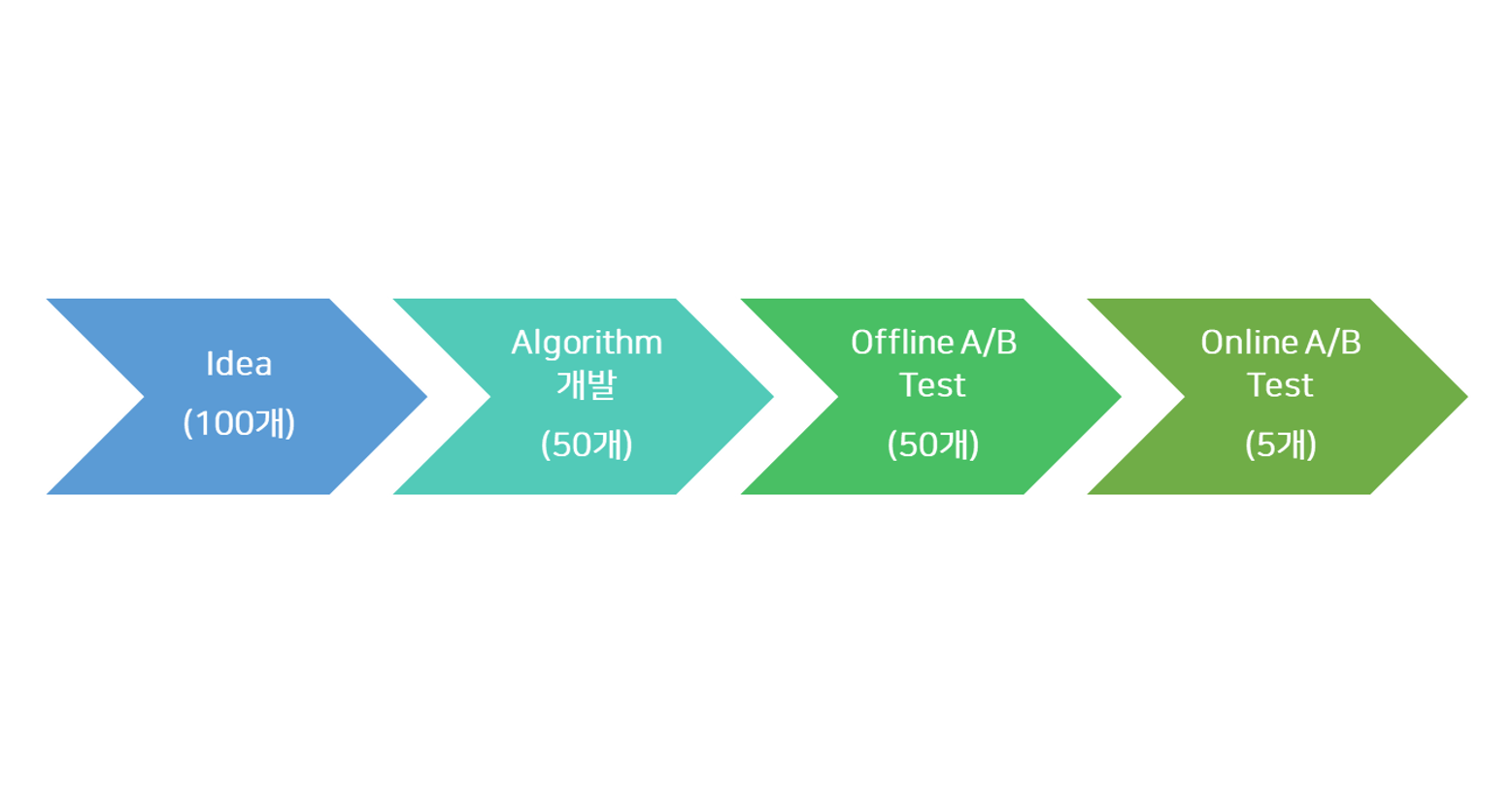
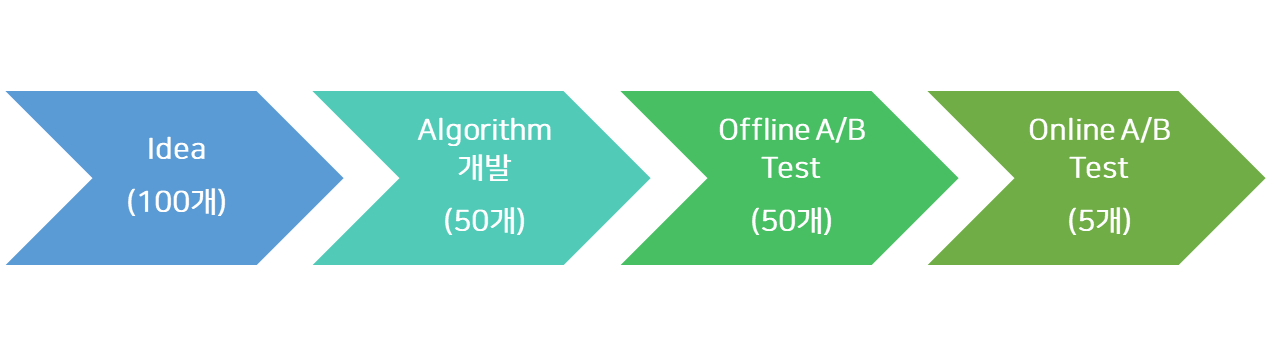
Offline A/B Test 개념
Online A/B Test란? 왜 중요한가?
