transforms.v2
기존의 transforms v1 최적화가 부족하여 느리다.
v2는 텐서기반으로 훨씬 빠르게 작동한다.
일부 메소드는 PIL형태의 이미지를 그대로 넣어도 작동하나 ToImage 메소드를 통해 텐서로 변환 후 사용하는 것을 권장한다.
1. 변환 파이프라인/조합
1.1 Compose
- 여러 개의 변환(transform)을 순차적으로 적용할 수 있는 파이프라인을 만든다.
- 리스트 형태로 변환들을 입력받아, 입력 이미지를 차례로 각 변환에 통과시킨다.
사용예시
import torchvision.transforms.v2 as v2
import torch
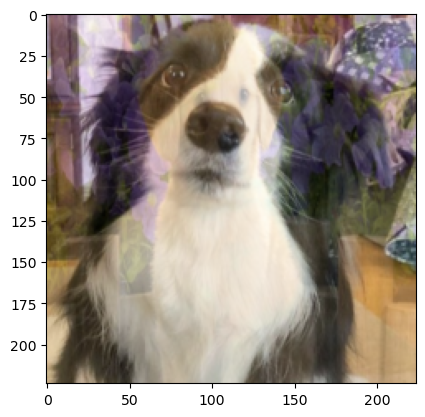
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Resize((224, 224))
])
transformed_image = transform(image)
plt.imshow(transformed_image.permute(1, 2, 0))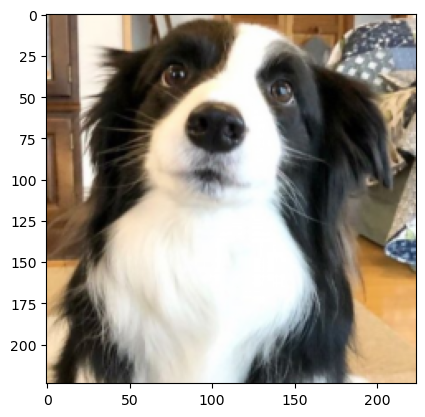
1.2 RandomApply
- 지정한 변환(transform) 리스트를 일정 확률로 적용한다.
- 파라미터 설명:
transforms: 적용할 변환 리스트p: 변환을 적용할 확률(기본값 0.5)
사용예시
transform = v2.RandomApply([
v2.ColorJitter(brightness=0.5)
], p=0.3)
transformed_image = transform(image)1.3 RandomChoice
- 여러 변환 중 하나를 랜덤하게 선택하여 적용한다.
사용예시
transform = v2.RandomChoice([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomVerticalFlip(p=1.0)
])
transformed_image = transform(image)2. 타입/데이터 변환
2.1 ToImage
- 입력 데이터를 torch.Tensor 이미지 객체로 변환한다.
- 주로 numpy 배열이나 PIL 이미지를 torch.Tensor로 변환할 때 사용한다.
- Compose 파이프라인의 첫 단계로 자주 사용한다.
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.Resize((128, 128))
])
transformed_image = transform(image)2.2 ToDtype
- 이미지의 데이터 타입을 변경한다.
- 파라미터 설명:
dtype: 변경할 데이터 타입(예: torch.float32, torch.uint8 등)scale: 정수형 이미지를 float으로 변환할 때 0~1로 정규화할지 여부(기본값 False)
- 주로 모델 입력 전에 float32로 변환하고, scale=True로 0~1 정규화를 함께 사용한다.
사용예시
#ToDtype
import torch
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
transformed_image = transform(image)2.3 ToPILImage
- 입력 이미지를 PIL.Image 객체로 변환한다.
- 주로 torch.Tensor나 numpy array를 PIL 이미지로 변환할 때 사용한다.
- 시각화나 PIL 기반 함수 사용 시에 활용한다.
사용예시
#ToPILImage
transform = v2.Compose([
v2.ToImage(),
v2.ToPILImage()
])
pil_image = transform(image)3. 정규화/스케일링
3.1 Normalize
- 이미지의 픽셀 값을 각 채널별로 정규화한다.
- 주로 모델 학습 전에 데이터 분포를 맞추기 위해 사용한다.
- 파라미터 설명:
mean: 각 채널별 평균값(리스트 또는 튜플, 예: [0.485, 0.456, 0.406])std: 각 채널별 표준편차(리스트 또는 튜플, 예: [0.229, 0.224, 0.225])
- 각 채널별로 (값 - mean) / std 연산이 적용된다.
