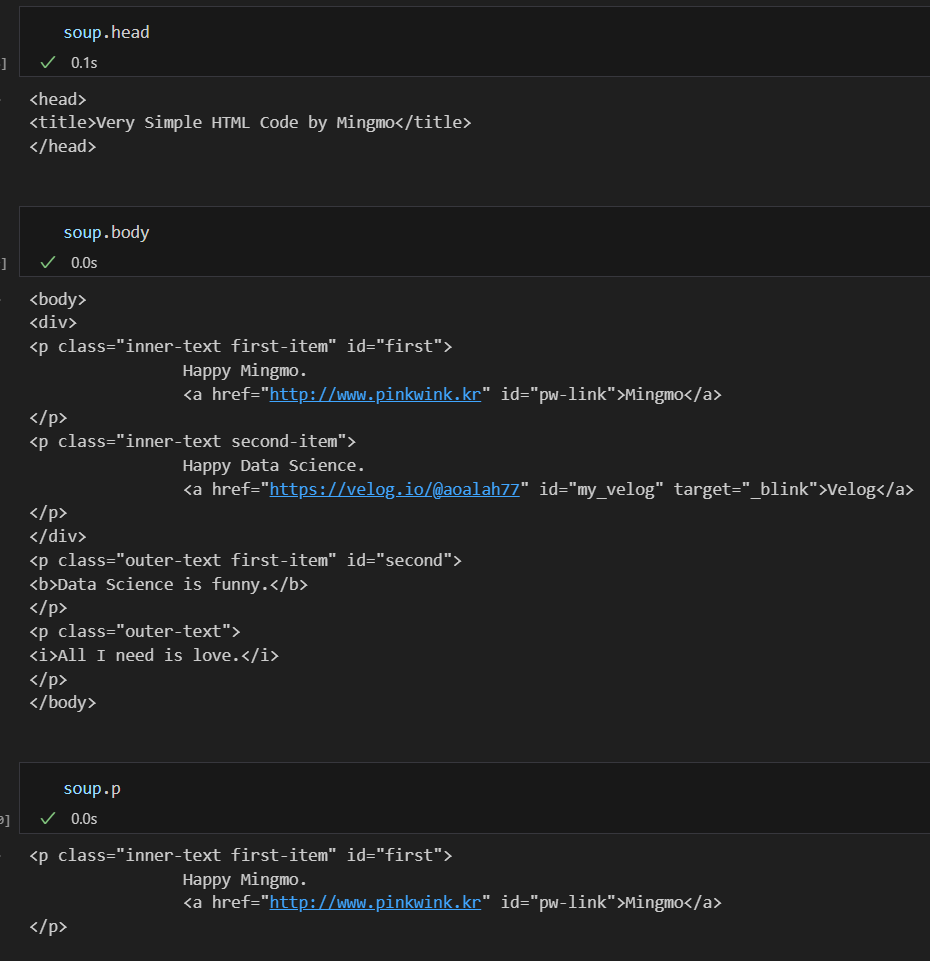
soup에 head와 body를 입력해주면 html 데이터에서 해당하는 부분이 호출된다.
♟️find(), find_all()
♟️find()
find() 단일조건find()를 해주면 최초에 발견하는 값을 출력해준다. 값이 여러개 일때 조건을 붙여주면 조건에 맞는 값을 찾아서 출력을 해준다. 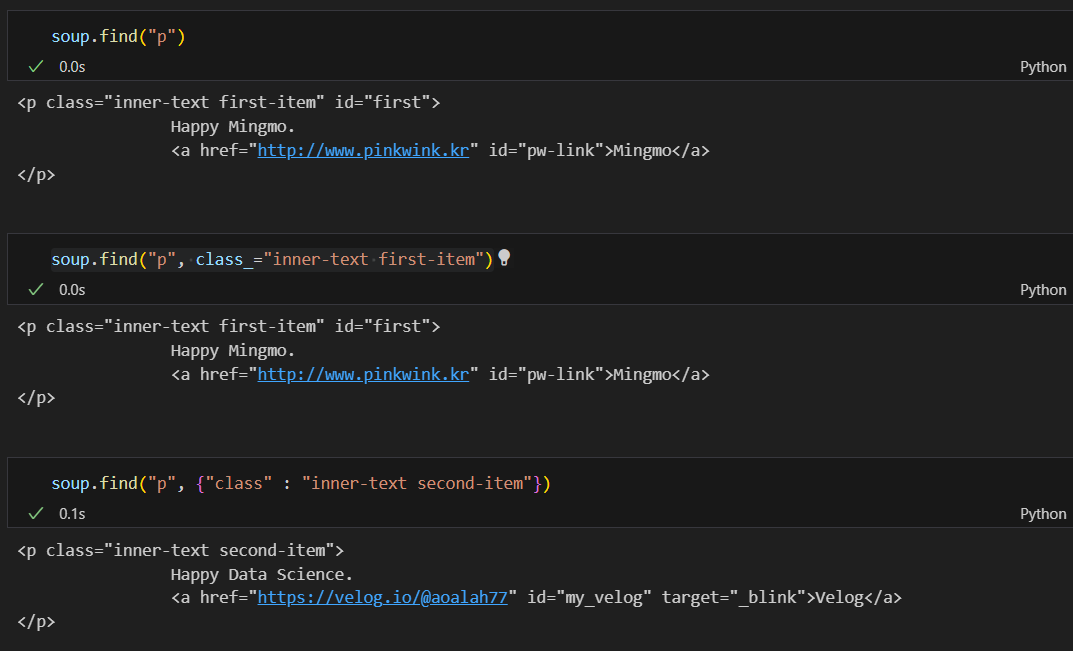 class에서 언더바를 붙이는 이유는 python의 예약언어와 겹칠수도 있기 때문에 종종 언더바를 쓴다. 그리고 딕셔너리 형태에서처럼 쓸수도 있다.
