서문
안녕하세요. 마이다스인에서 인재 채용 플랫폼 잡다의 웹 프론트엔드 개발을 담당하고 있는 배준형입니다.
잡다는 채용 플랫폼 중에서 인지도가 낮은 편에 속한다고 생각합니다. 이에 잡다 플랫폼의 사용 비중을 늘리기 위해서는 서비스에서 제공하는 기능도 중요하지만 구글이나 네이버에서 관련 내용을 검색했을 때 잡다가 상위에 노출될수록 인지도가 점점 증가할 것이라 생각하는데요. 이를 위해서는 검색 엔진 최적화(SEO)가 필수적으로 선행되어야 할 것입니다.
그런 측면에서 잡다의 검색 엔진 최적화(SEO)는 제대로 이루어지지 않고 있었는데요. 이를 개선하는 과정을 공유하고자 합니다.
Google 검색 작동 방식
먼저 구글에서의 잡다 페이지 SEO를 개선하고 싶습니다. 구글이 검색 결과 페이지를 구성하는 방식, 웹사이트를 구글에 노출시키는 방법은 무엇일까요?
구글 검색은 아래 세 단계로 작동합니다.
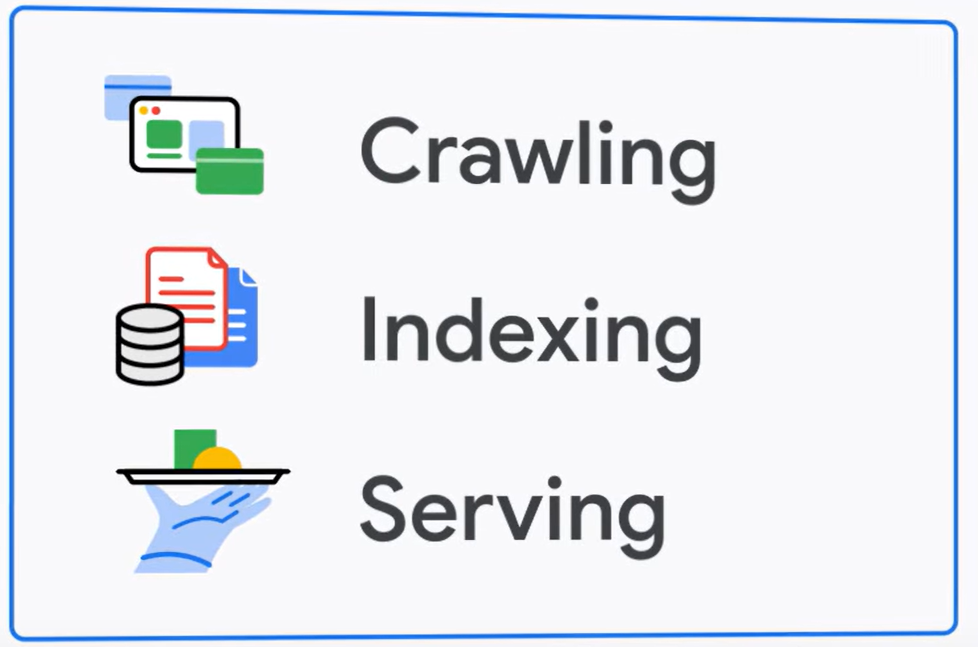 이미지 출처: https://www.youtube.com/watch?list=PLKoqnv2vTMUN83JWBNM6MoBuBcyqhFNY3&v=5MIAugQ17ks
이미지 출처: https://www.youtube.com/watch?list=PLKoqnv2vTMUN83JWBNM6MoBuBcyqhFNY3&v=5MIAugQ17ks
크롤링(Crawling)
구글이 검색 결과에 웹페이지를 띄우려면 해당 페이지가 실제로 존재하는지 알아야 합니다. 이를 위해 웹 크롤러가 인터넷을 탐색하여 새로운 웹페이지를 발견하고 수집하는 과정을 크롤링이라고 합니다.
- 웹 크롤러: 구글봇(Googlebot)이라고 불리는 구글의 웹 크롤러가 웹사이트의 링크를 따라가면서 새로운 페이지를 찾아냅니다.
- 단, 구글봇은 공개적으로 액세스할 수 있는 URL만 크롤링합니다.(로그인이 필요한 사이트는 크롤링 X)
- 사이트맵: 웹사이트의 페이지 URL을 모아둔 파일입니다.
- 대체로 XML 파일을 사용합니다.
- 사이트맵을 통해 구글에게 웹사이트 구조를 알릴 수 있고, 이를 통해 크롤러가 사이트를 더 효율적으로 탐색하도록 도와줍니다.
색인(Indexing)
페이지를 크롤링하면 해당 페이지의 내용을 알아야 합니다. 색인은 수집된 웹페이지 데이터를 분석하고 저장하는 과정입니다.
- 분석: 크롤러가 수집한 페이지는 구글의 인덱싱 시스템에 의해 분석됩니다. 여기에는 텍스트, 이미지, 비디오 등의 다양한 콘텐츠 유형이 포함됩니다.
- 메타데이터: 페이지의 제목, 설명, 키워드 등의 메타데이터도 인덱스에 저장됩니다.
- 표준 페이지(Canonical Version): 색인 생성 프로세스 중 페이지가 인터넷에 있는 다른 페이지와 중복되는지 아니면 표준 페이지인지 판단합니다.
- 표준 페이지는 검색 결과에 표시될 수 있는 페이지입니다.
서빙(Serving)
서빙은 사용자가 검색어를 입력했을 때, 구글이 생성된 색인에서 관련성이 높은 검색 결과를 제공하는 과정입니다.
- 검색어 해석: 검색어를 정리한 다음 특정 단어를 확인한 후에 이를 색인으로 보냅니다.
- 예시: 달의 사진 →
의를 제거하고 달, 사진만 남깁니다. - 예시: 자유의 여신상 → 여기서
의는 제거하지 않고,자유의 여신상을 하나의 독립적인 개체로 처리합니다.
- 예시: 달의 사진 →
- 랭킹: 페이지의 순위를 결정하는 요소에 따라 검색 결과가 달라집니다.
- 페이지의 실제 콘텐츠가 가장 중요합니다.
- 사용자 위치, 언어, 기기 유형에 따라서도 랭킹이 달라집니다.
Google 검색 엔진 최적화 시도
위의 내용을 봤을 때 시도할 수 있는 최적화 방법으로는 크롤링에 필요한 사이트맵 제공 / 색인에 필요한 적절한 meta tag / 이미지, 비디오 등의 대체 텍스트 부여 / 표준 페이지 지정 등의 방법을 사용할 수 있을 것으로 보입니다.
구글에서 검색 엔진 최적화를 할 때 Google Search Console을 이용할 수 있습니다.
사이트맵 제공
사이트맵은 사이트에 있는 페이지, 동영상 및 기타 파일과 각 관계에 관한 정보를 제공하는 파일입니다. 사이트맵이 없더라도 페이지가 제대로 링크되어 있다면 대부분의 사이트를 찾을 수 있지만, 사이트맵을 사용하면 크롤링을 개선할 수 있습니다.
사이트맵을 만드는 방법은 XML, RSS, mRSS, Atom 1.0, 텍스트 사이트맵 방식이 있는데, 가장 흔히 사용하는 방식은 XML 파일입니다.
sitemap.xml
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.example.com/foo.html</loc>
<lastmod>2022-06-04</lastmod>
</url>
</urlset><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">: 사이트맵 파일의 루트 요소입니다.xmlns속성은 이 문서가 사이트맵 프로토콜 버전 0.9를 따르고 있음을 명시합니다.<url>: 각 URL을 정의하는 요소입니다. 사이트맵 파일 안에 여러 개의<url>요소를 포함할 수 있습니다.<loc>: 페이지의 URL을 나타내는 요소입니다. 예를 들어,https://www.example.com/foo.html은 사이트의 특정 페이지를 가리킵니다.<lastmod>: 해당 URL의 마지막 수정 날짜를 나타내는 요소입니다.2022-06-04는 이 페이지가 마지막으로 수정된 날짜입니다.
Next.js에서 Sitemap 생성하기
잡다 서비스의 프론트에선 Next.js와 Pages Router를 사용합니다. 사이트 크기가 작은 경우 매뉴얼로 sitemap.xml 파일을 생성할 수도 있는데요. 그렇게 관리하기엔 잡다에서 사용 중인 페이지가 많아서 자동으로 생성되도록 만들 필요가 있었습니다. 이럴 때 next-sitemap 패키지를 사용하면 쉽게 사이트맵을 생성할 수 있습니다.
Terminal
$ yarn add next-sitemap설치가 완료되면 next-sitemap.config.js를 프로젝트 루트 폴더에 생성해줍니다.
next-sitemap.config.js
/** @type {import('next-sitemap').IConfig} */
module.exports = {
siteUrl: 'https://example.com',
generateRobotsTxt: true,
};/** @type {import('next-sitemap').IConfig} */: 파일 상단에 JSDoc 주석을 달아놓으면 자동완성 기능을 활용할 수 있습니다.siteUrl: 사이트의 URLgenerateRobotsTxt:robots.txt파일을 생성하고 생성된 사이트맵을 나열합니다.
이외에도 더 많은 옵션이 있으니 필요에 따라 옵션을 설정해주면 됩니다.
저는 sitemap이 빌드 시마다 생성되었으면 좋겠습니다. 그래서 package.json에서 scripts에 postbuild 키워드에 next-sitemap 스크립트를 추가해줍니다.
package.json
{
// ...
"scripts": {
"dev": "next dev",
"build": "next build",
"postbuild": "next-sitemap", // next-sitemap 스크립트를 추가합니다.
// ...
}- postbuild는 build 이후 실행되는데, 관련 내용은 npm Docs에서 확인할 수 있습니다.
이후 build 키워드를 통해 sitemap이 잘 생성되는지 확인해봅시다.
