KB Idea Market 디지털 공모전 - 3 시장 정보 데이터 스크래핑 및 시각화
1.시장 정보 데이터 스크래핑
- 처음에는 서울열린데이터광장에 있는 데이터를 사용하려고 하였으나, 마지막 업데이트 주기가 2020년으로 고정되어 있어 최신화가 안되어있는 상황
- 그렇기 떄문에, investing.com, ko.tradingeconomics.com 등에서 스크래핑 하기로 함
이번에는 네이버 종목토론방과는 다르게 스크래핑 하는 모든 정보들이 table 형식을 띄고 있기 때문에, html_table_parser 기능을 통해 테이블 정보를 통째로 불러오는 것으로 함
from selenium.webdriver import Chrome
import time
import os
import pandas as pd
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import datetime as dt
import urllib.request
import openpyxl
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
import subprocess
import re
from selenium.webdriver.support.ui import Select
from selenium.webdriver import ActionChains
import os, shutil
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import xlrd
import io
import sys
from html_table_parser import parser_functions as parseroptions = webdriver.ChromeOptions()
browser = webdriver.Chrome('C:/data/chromedriver.exe', options=options)
############신용등급############
browser.get('https://ko.tradingeconomics.com/country-list/rating')
html = browser.page_source
soup = BeautifulSoup(html,'html.parser')
data = soup.find_all('table')
p = parser.make2d(data[0]) #parser.make2d 기능을 통해 table을 df화
df = pd.DataFrame(p[2:],columns=p[0]) #p[0]을 컬럼으로 쓰고 두번째 데이터부터 DataFrame에 추가
df.to_csv('신용등급.csv',encoding='utf-8')| ID | Country | S&P | Moody's |
|---|---|---|---|
| 0 | Andorra | BBB | Baa2 |
| 1 | Angola | B- | B3 |
| 2 | Argentina | CCC+ | Ca |
| 3 | Armenia | B+ | Ba3 |
| 4 | Aruba | BBB | BB |
| ... | ... | ... | ... |
| 149 | Uruguay | BBB | Baa2 |
| 150 | Uzbekistan | BB- | B1 |
| 151 | Venezuela | N/A | C |
| 152 | Vietnam | BB | Ba3 |
| 153 | Zambia | SD | Ca |
########################국가별 금리#########################
df_current = pd.DataFrame()
for i in range(1,18):
table_df = pd.DataFrame()
browser.get('https://www.investing.com/central-banks/world-central-banks/{}'.format(i))
html = browser.page_source
soup = BeautifulSoup(html,'html.parser')
table = soup.find_all('table')
table = parser.make2d(table[0])
table_df = pd.DataFrame(table_1[1:])
df_current = pd.concat([table_df,df_current])
df_current.to_csv('금리.csv',encoding='utf-8-sig')해당 사이트는 신용등급 사이트와는 다르게 총 17페이지로 이루어져 있어서 동적 크롤링을 진행함.
| ID | Explanation | Interest Rate | Country |
|---|---|---|---|
| 0 | Da Afghanistan Bank\n(DAB)\nThe Afghanistan Ba... | 15% | Afghanistan |
| 1 | Bank of Albania\n(BoA)\nThe Bank of Albania is... | 0.5% | Albania |
| 2 | Bank of Algeria\nThe Bank of Algeria's mission... | 4% | Algeria |
| 3 | Central Bank of Angola\n(BNA)\nThe National Ba... | 20% | Angola |
| 4 | Central Bank of Argentina\n(BCRA)\nThe Central... | 60% | Argentina |
| 5 | Central Bank of Armenia\n(CBA)\nThe Central Ba... | 6.5% | Armenia |
| 6 | Central Bank of Aruba\n(CBA)\nThe Central Bank... | 3% | Aruba |
| 7 | Reserve Bank of Australia\n(RBA)\nThe Reserve ... | 0.10% | Australia |
| 8 | National Bank of Austria\n(OeNB)\nThe Oesterre... | 0% | Austria |
| 9 | Central Bank of Azerbaijan\n(NBA)\nThe Central... | 6.25% | Azerbaijan |
######### 시장 주식 등락 지수###########
current_df = current_df.reset_index(drop=True)
browser.get('https://ko.tradingeconomics.com/stocks')
html = browser.page_source
soup = BeautifulSoup(html,'html.parser')
table_current = soup.find_all('table')
current_df = pd.DataFrame()
for i in range(0,6):
table_current_1 = parser.make2d(table_current[i])
table_current_df = pd.DataFrame(table_current_1[1:],columns=table_current_1[0]) table_current_df.to_csv('{}.csv'.format(table_current_df.columns[1]),encoding='utf-8-sig')
t_body = soup.find_all('tbody')
list_1 = []
for i in range(len(t_body)):
flag = []
flag = t_body[i].find_all('div')
list_1.append(flag)
list_2.to_csv('flag.csv')
list_2 = pd.DataFrame(list_1)시장 주식 등락 지수는 table이 총 5개가 있어서 각각의 테이블들을 파일로 저장하였음.