Online A/B Test는 실제 상용 서비스에 A와 B 알고리즘을 적용해서 성능을 비교 평가하는 프로세스로, 하나의 서비스에 여러 개의 컨셉 및 알고리즘을 시도해 볼 수 있다는 장점이 있습니다.
예를 들면, 음악서비스에서는 다음과 같은 컨셉의 리스트를 적용해서 사용자 반응을 비교할 수 있습니다.
- 인기 순 (예: 주간 Top10, 실시간 차트 Top 10)
- 사용자가 좋아하는 가수의 음악
- 사용자의 좋아하는 장르의 음악
- 오늘 날씨에 듣기 좋은 음악 (#구름낀날, #비오는날, #햇살좋은날)
서비스 품질을 향상시키기 위해서는 어떤 알고리즘의 성능이 우수한지 실제 Online에서 평가하는 것이 중요합니다.
과거 데이터를 이용해서 최적화한 알고리즘을 실제 서비스에 적용한다면, 추천서비스의 환경적 요인에 의해서 결과가 달라질 수 있습니다. 또한, 과거의 데이터를 이용하여 사용자가 선호할 만한 아이템을 추천 하더라도 서비스의 특성상 최신/인기 콘텐츠를 더 좋아할 수도 있습니다. 따라서, 우리가 제안하는 머신러닝 알고리즘이 ‘서비스의 여러가지 외부요인이 반영된’ 실제 Online 환경에서 좋은 성능을 보장하는지 검증하는 절차가 필요합니다.
하지만, Online A/B 테스트는 적용하고 테스트하기까지 비용이 매우 큽니다. 결과는 신뢰할 수 있지만 충분한 양의 데이터가 수집되기까지 많은 시간이 소요되며, 만약 테스트 알고리즘이 좋은 성능을 보장하지 못한다면 최악의 경우 부정적인 경험을 한 사용자가 서비스를 탈퇴할 수 있는 리스크도 있습니다. 또한, 광고와 오픈마켓의 경우, 클릭이 수익으로 직결되기 때문에 테스트 알고리즘 영향으로 매출이 급격히 하락할 수도 있습니다.
그래서 대안으로 과거의 데이터를 이용하여 실제 성능을 추론해 보는, Offline A/B Test 기술이 있습니다.
Offline A/B Test란, 시간이나 사용자의 경험비용을 최소화하기 위해, 새로운 아이디어를 추가해 빠르게 확인할 수 있는 프로세스로, 사전에 성능이 떨어지는 알고리즘은 미리 제외하고 성능이 보장된 알고리즘만 Online에 적용 가능하다는 장점이 있습니다. 반면, 많은 가정이 필요하고 Offline 테스트 결과가 실제와 다를 수 있다는 리스크도 존재합니다.