Terminal
$ yarn build
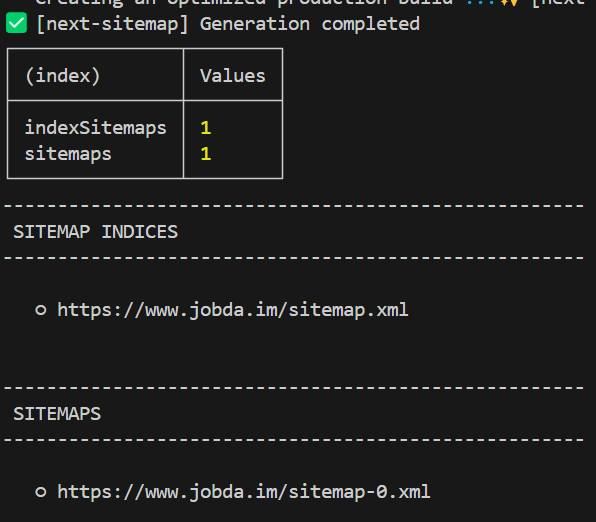 그림 2. next-sitemap 실행 후 결과
그림 2. next-sitemap 실행 후 결과
그러면, Build 이후에 위와 같이 Sitemap 생성이 완료되고, public 폴더에 robots.txt, sitemap-0.xml, sitemap.xml 파일을 확인할 수 있습니다.
public/robots.txt
# *
User-agent: *
Allow: /
# Host
Host: https://www.jobda.im
# Sitemaps
Sitemap: https://www.jobda.im/sitemap.xmlpublic/sitemap.xml
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap><loc>https://www.jobda.im/sitemap-0.xml</loc></sitemap>
</sitemapindex>public/sitemap-0.xml
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml" xmlns:mobile="http://www.google.com/schemas/sitemap-mobile/1.0" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url><loc>https://www.jobda.im</loc><lastmod>2024-05-20T12:25:46.632Z</lastmod><changefreq>daily</changefreq><priority>0.7</priority></url>
// ...
</urlset>생성된 stiemap-0.xml 파일을 확인해보면, 제 경우엔 약 80개의 페이지가 추가 됐습니다. 그런데, 잡다에서 사용 중인 채용 공고 페이지와 기업 정보 페이지를 모두 합하면 80개 페이지는 가볍게 넘길 것 같아요.
stiemap-0.xml 를 자세히 확인해보면 모두 정적 페이지인데요. getServerSideProps 또는 동적으로 구성되는 채용 공고 페이지 등에 대한 내용은 추가되지 않았는데, 이를 추가하려면 별도의 page를 추가해서 처리해줘야 합니다.
동적 페이지 Sitemap 추가하기
저는 pages 디렉토리를 사용하기에 pages/server-sitemap.xml/index.tsx 페이지를 추가해 줬습니다.
pages/server-sitemap.xml/index.tsx
import { getServerSideSitemapLegacy, ISitemapField } from 'next-sitemap';
import { GetServerSideProps } from 'next';
export default function Sitemap() {
return null; // 해당 페이지는 아무것도 리턴하지 않습니다.
}
const fetchSitemapData = (url: string): Promise<...> => {
// ...
return fetch(url, 'options') // 동적 페이지 생성에 필요한 정보를 받아옵니다.
};
export const getServerSideProps: GetServerSideProps = async (ctx) => {
const [companyData, positionData] = await Promise.all([
fetchSitemapData('기업 정보 API'),
fetchSitemapData('공고 정보 API'),
]);
const companyFields = companyData.map((id) => {
return {
loc: `https://www.jobda.im/company/${id}`,
lastmod: new Date().toISOString(),
} as ISitemapField;
});
const positionFields = positionData.map((id) => {
return {
loc: `https://www.jobda.im/position/${id}/jd`,
lastmod: new Date().toISOString(),
} as ISitemapField;
});
return getServerSideSitemapLegacy(ctx, [...companyFields, ...positionFields]);
};
- 해당 Page는 아무 콘텐츠도 반환하지 않습니다.
getServerSideSitemapLegacy함수를 썼는데, App Router를 사용한다면route.ts파일의GET함수 내부에서getServerSideSitemap함수를 사용할 수 있습니다.
잡다 서비스에서 동적 사이트맵이 필요한 페이지는 기업 정보 페이지, 포지션 정보 페이지가 있는데요. 두 페이지에서 사용될 페이지의 sitemap을 생성하는 server-sitemap.xml/index.tsx 파일을 만들어 줬고, 이를 config에 추가하면 됩니다.
next-sitemap.config.js
/** @type {import('next-sitemap').IConfig} */
module.exports = {
siteUrl: 'https://www.jobda.im',
generateRobotsTxt: true,
exclude: ['/server-sitemap.xml'],
robotsTxtOptions: {
additionalSitemaps: ['https://www.jobda.im/server-sitemap.xml'],
},
};exclude: /server-sitemap.xml 페이지는 sitemap 생성에서 제외합니다.robotsTxtOptions.additionalSitemaps: 넘겨준 값의 페이지 sitemap을 추가합니다.
이후 build 키워드를 통해 sitemap이 잘 생성되는지 확인해봅시다.
Terminal
$ yarn build
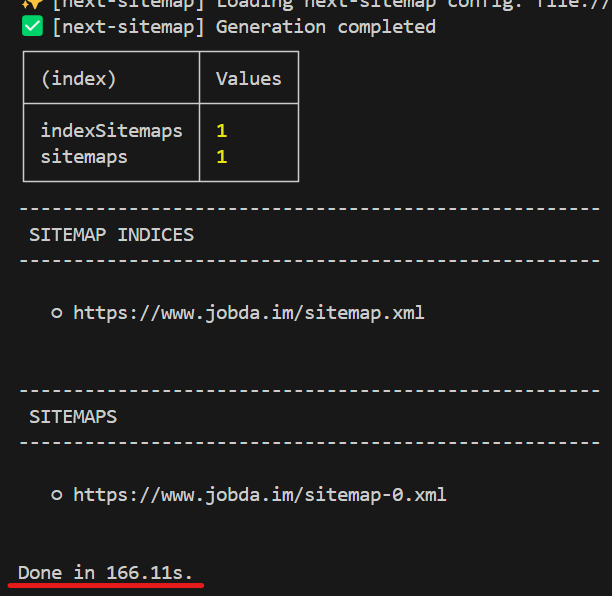 그림 3. 동적 라우트에 대한 sitemap 추가 후 next-sitemap 실행 결과
그림 3. 동적 라우트에 대한 sitemap 추가 후 next-sitemap 실행 결과
build time은 기존의 60s 수준에서 약 100s 증가됐는데, 무엇이 바뀌었을까요?
public/sitemap.xml
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap><loc>https://www.jobda.im/sitemap-0.xml</loc></sitemap>
<sitemap><loc>https://www.jobda.im/server-sitemap.xml</loc></sitemap> // 이 코드가 추가됐습니다.
</sitemapindex>이 외에 robots.txt, stiemap-0.xml 두 파일은 이전과 동일합니다.
동적으로 생성된 사이트맵은 /server-sitemap.xml 페이지로 접속해보면 확인할 수 있습니다.
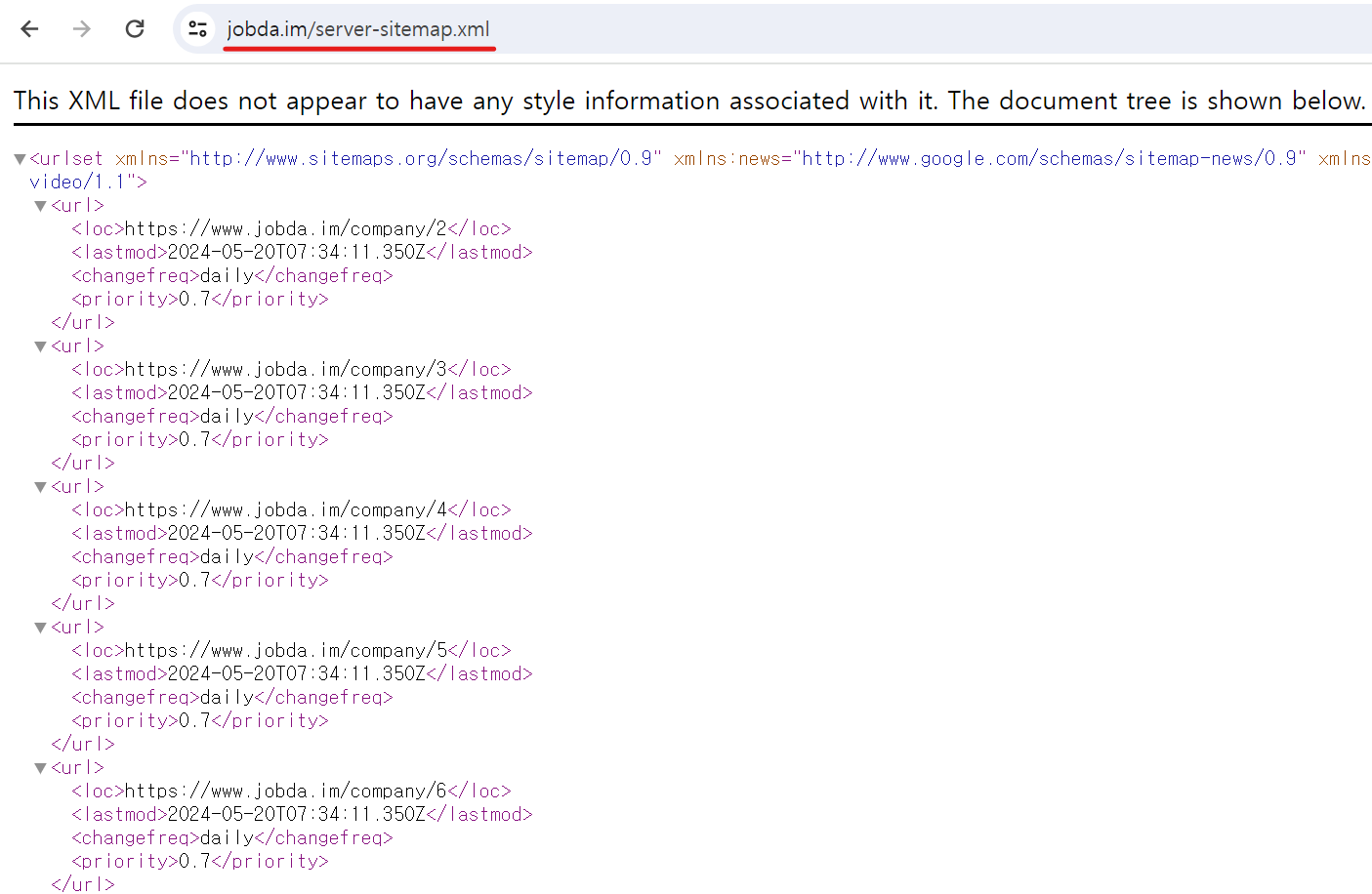 그림 4. 동적 라우트에 대한 생성된 sitemap 결과
그림 4. 동적 라우트에 대한 생성된 sitemap 결과
이렇게 생성된 Sitemap 파일들은 배포 환경에서 동적으로 생성되거나 빌드 프로세스의 일부로 생성되기에 git에 포함하지 않는 것이 좋을 것 같습니다.
제 경우엔 빌드 스크립트에서 이러한 파일들을 생성하도록 설정했고, 빌드 과정에서 생성된 파일을 버전 관리에 포함할 필요는 없기 때문에 gitignore에 파일들을 추가했습니다.
