1.기술 개발 배경 및 목표
가.배경
저희 Applied AI Lab은 게임 외에도 연합뉴스나 페이지 같은 미디어 서비스를 위한 연구도 진행하고 있습니다. 게임과 미디어는 서로 다른 영역이지만 "고객"을 중심으로 동작하는 서비스라는 공통점을 가지고 있습니다. 고객을 기반으로 한 서비스들은 서비스의 품질을 올리고 더 많은 매출을 창출하기 위해서 고객의 요구사항, 관심사, 상황들을 이해하고 싶어합니다. 이를 위해서 기업들은 고객설문조사, Focus Group Interview를 통해 직접적으로 고객 데이터를 수집하거나, 제품의 매출정보등을 이용하여 간접적으로라도 고객의 니즈를 이해하기 위해 노력합니다. 하지만, Focus Group Interview나 설문조사는 적은 샘플로 인한 편향 이슈가 있고, 매출 정보를 통한 분석은 과거의 단편적인 경향만을 이해할 수 있다는 단점이 있습니다.
근래에 들어 많은 서비스들이 제공하는 웹 혹은 모바일 채널들이 이러한 어려움을 극복할 수 있는 실마리를 제공하고 있습니다.유저들이 웹이나 모바일( 게임이라면 인게임에서의 행동들 )서비스를 이용하면서 다양한 행동 로그를 남기는데, 이러한 로그를 통해 많은 유저들의 행동을 이해할 수 있게 되었습니다. 하지만 유저들이 남기는 로그의 양이 너무 많아 이를 활용하는 것도 쉽지 않은 일이기 때문에 대용량 데이터를 저장하기 위한 기술부터 대용량 데이터를 분석하고 시각화하기 위한 기술까지 다양한 분야에서 이런 큰 데이터를 쉽게 사용하기 위한 기술이 연구되고 있습니다. 이런 다양한 기술 영역중에서 저희 Applied AI Lab은 대용량 Sequence를 단순한 Sequence로 축약하는 기술 연구를 진행중이며, 이러한 축약 기술은 대규모 유저 집합에서 유저의 요구나 불편점을 이해하는데 도움을 주리라 기대하고 있습니다.
나.기술 목표
유저 행동은 행동시간과 행동정보를 가진 Sequence 형태의 데이터로 구성됩니다. 저희가 진행하는 Sequence 축약 연구를 Sequence 형태로 구성된 유저 행동 로그에 적용하면 복잡한 행동 흐름을 단순한 형태의 행동흐름으로 요약할 수 있습니다. 저희 랩은 이렇게 요약된 Sequence가 유저를 더 쉽고 직관적으로 이해하는데 도움을 줄 수 있다고 생각합니다. 여기서 "유저 행동의 요약"은 다양한 방식으로 해결할 수 있겠지만, 저희는 유저의 행동에 대한 Labeling이 필요하지 않는 Unsupervised 방법론을 중심으로 연구를 진행했습니다. 축약된 유저 행동에 대한 정답 데이터를 보유하지 못했다는 이유가 가장 컸고, 유저의 행동을 축약하는 것은 사람마다 기준이 다양해서 라벨링이 어렵다는 점이 두 번째 이유였습니다.
그리고 이 연구에서 유저 행동의 축약은 "유저의 숨겨진 의도를 파악하는 것"으로 정의했습니다. 유저의 의도는 우리가 직접 관측할 수는 없지만 다양한 행동으로 표출됩니다. 유저의 의도는 유저의 행동보다는 덜 다양할 것이기 때문에 유저의 행동 Sequence에서 유저 의도 Sequence를 찾아낸다면 유저의 복잡한 행동을 더 쉽게 이해할 수 있으리라 생각했습니다. 아래 <그림1>처럼 유저의 의도/상황은 "허기짐", "졸림" 두 가지 이지만 그 때 발생되는 유저의 행동은 더 다양하기 때문에 유저의 의도가 행동보다 더 단순한 Sequence이리라 가정한 것입니다.
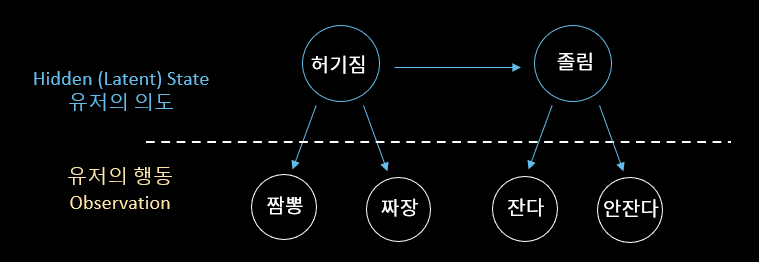 [그림1] 유저 의도 Sequence와 유저 행동 Sequence의 비교
[그림1] 유저 의도 Sequence와 유저 행동 Sequence의 비교
하지만, 유저의 현재 행동만으로 유저의 의도를 추론하기는 매우 어렵습니다. 아래 그림처럼 A연구실의 교수님은 기분이 나쁠때는 70프로 확률로 분노하지만, 기분이 좋을 때도 40프로의 확률로 분노하기에 현재 행동으로 기분을 추론하는 것은 어려운 일입니다. 하지만 교수님의 기분이 이전의 기분에 영향을 받고 있고, 교수님의 표현을 매일 Sequence형태로 관측할 수 있다면 좀 더 정확하게 교수님의 기분을 추론할 수 있을 것입니다.