Offline A/B Test 결과가 실제와 다른 이유
- 예시
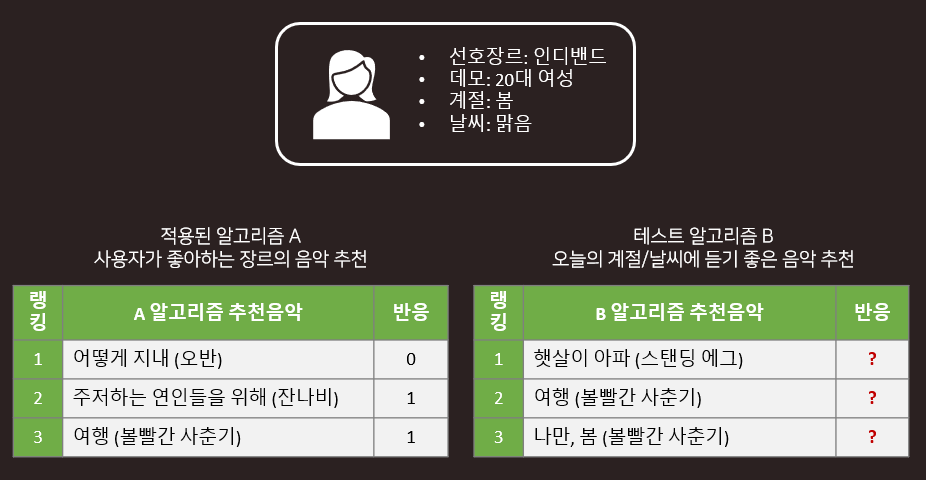
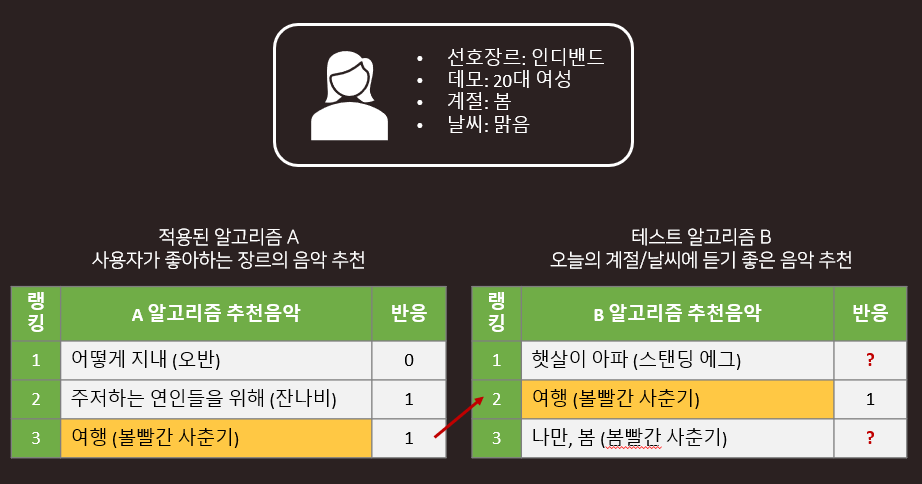
과거 데이터는 A 알고리즘과 그로부터 생성된 사용자의 반응에 편향되어 있습니다. 즉, 이미 적용된 알고리즘을 통해 추천된 콘텐츠에 대해서만 반응을 평가할 수 있고, Test 알고리즘이 새롭게 제시할 콘텐츠에 대한 사용자의 선호도를 평가하기 어렵습니다.
그럼, Counterfactual Thinking으로 접근해 볼까요?
‘만약… 했다면 (조건), … 했을텐데 (결과)‘
만약 ‘어떻게 지내’ 음악이 A 알고리즘이 아닌 B 알고리즘에 의해 첫 번째로 추천되었다면, 어떤 확률 값으로 추천되었을 것입니다.
즉, ‘B 알고리즘의 아이템 추천 확률’ 개념을 이용해서 사용자의 반응을 re-weighting하는 방식으로 접근하는 것입니다.
다른 기업들도 Offline A/B Test를 활용하고 있을까요? 실제로 Yahoo, Microsoft, Netflix, Criteo, Pandora 등 많은 기업들이 Offline A/B Test를 시도하고 있고, 2019년 이후부터 AI/머신러닝 관련 학술지에 Offline A/B Test 주제의 논문들이 증가하는 추세입니다. 2018년에는 이 주제로 RECSYS Workshop이 진행되기도 했습니다. 또한, Offline A/B Test는 추천 알고리즘 외에도 User-Interactive 시스템이나 상품 검색, 소셜미디어 피드 랭킹 등에도 적용 가능합니다.
Offline A/B Test의 추론 방법
Importance Weight 개념
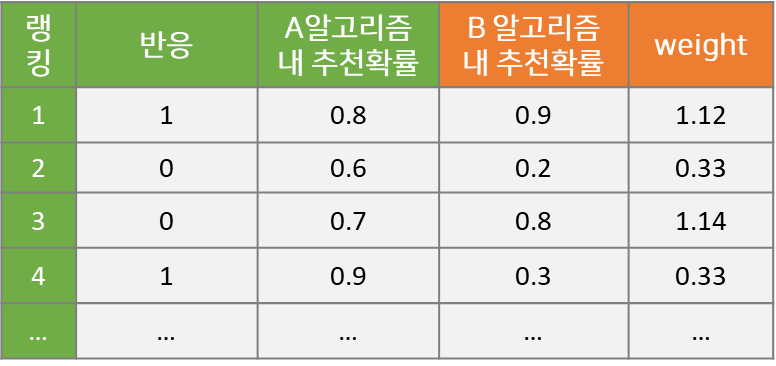
Offline A/B Test의 추론 방법에서 가장 중요하고 근간이 되는 Importance Weight 개념에 대해 설명드리겠습니다. 예를 들어, 아래와 같이 A 알고리즘을 통해 반응이 관측된 데이터가 있다고 가정해 봅시다.

