Bean에 대해 설명해보세요.
**핵심 답변**
일반적으로 Java Bean은 Java로 작성된, 데이퍼 표현을 목적으로 하는 자바 클래스입니다.
클래스의 멤버 변수는 properties라고 하며 private 접근 제한자를 갖습니다.
이 properties는 getter와 setter로만 접근할 수 있고, 전달 인자(argument)가 없는
기본 생성자(Default constructor)를 갖는 형태입니다.
Java Bean 예시
public class AboutJavaBean {
// 필드는 private로 선언
private String bean;
private int beanValue;
// 전달 인자가 없는(no-argument) 생성자
public AboutJavaBean() {
}
// getter
public String getBean() {
return beanName;
}
// setter
public void setBean(String bean) {
this.bean = bean;
}
public int getBeanValue() {
return beanValue;
}
public void setBeanValue(int beanValue) {
this.beanValue = beanValue;
}
}🤔 Spring Bean이란 무엇인가요?
스프링에서 Bean은 Spring IoC 컨테이너가 관리하는 Java 객체를 의미합니다.
즉, 스프링에 의해 생성, 라이프 사이클 수행, 의존성 주입이 일어나는 객체들을 Spring Bean
이라고 합니다. 자바 빈은 Class를 생성하고 new를 입력하여 원하는 객체를 직접 생성하지만,
스프링은 ApplicationContect.getBean()와 같은 메서드를 사용해 스프링으로부터 직접
자가 객체를 얻어서 사용합니다.
🤔 스프링 Bean의 생성 과정을 설명해주세요.
1.자바 어노테이션(Java Annotation)을 사용하는 방법
Bean을 등록하기 위해 @Component 어노테이션을 사용합니다.
이 어노테이션이 등록되어 있는 경우 스프링이 이를 확인하고 자체적으로 Bean을 등록합니다.
@Component, @Controller, @Service, @Entity등의 어노테이션이
내부적으로 @Component 어노테이션을 사용하는 예시입니다.
2.Bean Configuration File에 직접 Bean을 등록하는 방법
@Configuration과 @Bean 어노테이션을 이용해 Bean을 직접 등록할 수도 있습니다.
먼저 @Configuration을 이용해 Spring Project에서 Configuration역할을 하는
Class를 지정합니다. 그리고 해당 File 하위에 Bean으로 등록하고자 하는 Class에
@Bean 어노테이션을 지정하면 Bean을 등록할 수 있습니다.
@Configuration
public class HelloConfiguration {
@Bean
public HelloController sampleController() {
return new SampleController;
}
}🤔 스프링 Bean의 Scope에 대해서 설명해주세요.
스프링은 빈으로 객체를 만들고 싱글톤화 시켜서 관리합니다. 싱글톤이란 기본 스코프로,
스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프를 말합니다.
여기에서 알 수 있듯이 스코프란 빈이 관리되는 범위를 말합니다. 스프링은 싱글톤 스코프
외에도 프로토 타입 빈의 생성과 DI까지만 관여하는 매우 짧은 프로토타입 스코프도 갖고 있습니다.
또한 웹 관련 스코프로 웹 요청이 들어오고 나갈때까지 유지되는 request scope,
웹 세션이 생성되고 종료될 때까지 유지되는 session scope,
웹의 서블릿 컨텍스트와 같은 범위로 유지되는 application scope가 있습니다.
🤔 Bean/Component 어노테이션에 대해서 설명해주시고, 둘의 차이점에 대해 설명해주세요.
@Bean 어노테이션은 개발자가 컨트롤을 할 수 없는 외부 라이브러리들을 bean으로 등록하고
싶을 때 사용하는 어노테이션입니다. 예를 들어 Spring Security에서 제공하는
PasswordEncoder는 외부 클래스(라이브러리)이기 때문에 사용하기 위해서 bean
어노테이션을 사용합니다.
@Bean
public PasswordEncoder passwordEncoder(){
return new BCryptPasswordEncoder();
}@Component는 반대로 개발자가 직접 만들어 컨트롤할 수 있는 Class의 경우에 사용합니다.
@Component
@RequiredArgsConstructor
public class CustomAuthManager implements AuthenticationManager{
}Getter와 Setter를 사용해야하는 이유에 대해서 설명해주세요.
**핵심 답변**
Setter를 사용하는 이유는 변수에 임의로 접근하여 잘못된 기본 값을 대입함으로써 에러를
발생시키는 상황을 막기 위해서 입니다.