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
normalized_image = transform(image)
plt.imshow(normalized_image.permute(1, 2, 0))
4. 크기/비율/자르기 관련
4.1 Resize
- 이미지를 지정한 크기로 리사이즈한다.
- 파라미터 설명:
size: 원하는 출력 크기(튜플 또는 정수)interpolation: 보간 방법(기본값은 bilinear)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.Resize((32, 32))
])
resized_image = transform(image)
plt.imshow(resized_image.permute(1, 2, 0))출력
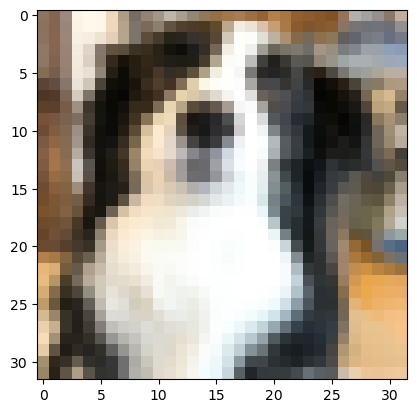
4.2 CenterCrop
- 이미지의 중앙을 기준으로 지정한 크기만큼 잘라낸다.
- 파라미터 설명:
size: 잘라낼 크기(정수 또는 튜플)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.CenterCrop(200)
])
cropped_image = transform(image)
plt.imshow(cropped_image.permute(1, 2, 0))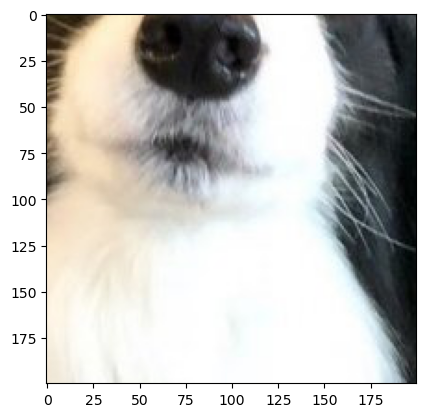
4.3 RandomCrop
- 이미지의 임의 위치에서 지정한 크기만큼 잘라낸다.
- 파라미터 설명:
size: 잘라낼 크기(정수 또는 튜플)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomCrop(128)
])
cropped_image = transform(image)
plt.imshow(cropped_image.permute(1, 2, 0))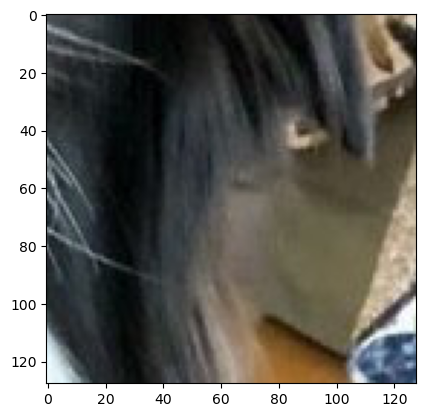
4.4 RandomResizedCrop
- 이미지를 임의의 영역에서 잘라내고, 지정한 크기로 리사이즈한다.
- 파라미터 설명:
size: 출력(리사이즈) 크기(정수 또는 튜플)scale: 원본 가로/잘라낼 영역 가로, 원본 세로/잘라낼 영역 세로, 기본값 (0.08, 1.0)ratio: 잘라낼 영역의 가로/세로 비율의 범위, 기본값 (3/4, 4/3) : 가로/세로 = 3/4 ~ 4/3
사용예시
from torchvision.transforms.functional import InterpolationMode
transform = v2.Compose([
v2.ToImage(),
v2.RandomResizedCrop(
size=(224, 224),
scale=(0.5, 0.5),
ratio=(0.75, 1.25),
interpolation=InterpolationMode.BILINEAR,
antialias=True
)
])
cropped_image = transform(image)
plt.imshow(cropped_image.permute(1, 2, 0))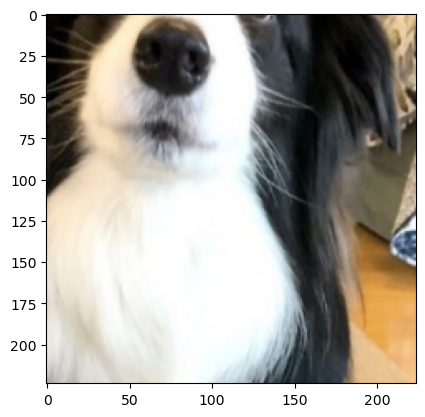
4.5 Pad
- 이미지의 가장자리에 지정한 크기만큼 패딩을 추가한다.