어떤 사용자에게 3개 음악을 추천했을 때 2개 음악을 클릭하여 들었으니, A 알고리즘의 반응률은 2/3=66.6% 가 됩니다.
위 예시에서 각 음악이 1번~3번 순위로 추천되었지만, 추천 모델이 확률 기반의 Stochastic 알고리즘의 경우 각 음악이 k번째 추천될 확률이 존재합니다. 추천 순서를 결정하는 Score 값이 고정되지 않고, 분포에서 Sampling 되기 때문에 동일한 상황이더라도 추천 리스트가 달라질 수 있습니다. 즉, 아래 표와 같이 각 노래가 A 알고리즘을 통해 해당 랭킹으로 추천될 확률이 존재하는 것입니다.
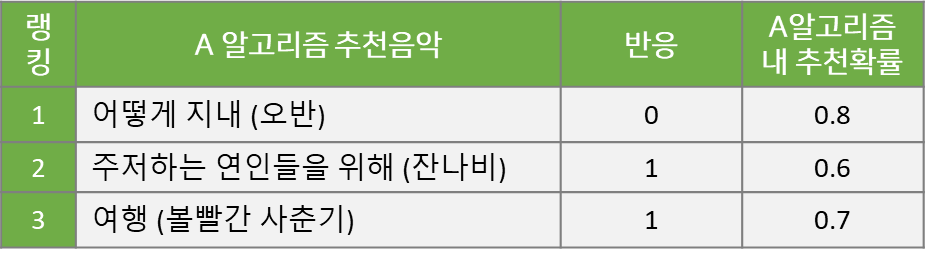
이 A 알고리즘의 추천확률에 B 알고리즘의 추천확률을 추가하는 것이 핵심입니다. B 알고리즘을 온라인에 적용하지 않았지만, 과거의 추천 상황을 재현하고 A 대신 B 알고리즘을 적용했을 때, 각 노래가 k번째 추천될 확률을 계산하는 것입니다. Monte Carlo Simulation을 활용해서, 예를 들어, 1,000번 추천 리스트를 생성해서 B 알고리즘이 '어떻게 지내'라는 노래를 첫번째로 노출시킬 확률을 계산합니다. B 알고리즘이 각 노래를 해당 랭킹으로 추천할 확률을 계산해서 아래 표에 추가 했습니다.
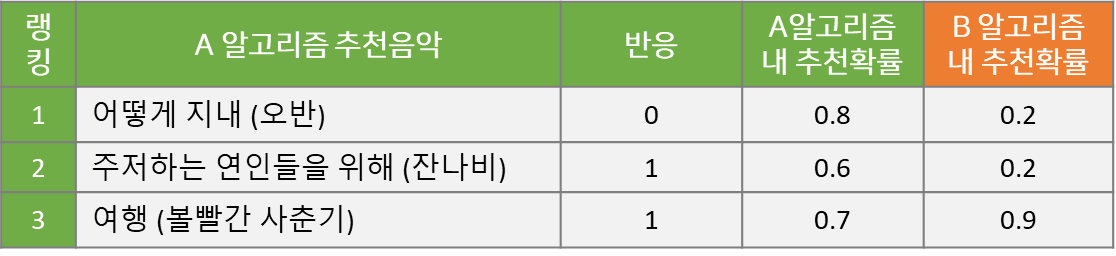
이와 같이 B 알고리즘 내 k번째 추천 확률을 계산한 다음, A 알고리즘의 해당 확률 값으로 나누어주면 다음과 같이 Importance Weight를 얻을 수 있습니다. 이 Weight는 두 알고리즘의 추천 확률이 동일하면 1이고, B 알고리즘의 추천 확률이 A보다 높은 값을 갖게 되면 1보다 크며, 반대의 경우 1보다 작습니다. 즉, 예시에서 1번과 2번에 랭킹된 노래는 A 알고리즘이 해당 랭킹에서 노출될 확률이 높고, 3번에 랭킹된 노래는 B 알고리즘에서 해당 랭킹에 노출시킬 확률이 높습니다.
