딥러닝의 주요 개념
Batch Size, Epoch( 배치사이즈와 에폭)
batch와 iteration
수 많은 양의 데이터셋이 있을경우,
해당 데이터셋을 한꺼번에 메모리에 올리고 학습시키려면 엄청난 용량을 가진 메모리가 필요하고,
그 메모리를 사는데(개발하는데) 천문학적인 비용이 들게 된다.
따라서 이 데이터셋을 작은 단위로 쪼개서 학습시키게 되는데, 쪼개는 단위를 배치(Batch)라고 한다.
이때 데이터를 쪼개서 수 많은 반복을 하게되는데, 이 반복하는 과정을 iteration(이터레이션)이라고 한다.Epoch
보통 머신러닝에서는 똑같은 데이터셋을 가지고 반복학습을 하게 되는데,
만약 100번 반복 학습을 한다면 100 epochs(에폭)을 반복한다고 한다.즉, 반복 학습의 단위가 epochs이다.
batch를 몇 개로 나눠놓았는지에 상관 없이 전체 데이터셋을 한 번 돌 때 한 epoch이 끝나게 된다.
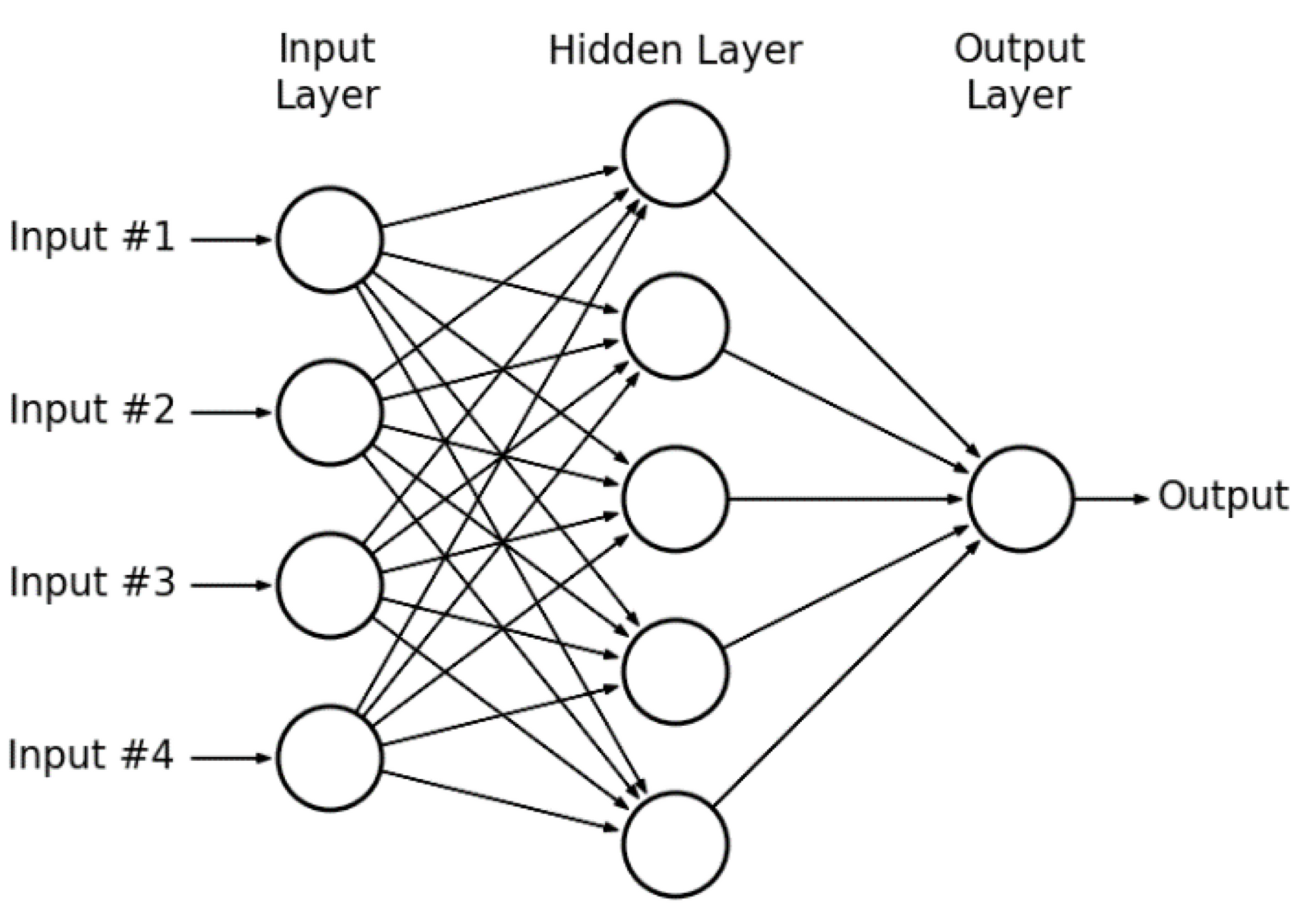
활성화 함수(Activation Function)
MLP의 연결 구조를 여러개의 뉴런이 연결된 모습과 비슷하다고 가정할 때,
수 많은 뉴런들은 서로 빠짐없이 연결되어 있다.