Getter를 사용하는 이유는 은닉성 때문입니다.
변수 중에서 다른 사람들이 필요로하는 최소한의 주요 변수만을 getter를 통해 드러내고
나머지는 private 처리를 해서 해당 클래스 안에서만 노출되게 해줍니다.
이렇게 Getter/Setter를 사용함으로써 데이터의 정확성과 일관성을 유지하고 보증하는
무결성을 갖게 됩니다.
Spring에서 데이터를 받는 방식(과정)과 종류에 대해서 설명해주세요.
**핵심 답변**
1.정적 컨텐츠: 파일을 그대로 웹 브라우저에 전달하는 방식입니다. 예를 들어 웹 브라우저에서
hello.html을 요청하면 tomcat 내장 서버는 이 요청을 스프링에게 알립니다.
스프링은 컨트롤러에 우선권을 주어 hello라는 메서드를 찾는데, 이 메서드가 있으면 실행하고
없으면 resource/static에 있는 hello.html파일을 찾아 서버에 전달합니다.
정적 컨텐츠이기 때문에 동적인 프로그래밍은 불가하다는 단점이 있습니다.
2.MVC와 템플릿 엔진: hello-mvc라는 요청이 들어오면 tomcat 내장 서버는 스프링 컨테이너
에게 알립니다. helloController에 hello-mvc라는 메서드가 있으면 이를 실행합니다.
<HelloController.java>
@GetMapping("hello-mvc")
public String helloMvc(@RequestParam("name") String name, Model model) {
model.addAttribute("name", name);
return "hello-template";
}<hello-template.html>
<html xmlns:th="http://www.thymeleaf.org">
<body>
<p th:text="'hello ' + ${name}">hello! empty</p>
</body>
</html>위와 같이 hello-mvc에서 model에 name이라는 키와 value값을 넘겨주면 viewResolver에서
템플릿 엔진을 사용해 hello-template에 있는 name이라는 키를 요청 키 value값으로 변환해
웹 브라우저에 전달합니다. 정적 컨텐츠와 달리 동적 프로그래밍이 가능해집니다.
3.API: API는 json형태로 데이터를 바로 받습니다. @ResponseBody라는 태그를 이용합니다.
웹 브라우저에서 hello-api를 요청하면 tomcat 내장 서버가 스프링 컨테이너에 알립니다.
HelloController에서 hello-api 메서드가 있는지 확인하고, @ResponseBody라는
어노테이션이 있다면 HttpMessageConverter로 전달해 json 형태로 데이터를 변환하여 전달해 줍니다.
Spring에서 예외처리하는 방법에 대해서 설명해주세요.
**핵심 답변**
프로그램이 처리되는 동안 특정 문제가 발생 했을 때 처리를 중단하고 다른 처리를 하는 것을
예외 처리라고 합니다. 스프링에서는 아래 3가지 방법으로 예외 처리를 하고 있습니다.
1.Method level - try/catch를 사용
2.Controller level - @ExceptionHandler를 이용
3.Global level - controller 이후 Client에게 전달되기 직전 처리 @ControllerAdvice이용
🤔 Spring Boot의 예외처리의 내부 구현은 어떻게 되어 있나요?
DTO를 사용하는 이유?**
**핵심 답변**
1.Entity 내부 구현을 캡슐화 할 수 있다.
Entity는 도메인의 핵심 로직과 속성을 가지며, 실제 DB의 테이블과 매칭되는 클래스입니다.
따라서 엔티티가 getter와 setter를 갖게 된다면 보안상 문제가 발생할 수 있고,
비즈니스 로직과 크게 상관 없는 곳에서 리소스의 속성이 실수로라도 변경될 가능성이 있습니다.
따라서 이를 방지하고자 Entity는 내부 구현을 캡슐화 하고, DTO를 사용하여 데이터 전달
역할만을 맡기면 됩니다.
2.화면에 필요한 데이터를 선별할 수 있다.
애플리케이션이 확장되면 엔티티의 크기는 점차 커지며, view단도 다양해지며 API 스펙도
더 많아질 것입니다. 이때 request/response를 엔티티로 보내면 엔티티의 모든 속성이
함께 전송되기 때문에 속도가 느려집니다. 따라서 특정 API에 필요한 데이터를 포함해
DTO를 만들면 화면에서 요구하는 데이터만 선별하여 request/response할 수 있습니다.