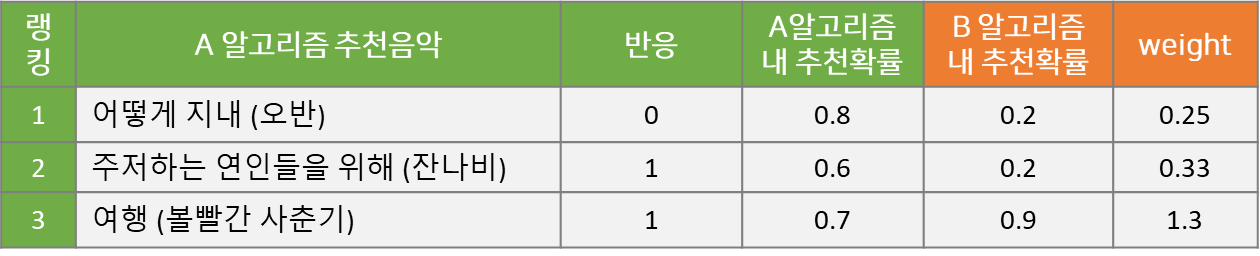
Importance Weight = (B 알고리즘 내 k번째 추천될 확률) / (A 알고리즘 내 k번째 추천될 확률)

IS, Importance Sampling
이와 같이 'B 알고리즘 기준으로 A에 비해 얼마나 추천될 확률이 높은지' 의미를 담고 있는 Importance Weight를 사용하여 사용자 반응을 보정해주는 방법이 Importance Sampling, IS 입니다.
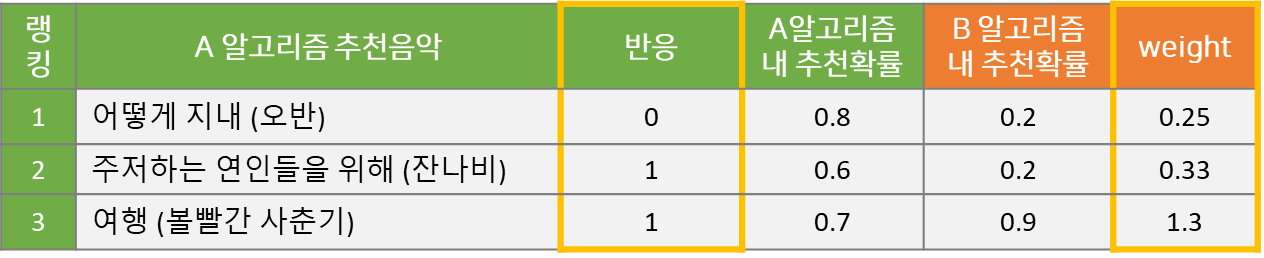

Importance Sampling을 통해 B 알고리즘의 반응률을 추정하면,
(0 + 0.33 + 1.3) / 3 = 1.63 / 3 = 54.3%
으로 계산됩니다.
그러나, IS 방법론에 단점이 있습니다. A 알고리즘에서 매우 낮은 확률로 노래가 추천되는 경우, 분모가 매우 작아지기 때문에 큰 Weight 값이 생성될 수 있다는 것입니다. 이 경우, 하나의 Weight가 전체 반응률 추정 결과에 큰 영향을 미치게 됩니다. 예시를 들어보겠습니다.
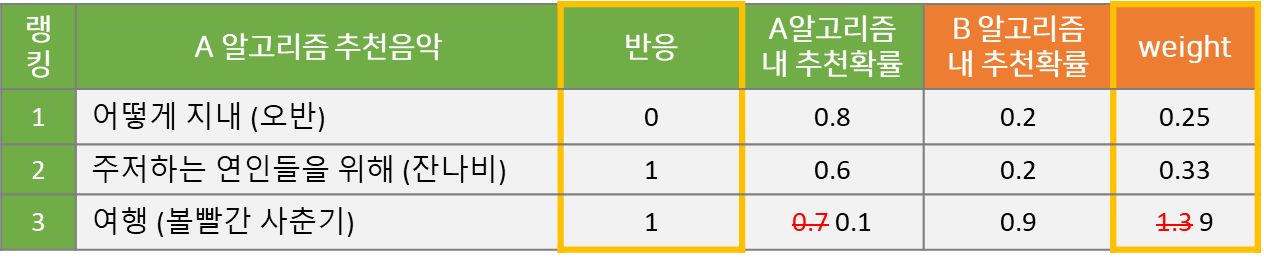
A 알고리즘에서 '여행' 추천 확률이 0.1로 떨어지게 되면 Weight가 기존 1.3에서 9로 상승하고, B 알고리즘의 반응률은,
(0 + 0.33 + 9) / 3 = 9.33 / 3 = 311%
가 됩니다. 게다가 반응률의 최대값은 100%인데, 비정상적으로 311%로 계산이 된 것입니다.