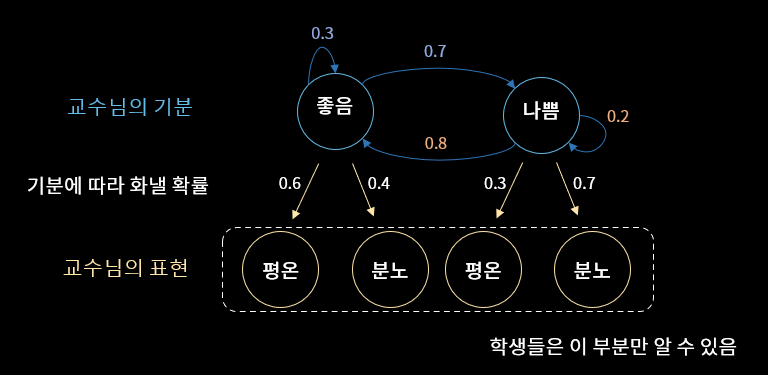 [그림2] 교수님의 기분전환 확률과 표현확률
[그림2] 교수님의 기분전환 확률과 표현확률
2.방법론 소개
가.Hidden Markov Model(HMM)
Hidden Markov Model을 설명하기 위해서는 우선 Makov 성질과 Markov Chain에 대한 설명이 필요할 것 같습니다. Makov 성질이란 "과거와 현재 상태가 주어졌을 때, 미래 상태는 과거와 상관없이 현재 상태에만 영향을 받는 성질"을 의미합니다. 이러한 Markov 성질을 따르는 이산 확률 과정을 Markov Chain( 혹은 Markov Process)라고 정의합니다. 아래의 <그림3>처럼 짜장/짬뽕중 오늘 먹을 메뉴는 어제 먹었던 메뉴에만 의존적이라면, 이 사람의 중식 취향은 Markov Chain이 됩니다.
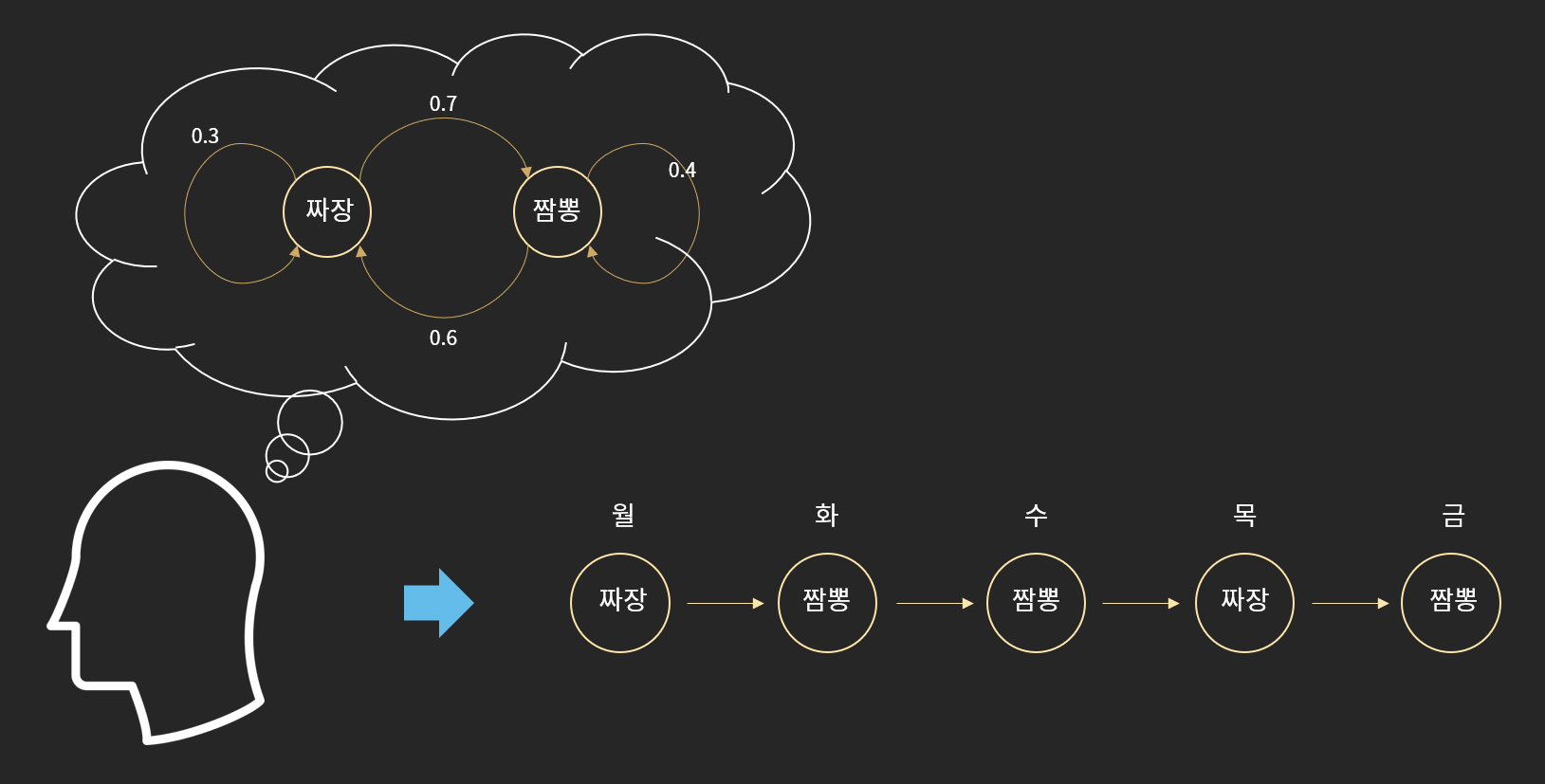 [그림3] Markov Process를 따르는 오늘의 메뉴 결정
[그림3] Markov Process를 따르는 오늘의 메뉴 결정
