- 네이버 주식 토론방에서 스크래핑한 본문 데이터를 토대로 형태소 분석을 진행하고, 이에 따라 워드클라우드를 생성
- 형태소 분석 라이브러리는 kkma, okt를 둘 다 사용했으며, 사용 결과, kkma 라이브러리의 결과물을 사용하기로 함
텍스트 전처리 및 워드클라우드
#---------------------------------워드 클라우드 -------------------------
from konlpy.tag import Kkma
from collections import Counter
from konlpy.tag import Okt
def text_preprocessing(text,tokenizer): #불용어 처리하는 function
stopwords = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/korean_stopwords.txt").values.tolist()
stopwords.append('n')
stopwords.append("''")
txt = re.sub('[^가-힣a-z]', ' ', text)
token = tokenizer.morphs(txt)
token = [t for t in token if t not in stopwords]
return token
kkma = Kkma() #Kkma 라이브러리 로딩
tokenizer = Okt() #Okt 라이브러리 로딩
path = 'C:/Users/apjh2/공모전/나스닥_50'
file_list = os.listdir(path) #스크래핑한 csv파일 한꺼번에 불러오기
file_list_py = [file for file in file_list if file.endswith('.csv')]
file_list = []
file_list_1 = []
for i in file_list_py: #.csv 확장자가 붙은 리스트 1개, .csv 확장자가 없는 리스트 1개를 분류, 생성
i = i.replace("'","")
for i in file_list_py:
i_1 = i.replace(".csv","")
file_list.append(i_1)
for i in file_list:
file_list_1.append(i)
for i in range(len(file_list_1)): #텍스트 형태소 분석
word_count = {}
text = [''.join(v for v in file_list_1[i]['1'])]
text_result = text[0].split(',')
nouns = kkma.nouns(str(text_result)) #kkma 패키지로 형태소 분석
nouns_1 = [x for x in nouns if len(x) > 1]
nouns_stopwords= text_preprocessing(str(nouns_1),tokenizer)
nouns_stopwords = ' '.join(nouns_stopwords)
nouns_1 = ' '.join(nouns_1)
try:
wordcloud = WordCloud(font_path='malgun', width=400, height=400, scale=2.0, max_font_size=250,mask=cloud_mask,background_color='white').generate(str(nouns_1))
except ValueError as E:
print(E)
plt.figure()
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
wordcloud.to_file(filename="C:/Users/apjh2/공모전/나스닥_50/그림//{}.png".format(file_list[i]))
[그림1: 애플 주식의 워드클라우드 생성]
감성 사전 기반 감성 분석
- 해당 분석에서는 Python은 한국어 기반의 감성 사전 라이브러리가 구축되어 있지 않아, 감성 분석은 R-studio로 진행
- 'KNU' 감성 사전을 사용하였으며, 'Konlpy', 'SentimentAnalysis', 'KnuSentiLexR', 'RcppMeCab' 라이브러리를 사용함
# 라이브러리 로딩
library(rvest)
library(stringr)
library(tibble)
library(dplyr)
library(KnuSentiLexR)
library(RcppMeCab)
library(tidytext)
library(tidyverse)
library(KoNLP)
library(remotes)
library(ggplot2)
library(readr)
library(extrafont)
useSejongDic()
setwd('c:/data/nas_csv')
filenames = list.files(pattern='csv') #nas_csv 폴더에 csv파일 로딩
filenames_1 <- gsub(".csv","",filenames)
color_palette <- c("#56B4E9","#D55E00")
pdf.options(family="Korea1deb") #PDF 저장할시 한글 폰트 깨짐 방지
for(i in 1:length(filenames)){
data = read_csv(filenames[i])
data <- data %>% mutate(id=row_number())
word_dic <- data %>% unnest_tokens(input = '1', output = word, token = RcppMeCab::pos, drop =FALSE) %>% #본문을 RcppMeCab 패키지를 이용해 형태소 분석을 하고, 일반명사만 추출함
separate(word, c("word", "pos"), sep = "/") %>% filter(pos == "nng") %>%
inner_join(dic, by = "word")```
- 'word', 'pos', 'polarity' 컬럼을 통해 어떠한 일반 명사가 -2, -1, 0, 1, 2로 감성 점수가 나왔는지 파악할 수 있음.
