신분당선 데이터마이닝 프로젝트 3주차 기록
팀명 : 아신낭
주제 : 신분당선 시간별 수요 데이터 마이닝 프로젝트
팀장 : 아주대학교 박종일
팀원 : 아주대학교 김용찬, 아주대학교 임재환
1주차
박종일 : 데이터 수집 및 계획 + 데이터 분석(DA), 통계 정리, 데이터마이닝
김용찬 : 데이터 수집 머신러닝 기법 수립(lightgbm) , 데이터마이닝
임재환 : 데이터 수집 및 레퍼런스 참조, 데이터 마이닝
2주차
주제 구체화: 재환 - 카카오 / 용찬 - 넥슨 / 종일 - 포스코 /
출근길 커피를 들고 신입사원처럼 출근하기!
3주차
데이터 구체화!
나는 신입사원으로 절대 시각을 하지 않는 자기 관리 역량이 뛰어난 사람!
박종일 : 모델링 분석
김용찬 : 모델링 분석
임재환 : 모델링 분석
모델링은 lightgbm regressor 사용 및 데이터 전처리에 힘을 더욱 쏟음
데이터 정리 결과 구성은 아래와 같다
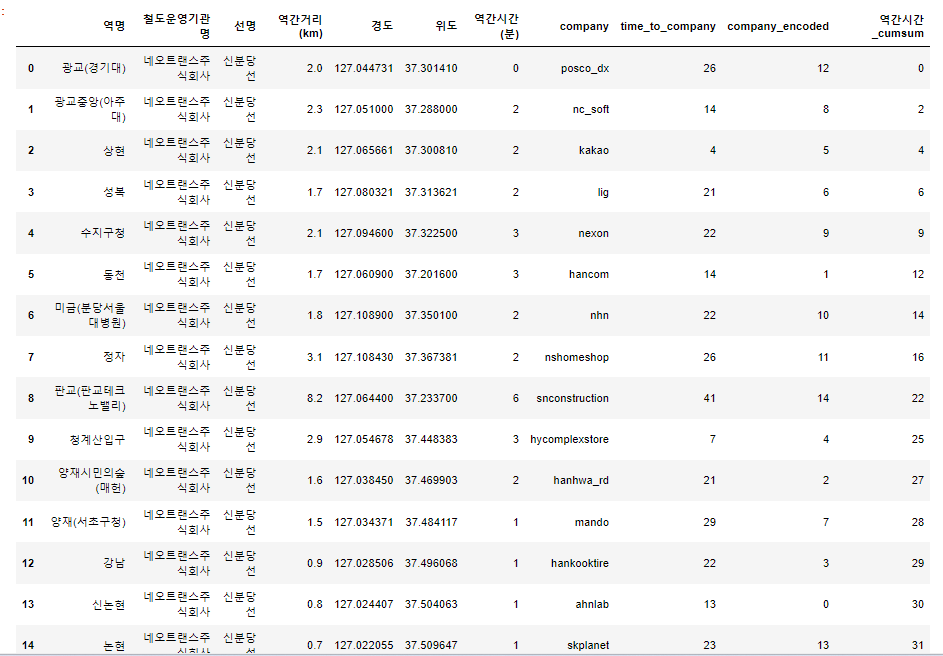
추가로 피처엔지니어링이 진행하고, 모델링 마무리하는 것을 4주차 목표로 두었다.
개인공부정리
박종일

LG aimers 4기 시계열 데이터 정리 및 공부

LG aimers 4기 해커톤 참여
import pandas as pd
import numpy as np
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
f1_score,
precision_score,
recall_score,
)
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
df_train = pd.read_csv("train.csv") # 학습용 데이터
df_test = pd.read_csv("submission.csv") # 테스트 데이터(제출파일의 데이터)
def label_encoding(series: pd.Series) -> pd.Series:
"""범주형 데이터를 시리즈 형태로 받아 숫자형 데이터로 변환합니다."""
my_dict = {}
# 모든 요소를 문자열로 변환
series = series.astype(str)
for idx, value in enumerate(sorted(series.unique())):
my_dict[value] = idx
series = series.map(my_dict)
return series
# 레이블 인코딩할 칼럼들
label_columns = [
"customer_country",
"business_subarea",
"business_area",
"business_unit",
"customer_type",
"enterprise",
"customer_job",
"inquiry_type",
"product_category",
"product_subcategory",
"product_modelname",
"customer_country.1",
"customer_position",
"response_corporate",
"expected_timeline",
]
df_all = pd.concat([df_train[label_columns], df_test[label_columns]])
for col in label_columns:
df_all[col] = label_encoding(df_all[col])
for col in label_columns:
df_train[col] = df_all.iloc[: len(df_train)][col]
df_test[col] = df_all.iloc[len(df_train) :][col]
x_train, x_val, y_train, y_val = train_test_split(
df_train.drop("is_converted", axis=1),
df_train["is_converted"],
test_size=0.2,
shuffle=True,
random_state=400,
)
model = DecisionTreeClassifier(max_depth = 16, min_samples_split=4, min_samples_leaf=2)
# 모델학습까지 베이스라인 분석 및 변형 김용찬
- 노션 정리
https://www.notion.so/a85c673465b34607b4b2a05dd720f214?pvs=4
모각소 정리
임재환
- NLP 기본 다지기
https://woghkszhf.tistory.com/78

존경하는 인물: 스토브리그 백승수 단장(남궁민)