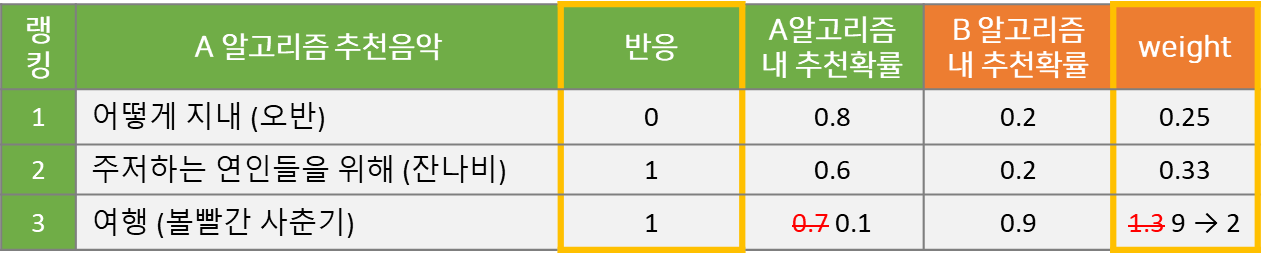
이런 문제를 해결하는 기법이 바로 Capping Importance Sampling, CIS 입니다. 특정 값 c보다 Weight가 클 경우 c로 대체시켜주는 방법입니다. 아래 표에서 c값을 임의로 2로 설정하여 에러를 최소화했고, B 알고리즘의 반응률은,
(0 + 0.33 + 2) / 3 = 2.33 / 3 = 77.6%
로 계산됩니다.

NCIS, Nomralized Capping Importance Sampling
앞서 설명한 CIS에서 Capping Weight 값의 합을 이용하여 아래 식과 같이 정규화하는 NCIS 방법론이 있습니다.

이 외에도 최적의 그룹별로 정규화한 pieceNCIS 기법과 데이터 하나씩 정규화하는 pointNCIS 기법 등 IS 방법론은 계속해서 발전하고 있습니다.
실제 서비스 적용 사례
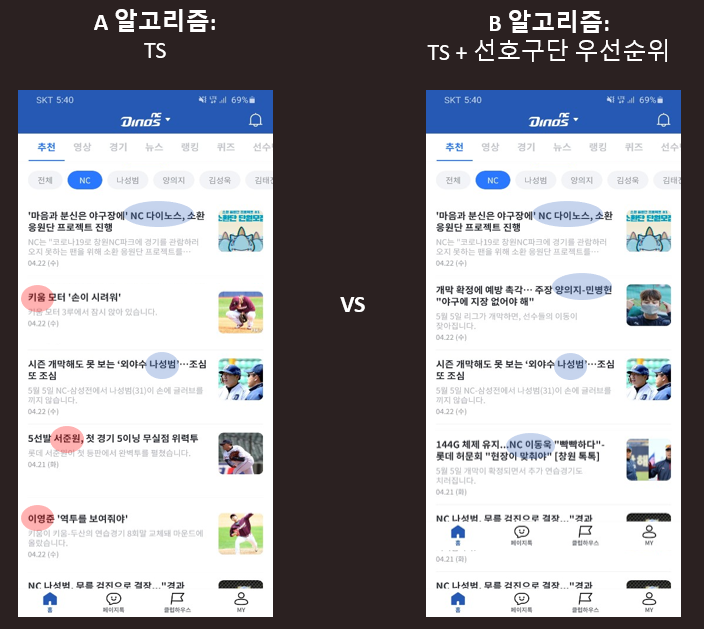
Offline A/B Test를 실제 서비스에 적용한 사례에 대해 말씀드리겠습니다. 적용한 서비스는 아쉽게도 '22.12.23일에 종료한 NC의 한국 프로야구 서비스 PAIGE입니다. 저희가 서비스에 적용할 당시, 추천영역은 PAIGE 홈탭이었고, 뉴스, 영상, 퀴즈, SNS 글 등 다양한 종류의 피드를 추천했습니다. 기본 추천 알고리즘으로 Multi-Armed Bandit에서 성능이 우수하다고 알려진 Thompson Sampling, TS를 사용하였습니다. TS는 이용 (Exploitation)과 탐색 (Exploration)을 적절하게 수행하며, 최신성과 인기를 반영하여 추천해주는 Stochastic 알고리즘입니다.
Thompson Sampling (TS)에 선호구단 Priority를 반영한다면?
그럼, 이제 Offline A/B Test 기법을 이용하여 실제 문제를 풀어보겠습니다. TS 알고리즘에 선호구단 우선순위를 적용한다면 반응률 측면에서 성능이 향상될까요?
B 알고리즘의 반응률을 추정하기 위해 먼저 A 알고리즘의 과거 사용자반응 데이터와 추천확률을 이용합니다. 그 다음, 앞서 설명드린 Monte Carlo Simulation 기법을 활용하여 B 알고리즘 내 추천 확률을 계산합니다. A 알고리즘은 TS, B 알고리즘은 선호구단 우선순위가 반영된 TS로, NC 선호구단에 대한 1, 3번째 피드는 B 알고리즘에서 추천된 확률이 높아 Weight가 높고, 2, 4번째 피드는 그렇지 않아 Weight가 낮은 것을 아래 표 예시에서 확인하실 수 있습니다.