뉴런들은 전기 신호의 크기가 특정 임계치(Threshold)를 넘어야만 다음 뉴런으로 신호를 전달하도록 설계가 되어있는데,
이 신호전달 체계를 흉내내는 함수를 수학적으로 만들었고,
전기 신호의 임계치를 넘어야 다음 뉴런이 활성화 한다고 해서 활성화 함수라고 한다.활성화 함수는 비선형 함수여야 한다. (예, sigmoid, softMax 등)
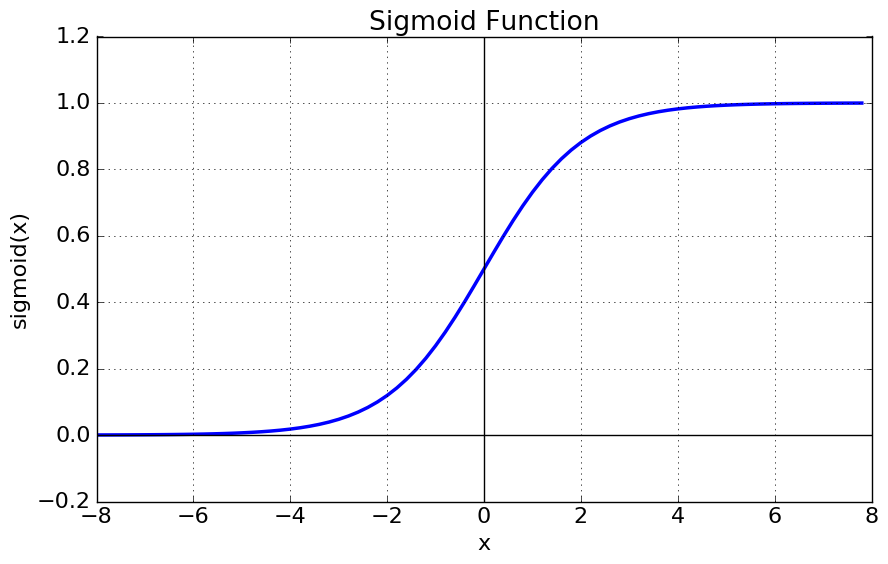
시그모이드
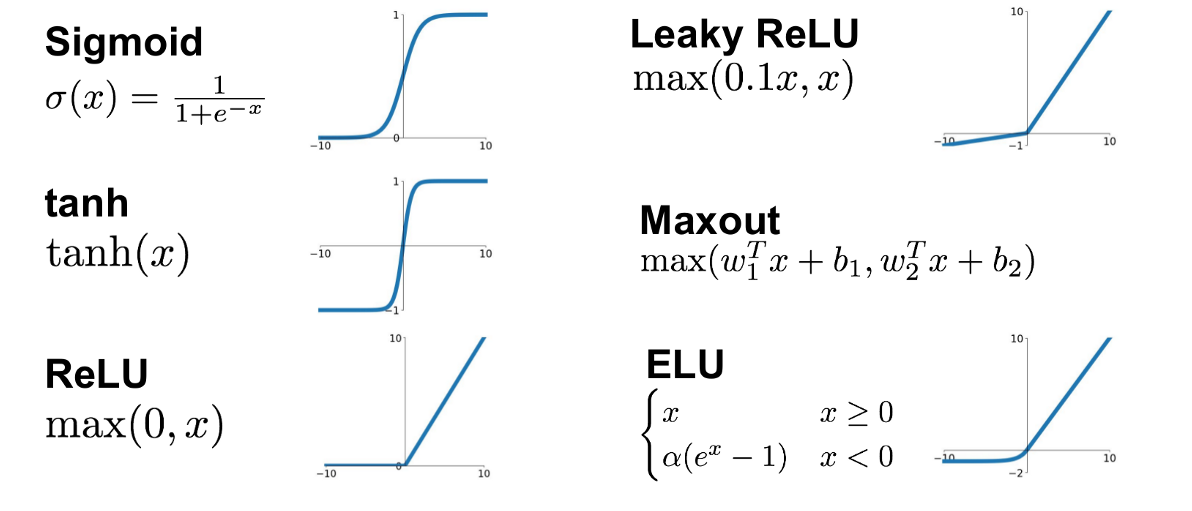
위의 그래프를 보면 x가 -6보다 작을 때, 0에 가까운 값을 출력으로 내보내서 비활성 상태로 만들고, 반대로 6보다 클때 1에 가까운 값을 출력으로 내보내서 활성화 상태로 만든다.활성화 함수에는 여러가지 종류가 있는데, 그래프를 보면 다음과 같다.
딥러닝에서는 가장 많이 보편적으로 사용되는 활성화 함수는 ReLU(렐루)를 사용한다.다른 활성화 함수에 비해 학습이 빠르고, 연산 비용이 적으며, 구현이 간단하기 때문.