3.순환참조를 예방할 수 있다.
양방향 참조된 엔티티를 컨트롤러에서 response로 return하게 되면, 엔티티가 참조하고 있는
객체는 지연 로딩 되고, 로딩된 객체는 또 다시 본인이 참조하고 있는 객체를 호출하는 순환참조의
문제를 낳습니다. 따라서 이를 방지하기 위해 return으로 DTO를 두는 것이 더 안전합니다.
4.validation 코드와 모델링 코드를 분리할 수 있다.
엔티티 클래스는 db 테이블과 매칭되는 필드가 속성으로 선언되어 있고, 비즈니스 로직도 복잡합니다.
따라서 속성에 모델링을 위해 @Column, @JoinColumn, @ManyToOne, @OneToOne
등의 코드가 추가됩니다. 이때 @NotNull, @NotEmpty, @NotBlank같은 요청에 대한
validation 코드가 들어가면 엔티티 코드가 더 복잡해질 것입니다. 따라서 validation을
DTO에서 정의하면 엔티티는 모델링과 비즈니스 로직에 집중할 수 있도록 할 수 있습니다.
🤔 DAO와 DTO의 차이를 설명해주세요
Data Access Object는 실제로 DB에 접근을 하기 위해 생성하는 객체이고,
Data Transfer Object는 데이터 교환을 위해 사용하는 객체로, DB의 데이터를 controller 혹은 service로 보낼 때 사용합니다.
Filter와 Interceptor 차이
**핵심 답변**
필터와 인터셉터는 모두 공통적으로 처리해야 하는 일들(ex.로그인 관련 세션 처리, 권한 체크,
XSS 방어 등)을 처리하는 역할을 합니다.
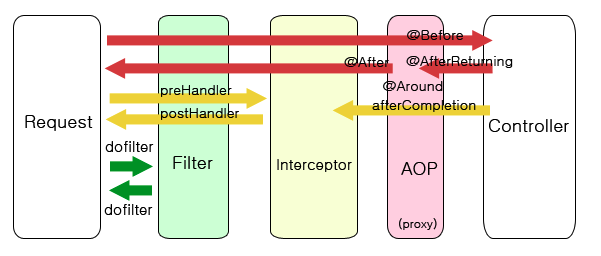
필터는 디스패처 서블릿(Dispatcher Servlet)에 요청이 전달되기 전/후에 url 패턴에 맞는 모든 요청에 대해
부가작업을 처리할 수 있는 기능을 제공해줍니다.
반면 인터셉터는 Spring이 제공하는 기술로써, 디스패처 서블릿(Dispatcher Servlet)이 컨트롤러를 호출하기
전과 후에 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공합니다.
즉 필터는 웹 컨테이너에서, 인터셉터는 스프링 컨테이너에서 동작한다는 차이가 있습니다.
| 대상 | 필터(Filter) | 인터셉터(interceptor) |
| --- | --- | --- |
| 동작 | 웹 컨테이너 | 스프링 컨테이너 |
| Request/Response 조작 가능 여부 | O | X |
| 용도 | ①보안 관련 공통 작업 ②모든 요청에 대한 로깅 및 감사 ③이미지,데이터 압축 및 문자열 인코딩 | ①인증,인가 공통작업 ②Controller로 넘겨주는 정보 가공 ③API 호출에 대한 로깅 또는 감사 |
🤔 Filter는 Servlet의 스펙이고, Interceptor는 Spring MVC의 스펙입니다. Spring Application에서 Filter와 Interceptor를 통해 예외를 처리할 경우 어떻게 해야 할까요?
동작 대상이 다르기 때문에 필터는 예외가 발생하면 Web Application에서 처리해야 합니다.
선언이나 필터 내에서 request.getRequestDispatcher(String)과 같이
예외 처리 할 수 있습니다.
반면 인터셉터는 스프링의 ServletDispatcher내부에 있으므로 @ConstrollerAdvice에서 @ExceptionHandler를 사용해 예외처리 할 수 있습니다.
Spring Application을 구동할 때 메서드를 실행시키는 방법에 대해 설명해주세요.
**핵심 답변**
JPA
JPA란?
**핵심 답변**
JPA에는 '자바 ORM 표준'이라는 수식어가 붙습니다. ORM은 객체 관계 매핑의 약자로,
객체는 객체대로 설계하고, 관계형 DB는 관계형 DB대로 설계한 후 ORM 프레임워크가
중간에서 매핑해준다는 의미입니다.