- 파라미터 설명:
padding: 패딩 크기(정수, 튜플)fill: 패딩 영역의 색상(기본값 0)padding_mode: 패딩 방식('constant', 'edge', 'reflect', 'symmetric' 등)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.Pad(padding=50, fill=128)
])
padded_image = transform(image)
plt.imshow(padded_image.permute(1, 2, 0))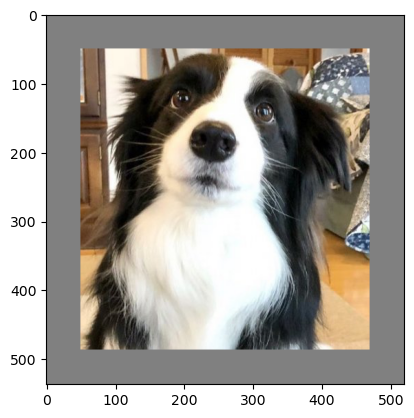
5. 기하학적 변환
5.1 RandomRotation
- 이미지를 임의의 각도로 회전시킨다.
- 파라미터 설명:
degrees: 회전 각도 범위(정수 또는 튜플, 예: 30이면 -30도~+30도 사이에서 랜덤)interpolation: 보간 방법(기본값 'nearest')expand: True로 설정하면 회전 후 이미지 크기를 확장해서 잘림을 방지한다(기본값 False)center: 회전 중심(기본값은 이미지 중앙)fill: 회전으로 생긴 빈 영역의 색상(기본값 0)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomRotation(
degrees=45,
interpolation=InterpolationMode.BILINEAR,
expand=True,
fill=128
)
])
rotated_image = transform(image)
plt.imshow(rotated_image.permute(1, 2, 0))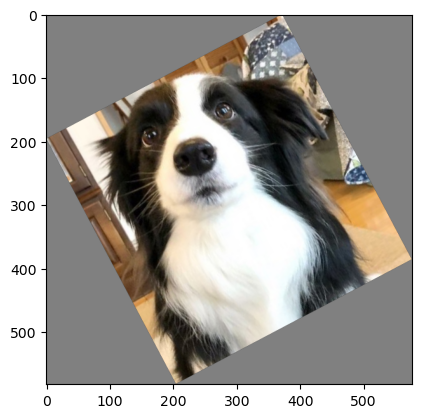
5.2 RandomHorizontalFlip
- 이미지를 일정 확률로 수평(좌우) 뒤집는다.
- 파라미터 설명:
p: 뒤집을 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomHorizontalFlip(p=0.7)
])
flipped_image = transform(image)
plt.imshow(flipped_image.permute(1, 2, 0))5.3 RandomVerticalFlip
- 이미지를 일정 확률로 수직(상하) 뒤집는다.
- 파라미터 설명:
p: 뒤집을 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomVerticalFlip(p=0.3)
])
flipped_image = transform(image)
plt.imshow(flipped_image.permute(1, 2, 0))5.4 RandomAffine
- 임의의 아핀 변환(이동, 회전, 확대/축소, 기울이기 등)을 적용한다.
- 파라미터 설명:
degrees: 회전 각도 범위(필수)translate: 가로, 세로의 이동 범위 비율scale: 확대/축소 범위shear: 기울임 각의 최대값(혹은 범위)- a - x축 방향으로 최대 a도
- (a, b) - x축 방향 최대 a도, y축 최대 b도
- (a, b, c, d) - x축방향 a~b도, y축 c~d도
interpolation: 보간 방법(기본값 'nearest')fill: 변환 후 생긴 빈 영역의 색상(기본값 0)center: 변환 중심(기본값 이미지 중앙)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomAffine(
degrees=30,
translate=(0.5, 0.5),
scale=(0.8, 1.2),
shear=30,
interpolation=InterpolationMode.BILINEAR,
fill=100
)
])
affined_image = transform(image)
plt.imshow(affined_image.permute(1, 2, 0))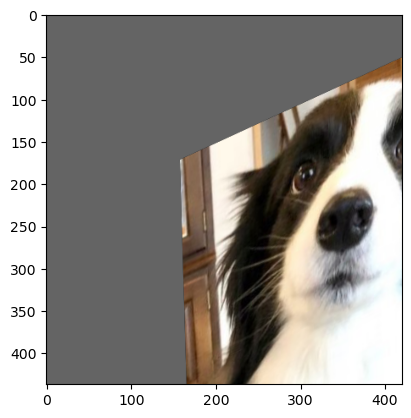
5.5 RandomPerspective
- 이미지를 임의로 원근 변환(perspective transform)한다.