class에서 언더바를 붙이는 이유는 python의 예약언어와 겹칠수도 있기 때문에 종종 언더바를 쓴다. 그리고 딕셔너리 형태에서처럼 쓸수도 있다.
find() 다중조건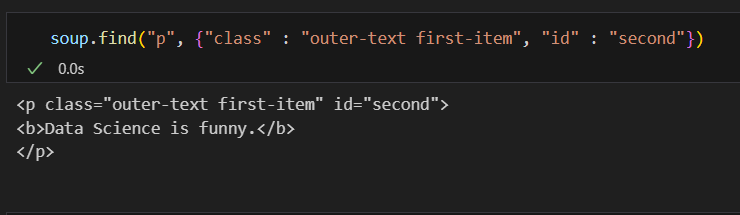 find()에서 하나의 조건만 아니라 여러개의 조건을 걸어서 데이터를 찾을수도 있다.
find()에서 하나의 조건만 아니라 여러개의 조건을 걸어서 데이터를 찾을수도 있다.
find() text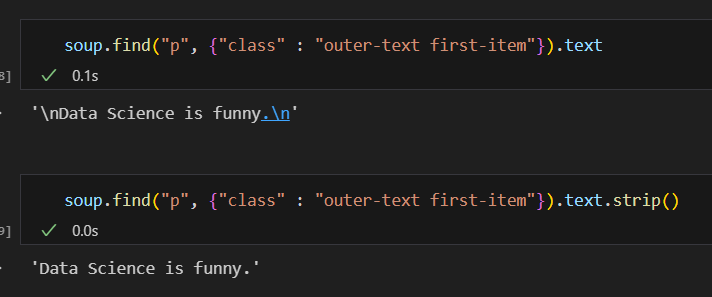 그리고 .text라고 해서 텍스트만 불러낼 수도 있다. 가끔 텍스트를 불러냈을때 html 문법이 나오거나 사진과 같은 개행이 나오거나 할 수 있는데 이때는 sprit()으로 공백을 없애주면 된다.
그리고 .text라고 해서 텍스트만 불러낼 수도 있다. 가끔 텍스트를 불러냈을때 html 문법이 나오거나 사진과 같은 개행이 나오거나 할 수 있는데 이때는 sprit()으로 공백을 없애주면 된다.
♟️find_all()
여러개의 태그를 반환하고, List 형태로 반환을 해준다.
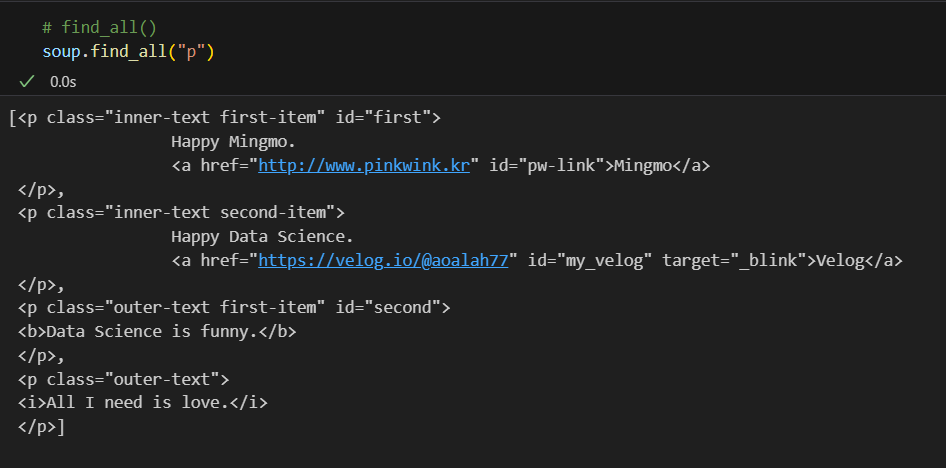 find_all()을 하면 태그된 모든 값을 출력해준다.
find_all()을 하면 태그된 모든 값을 출력해준다.