word_comment <- word_dic %>%
mutate(sentiment = ifelse(polarity >= 1, "긍정",
ifelse(polarity < -1, "부정","중립")))
word_comment %>% count(sentiment)
top10 <- word_comment %>% filter(sentiment != "중립") %>% count(sentiment, word)%>%
arrange(desc(n)) %>% group_by(sentiment) %>% slice_head(n=10)
png(paste0('c:/data/nas_csv/plot/',filenames_1[i],' bar plot','.png'))
barplot(table(word_comment$sentiment),main=paste(filenames_1[i],"감성분석 결과"),col=c("sky blue","red","grey"))
dev.off()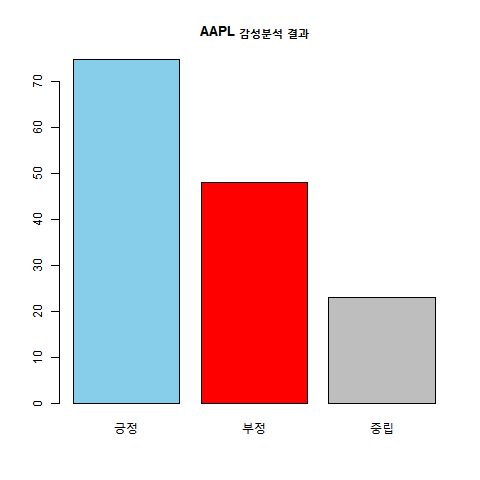
- 각 종목 토론방별로 긍정, 부정, 중립 코멘트가 몇 개나 분포하고 있는지 파악 가능.
ggplot(top10, aes(reorder(word, n), n, fill = sentiment)) +
ggtitle(paste(filenames_1[i],"감성 키워드 빈도 top 10")) +
geom_col(show.legend = TRUE, colour = "black") +
facet_wrap(~sentiment, scales = "free") +
coord_flip() +
geom_text(aes(label = n), hjust = -0.3) + labs(x = NULL) + scale_fill_manual(values = color_palette) +
scale_y_continuous(expand = expansion(mult = c(0.05, 0.15)))
ggsave(paste0('c:/data/nas_csv/plot/',filenames_1[i],' TOP 10',".pdf"))
}
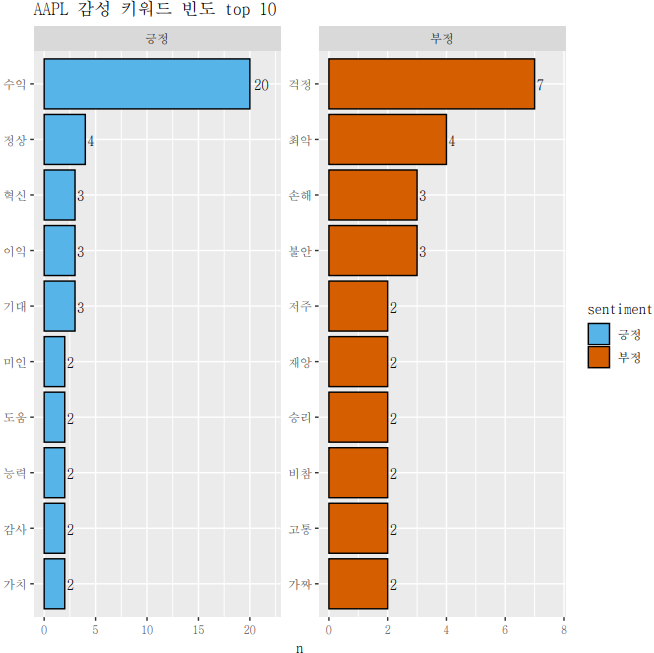
- 해당 ggplot을 통해 종목 토론방에서 어느 키워드가 많이 나왔는지 파악 가능
- 총 50개의 Top 10 plot, Bar plot이 생성되었음.

안녕하세요