Hidden Markov Model의 변수는 Hidden( 혹은 Latent) State 변수와 관측변수(Observation), 두 가지로 분류됩니다. 이러한 설정에서 관측변수 분포가 Hidden State에 따라 결정이 되고, Hidden State Sequence는 Markov Chain인 Model을 Hidden Markov Model이라고 합니다. 아래 그림에서 X(관측변수)의 분포는 Z(Hidden State)에 의존하고 있고, Z(Hidden State)는 직전의 Z(Hidden State)에만 의존하는 것을 도식화한 것으로 HMM을 표현한 것입니다.
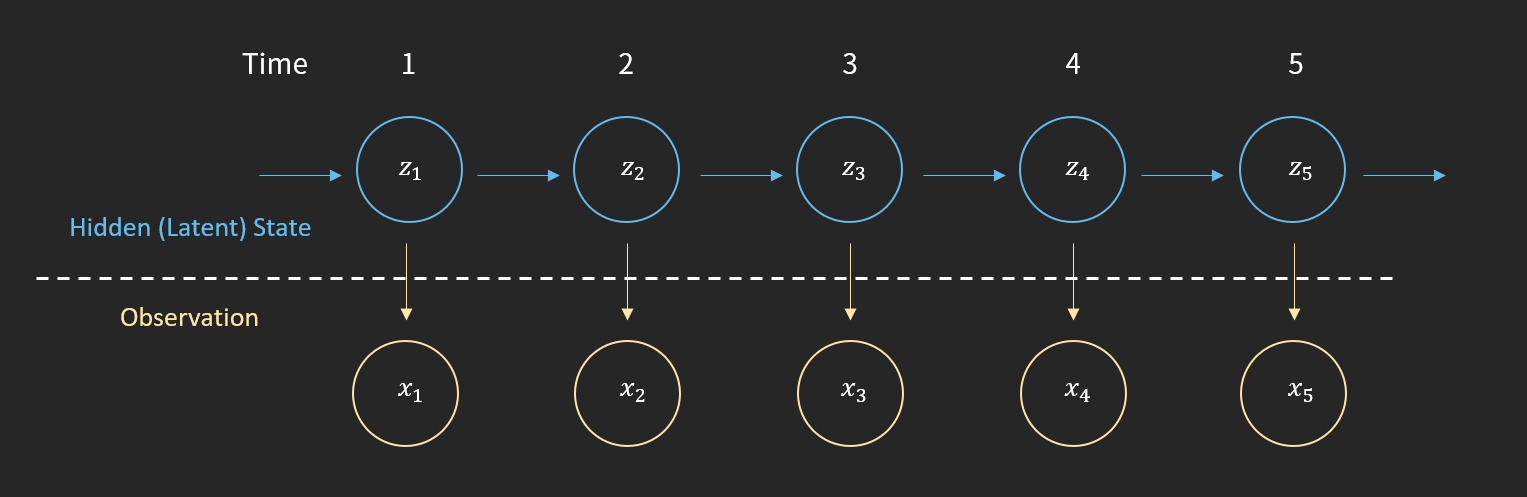 [그림4] Hidden Markov Model 구조
[그림4] Hidden Markov Model 구조
예를 들어 설명하기 위해서 앞에서 언급했던 우리 교수님을 다시 모시고 오겠습니다. 앞에서 얘기했던 것처럼 학생들은 교수님의 분노여부(관측변수)는 관측할 수 있지만, 실제로 교수님의 기분(Hidden State)이 좋은지 알 수는 없습니다. 학생들이 교수님의 분노이력을 이용해서 오늘의 기분을 추론해야한다고 할 때, HMM은 매우 유용할 수 있습니다.