- 해당 데이터들은 csv로 저장하여, ISO-6116 기준으로 한국명, 영어명, 2자리 코드를 통해 right join을 진행하여 결합하였음
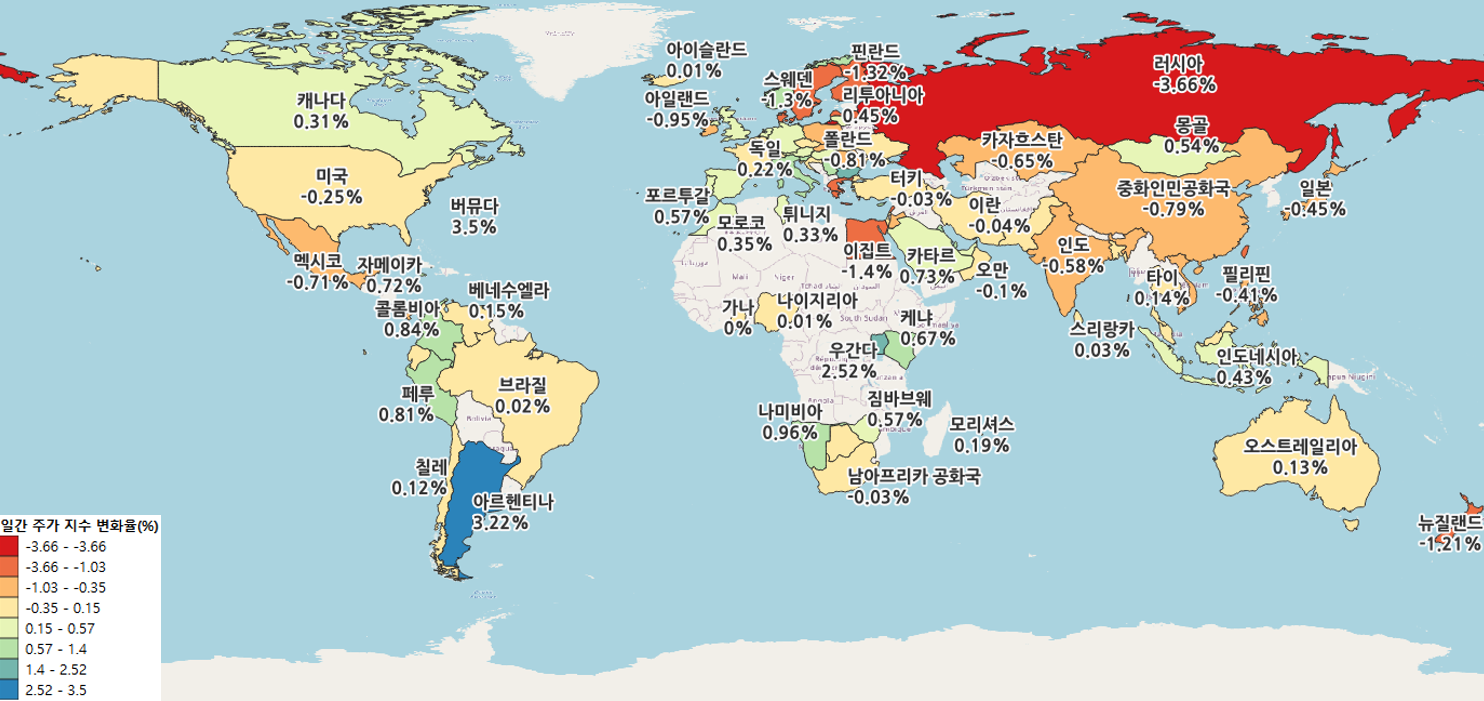
시장 지수 시각화
- 해장 시장 지수 시각화는 QGIS로 진행
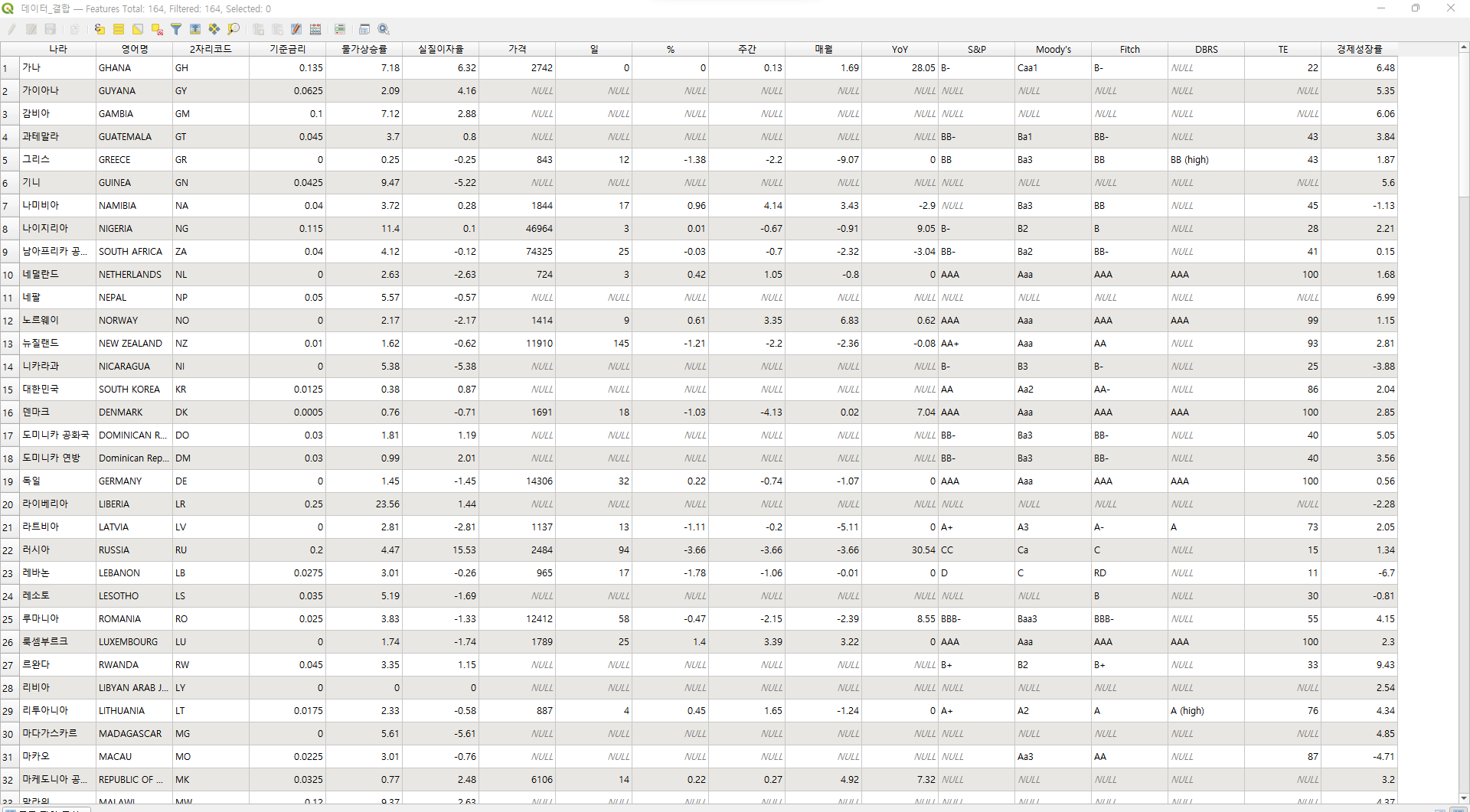