- 원근변환이란 사진의 모서리를 이동시켜 사진을 변환한다.
- 파라미터 설명:
distortion_scale: 모서리의 최대 이동 거리(0~1, 기본값 0.5)p: 변환 적용 확률(기본값 0.5)interpolation: 보간 방법(기본값 'bilinear')fill: 변환 후 생긴 빈 영역의 색상(기본값 0)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomPerspective(
distortion_scale=0.7,
p=1.0,
fill=255
)
])
perspective_image = transform(image)
plt.imshow(perspective_image.permute(1, 2, 0))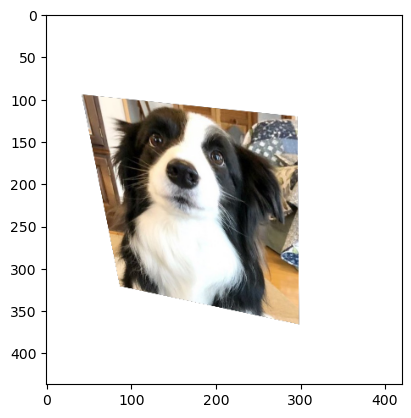
6. 색상/이미지 속성 변환
6.1 ColorJitter
- 이미지의 밝기(brightness), 대비(contrast), 채도(saturation), 색조(hue)를 랜덤하게 변화시킨다.
- 파라미터 설명:
brightness: 밝기 배율 범위(0이상, n 이면 1-n배 ~ 1+n배)contrast: 대비 조절 배율 범위(0~)saturation: 채도 조절 배율 범위hue: 색조 조절 배율 범위(-0.5 ~ +0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.ColorJitter(brightness=0.0, contrast=0.9, saturation=0.9, hue=0.5)
])
jittered_image = transform(image)
plt.imshow(jittered_image.permute(1, 2, 0))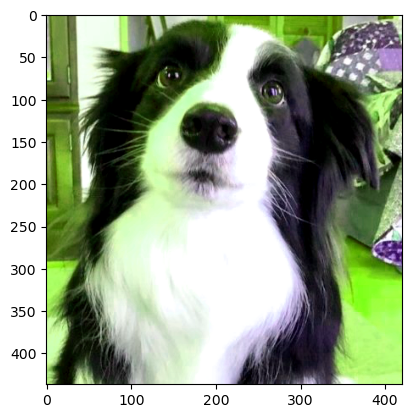
6.2 Grayscale
- 이미지를 흑백(그레이스케일)으로 변환한다.
- 파라미터 설명:
num_output_channels: 출력 채널 수(1 또는 3, 기본값 1)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.Grayscale(num_output_channels=1)
])
gray_image = transform(image)
plt.imshow(gray_image.squeeze(), cmap='gray')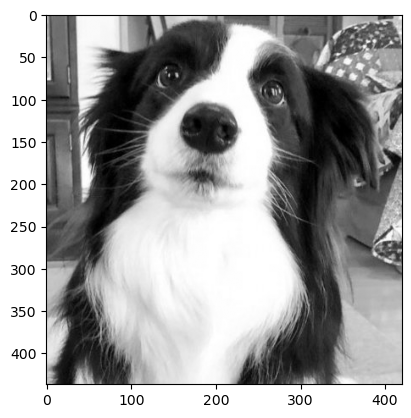
6.3 RandomInvert
- 이미지를 일정 확률로 색상 반전(negative)시킨다.
- 파라미터 설명:
p: 반전 적용 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomInvert(p=1)
])
inverted_image = transform(image)
plt.imshow(inverted_image.permute(1, 2, 0))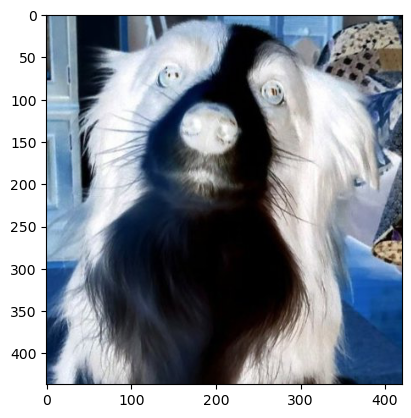
6.4 RandomPosterize
- 이미지를 일정 확률로 포스터라이즈(색상 단계 감소)한다.
- 포스터라이즈란 이미지의 각 픽셀 색상 값을 표현하는 비트 수를 줄여서, 색상 단계가 줄어들고 계단 현상(색상 구분이 뚜렷해짐)이 생기는 변화이다.