find_all() 특정 태그 확인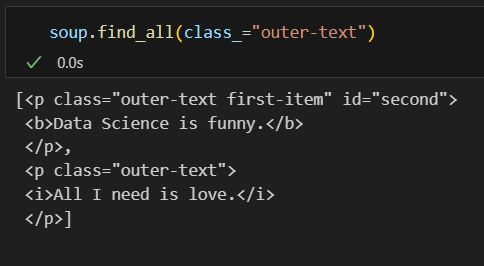 find()와 마찬가지로 특정한 태그를 넣어서 데이터를 찾을 수 있다. 물론 출력된 데이터는 최초에 만나는 데이터가 아니라 태그된 모든 데이터이고 형식은 List 형식이다.
find()와 마찬가지로 특정한 태그를 넣어서 데이터를 찾을 수 있다. 물론 출력된 데이터는 최초에 만나는 데이터가 아니라 태그된 모든 데이터이고 형식은 List 형식이다.
find_all() text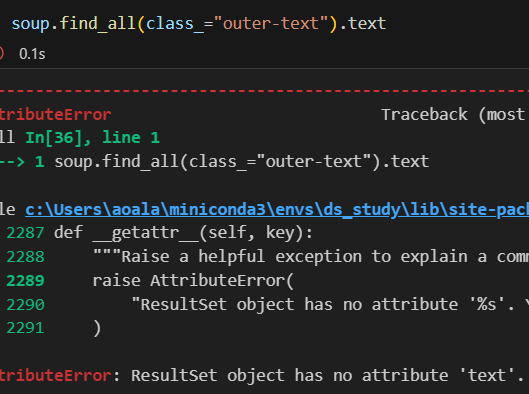 find_all()을 반환되는 데이터의 형태가 리스트이기 때문에 바로 .text를 쓸 수 없다. 그래서 리스트의 인덱스 호출법을 이용해서 호출한 후 .text를 쓰면 데이터가 호출이 된다.
find_all()을 반환되는 데이터의 형태가 리스트이기 때문에 바로 .text를 쓸 수 없다. 그래서 리스트의 인덱스 호출법을 이용해서 호출한 후 .text를 쓰면 데이터가 호출이 된다.
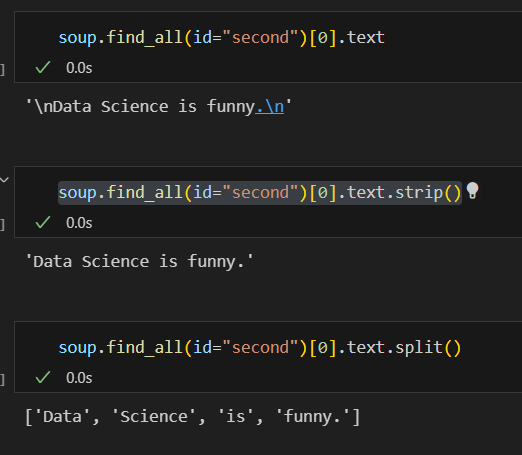 리스트 형태로 변환되기 때문에 리스트에서 쓸수 있는 split(), strip()이 사용 가능하다.
리스트 형태로 변환되기 때문에 리스트에서 쓸수 있는 split(), strip()이 사용 가능하다.
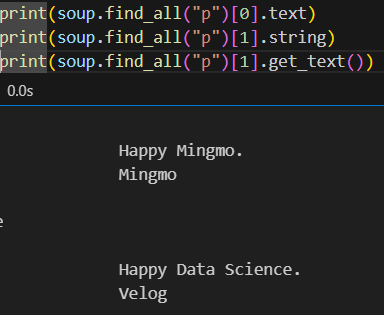 p태그에서 text를 가져올 수 있는 방법은 위 세가지다. .text, string, get_text(). 물론 리스트 형태로 먼저 받아주는 인덱스 표시도 필요하다
p태그에서 text를 가져올 수 있는 방법은 위 세가지다. .text, string, get_text(). 물론 리스트 형태로 먼저 받아주는 인덱스 표시도 필요하다
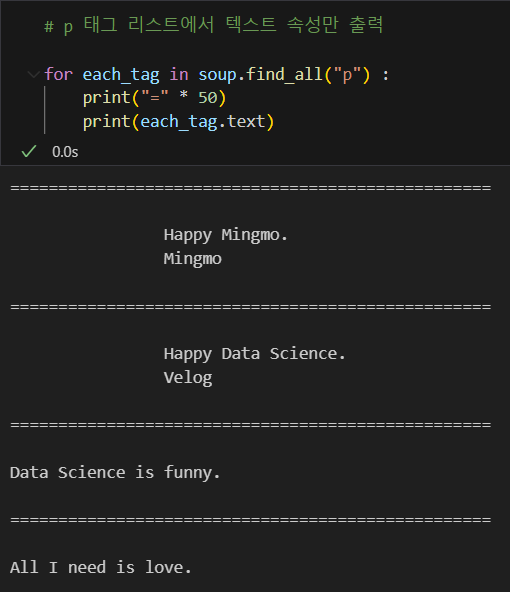 for 반복문을 사용하면 반환되는 형태는 리스트 형태이기 때문에 반복문으로도 출력이 가능하다.
for 반복문을 사용하면 반환되는 형태는 리스트 형태이기 때문에 반복문으로도 출력이 가능하다.