- 각각의 모든 데이터들을 결합하여 SHP 파일에 join한 결과
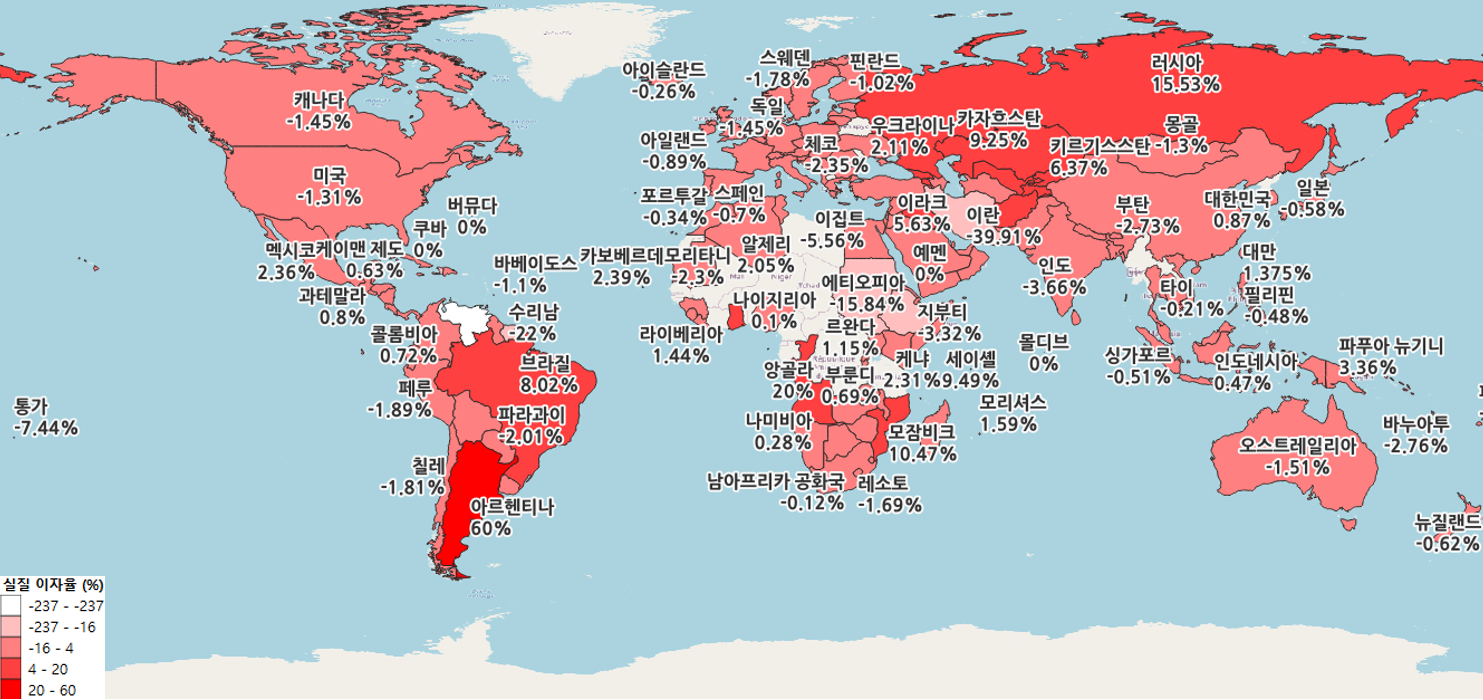