.gitignore
sitemap.xml
sitemap-0.xml
robots.txt사이트맵 제출
위 작업까지 마무리 되어서 Google Search Console의 sitemaps 탭에서 사이트맵 URL을 추가해 줬습니다.
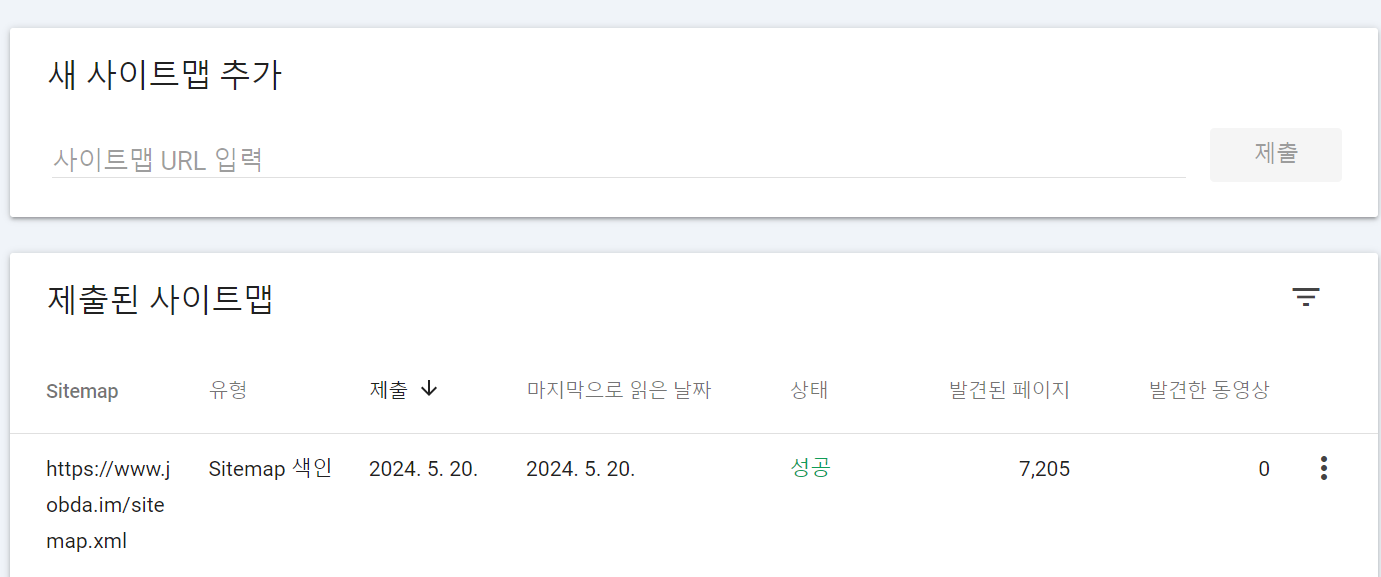
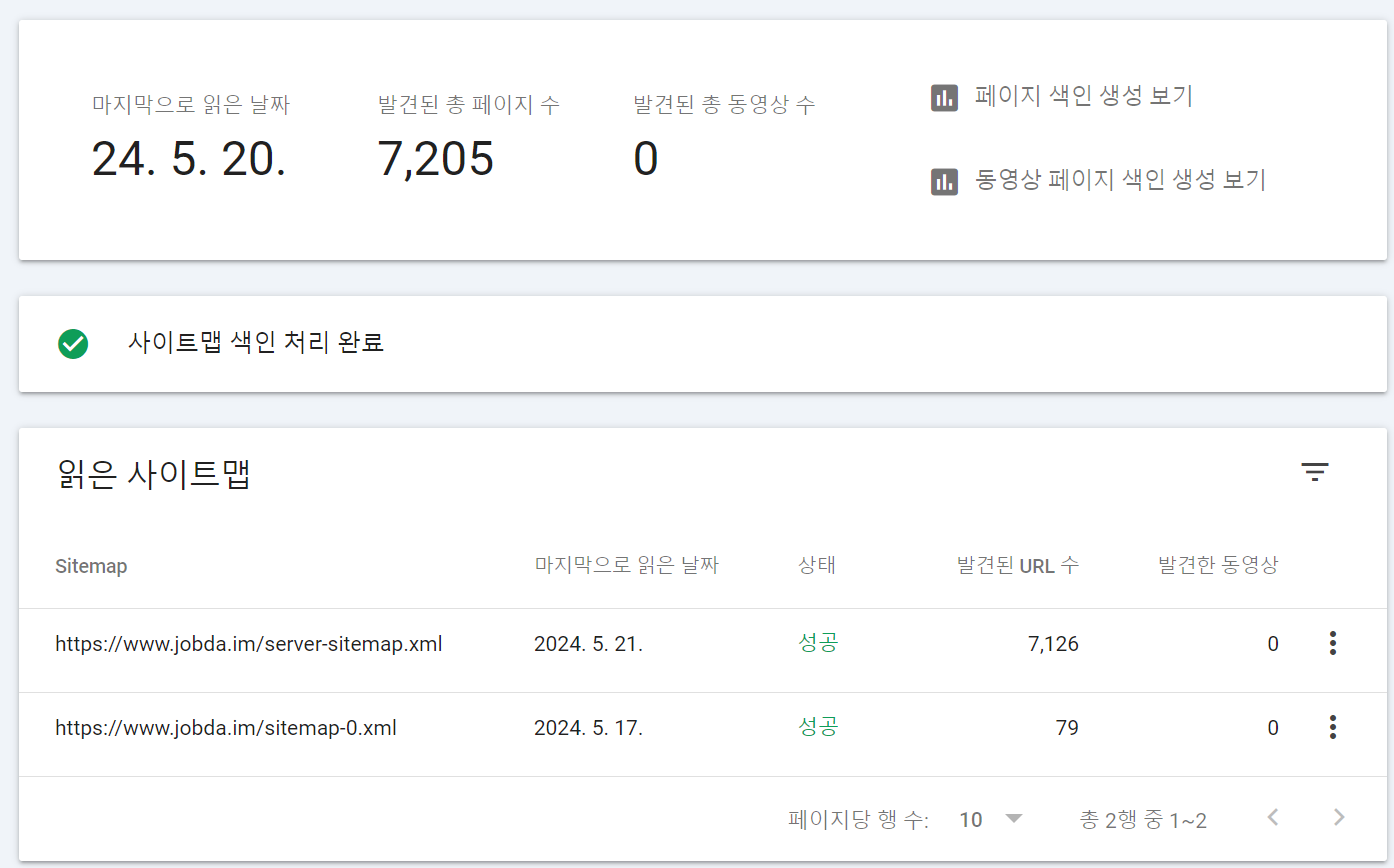
그림 5. Google Search Console 사이트맵 추가 페이지 그림 6. 추가된 사이트맵 정보
사이트맵 URL 제출 결과 7,126 개의 동적 페이지와 79개의 정적 페이지에 대한 사이트맵이 생성되었습니다.
적절한 meta 태그 사용하기
크롤링에 도움이 되는 사이트맵을 생성했으니 다음 단계로 색인에 필요한 적절한 meta tag를 지정하는 작업을 수행할 수 있을 것 같습니다.
잡다에서는 각 페이지별로 next/head의 Head 컴포넌트를 활용한 CustomHead 컴포넌트를 만들고, 이를 페이지별로 import하여 사용하고 있었습니다.
개선 전
interface CustomHeadProps {
customHeadData: CustomHeadVO;
}
const CustomHead = ({ customHeadData }: CustomHeadProps) => {
const { title, description, url, image } = customHeadData;
return (
<>
<Head>
<title>{title}</title>
<meta name="title" content={title} key="description" />
<meta name="description" content={description} key="description" />
<meta property="og:url" content={url} key="og:url" />
<meta property="og:title" content={title} key="og:title" />
<meta property="og:description" content={description} key="og:description" />
<meta property="og:image" content={image} key="og:image" />
<meta property="og:type" content="website" key="og:type" />
</Head>
</>
);
};최초엔 이렇게 meta 태그가 쓰이고 있었는데요. 다음과 같은 문제가 보입니다.
title의 key 값과description의 key 값이 모두 description으로 잘못 작성되어 있습니다.- meta tag 자체는 특정 페이지 내부에서 동적으로 변경되는 사항이 아니니 key 값을 넘겨주지 않아도 괜찮아 보입니다.
- 그리고 지금은 문자열 자체를 key 값으로 설정하고 있어서 적절한 의미로 사용되지 않고 있습니다.
title태그와meta name="title"두 태그가 중복으로 정보를 제공하고 있습니다.
그리고 다음과 같이 1차 개선이 이루어집니다.
중간 개선
const CustomHead = ({ customHeadData }: CustomHeadProps) => {
const { title, description, url, image } = customHeadData;
return (
<>
<Head>
<title>{title}</title>
<meta name="title" content={title} key="title" /> // <title> 태그와 중복
<meta name="description" content={description} key="description" />
<meta name="author" content="잡다" key="author" />
<meta name="writer" content="잡다" key="writer" /> // author 내용과 중복
<meta
name="keywords"
content="잡다, 취업, 채용, 채용공고, 채용제안, 채용정보, 역검, 역량검사, 공채, 수상시, 기업, 취준"
key="keywords"
/> // 구글에서는 더 이상 활용하지 않는 keywords 정보
<meta name="facebook:title" content={title} key="facebook:title" /> // og:title 내용과 중복
<meta name="facebook:description" content={description} key="facebook:description" />
<meta property="og:title" content={title} key="og:title" />
<meta property="og:description" content={description} key="og:description" />
<meta property="og:url" content={url} key="og:url" />
<meta property="og:image" content={image} key="og:image" />
<meta property="og:image:alt" content="JOBDA" key="og:image" />
<meta property="og:type" content="website" key="og:type" />
</Head>
</>
);
};
이후 1차 개선된 코드는 위와 같습니다. title과 description의 key 값이 동일했던 문제가 해결되었고, author, writer, keywords, facebook: 메타 태그도 추가되었으나 여전히 문제가 보입니다.
title정보,description정보에 대한 중복facebook,og타입의 중복author,writer정보 중복- 구글에서는 사용되지 않고 있는
keywords정보
meta 태그는 많을 수록 좋은 것이 아니고, 중복된 정보가 있다면 검색 엔진 크롤러는 어떤 메타 태그를 우선해야 할지 혼란스러울 수 있습니다. 이는 검색 결과에서 페이지의 순위를 떨어뜨릴 수 있는데요. 그런 관점에서 <title>, name="title", name="facebook:title", name="og:title"태그가 쓰인 것과 같은 중복되는 정보를 줄이는 것이 도움이 될 수 있습니다.