마찬가지로 a 태그에서 href 속성값에 있는 값을 추출하려면 .get("href"), 또는 ["href"]를 이용한다. 또 find_all() 이기 때문에 반복문을 이용해서 추출해주면 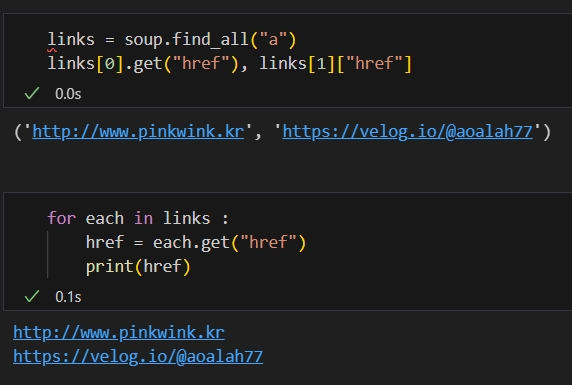
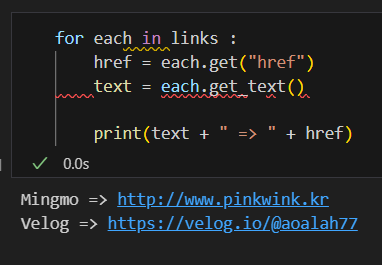 이런식으로도 가능하다
이런식으로도 가능하다
♟️개발자 도구
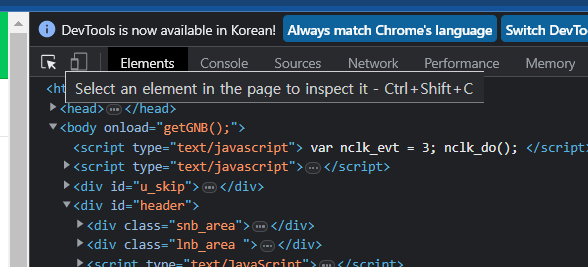 네이버나 홈페이지에서 ctrl + shift + i 를 누르거나 옵션에서 개발자 도구 보기를 선택하면
네이버나 홈페이지에서 ctrl + shift + i 를 누르거나 옵션에서 개발자 도구 보기를 선택하면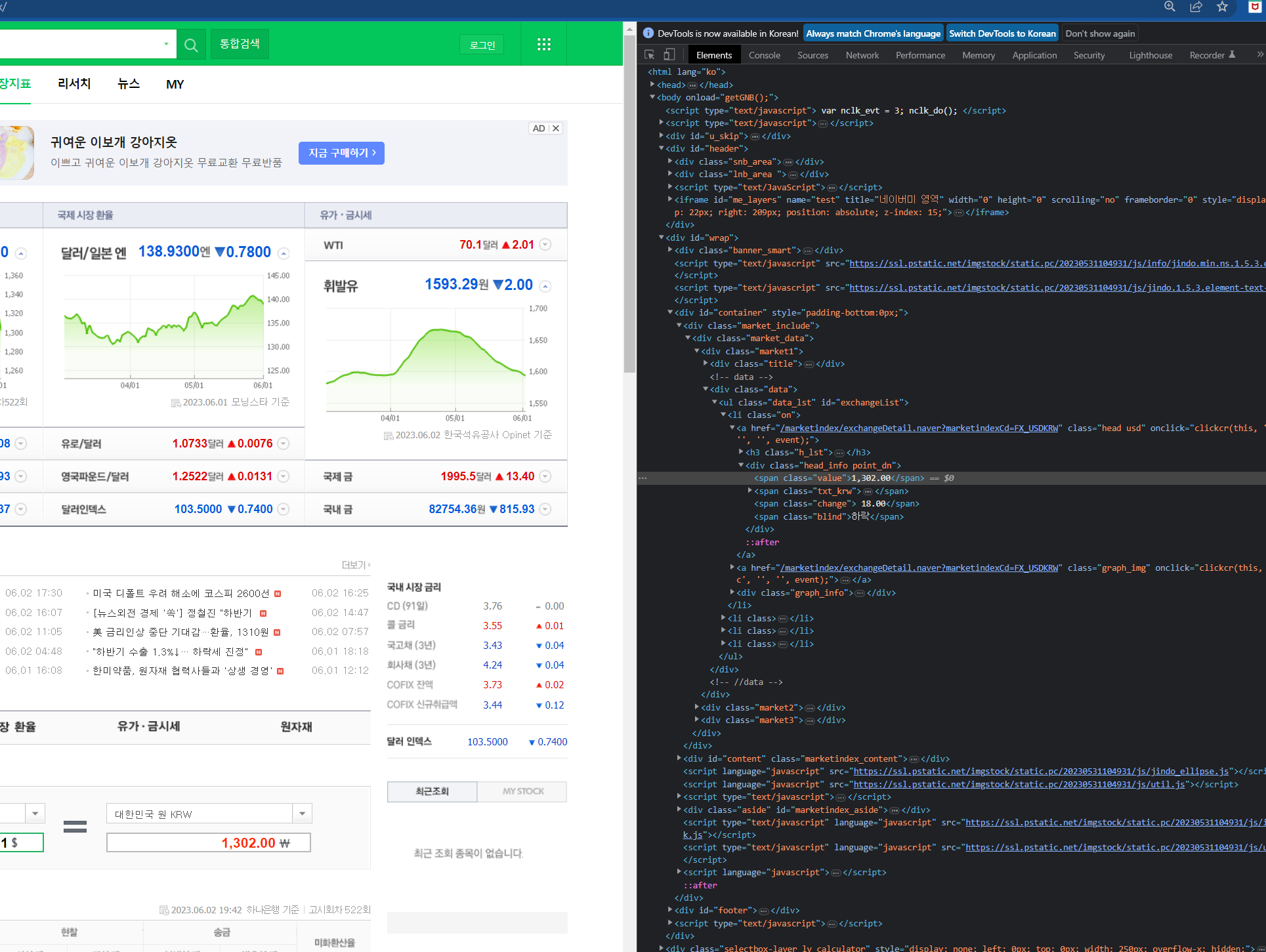 이런식으로 홈페이지에 html 주소가 나오고 코드가 나오게 된다. 여기서
이런식으로 홈페이지에 html 주소가 나오고 코드가 나오게 된다. 여기서  을 선택하게 되면 화면에 있는 요소들에 마우스를 올리면 각각에 맞는 코드와 위치가 개발자 도구에 보여진다.
을 선택하게 되면 화면에 있는 요소들에 마우스를 올리면 각각에 맞는 코드와 위치가 개발자 도구에 보여진다.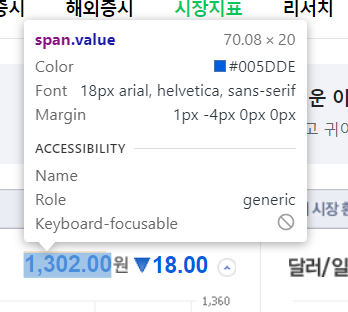
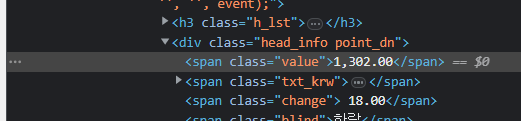
여기서 우리는 span에서 value 값은 환율이나 어떤 것의 시세의 값의 주소라는 것을 알 수 있다.