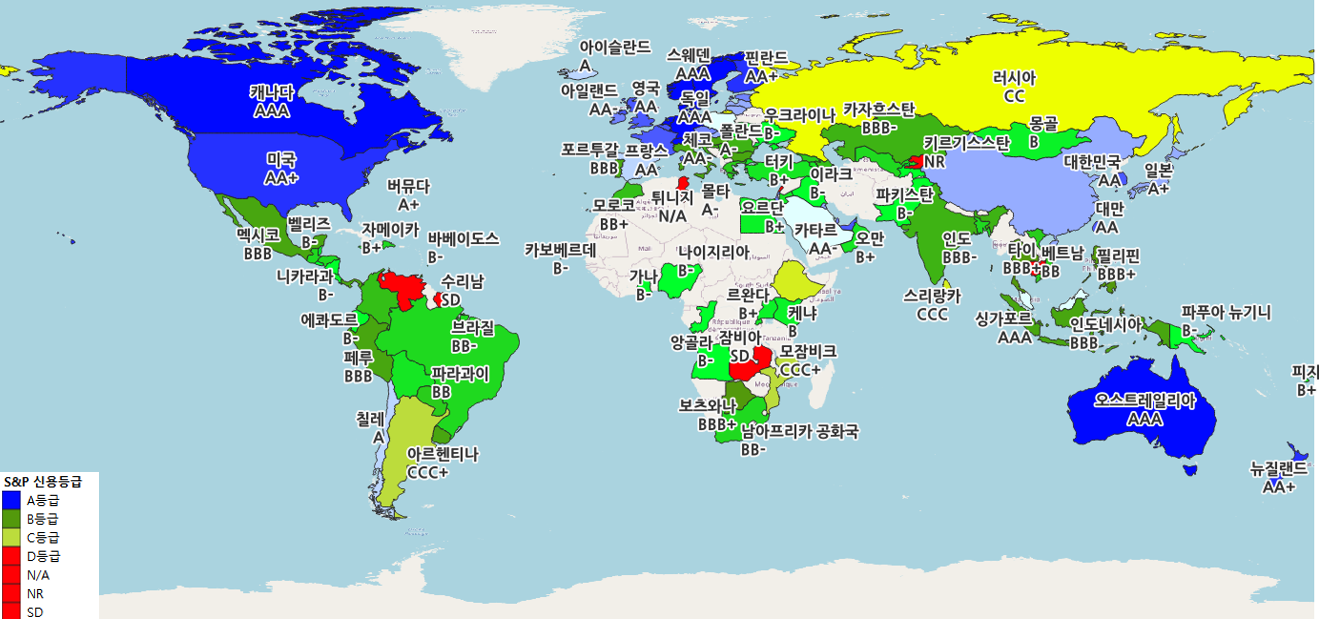
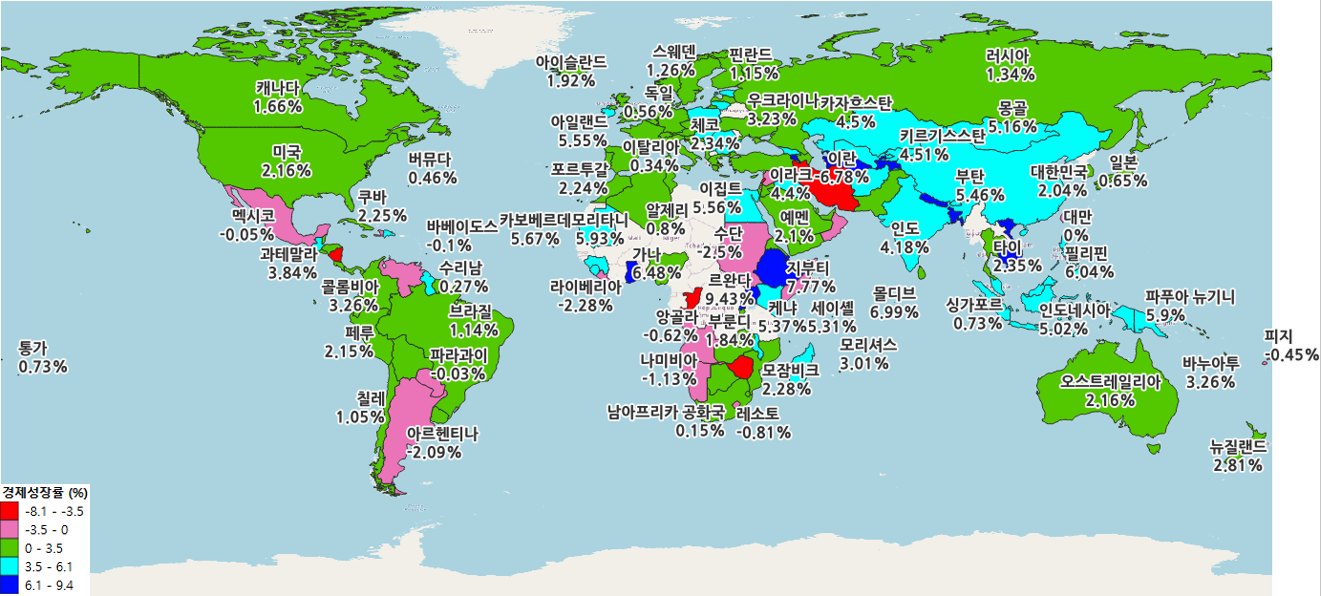

안녕하세요