또한, 2009년 9월 21일 구글 블로그에 게시된 keywords 관련 글에서 keywords 메타 태그는 구글에서 더 이상 쓰이지 않는다고 알리고 있습니다.
이런 부분들은 개선할 필요가 있어 보입니다.
최종 개선
const CustomHead = ({ customHeadData }: CustomHeadProps) => {
const { title, description, url, image } = customHeadData;
return (
<Head>
<title>{title}</title>
<meta name="description" content={description} />
<meta name="author" content="잡다" />
<meta property="og:title" content={title} />
<meta property="og:description" content={description} />
<meta property="og:url" content={url} />
<meta property="og:image" content={image} />
<meta
property="og:type"
content={url.includes('position') || url.includes('company') ? 'article' : 'website'}
/>
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:title" content={title} />
<meta name="twitter:description" content={description} />
<meta name="twitter:image" content={image} />
<meta name="robots" content="index, follow" />
<link rel="canonical" href={url} />
</Head>
);
};meta name="title": 태그는 title 태그와 중복이므로 제거writer:author와 중복이므로 제거og:type: 채용 공고와 기업 정보 페이지는 개별적인 글로 간주될 수 있기에article, 그 외에 경우엔websitetype으로 처리facebook::og:태그와 중복이므로 제거- facebook은 Open Graph 메타 태그를 우선적으로 사용하여 페이지를 렌더링합니다.
twitter:: 트위터카드를 설정하는데 사용, 트위터에 공유될 때 미리보기를 제공합니다.robots: 페이지 별 robots의 접근 여부를 제어할 수 있는 정보입니다. 해당 페이지가 검색 결과에서 제외되지 않도록 처리하기 위해 추가index: 색인 대상에 추가follow: 페이지 내 링크 수집
canonical: 페이지의 표준 URL을 지정하고, 중복된 콘텐츠 문제를 방지하기 위해 추가
여기서 <title> 태그와 name="og:title", name="description" 태그와 name="og:description"이 중복되는 것처럼 보이지만, 둘의 용도가 다르기에 둘 다 사용하는 것이 좋습니다.
<title> 태그는 검색 엔진과 브라우저에, og:title 태그는 소셜 미디어에 사용되므로 각각 설정해야 하며, <meta name="description">은 검색 엔진 최적화(SEO)를 위해, og:description은 소셜 미디어 최적화를 위해 필요합니다.
이렇게 수정하면서 중복으로 제공하고 있는 title, description, writer, facebook:* 등의 정보를 제거하고, twitter, robots, canonical url등을 추가하였습니다. 이렇게 하면 적절히 색인이 형성될 것이고, twitter에 잡다 링크를 공유하면 meta 태그로 설정한 image, title, description이 적절히 표현될 것입니다.
그리고, canonical url을 통해 표준 페이지를 지정해줬고, 이는 색인에 도움이 될 것입니다.
색인이 생성되지 않은 페이지
Google Search Console을 사용하면 색인이 생성되지 않은 페이지들을 확인할 수 있습니다.
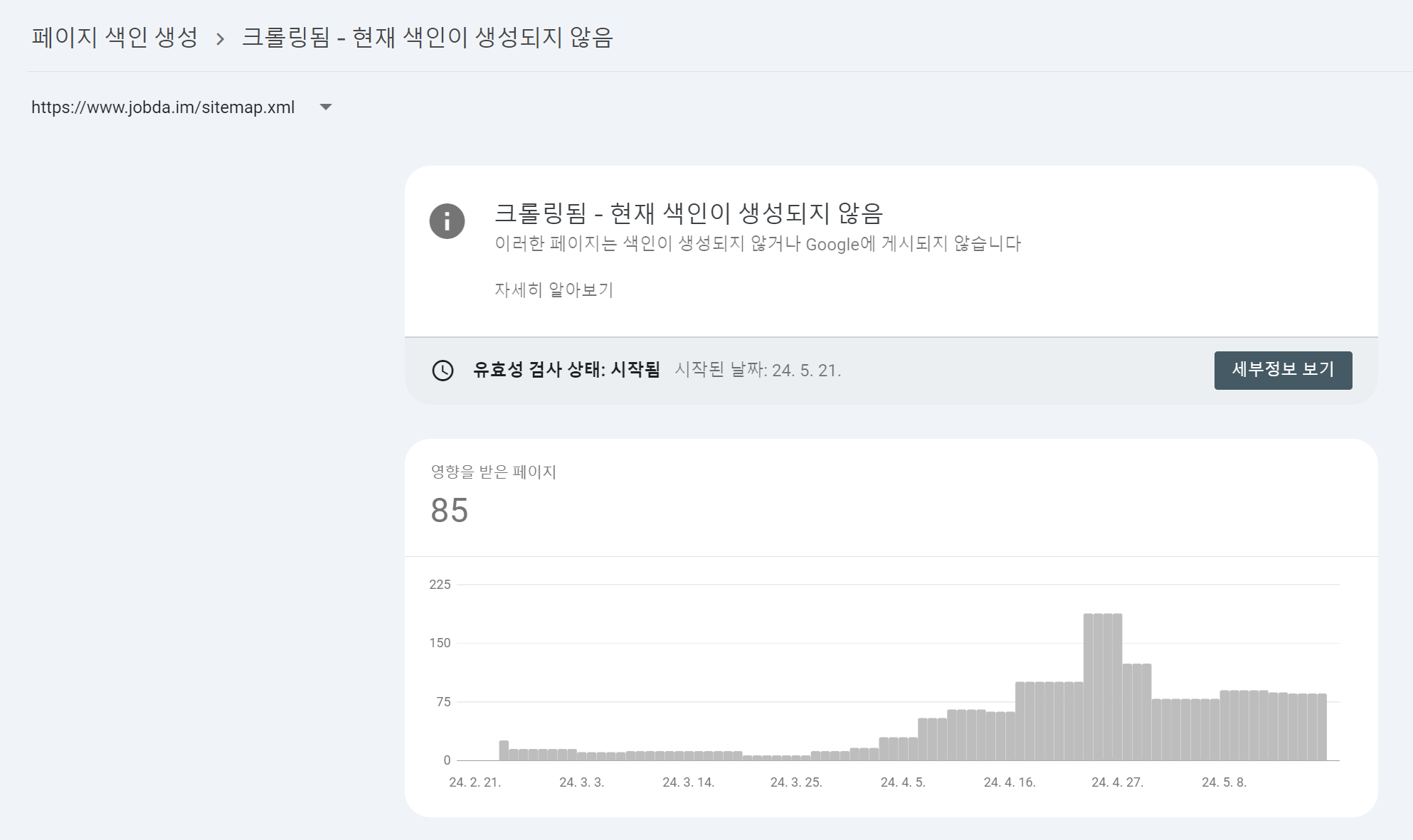 그림 7. 크롤링은 되었지만 색인이 생성되지 않은 85개의 페이지
그림 7. 크롤링은 되었지만 색인이 생성되지 않은 85개의 페이지
잡다 사이트의 경우 색인이 생성되지 않은 페이지가 점점 증가하다가 글을 작성하는 시점에는 85개의 페이지가 크롤링은 되었지만 색인은 생성되지 않았다고 보고하고 있습니다.
그런 페이지 중 몇 개를 살펴보자면 마케팅 정보 수신 동의 약관 전문 페이지, 15세 미만 이용자 대상 생년월일 변경 페이지, 프로필에 등록한 PDF view 조회 페이지 등이 있습니다.
이런 페이지들은 서비스 이용 중에 자연스럽게 접근할 수 있는 페이지이고, 해당 페이지를 먼저 검색해서 들어올 필요는 없어 보입니다. 이러한 페이지에서는 meta 태그를 간소화하는 것이 좋지만, 완전히 제거하기 보다는 최소한의 정보는 제공하는 것이 좋습니다.
 그림 8. meta 태그가 없는 잡다 페이지
그림 8. meta 태그가 없는 잡다 페이지
실제로 사용 중인 페이지임에도 <title> 태그가 없어서 무언가 미완성된 페이지처럼 보입니다. 검색 엔진 최적화가 필요 없는 페이지라고 하더라도 <title> 태그는 여전히 중요하며, <meta name="robots"> 태그를 사용해서 크롤러에게 색인이나 페이지 링크 수집에 필요 없는 페이지임을 알려 SEO 작업 효율성을 높일 수 있습니다.
jobda.im/marketingPolicy 페이지
<Head>
<title>마케팅 정보 수신 동의 약관</title>
<meta name="robots" content="noindex, nofollow" />
<meta name="description" content="마케팅 정보 수신 동의 약관 페이지입니다." />
</Head>이렇게 meta tag를 작성해 주었는데요. noindex는 검색 엔진에게 해당 페이지를 인덱싱하지 않도록 지시하는 것이고, nofollow는 페이지 내 링크를 따라가지 않도록 지시하는 것입니다.
이렇게 하면 페이지의 기본적인 정보는 제공하면서도, 불필요한 SEO 작업을 피할 수 있습니다.
Google Search Console을 통해 확인한 meta 정보가 없는 페이지에 대해서 쉽게 확인할 수 있었고, 이에 따라 각 페이지에 최소한의 meta 태그는 작성해주었습니다.
색인이 생성되지 않은 리디렉션이 포함된 페이지
Google Search Console에서 페이지 색인이 생성되지 않은 페이지 중 리디렉션이 포함된 페이지도 확인할 수 있습니다.
위에서 최종으로 개선한 meta 태그를 적용하기 전 1,029개의 페이지의 색인이 생성되지 않고 있었는데요.
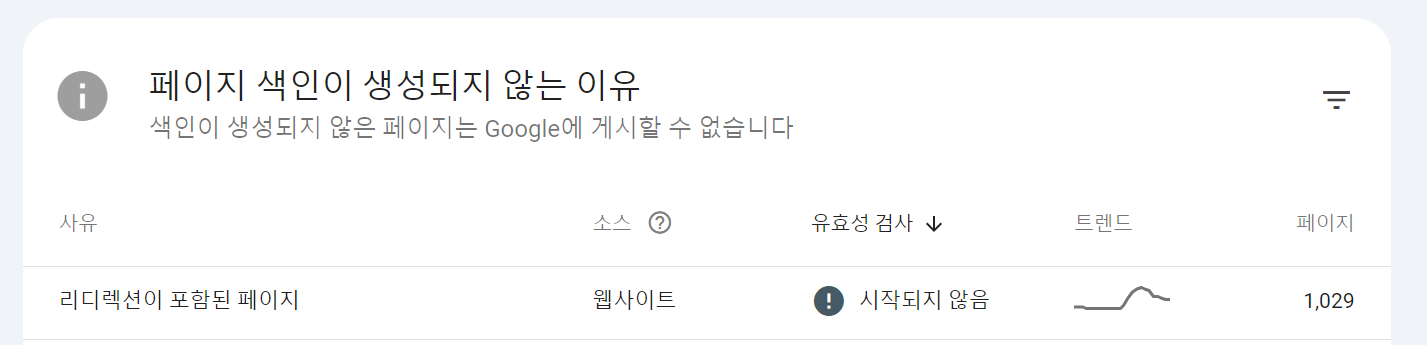 그림 9. 색인이 생성되지 않은 리디렉션이 포함된 페이지
그림 9. 색인이 생성되지 않은 리디렉션이 포함된 페이지
내용은 대부분 공고 페이지 또는 기업 정보 페이지였습니다.