JPA(Java Persistence API)는 Java 진영에서 ORM 기술 표준으로 사용하는
인터페이스의 모음입니다. Hibernate, OpenJPA등이 JPA를 구현합니다.
🤔 JPA를 사용할 때의 이점에 대해서 설명해주세요.
1.생산성: 자바 컬렉션에 저장하듯이 JPA에 저장할 객체를 전달하면 되므로 반복적인 코드를
개발자가 직접 작성하지 않아도 되기 때문에 객체 설계 중심의 개발이 가능합니다.
2.유지보수: 필드 추가시 필요한 SQL 및 JDBC 코드를 JPA가 대신 처리해주어 개발자가 직접
유지보수를 해야 할 필요성이 줄어듭니다.
3.패러다임 불일치 해결: JPA는 연관된 객체를 사용하는 시점에 SQL을 전달하고,
같은 트랜잭션 내에서 조회할 때 동일성도 보장해 주어 다양한 패러다임 불일치를 해결합니다.
4.성능 최적화: 같은 트랜잭션 안에서 같은 엔티티를 반환해 DB와의 통신 횟수를 줄여줍니다.
또한 트랜잭션을 commit하기 전까지 쓰기 지연 메모리에 쌓아주었다가 한번에 SQL을 전송해 성능이 최적화 됩니다.
5.데이터 접근 추상화와 벤더 독립성: 관계형 DB는 벤더마다 사용법이 달라 처음 선택한 DB에
종속되는 문제가 발생합니다. JPA를 사용하면 Application과 DB 사이에서 추상화된 데이터 접근을
제공하기 때문에 종속이 되지 않도록 합니다.
🤔 JPA 영속성 컨텍스트의 이점(5가지)를 설명해주세요.
영속성 컨텍스트는 엔티티를 영구 저장하는 환경이라는 뜻입니다. em.persist()를 통해
객체를 저장하는 시점부터 영속성 컨텍스트에 관리되는 상태가 됩니다.
1.1차 캐시
영속성 컨텍스트의 관리되는 상태가 되면 DB에 바로 저장하는 것이 아니라 영속성 컨텍스트에
의해 관리되고, 1차 캐시에서 조회가 가능합니다. 만약 DB에는 저장되어 있지만 1차 캐시에는
데이터가 없다면 DB에서 조회해 가져온 뒤 1차 캐시에 저장하고 그 엔티티를 반환합니다.
2.동일성 보장
영속성 컨텍스트에서 관리되는 엔티티를 가져왔을 경우 동일성을 보장합니다.
3.트랜잭션을 지원하는 쓰기 지연(Transaction write-behind)
트랜잭션 commit 전까지 SQL을 쓰기 지연 메모리에 쌓아두었다가 commit시 한번에 전송해 통신 횟수를
줄여 성능을 최적화 합니다.
4.변경 감지(Dirty Checking)
1차 캐시에 들어온 데이터를 스냅샷합니다. commit되는 시점에 엔티티와 스냅샷을 비교해
변경이 일어나면 이를 감지합니다.
5.지연 로딩
엔티티에서 해당 엔티티를 불러올 때 SQL을 날려 해당 데이터를 가져옵니다.
🤔 JPA에서 N + 1 문제가 발생하는 이유와 이를 해결하는 방법을 설명해주세요.
N + 1 문제는 1번 조회해야 할 데이터를 N개 종류의 데이터 각각 추가로 조회하게 되는 문제입니다.
문제는 N에 들어갈 숫자가 무한히 커지는 경우입니다. 이렇게 되면 성능에 큰 영향을 줄 수 있기 때문입니다.
이 문제는 JPA의 프록시로 인한 지연 로딩 때문에 발생 합니다.
해결 방법으로는
1.Fetch Join
2.FetchType을 LAZY에서 EAGER로 변경
3.@EntityGraph 사용
참고 블로그
🤔 JPA를 사용할 때 쿼리를 사용하는 방법에 대해서 설명해주세요.
Spring Data JPA에서 정해놓은 네이밍 컨벤션을 지키면 JPA가 해당 메서드를 분석해 적절하게 JPQL을 구성합니다.
대표적인 키워드로는 And, Or, Is, Equal, Between, LessThan, After, Before, IsNull
OrderBy, Not 등이 있습니다.
| Keyword | Sample | JPQL snippet |
| --- | --- | --- |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
공식문서