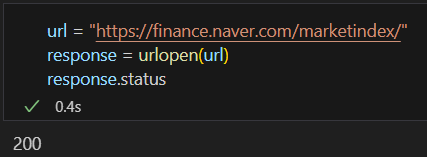 .status를 이용해서 나오는 숫자를 HTTP 상태 코드라고 하고 숫자에 따라 다른 상황을 나타낸다.
.status를 이용해서 나오는 숫자를 HTTP 상태 코드라고 하고 숫자에 따라 다른 상황을 나타낸다.
(참조 : https://ko.wikipedia.org/wiki/HTTP_%EC%83%81%ED%83%9C_%EC%BD%94%EB%93%9C )
♟️네이버 금융
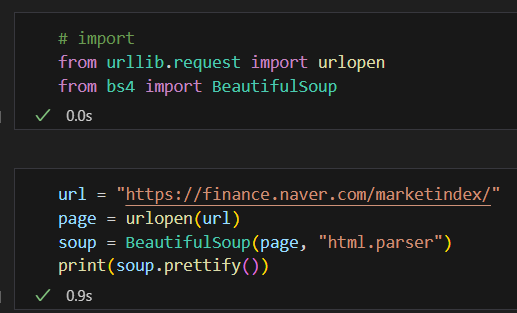 url을 읽을려면 urllib.request에서 urlopen 이라는 모듈을 import 해주고 beautifulsoup 사용을 위해 bs4에서 BeautifulSoup를 import 해준다.
url을 읽을려면 urllib.request에서 urlopen 이라는 모듈을 import 해주고 beautifulsoup 사용을 위해 bs4에서 BeautifulSoup를 import 해준다.
다음으로 url을 읽을려는 홈페이지 주소로 설정을 해주고 page라는 변수에 urlopen() 을 이용해 변수를 선언해준다. 지난 강의에서 배웠던 BeautifulSoup() 을 사용할려면 html 이 들어가있는 변수와 변수를 읽을때 사용할 엔진을 입력해주면 된다. 그리고 출력을 들여쓰기가 같이 나와지는 prettify()로 해준다.
 진짜 한글이 계속 깨져서 나와서 컴퓨터 설정도 바꾸고 글꼴도 바꾸고 했는데 encoding 하나로 다 고쳐졌다....