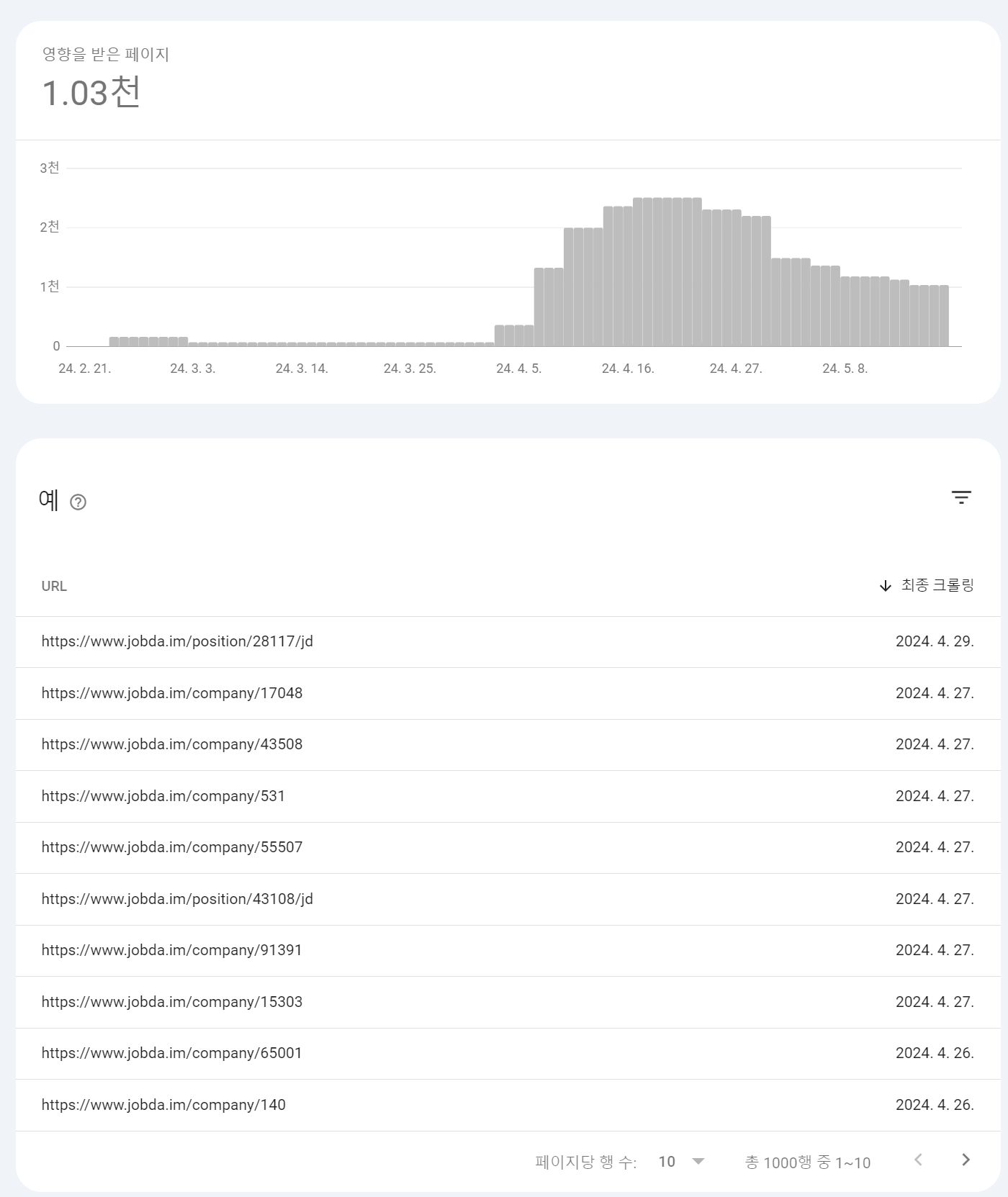
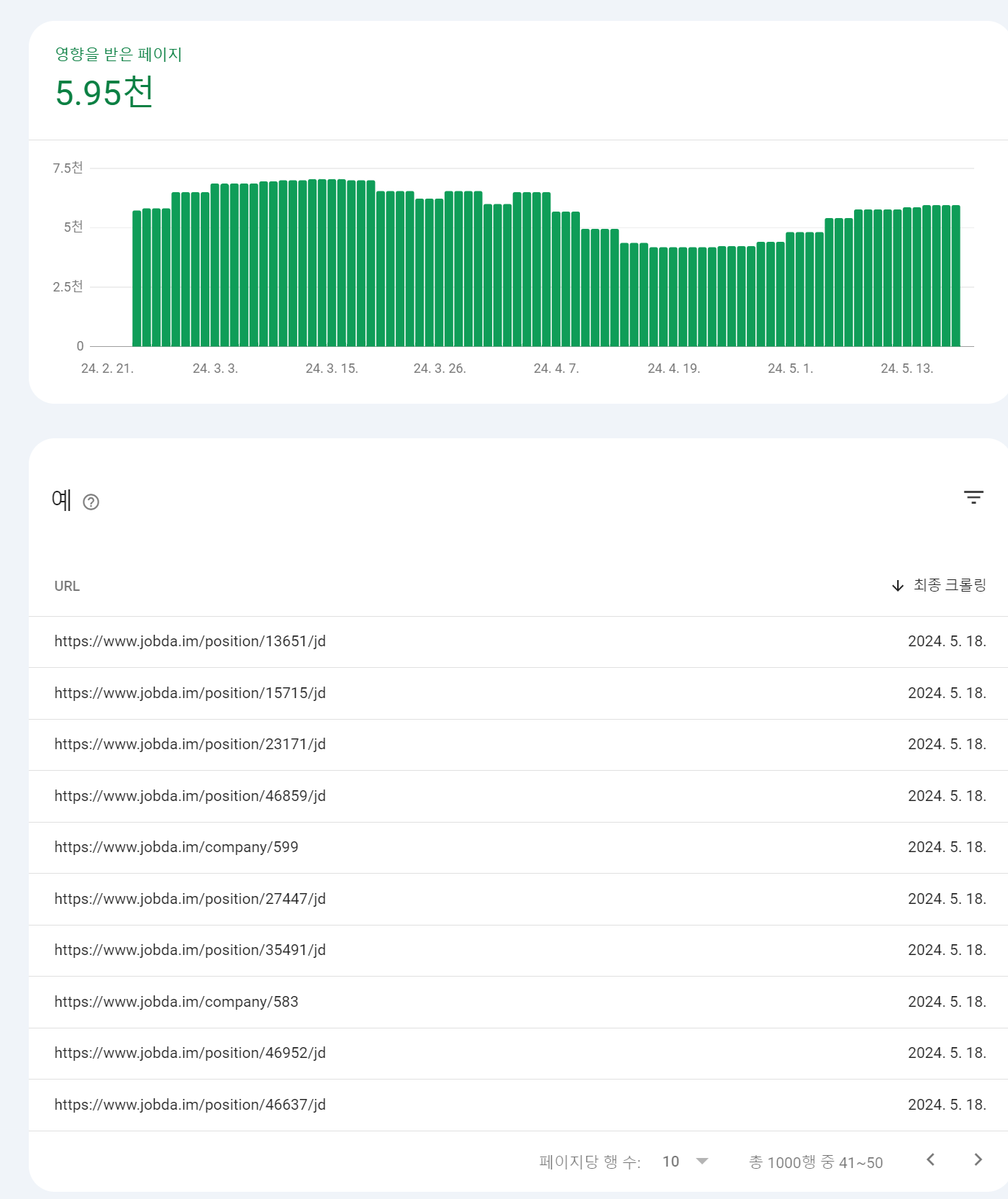
그림 10. 색인이 생성되지 않은 페이지 그림 11. 색인이 생성된 페이지
동적 라우트만 다른 페이지인데 약 1,000개의 페이지들은 왜 색인이 생성되지 않았을까요??
보고서에 따르면 리디렉션이 포함된 페이지로 색인이 생성되지 않은 경우 다른 페이지로 리디렉션되는 비표준 URL이기 때문에 색인이 생성되지 않았다고 판단합니다. 반면, 리디렉션이 포함된 표준 URL은 색인이 생성될 수 있다고 보고하고 있는데요. 생성에 실패한 페이지 색인 생성 보고서를 확인해보면 아래와 같은 정보를 확인할 수 있습니다.