이렇게 계산된 weight값을 이용하여 앞서 소개드린 IS, CIS, NCIS 에 적용시켜 보면 추정 반응률을 구할 수 있습니다.
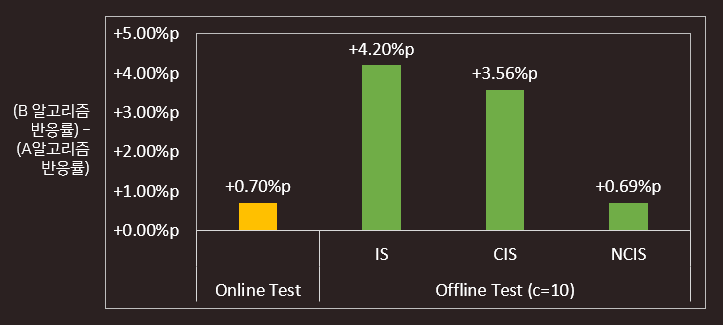
선호구단 Priority를 반영하면 NCIS 기준 0.69%가 상승할 것으로 예측하였고, 실제 온라인 테스트 결과도 0.7%p 상승으로 동일한 수준으로 예측하였습니다. 여러 연구에서 IS와 CIS보다 NCIS가 통상적으로 성능이 우수하다고 알려져 있는데, 이번 실험에서도 NCIS가 실제 값과 가장 유사하게 예측하는 것을 확인했습니다.
'사용자의 최근 반응'에 가중치를 부여한다면?
선호구단 Priority 반영 외에도, 계속해서 추천 알고리즘을 최적화시키고 더 성능이 좋을 것 같은 알고리즘을 찾기 위해 다른 시도를 해보았습니다. PAIGE는 경기가 진행되면 신규 컨텐츠 (또는 피드)가 계속 생성되는 서비스로, 컨텐츠에 대한 사용자의 반응이 시간에 따라 변화합니다. 따라서, 과거 사용자의 반응을 할인 (discount)해서 최근 반응의 가중치를 상대적으로 높이는 dTS (discounted TS) 알고리즘을 적용했습니다.
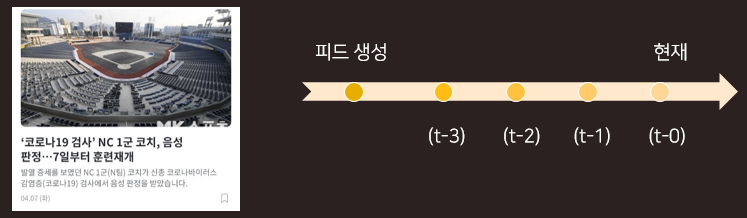
'탐색을 줄이고 이용을 더 많이 하도록' TS를 조정한다면?
마지막으로 dTS 알고리즘에 탐색을 줄이고 이용을 더 많이 하게 조정하는 기법을 적용하면 추천 성능에 도움이 될까요? TS에서 어떤 피드의 반응률이 좋을지 탐색하는 비중을 줄이고, 현재까지 축적된 데이터를 기반으로 반응률이 좋은 피드를 추천하도록 보정하는, dOTS (discounted Optimistic TS) 알고리즘을 적용했습니다.
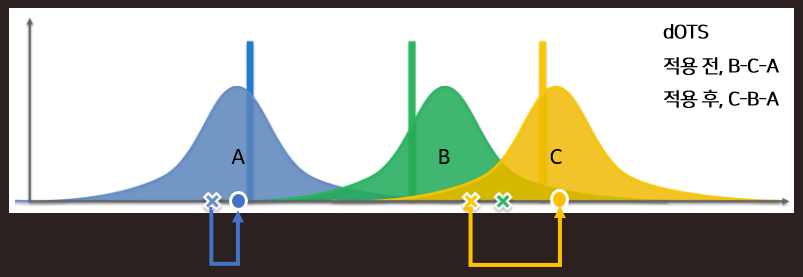
예시에서 각각 A, B, C 피드가 존재하고 각 피드의 추천될 분포가 다음과 같다고 가정했을 때, 실제로는 C분포의 반응률이 제일 좋아 C->B->A 순으로 노출되어야 하나, TS는 분포에서 샘플링한 값을 Score로 사용하기 때문에 B->C->A 순으로 추천될 것입니다. 그러나, dOTS 기법을 적용하면 Score값이 평균 이하로 뽑혔을 때 평균으로 대체시켜 주기 때문에 반응률이 가장 좋은 C->B->A 순으로 추천이 됩니다.
dTS와 dTOS의 Offline A/B 테스트 결과는 아래 그림과 같습니다. 사용자의 최근 반응에 가중치를 부여한 dTS의 성능 향상은 미미한 것으로 예측되었고, 탐색을 줄이고 이용을 더 많이 하도록 조정한 dOTS는 성능이 향상될 것으로 예측되었습니다.