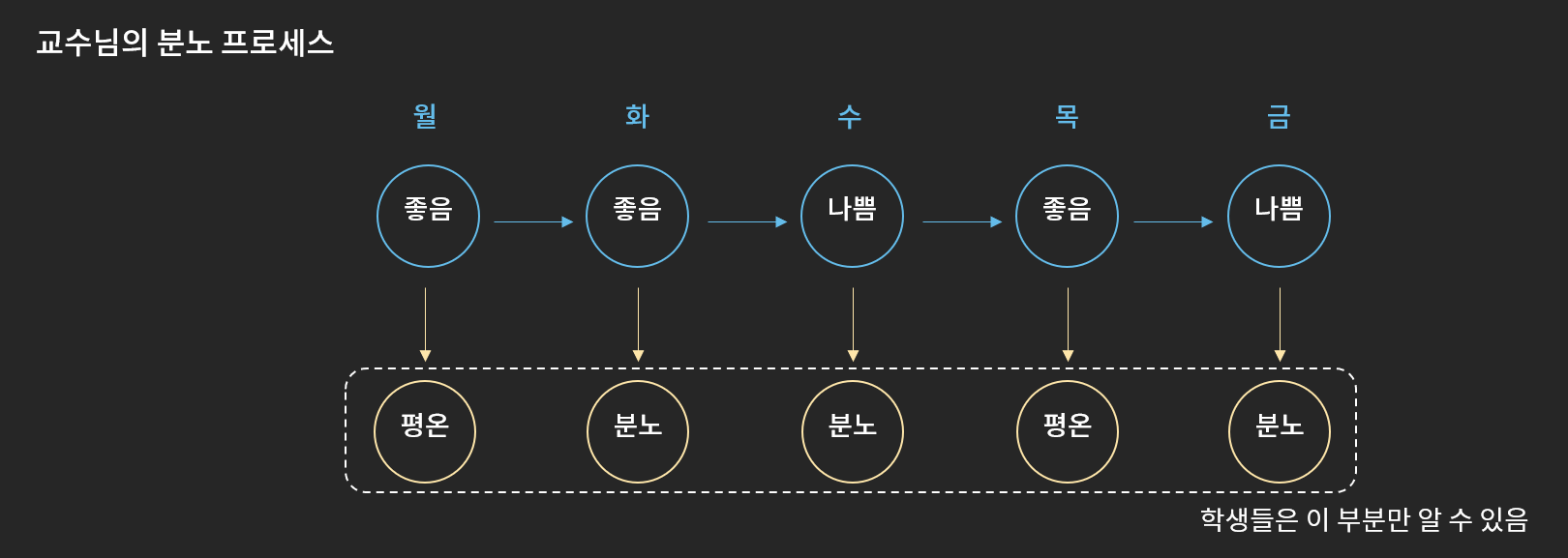 [그림5] 교수님의 분노 프로세스
[그림5] 교수님의 분노 프로세스
우리는 HMM을 이용해서 교수님의 기분(Hidden State) 전환 확률( 오늘 기분에 따라 내일 기분이 결정될 확률분포 ), 교수님의 기분에 따른 분노확률 분포를 추론할 수 있고 이 두 Parameter를 이용해 오늘 교수님의 기분을 추론할 수 있습니다. 유저의 행동만 관측할 수 있고, 유저의 행동은 유저의 의도에 따라 결정이 된다는 점에서 우리의 문제는 HMM의 설정과 매우 닮아 있기 때문에 HMM을 통해 우리의 문제를 풀어보려 합니다. HMM 모델 구조에서 각 parameter( 기분전환확률, 기분에 따른 분노확률 )를 추정하는 것은 어려운 일입니다. 보통 EM Algorithm의 특수한 경우인 Baum-Welch Algorithm을 이용하여 parameter를 추론하며, 계산 효율성을 올리기 위해 다양한 방법들이 개발되어 있습니다. 현재 다양한 언어에서 HMM을 구현하기 위한 라이브러리를 제공하고 있습니다.