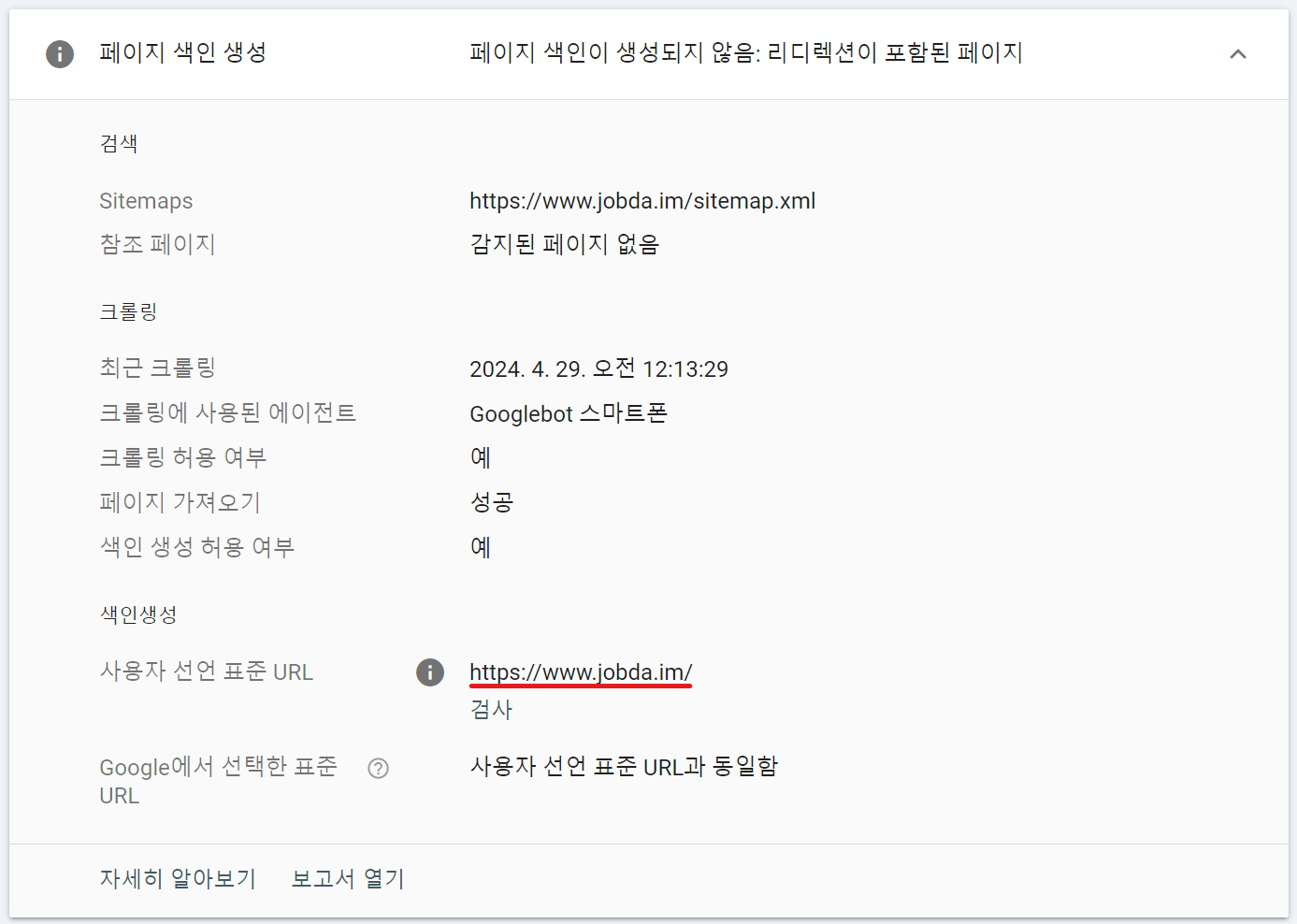 그림 12. 색인 생성에 실패한 페이지의 색인 실패 보고서
그림 12. 색인 생성에 실패한 페이지의 색인 실패 보고서
사용자 선언 표준 URL이 메인 페이지를 가리키고 있었습니다. 표준 URL 바로 아래에 있는 검사 버튼을 눌러보면 색인이 정상 생성이 되는데요.
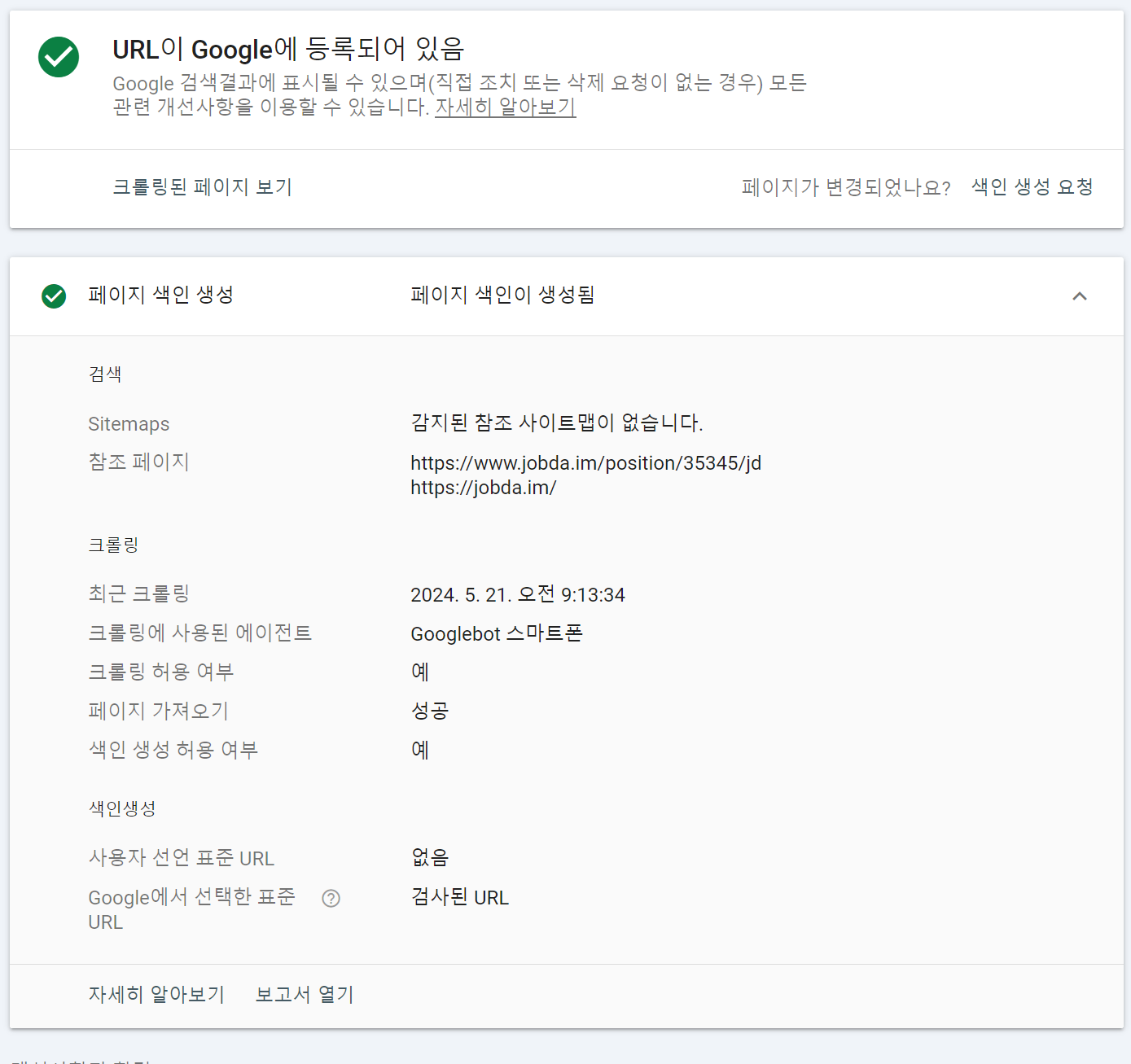 그림 13. 검사 버튼 클릭 후 정상 생성된 색인
그림 13. 검사 버튼 클릭 후 정상 생성된 색인
색인이 정상 생성되는 것을 보면 페이지에 필요한 정보는 적절하게 포함되어 있는 것으로 판단되며, 이는 link 태그의 canonical url를 작성해줘서 표준 URL을 전달한다면 해결될 문제로 보여집니다.
네이버 검색 엔진 최적화 시도
위의 내용을 기반으로 작성된 코드들은 어느정도 검색 엔진 최적화가 되었을 것인데요. 이는 구글에서 제시하는 가이드를 따른 것인데, 국내에서 사용하는 검색 사이트의 경우 2023년 기준 국내에선 검색 점유율이 네이버 58.2%, 구글 31.9% 차지할 만큼 네이버 검색 점유율이 높습니다.
이에 따라 네이버에서 제시하는 가이드를 따르며 부족한 부분들을 채워주면 좋을 것 같습니다.
네이버에서 검색 엔진 최적화를 할 때 네이버 서치 어드바이저를 이용할 수 있습니다.
사이트 진단하기
우선 서치 어드바이저에서 사이트 간단 체크를 해봅시다. 웹 사이트 주소를 입력하면 title, description, robots.txt 등의 여부를 판단하여 알려줍니다.
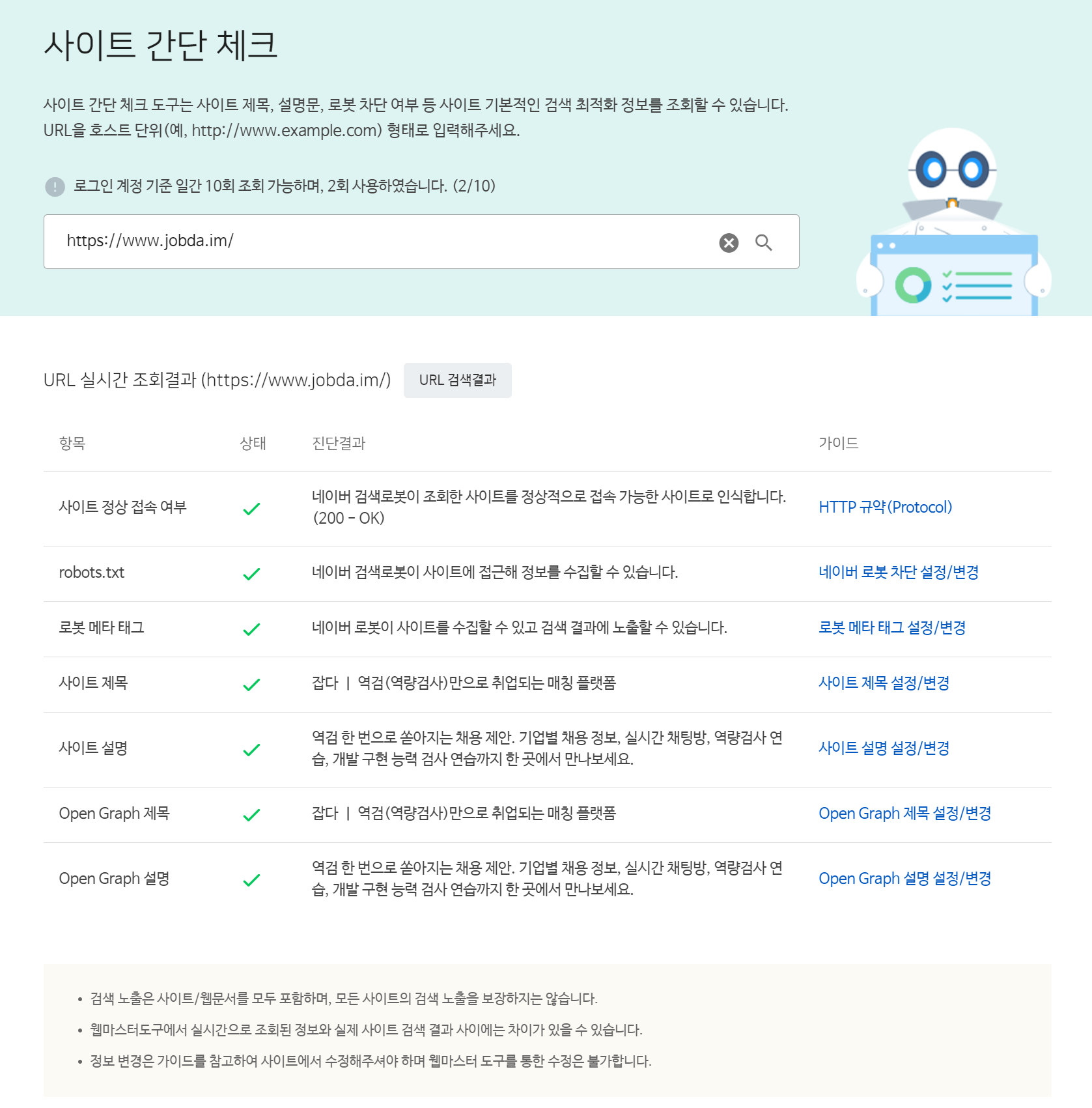 그림 14. 잡다 사이트 간단 체크
그림 14. 잡다 사이트 간단 체크
간단 체크에서 잡다 사이트는 적절히 조치가 되어 있는 것으로 보입니다. 우측에 HTTP 규약(Protocol), 네이버 로봇 차단 설정/변경 등의 링크를 클릭하면 해당 주제에 맞는 가이드를 보여줍니다.