진짜 한글이 계속 깨져서 나와서 컴퓨터 설정도 바꾸고 글꼴도 바꾸고 했는데 encoding 하나로 다 고쳐졌다....
soup.find_all() 을 사용해서 span 이라는 태그가 들어간 모든 값을 찾아준다. 그중 값이 value인 데이터를 찾을려면 find_all() 의 다중조건을 이용해서 find_all("span", "value")를 이용해서 찾아준다.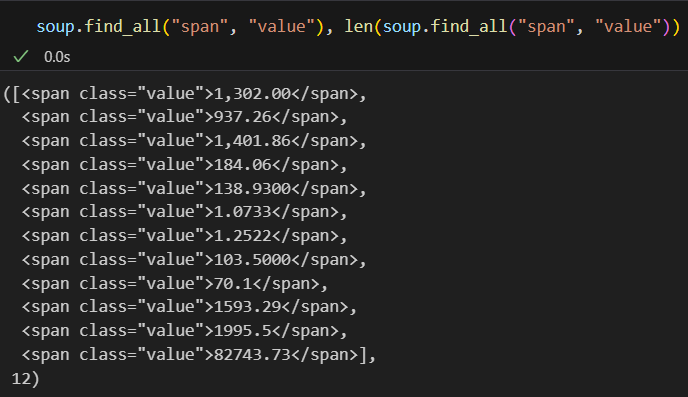
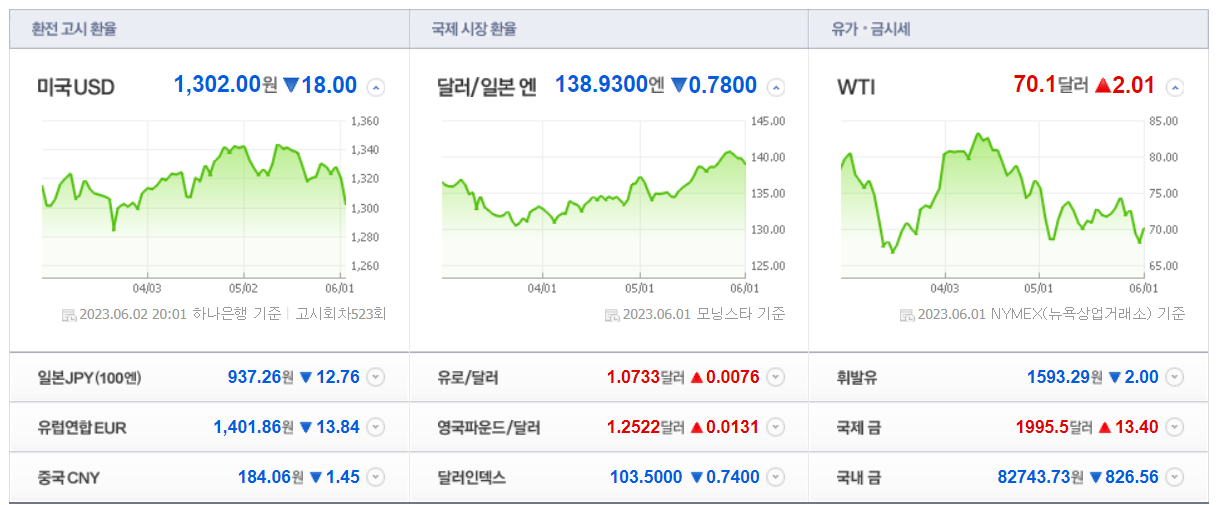 길이 총 12개의 span, value 값을 찾아냈고 화면에서도 12개의 환율, 시세값이 있는걸 알 수 있다.
길이 총 12개의 span, value 값을 찾아냈고 화면에서도 12개의 환율, 시세값이 있는걸 알 수 있다.
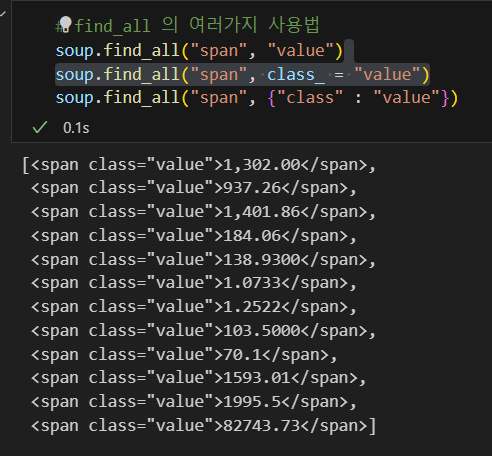 위에 있는 세가지 방법중 아무거나 써도 똑같은 값이 출력된다.
위에 있는 세가지 방법중 아무거나 써도 똑같은 값이 출력된다.