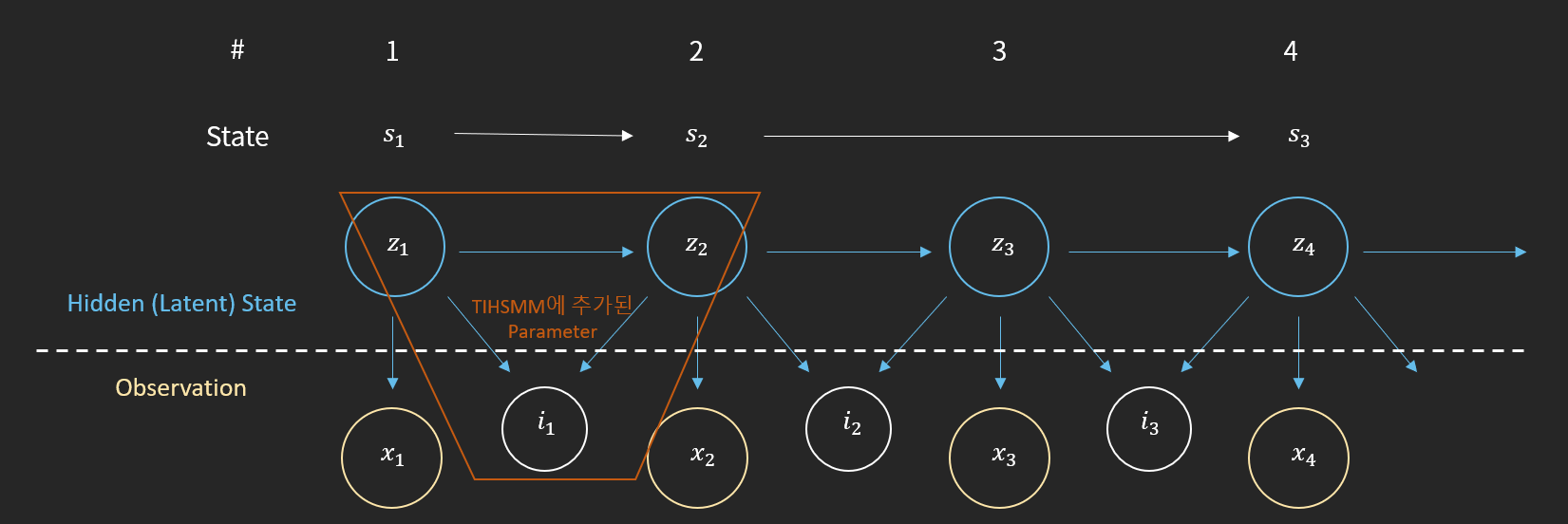
나.Time Interval Hidden Semi Markov Model(TIHSMM)
이렇게 교수님의 기분을 추론하여 아슬아슬하게 평화를 유지하던 중 한 학생이 교수님의 기분은 매일 매일 급변하지 않을 것이기 때문에 이런 부분을 모델에 반영해야한다고 주장합니다. 아무래도 한 번 기분이 좋으면 그것이 며칠은 갈 것이기 때문에 일정기간 기분이 유지될 가능성을 HMM에 녹여야한다는 주장입니다. 이러한 가정을 해결하기 위해 나온 방법론이 Hidden Semi Markov Model입니다. HSMM은 HMM과 다르게 하나의 State가 유지되는 duration을 parameter로 추가하여 모델 학습에서 추론하게 됩니다. 이 학생의 Idea와 노력으로 우리는 교수님이 기분이 며칠이나 유지되는지 추론할 수 있게 되었고 학생들은 교수님에 대해 더 깊게 이해할 수 있게 되었습니다.
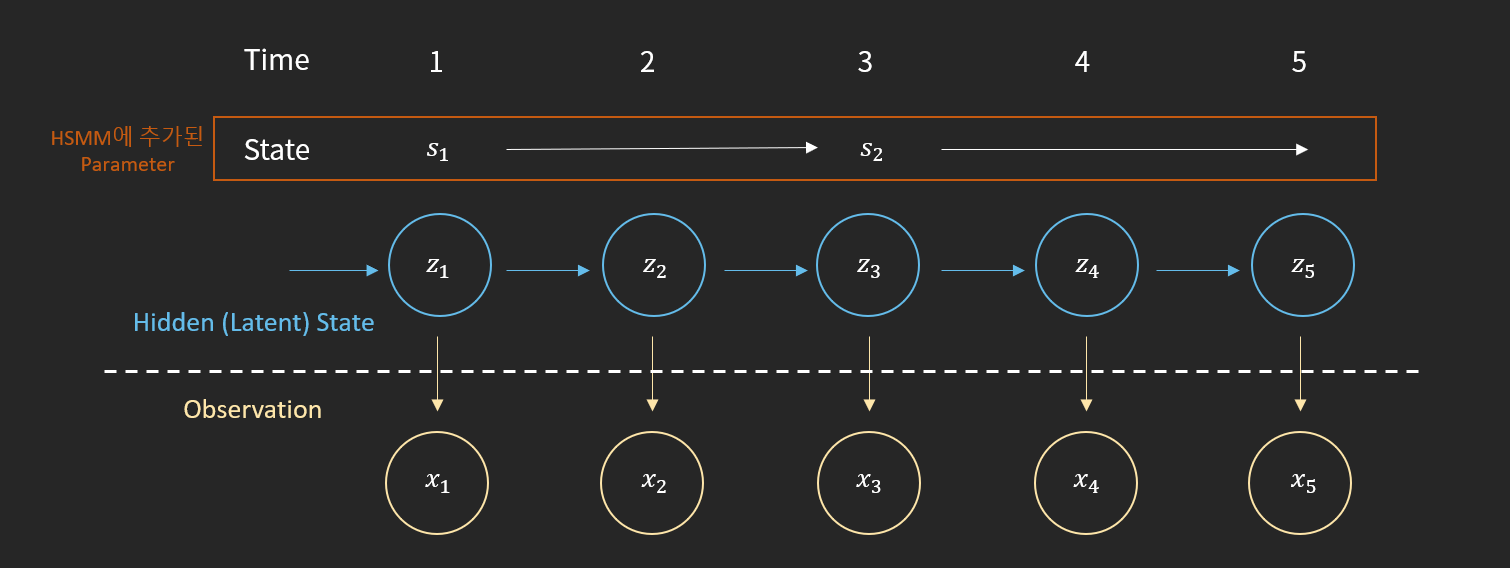 [그림6] Hidden Semi Markov Model 구조
[그림6] Hidden Semi Markov Model 구조
하지만, 교수님의 기분을 파악하기 위해 사용한 HSMM으로도 유저들을 이해하기에 조금 아쉬운 점이 있었습니다. 유저들이 특정행동을 한 후 다른 행동을 취하기까지 소요된 시간이 유저들을 이해하는데 유용할 것 같은데 HSMM에서는 이런 행동간 시간 차이를 이용할 수 없습니다. 이를 개선하기 위해서 저희 랩에서 Time interval HSMM이라는 방법론을 개발하여 적용해보았습니다. 이 모델은 HSMM에서 선후행동에 따른 시간갭의 분포를 Parameter로 추가한 모델입니다.