사이트 등록하고 URL 검사하기
서치 어드바이저에서 웹마스터 도구 > 사이트 관리 페이지에서 URL 검사에 웹사이트 주소를 등록하면 메타와 SEO 정보를 제공하여 최적화가 부족한 부분을 안내하고 있습니다.
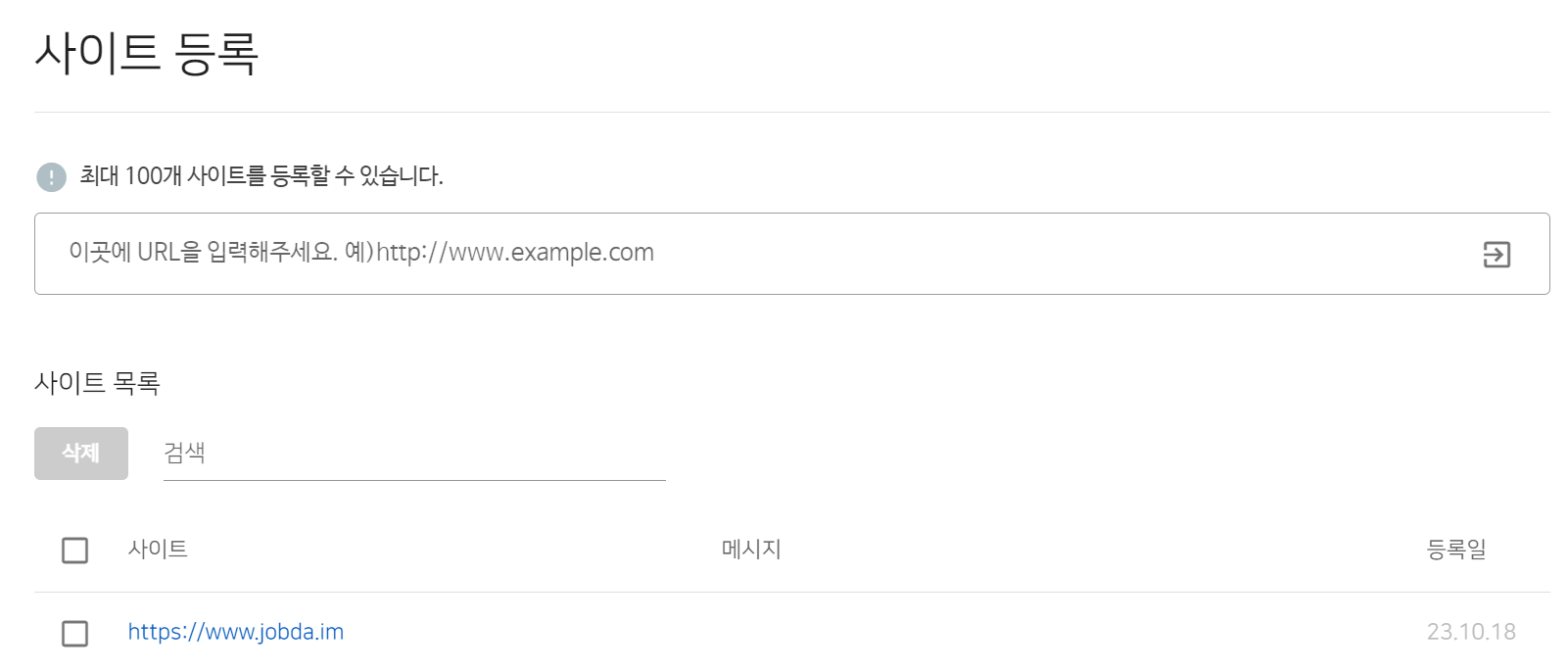 그림 15. 웹 마스터 도구 사이트 등록
그림 15. 웹 마스터 도구 사이트 등록
잡다는 이미 등록이 되어 있었는데요. 링크를 클릭하여 상세 정보를 확인해보면 노출/클릭 현황과 사이트 진단 등에 대한 내용들을 확인할 수 있습니다.
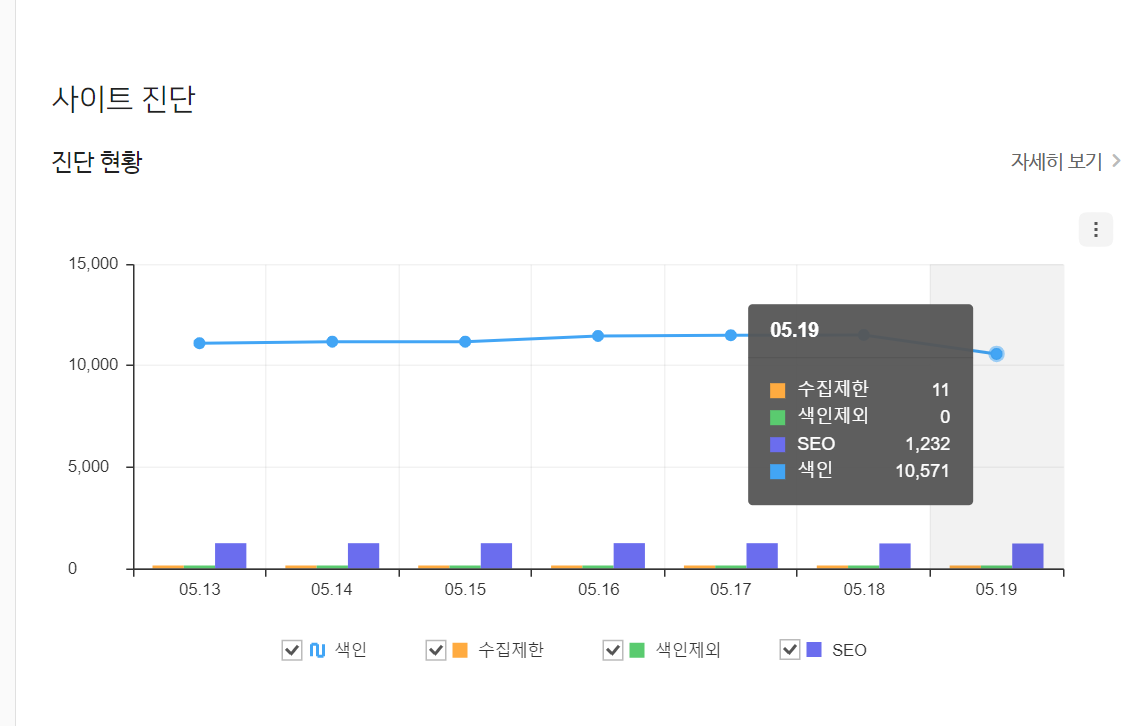 그림 16. 웹 마스터 도구 사이트 진단
그림 16. 웹 마스터 도구 사이트 진단
5월 19일 기준 위와 같은 정보를 보여주고 있는데, 우측 상단에 자세히 보기를 클릭하면 유형별 진단 정보를 확인할 수 있습니다.
 그림 17. 사이트 진단에 대한 유형별 진단 정보
그림 17. 사이트 진단에 대한 유형별 진단 정보
Google Search Console에서도 비슷한 내용들이 있었는데, 더 상세하게 정보를 알려주는 것처럼 느껴집니다. 수정해야할 부분이 많아 보이고, 이를 하나씩 수정해 나가면 될 것 같습니다.
<title> 또는 <meta name=”description”> 누락
진단 정보에 따르면 <title> 태그 찾을 수 없음 약 140건, <meta name="description"> 누락 약 120건인데요. 자세히 살펴보면 다음과 같습니다.
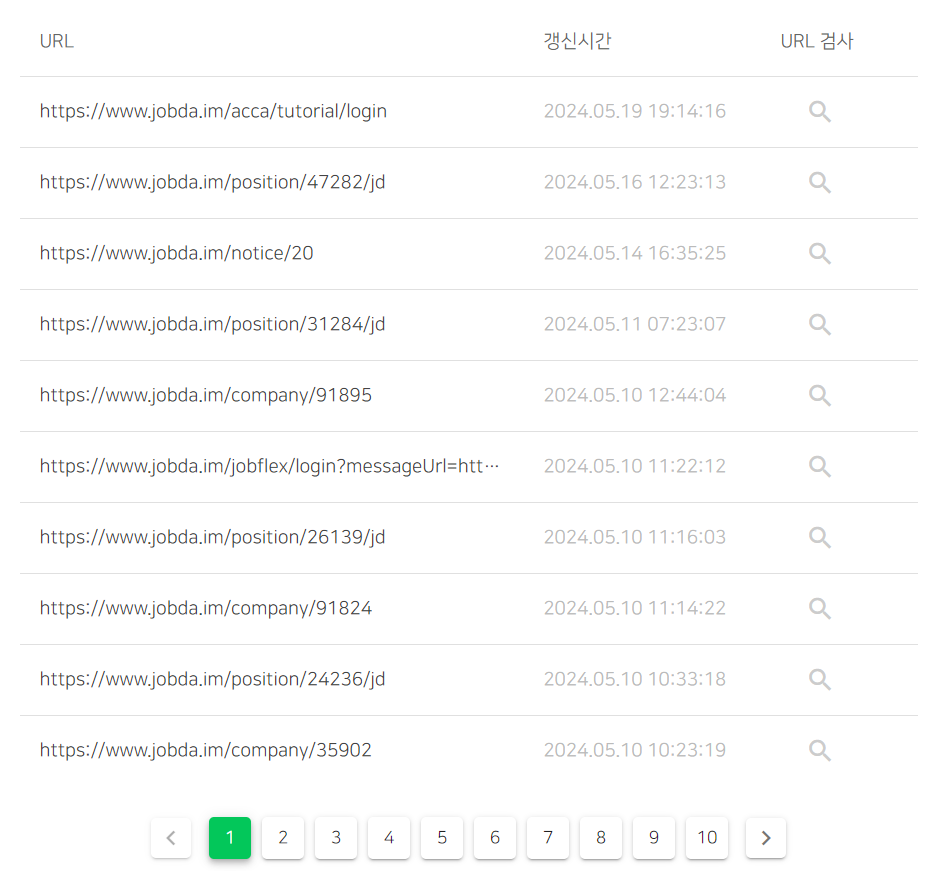 그림 18. title 태그가 누락된 페이지
그림 18. title 태그가 누락된 페이지
/acca/tutorial/login|/jobflex/login: 코드 상 메타 정보가 없는 경우/position/[id]/jd|/company/[id]: 없는 공고, 기업 정보 페이지에 접근한 경우
위 두 가지 케이스로 나뉘고 있었습니다.
