
1편에서 Bedrock을 살펴보았고, API를 당겨와서 간편하게 사용할 수 있음을 확인하였다.
아키텍처를 구축하기 전에 Bedrock API를 활용해 FM과 대화를 나눌 수 있는 간단한 챗봇을 만들어 보고자 한다. 터미널에서 실행할 수 있는 간단한 챗봇 코드를 만들어보자.
현재 아키텍처는 아래 그림과 같다.
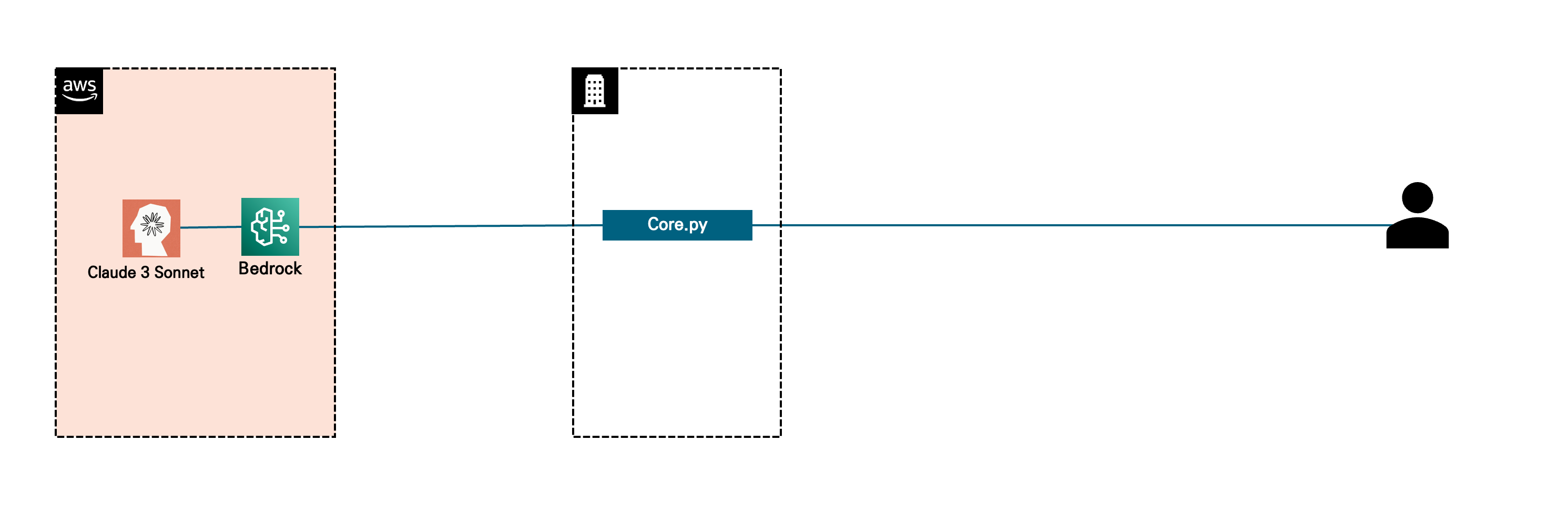
Core.py에서 서비스를 간편하게 만들기 위해서 가장 널리 쓰이는 프레임워크인 langchain을 사용할 것이다.
from langchain_aws import ChatBedrock
from langchain_core.callbacks import BaseCallbackHandler
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory먼저 응답을 실시간으로 출력하기 위해 ConsoleCallbackHandler 클래스를 정의한다. 토큰 단위로 on_llm_new_token 함수를 호출해 글자 단위로 바로바로 답변 스트림이 출력되도록 할 것이다.
class ConsoleCallbackHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs):
print(token, end='', flush=True)이어서 앞서 살펴본 Bedrock API를 모델로 불러오자. 여기서는 Claude 3 Haiku 모델을 사용하였다.
model = ChatBedrock(
model_id="anthropic.claude-3-haiku-20240307-v1:0",
streaming=True,
callbacks=[ConsoleCallbackHandler()],
model_kwargs={
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 3000,
"temperature": 0.1
}
)LLM 에이전트가 이전 대화를 모두 기억할 수 있도록 (정확히는 대화가 누적되어 전달되도록) 메모리 개체를 설정하고, 또 사용자 입력과 메모리를 연결해 대화 맥락을 유지하도록 Chain 개체도 설정해야 한다.
memory = ConversationBufferMemory()
chain = ConversationChain(llm=model, memory=memory)이렇게 만든 개체들을 바탕으로 루프를 만들어 대화를 나누어보자.
사용자가 지정한 종료어 (종료, quit)이 입력되기 전까지 루프 안에서 대화가 이루어진다.
# 대화 루프
while True:
user_input = input("\nYou: ")
if user_input.lower() in ['종료', 'quit']:
print("대화를 종료합니다.")
break
print("\nAssistant: ", end='')
response = chain.predict(input=f"\n\nHuman: {user_input}\n\nAssistant:")
print("\n") # 응답 후 새 줄 추가코드를 실행하면 다음과 같이 이전 맥락을 기억하여 대화가 반복적으로 이루어짐을 볼 수 있다.

이제 이 구조를 AWS로 옮겨 보자.

딴짓 좋아하는 데이터쟁이