예를 들어, 8비트(0~255)에서 4비트(0~15)로 줄이면 색상 표현이 단순해진다. - 파라미터 설명:
bits: 유지할 비트 수(예: 4)p: 적용 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomPosterize(bits=1, p=1)
])
posterized_image = transform(image)
plt.imshow(posterized_image.permute(1, 2, 0))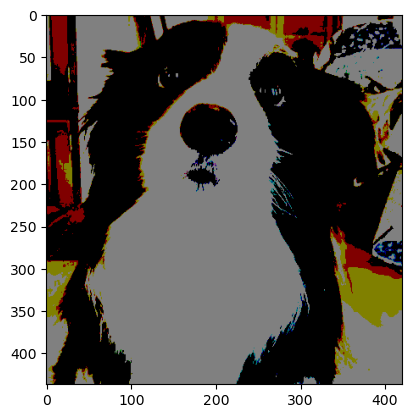
6.5 RandomSolarize
- 픽셀값이 임계값 이상이면 일정 확률로 반전시킨다.
- 파라미터 설명:
threshold: 임계값(예: 128)p: 적용 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomSolarize(threshold=72, p=1)
])
solarized_image = transform(image)
plt.imshow(solarized_image.permute(1, 2, 0))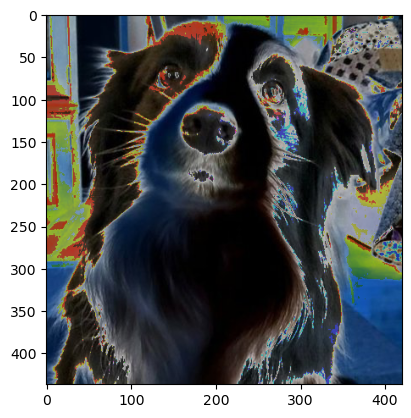
6.6 RandomAutocontrast
- 이미지를 일정 확률로 자동 대비 처리(이미지의 픽셀값 분포를 전체 밝기 범위(0~255)로 자동으로 늘려서
가장 어두운 픽셀은 0, 가장 밝은 픽셀은 255가 되게 만드는 처리)한다. - 파라미터 설명:
p: 적용 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomAutocontrast(p=1)
])
autocontrasted_image = transform(image)
plt.imshow(autocontrasted_image.permute(1, 2, 0))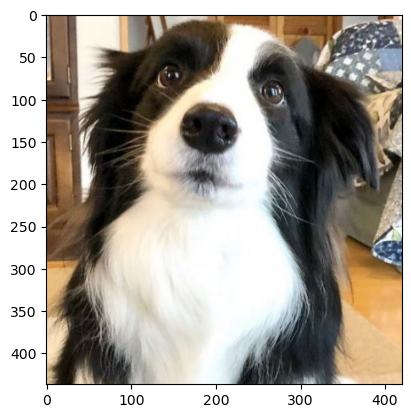
6.7 RandomEqualize
- 이미지를 일정 확률로 히스토그램 평활화(equalize)한다.
- 평활화란 이미지의 픽셀값(밝기 분포)이 특정 구간에 몰려 있을 때, 이 분포를 고르게(평평하게) 펴준다. 공식 생략
- 파라미터 설명:
p: 적용 확률(기본값 0.5)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomAutocontrast(p=1)
])
autocontrasted_image = transform(image)
plt.imshow(autocontrasted_image.permute(1, 2, 0))7. 블러/노이즈/마스킹
7.1 GaussianBlur
- 이미지를 가우시안 블러로 흐리게 만든다.
- 가우시안 블러란
- 이미지의 각 픽셀 값을 주변 픽셀들과 가우시안(정규분포) 함수로 도출한 가중 평균대체한다.
- 중심에 가까운 픽셀일수록 더 큰 가중치를 주고, 멀수록 가중치가 작아진다.- 2차원 가우시안 분포 :
- 파라미터 설명:
kernel_size: 커널 크기(정수 또는 튜플)sigma: 표준편차 범위(튜플, 기본값 (0.1, 2.0))
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.GaussianBlur(kernel_size=21, sigma=(5, 10))
])
blurred_image = transform(image)
plt.imshow(blurred_image.permute(1, 2, 0))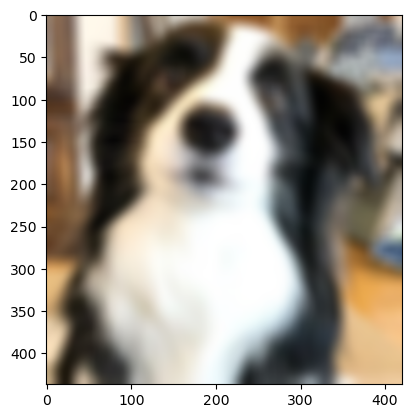
7.2 RandomErasing
- 이미지의 임의 위치에 사각형 영역을 랜덤하게 지운다.