메타 정보가 없는 경우
Google Search console에서 확인한 메타 정보가 없는 페이지에 그랬듯이, 메타 정보가 없는 페이지에 코드를 추가해 줬습니다. /acca/tutorial/login 같은 페이지는 검색 결과 상위에 노출될 필요가 없고, 서비스를 이용한다면 도달할 수 있는 페이지이기에 <meta name="robots" content="noindex, nofollow"> 태그로 작성해줍니다.
const CustomHeadWithNoIndex = ({ title, description }: { title: string; description: string }) => {
return (
<Head>
<title>{title}</title>
<meta name="description" content={description} />
<meta name="robots" content="noindex, nofollow" />
</Head>
);
};없는 공고, 기업 정보 페이지에 접근한 경우
이 경우는 잡다 서비스 이용자가 특정 공고나 기업 정보 페이지를 즐겨찾기 해놓고, 시간이 흐른 뒤에 접근했을 때 문제가 발생하는 경우로 추정됩니다. 예를 들면, 공채 기간이 종료된 다음 접속한 경우나 상시 채용 중 채용이 완료되어 공고가 삭제된 케이스라고 예측해볼 수 있겠네요.
글을 작성하는 시점에 이러한 처리가 되어있지 않았는데요. 그래서 해당 페이지에 접근하면 화면이 로딩 중인건지, 에러가 발생한건지 분간이 안되고, 메타 정보도 없는 상태로 방치되고 있었습니다.
이에 접근할 수 없음을 나타내는 공용 UI를 표시해 주면서, 위에서 만들었던 CustomHeadWithNoIndex 컴포넌트로 메타 정보를 넘겨주었습니다.
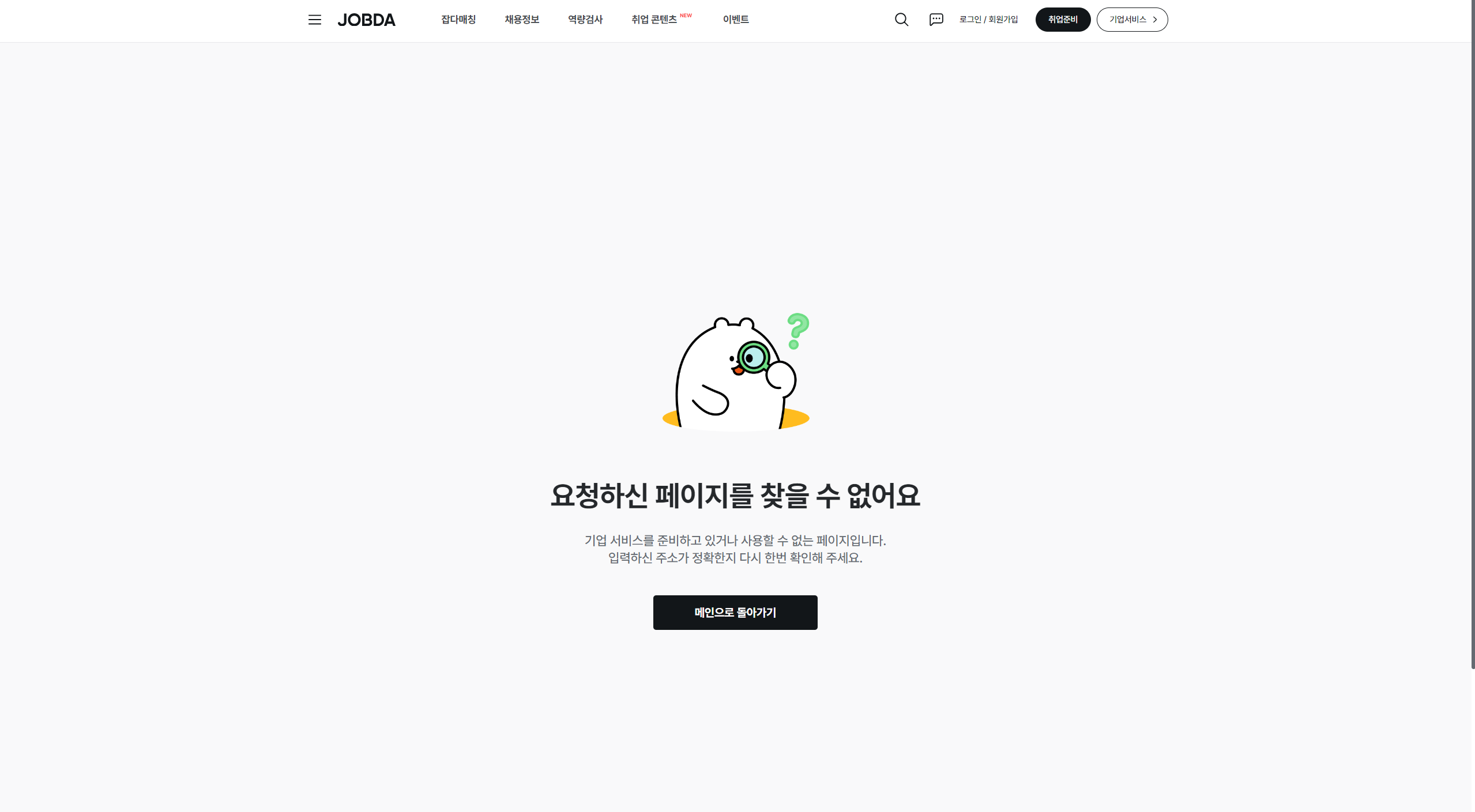
그림 19. 개선 전 - 아무 것도 보여주지 않으며 title 정보가 없음 그림 20. 개선 후 - 공용 Error UI를 보여주며 title 정보가 있음
정리
검색 엔진 최적화를 위해 Sitemap을 추가하고, 각 메타 태그에 적절한 정보를 입력한 결과, Google Search Console, 네이버 서치 어드바이저에서 점진적으로 페이지 색인이 되는 것을 확인할 수 있었습니다.
이 과정에서 사용자 경험도 자연스럽게 개선되었습니다. 예를 들면, <title> 태그가 없어서 미완성된 사이트처럼 보이던 문제나, 존재하지 않는 공고 페이지에 접속했을 때 적절한 UI가 표시되지 않는 문제 등을 해결할 수 있었습니다.
검색 엔진 최적화를 위해 수행한 작업들이지만, 반대로 생각해보면 좋은 콘텐츠를 제공하는 페이지가 검색 결과 상위에 노출되는 것이 어떻게 보면 당연했던 것이라 생각합니다.
이번에 작업을 하면서 SEO가 한번 작업되면 끝이 아니라 지속적으로 관리를 해야 함을 느꼈습니다. 제가 개선하기 이전에 다른 팀원이 이미 일부 작업을 했었지만, 일부 작은 부분에서 누락되거나 중복된 부분이 있었습니다. 이번 기회에 이러한 부분을 한 번에 정리할 수 있었지만, 이것이 끝이 아니라 지속적으로 관심을 갖고 작업을 수행해야 할 것 같습니다.
참조
- https://ogp.me/#types
- https://searchadvisor.naver.com/guide
- https://developers.google.com/search/docs/fundamentals/how-search-works?hl=ko
- https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap?hl=ko
- https://developers.facebook.com/docs/sharing/webmasters?locale=ko_KR
- https://developer.mozilla.org/ko/docs/Learn/HTML/Introduction_to_HTML/The_head_metadata_in_HTML
2024.06.12 내용 추가
개선 결과
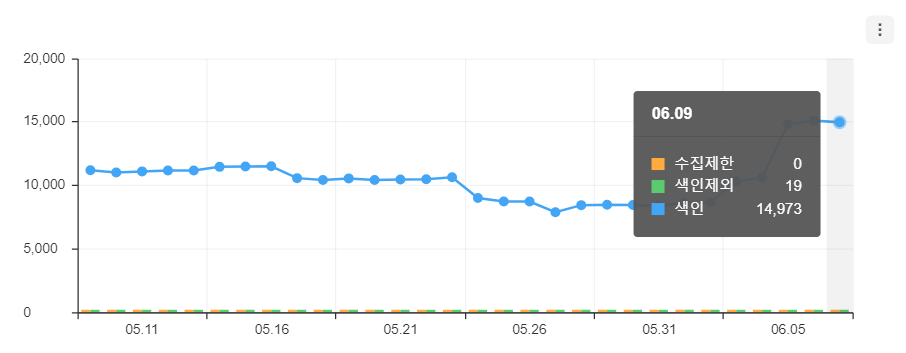
수정 전 (24.05.22)

- 수집제한: 10
- 색인제외 0
- 색인: 10,426
수정 후 (24.06.09)
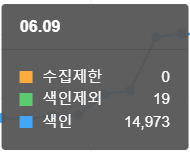
- 수집제한: 0
- 색인제외: 19
- 색인: 14,973
수집제한 항목으로 존재했던 10개의 페이지는 모두 사라졌고, 색인 자체가 불필요한 페이지들은 의도적으로 제외하여 19개의 페이지는 색인에서 제외되었습니다. 색인 제외된 페이지에는 로그인 페이지, 약관 페이지 등 검색 결과에 포함되지 않아도 되지만 서비스 내에서 정상 이용이 가능한 페이지들이 포함되어 있습니다.
색인이 된 페이지도 10,426 페이지에서 14,973 페이지로 약 30% 증가했습니다. 물론 여기엔 채용 공고 수의 증가, 기업 정보 페이지의 증가도 영향이 있겠지만, 유의미한 개선은 된 것으로 판단됩니다.
위의 내용은 네이버 서치 어드바이저 결과로 네이버 검색 결과에선 개선이 되었지만, Google Search Console에서는 아직 유의미한 차이가 발생하지는 않았습니다. 시간을 두고 개선이 되는지 지켜봐야할 것 같습니다.

SEO 작업 이후 유입량 전후 증가 여부도 있으면 더 좋을것 같아요! 글 잘 읽었습니다!