이 모델을 통해 유저가 동일한 행동을 보이더라도 그 행동사이의 시간에 따라 유저의 의도를 다르게 추론할 수 있으리라 기대했습니다.
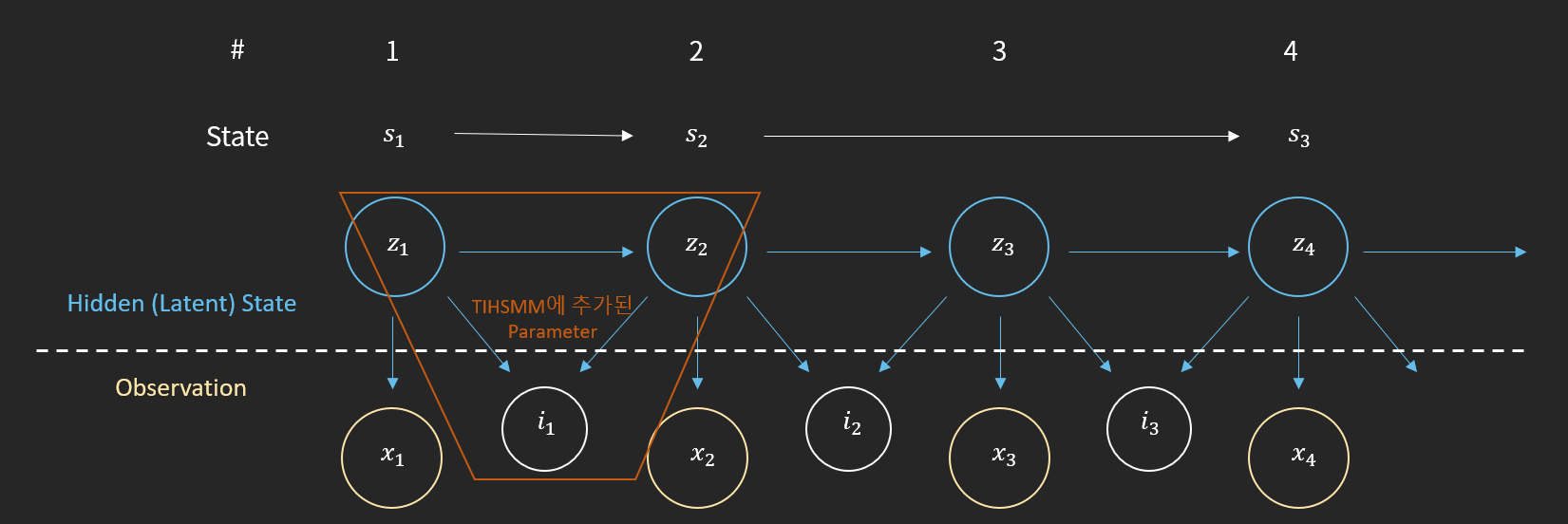 [그림7] Time Interval Hidden Semi Markov Model 구조
[그림7] Time Interval Hidden Semi Markov Model 구조
3.실험 및 평가방법
가.데이터
저희는 2020년 한 해 동안 게임에서 수집된 유저 행동 로그를 이용하여 위의 세 가지 방법론을 비교했습니다. 유저 행동 로그에서 불필요한 로그는 필터링하고, 유저단위로 시간 및 수집순서에 따라 정렬된 로그를 Sequence 데이터로 구성했습니다. 그리고 방법론들을 비교 평가하기 위해서 정답 데이터를 직접 생성했습니다. 유저의 의도는 정답을 알 수 없기 때문에 아래 그림처럼 세 명의 작업자가 작업한 후 다수의견에 따라 정답을 구성했습니다. 작업자가 유저의 의도를 잘 추론할 수 있도록 유저 행동의 전후 맥락정보를 제공하여 Tagging을 진행했고, 유저의 의도를 24가지로 미리 정의하여 Tagging을 진행했습니다.