- 파라미터 설명:
p: 적용 확률(기본값 0.5)scale: 사각형 영역의 크기 비율 범위(기본값 (0.02, 0.33))ratio: 사각형 영역의 가로세로 비율 범위(기본값 (0.3, 3.3))value: 지운 영역에 채울 값- 정수: 모든 채널을 해당 값으로 채움 (예: 0이면 검정)
- (R,G,B) 튜플: 각 채널별 색상 지정
- 'random': 픽셀마다 랜덤값으로 채움
- 정수: 모든 채널을 해당 값으로 채움 (예: 0이면 검정)
사용예시
transform = v2.Compose([
v2.ToImage(),
v2.RandomErasing(p=1, scale=(0.02, 0.2), ratio=(0.3, 3.3), value=0)
])
erased_image = transform(image)
plt.imshow(erased_image.permute(1, 2, 0))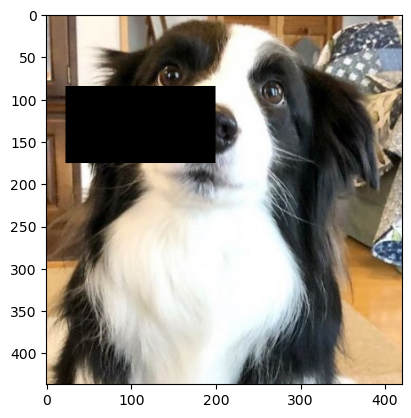
8. 혼합/증강 기법
8.1 CutMix
-
데이터 로더로 배치 단위의 이미지를 입력받는다.
-
분포에서 λ(lambda) 값을 샘플링한다.
-
배치에서 원본이미지와 섞을 이미지를 1장씩 고른다.
-
섞을 이미지를 잘라서 원본 이미지에 붙여 새로운 이미지를 만든다.
-
이때 새로운 이미지에서 섞인 이미지 넓이는 이다.
-
타겟값은 이다.
-
배치 내의 모든 이미지를 한 번은 원본이미지로 한 번은 섞을 이미지로 선택하여 배치 수 만큼의 이미지를 만든다.
-
결국 배치 사이즈와 같은 합성된 이미지를 반환한다.
-
파라미터 설명:
-num_classes: 클래스의 갯수alpha: 베타 분포의 alpha 값(혼합 비율 결정)
-
PIL 이미지를 지원하지 않기에 ToTenser를 사용 후 적용한다.
사용예시
#컷믹스 객체 생성
cutmix = v2.CutMix(num_classes=NUM_CLASSES, alpha=1.0)
...
#학습루프
for images, labels in dataloader:
# CutMix는 배치 단위로 적용
images, labels = cutmix(images, labels)
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
break # 예시로 한 배치만배치단위로 합성되기에 실제론 여러장이 합성되지만
임의로 2장만 섞어서 출력해보면 아래와 같다.
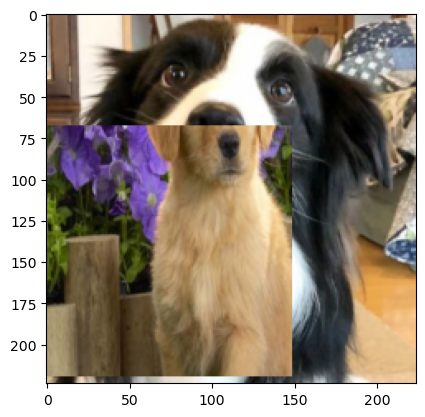
8.2 MixUp
- CutMix와 같은 과정으로 두 이미지와 라벨를 선택하여
으로 이미지와 라벨을 새로 만든다. - 파라미터 설명:
alpha: 베타 분포의 alpha 값(혼합 비율 결정)
사용예시
#믹스업 객체 생성
mixup = MixUp(num_classes=10, alpha=1.0)
...
#학습루프
for images, labels in dataloader:
# images: (batch, C, H, W), labels: (batch,)
images, labels = mixup(images, labels) # 또는 cutmix(images, labels)
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()