♟️request
openurl과 비슷한 requests 모듈이 있다.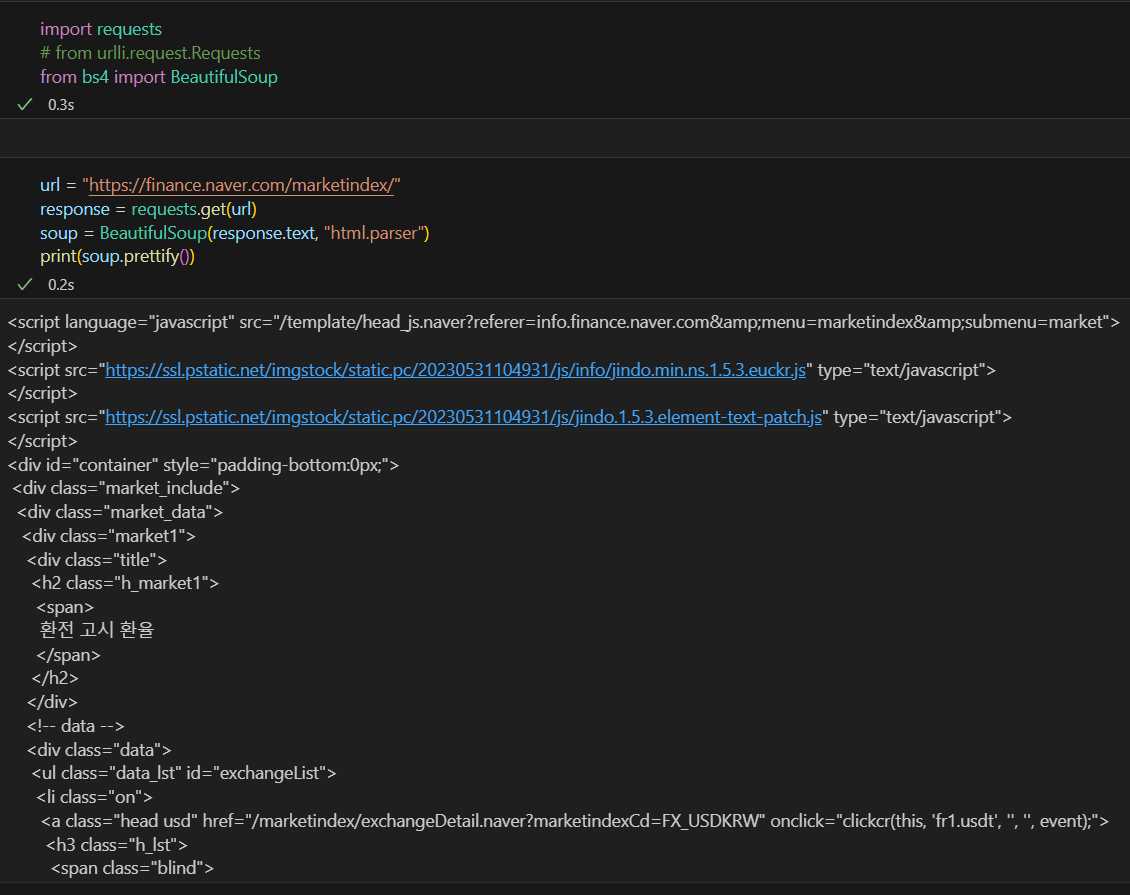 아까는 openurl()을 썻다면 이번에는 requests.get을 이용한다.
아까는 openurl()을 썻다면 이번에는 requests.get을 이용한다.
♟️select, select_one
♟️select
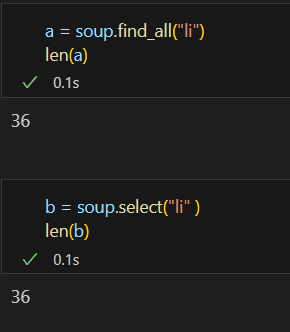
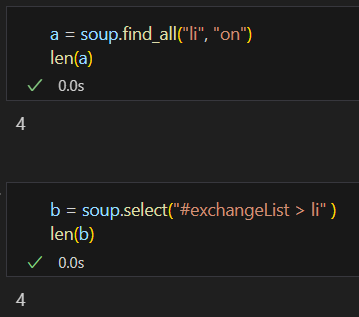
select와 find_all은 찾을려는 대상이 똑같지만 사용법은 약간씩 다르다. 특히 select에서 호출할때 class는 "."으로 붙이고 id로 호출할때는 "#"으로 한다.