대부분 딥러닝 모델을 설계할 때는 ReLU를 기본적으로 많이 쓰고, 여러 활성화 함수를 교체하는 과정 거쳐 최종적으로 정확도를 높이는 작업을 동반한다.
이러한 과정을 모델 튜닝이라고 부른다.
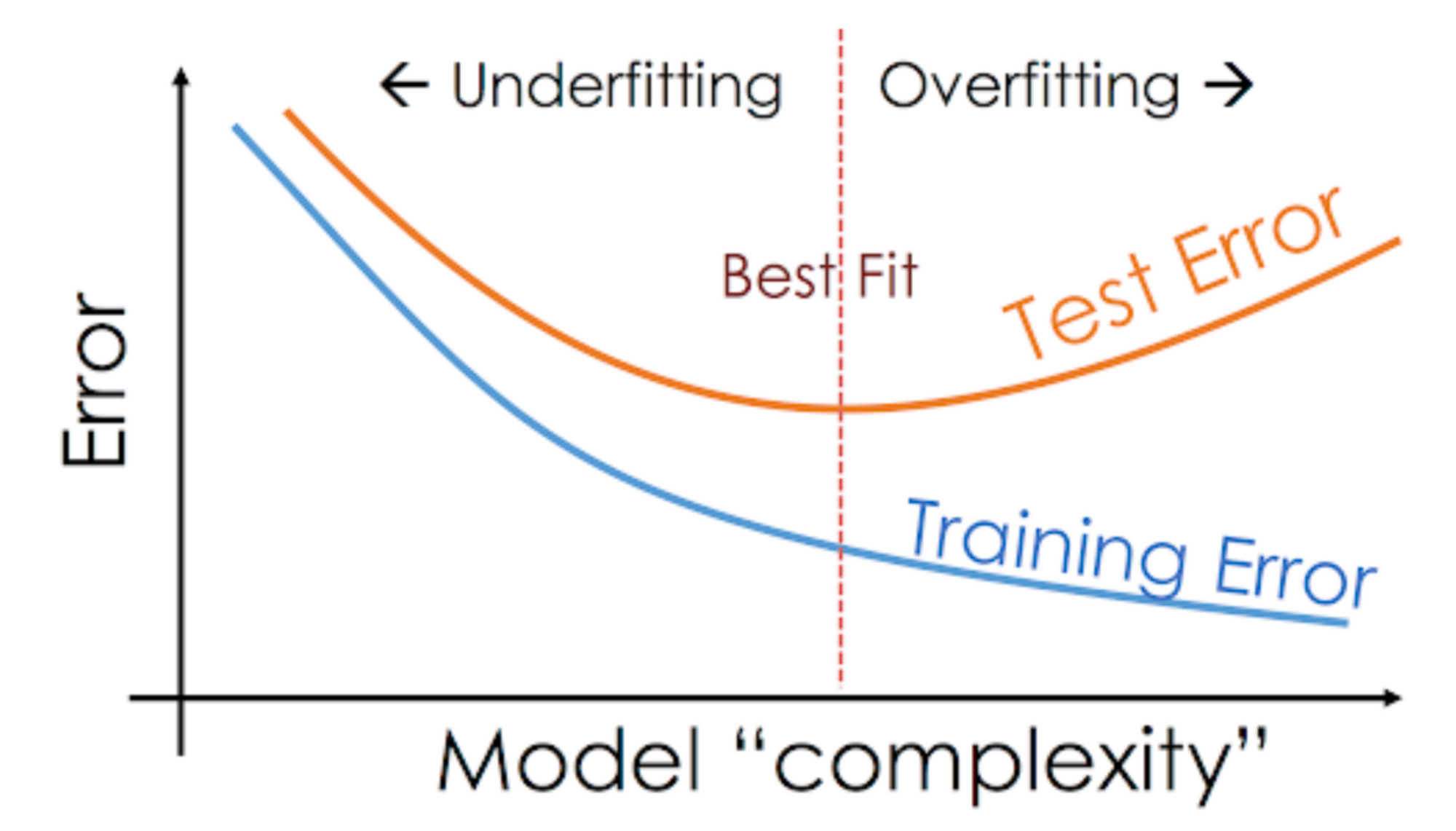
Overfitting, Underfitting (과적합, 과소적합)
[Overfitting]
딥러닝 모델을 설계/튜닝하고 학습하다 보면 가끔씩 Training loss는 점점 낮아지는데, Validation loss가 높아지는 시점이 있다.
이러한 현상을 과적합(Overfitting) 현상이라고 한다.
문제의 난이도에 비해 모델의 복잡도(Complexity)가 클 경우 가장 많이 발생하는 현상.적당한 복잡도를 가진 모델을 찾아야 하고, 수십번의 튜닝을 거쳐 최적합(Best Fit)의 모델을 찾아야 한다.
보통 과소적합보다는 과적합때문에 골치를 썩는 경우가 많은데, 과적합을 해결하는 방법에는 여러가지 방법이 있지만 대표적인 방법으로는 데이터를 더 모으기, Data augmenation, Dropout 등이 있다.