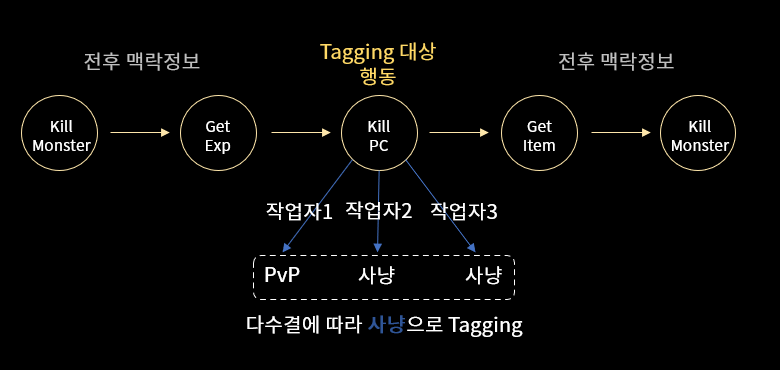 [그림8] 유저 의도 Tagging 작업
[그림8] 유저 의도 Tagging 작업
나.평가방법
우리가 각 방법론을 검증한 가설과 그에 대한 평가지표는 아래와 같습니다.
- 추론된 유저의 의도가 정답 데이터와 얼마나 일치하는가? - F1 Score/Accuracy, V-Measure[3], Variation of Information(VI)[4]
- 추론된 유저 의도 subsequence가 정답 데이터와 얼마나 일치하는가? - Segment Accuracy, TransitionF1 score/accuracy
- 사례검토 - 정성평가
첫번째로는 Sequence를 구성하는 Token 단위 성능을 평가하기 위해 익숙한 평가지표 네 가지를 이용했습니다. 이 중 V-Measure와 VI는 Clustering 성능을 판단하는 지표로써 아래 참고 자료를 통해 상세히 확인하실 수 있습니다. 하지만 Token단위 평가만으로는 아래 <그림9>와 같은 상황처럼 유저의 의도가 일정시간 유지된다는 부분을 평가하기 어렵습니다. 그래서 유저 의도 Subsequence( 편의상 segment라 부르겠습니다.)가 잘 구성되었는지 확인하기 위해서 Segment Recall와 Transition 지표를 도입하여 Segment 단위 평가 또한 진행했습니다.
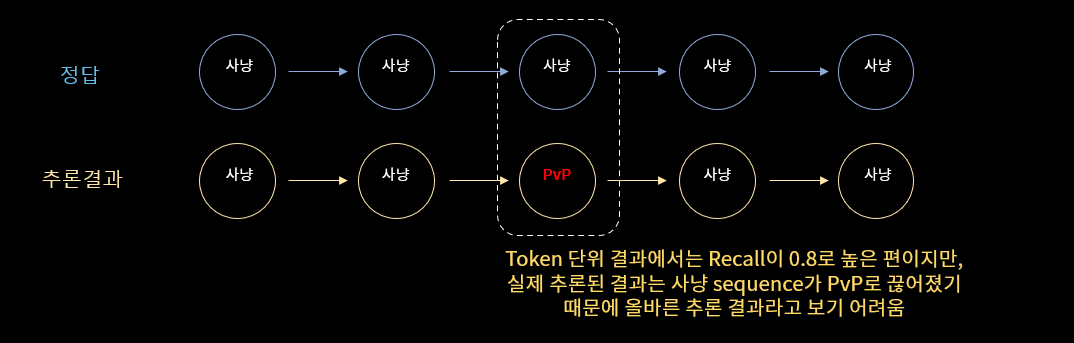 [그림9] Segement 단위 평가 이유
[그림9] Segement 단위 평가 이유
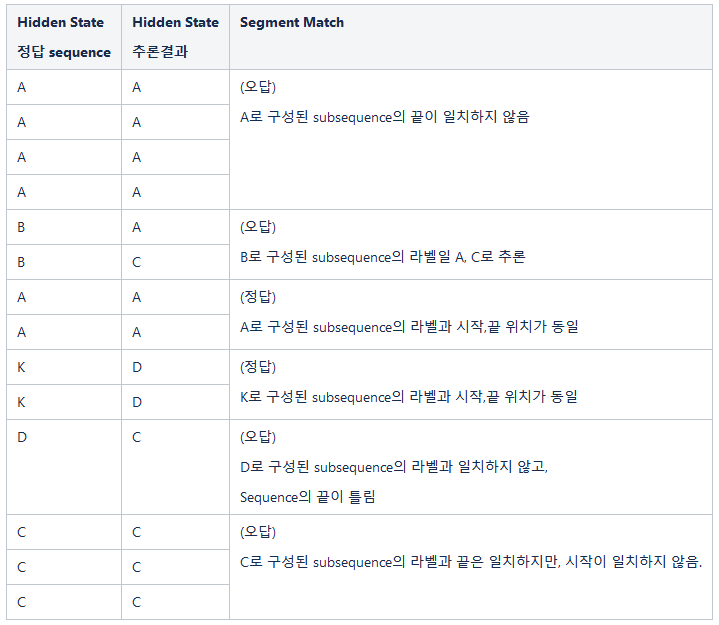
Segment Recall이란 아래 <표1>처럼 정답의 Segment를 기준으로 추론된 Segment와 시작과 끝이 일치하고, 그 Label도 일치하면 정답으로 인정하는 지표입니다. Segment의 시작과 끝이 어긋나거나 Label이 일치하지 않으면 오답으로 처리되기 때문에 유저 의도 Subsequence가 잘 유지되는지 평가하기에 적합한 지표입니다. 그리고 유저의 행동변화 시점 추론 성능을 확인하기 위해 Transition 지표를 확인했습니다. 정답 데이터에서 발생한 Transition 시점에 모델이 잘 추론했는지 확인하기 위해 Transition Recall값을 확인했고, 전체적인 성능을 비교하기 위해 F1 score값도 확인했습니다.