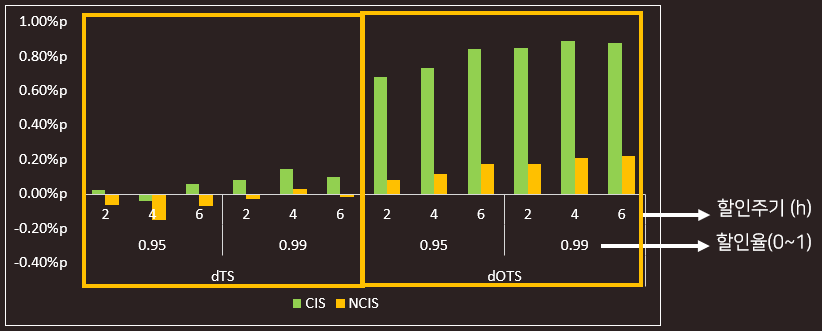
또한, dOTS에서 최근 반응의 가중치를 높이기 위해 설정하는 과거 데이터 할인율이 0.99%일 때, 과거 데이터 할인 주기는 4시간일 때 비교적 성능이 우수한 것을 확인할 수 있었습니다.
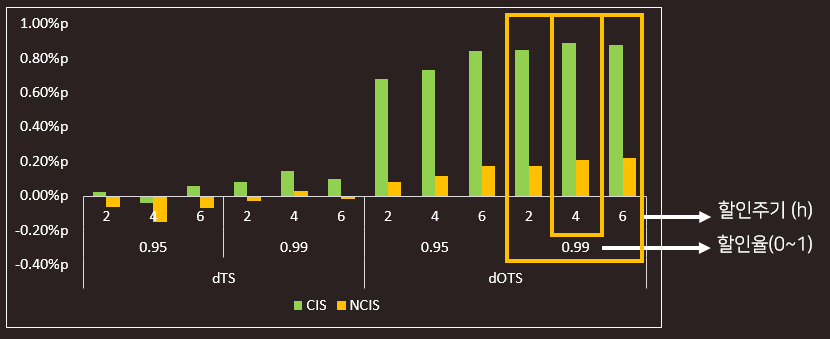
앞서 선호구단 Priority 실험과 달리, 실제 Online A/B 테스트 결과를 직접 비교하진 않았으나, 이후 dOTS 추천 알고리즘을 실제 서비스에 반영하여 서비스 버전 업 전까지 안정적으로 추천을 제공했습니다.
향후 연구
앞으로 더 발전시켜 나가야 하는 Offline A/B 테스트 연구 중 하나가 바로 Deterministic 알고리즘의 오프라인 성능 예측입니다. User-Item Pair에 대해서 추천 Score가 변하지 않기 때문에 앞서 설명 드린 추정방법론을 적용하기 어렵습니다. 이러한 문제를 보완하고자 랭킹 스코어 기반의 Weighted Sampling기법을 적용하여 추천확률을 계산하는 연구를 진행하고 있습니다.
또, 실제로 Offline A/B 테스트를 수행 하다보니 A와 B 알고리즘이 매우 다른 경우, 예를 들면, "Stochastic vs. Deterministic" 모델 간 비교, "Group Targeting vs. Personalization" 모델 간 비교 등의 경우, 에러를 최소화할 수 있는 Capping Function도 연구되면 좋겠습니다.
Reference
- https://ko.wikipedia.org/wiki/몬테카를로_방법
- https://abhadury.com/articles/2019-05/simulating-ab-tests
- Alois Gruson and et al., Offline Evaluation to Make Decisions About Playlist Recommendation Algorithms, WSDM 2019
- Olivier Jeunen, Revisiting Offline Evaluation for Implicit-Feedback Recommender Systems, In Proceedings of Thirteenth ACM Conference on Recommender Systems, Recsys 2019
- Alexandre Gilotte and et al., Offline A/B testing for Recommender Systems, WSDM 2018
- Vishnu Raj and et al., Taming Non-stationary Bandits: A Bayesian Approach, NIPS 2017
- Curation팀 정예원님이 연구하여 2020년 NCDP와 2021년 NDP에서 발표한 내용을, Applied AI Lab 김진선님이 Blog 글로 정리하였습니다.