♟️select_one
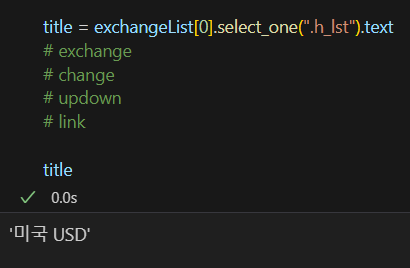 select_one도 마찬가지로 class로 태그된 걸 호출할때는 ".", id로 태그된거에는 "#"을 쓴다. 마찬가지로
select_one도 마찬가지로 class로 태그된 걸 호출할때는 ".", id로 태그된거에는 "#"을 쓴다. 마찬가지로 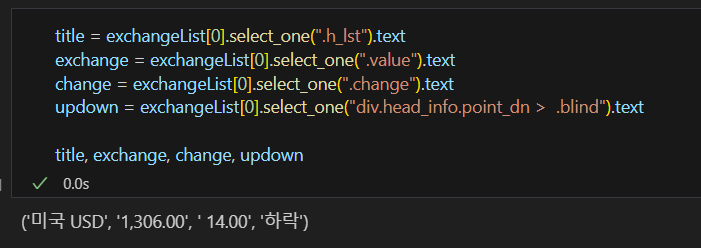 하락이라는 데이터는 가져오는 방법이 특별하다. div = class.head_info point_dn 이라는 클래스에 태그 되있는데 중간에 띄어쓰기가 있으면 두개의 클래스로 인지해서 "."으로 구분해주고 하위 태그를 위해서 ">"를 써주었다.
하락이라는 데이터는 가져오는 방법이 특별하다. div = class.head_info point_dn 이라는 클래스에 태그 되있는데 중간에 띄어쓰기가 있으면 두개의 클래스로 인지해서 "."으로 구분해주고 하위 태그를 위해서 ">"를 써주었다.
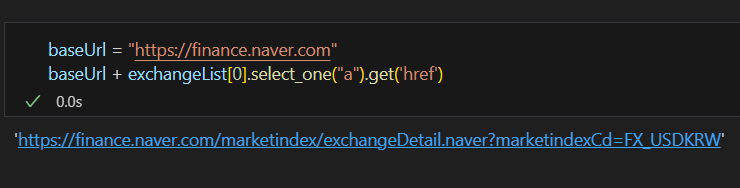 주소 같은 경우에는 .get("href")만 하면 com까지의 주소는 안나와서 베이스 주소를 하나 새로 선언해주었다.
주소 같은 경우에는 .get("href")만 하면 com까지의 주소는 안나와서 베이스 주소를 하나 새로 선언해주었다.
♟️시각화
반복문을 이용해서 위에서 사용했던 추출값들이 제대로 추출되는지 확인, 그리고 리스트 안에 넣어준다. 리스트 데이터는 데이터프레임으로 사용하기 좋기때문에 pandas를 이용해 시각화를 해준다.
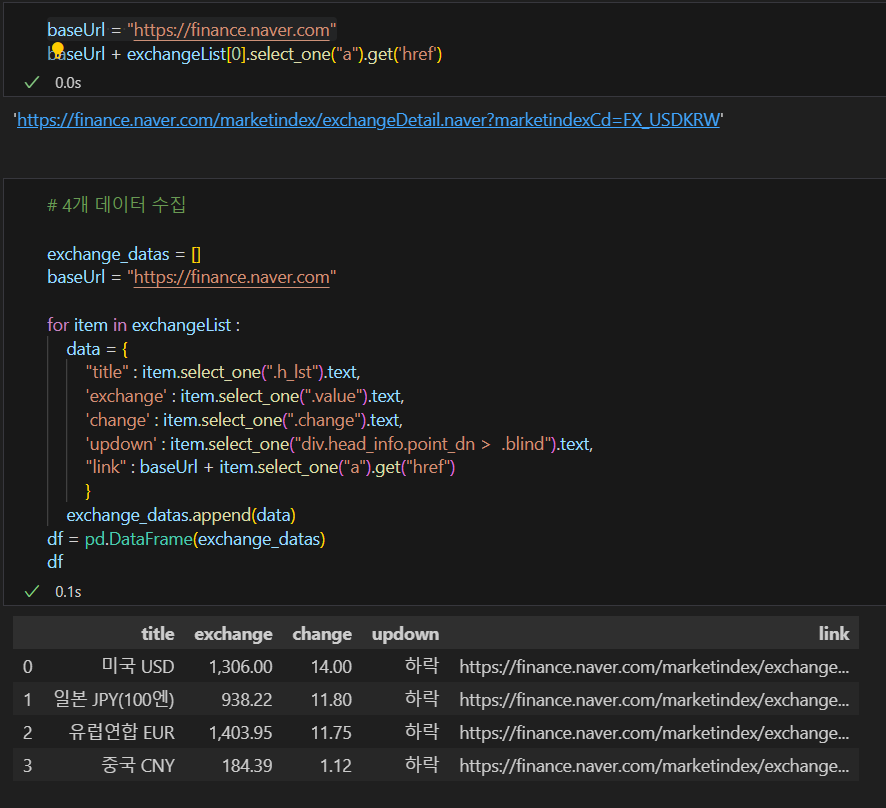
♟️오늘의 공부를 마치며
앞에서 했던 CCTV와 범죄는 그래도 할 만 했던거 같은데 beautifulSoup는 생각보다 너무 헷갈린다. 웹크롤링의 원리는 알겠는데 많이 헷갈리긴 해서 블로그로 정리하면 또 블로그를 계속 봐야할거 같다.