[표1] Segment Recall 계산 예제 : 정답 Sequence 및 추론된 Sequence의 비교
다.실험결과
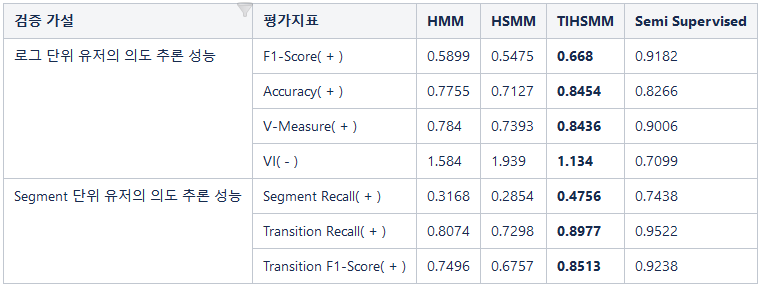
로그 및 Segment 단위로 각각 성능을 검증한 결과, 행동간 시간 차이를 이용한 TIHSMM이 HMM이나 HSMM에 비해 더 좋은 성능을 보인다는 것을 확인할 수 있었습니다. 그리고 실제 라벨을 활용한 Semi Supervised 모델보다 전반적으로 성능은 떨어지지만, 로그단위의 Accuracy 및 V-Measure가 Semi-supervised에 근접하고 있고, Transition에 대한 성능도 격차가 적어 TIHSMM이 라벨을 전혀 활용하지 않았다는 점을 고려하면 실무에 적용해볼 수 있는 유용한 기술이라고 생각합니다.
[표2] 방법론 성능 비교
4.결론 및 한계
많은 서비스에서 유저의 행동 로그를 수집 및 활용하여 유저를 잘 이해하기 위해 노력하고 있습니다. 유저 이해를 위해서 다양한 관점에서 기술이 개발이 되고 있는데, 저희는 행동으로부터 유저의 의도를 추론할 수 있는 기술을 개발하고자 했고 HMM기반의 방법론 연구는 이러한 목표를 달성하기에 좋은 연구였다고 생각합니다.
이 방법론들은 라벨이 없어도 사용가능하기 때문에 실무에 바로 적용해볼 수 있다는 장점이 있고, 라벨을 활용하지 않았음에도 라벨을 활용한 모델의 성능과 큰 차이가 나지 않는다는 것도 긍정적인 부분입니다. 또한, 이 번 연구를 통해 유저 행동간 시간 차이가 유저를 이해하는데 중요한 정보임을 같이 확인할 수 있었습니다.
TIHSMM도 기존 HMM방법론의 단점을 그대로 보유하고 있습니다. 앞서 유저의 의도를 미리 24가지라고 설정한 것처럼 상태의 개수를 미리 결정해줘야하고, 추론된 상태에 대한 정보들을 보고 사람의 해석이 필요하기에 사람이 많은 부분 관여해야 합니다. 그리고 이 연구에서는 유저의 의도가 24개라 가정했는데, 실제로는 사람의 욕구는 더 다양하기에 유저의 의도( Hidden State)가 매우 많은 상황에도 적용가능한지 검토가 필요할 것 같습니다.
저희 랩은 이러한 단점을 보완하기 위해 방법론을 지속적으로 개선하고 있으며, 실제 서비스에 활용하기 위한 완성도를 높이기 위해 계속 노력해가고 있습니다.
Reference
[1] Baum, L. E.; Petrie, T. "Statistical Inference for Probabilistic Functions of Finite State Markov Chains". The Annals of Mathematical Statistics. 37 (6): 1554–1563, (1966)
[2] Yu, Shun-Zheng, and Hisashi Kobayashi. "Practical implementation of an efficient forward-backward algorithm for an explicit-duration hidden Markov model." IEEE Transactions on Signal Processing 54.5 (2006)
[3] Andrew Rosenberg and Julia Hirschb, "V-measure : A conditional entropy-based external cluster evaluation measure, EMNLP-CoNLL, (2007)
[4] Meila, M. "Comparing clusterings-an information based distance", journal of multivariate analysis, (2007)
