♣ 월요일 훈련 시작 전 사전 학습과 병행하여 노드 학습을 진행했습니다. 특히 새롭게 들어가는 DeepML 풀잎은 첫 수업이므로 AI-REMEMBER에서는 첫 수업에 대한 간단한 느낀 점 위주로 기록해 보았습니다!
Fundamental 11 - 사이킷런으로 구현해 보는 머신러닝
<배우는 것>
A. 머신러닝의 다양한 알고리즘
B. 사이킷런 라이브러리의 사용 방법
C. 사이킷런에서 데이터를 표현하는 방법
D. 훈련용 or 테스트용 데이터 Set로 데이터를 나누는 방법
11.2 머신러닝 알고리즘
- 머신러닝의 알고리즘 종류 : 지도학습, 비지도학습, 강화학습
- 지도학습으로 학습하다 차원과 특징의 가짓수가 많아지면 비지도학습으로 전환되기도 한다.
- 알파고 : 지도학습을 통해 바둑의 기보를 익히고 강화학습을 통해 최적화된 사례이다.
- 지도학습의 대표적 알고리즘 : 분류, 회귀, 예측
- 비지도학습의 대표적 알고리즘 : 클러스터링, 차원 축소
- 기타 다양한 알고리즘들 : 선형 회귀, 로지스틱 회귀, 의사결정 트리, 신경망 및 딥러닝, 계층적 군집화 등이 있다.
- 지도학습과 비지도학습을 구분하는 기준 : 라벨(정답)이 존재하는가, 존재하지 않는가?
- 차원 축소는 데이터가 매우 복잡하게 모여있을 때 사용하는 기법이다.
- 선형 회귀는 수치형(or 연속적인) 데이터 예측에 사용되는 기법이다.
- 로지스틱 회귀는 이진분류에 사용되는 기법이다.
- 라벨의 유무, 데이터의 종류와 특성, 문제의 정의 등의 요인에 따라 알고리즘은 복합적으로 활용된다.
- 강화학습은 지도/비지도학습과는 다른 방향성의 알고리즘이다.
- 강화학습에서 주로 사용되는 용어들 : 에이전트, 환경, 행동, 보상
13-a) 에이전트 : 학습 주체, 또는 Controller
13-b) 환경 : 에이전트에게 주어진 상황이나 조건
13-c) 행동 : 환경으로부터 주어진 정보를 기반으로 에이전트가 내린 행동
13-d) 보상 : 행동에 대한 보상을 머신러닝 개발자가 구축 - 강화학습 알고리즘의 대표적인 종류 : 몬테 카를로 방법, Q-Learning, Policy Gradient 방법
- 알고리즘은 상황에 따라 변경하거나 중복하는 것이 가능하므로 절대적이지 않다.
11.3 사이킷런 가이드라인에 기반한 머신러닝 알고리즘
- 알고리즘의 Task들
1-a) classification (분류)
1-b) regression (회귀)
1-c) clustering (클러스터링)
1-d) dimensionality reduction (차원 축소)
11.4 Hello, Scikit-learn
- Scikit-learn의 Scikit = SciPy + Toolkit로 SciPy에 기반한 파이썬 머신러닝 라이브러리이다.
- 훈련 데이터와 테스트 데이터를 나누는 기능을 제공하는 함수 : train_test_split
- ETL(Extract Transform Load) 기능을 수행하는 함수 : transformer()
- 모델로 표현되는 클래스 : Estimator
- Estimator 클래스의 메서드 : estimator.fit(x,y), estimator.predict(x)
- Estimator와 transformer() 기능을 모두 수행하는 API : Pipeline
- Scikit-learn은 SciPy에 기반하는데, SciPy가 Numpy의 확장판이기 때문에 풍부한 데이터 표현 및 수학적 함수를 가지고 있다.
11.5 Scikit-learn 데이터 표현법
- 사이킷런의 알고리즘은 파이썬 클래스로 구현되어있다.
- 데이터셋의 표현 방법
2-a) Numpy : ndarray
2-b) Pandas : DataFrame
2-c) SciPy : Sparse Matrix - 훈련, 예측 등 머신러닝 모델을 관리하는 CoreAPI
3-a) fit()
3-b) transformer()
3-c) predict() - 사이킷런의 데이터 표현 방식 : 특성행렬 방식, 타겟벡터 방식
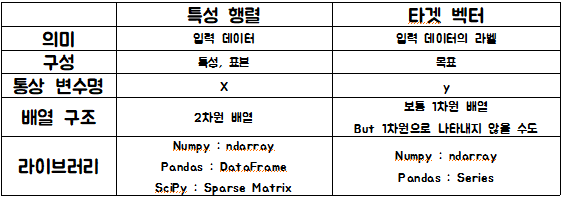
- 여기서 특성행렬과 타겟벡터의 n_samples 즉, 표본/라벨의 개수는 같아야 한다.
11.6 Scikit-learn 회귀모델
- (n,) : 1차원 벡터를 나타낸다.
- fit(X, y) : 인자로 특성행렬(X)와 타겟벡터(y)를 각각 넣어준다.
- reshape(a,b) 함수에서 a에 -1을 넣으면 자동으로 남은 숫자를 계산해준다.
- 모델의 성능 평가 관련 모듈이 저장된 곳 : sklearn.metrics
- 회귀모델의 성능평가에 사용되는 기법 : RMSE(Root Mean Square Error)
11.7 Scikit-learn Datasets 모듈
- 크게 두 가지로 나뉜다. : dataset loaders, dataset fetchers
- keys() : 파이썬의 딕셔너리 메서드
- 특성행렬의 행에는 데이터의 개수(n_samples), 열에는 특성의 개수(n_features)가 보통 들어간다.
- data.data.shape → (a,b) : 데이터가 a개이고 특성이 b개인 특성행렬이다.
- data.data.ndim : data.data에 대한 차원을 확인하는 방법
- 타겟벡터는 특성행렬의 데이터 개수와 정확히 일치해야 한다. 예를 들어 data.(특성행렬).shape → (50,6)이라면 data.(타겟벡터).shape는 (50,)의 형태이어야 한다.
- DESCR : 사이킷런에서 데이터에 대한 상세 설명을 출력하는 메서드
11.9 Scikit-learn Estimator
- 머신러닝 모델의 훈련은 fit() 메서드를, 예측은 predict() 메서드를 이용한다.
- 사이킷런은 API가 매우 일관성 있게 설계되어 있는 라이브러리이다.
- Estimator 객체 : 데이터셋을 기반으로 머신러닝 모델의 파라미터를 추정하는 객체
3-a) 파라미터 : 몇 개의 변수 사이에 함수 관계를 정하기 위해 사용되는 또 다른 변수 - 사이킷런의 모든 머신러닝 모델은 이 Estimator라는 파이썬의 '클래스'로 구현되어 있다.
- Estimator 객체를 사용하면 지도/비지도 학습에 관계없이 학습과 예측을 할 수 있다.
11.10 훈련 데이터와 테스트 데이터 분리하기
- 훈련에 쓰이는 데이터와 예측에 쓰이는 데이터는 서로 다른 데이터를 사용한다.
- 보통 훈련 데이터 8 : 테스트 데이터 2의 비율로 설정한다.
- train_test_split() 함수를 활용할 수도 있다.
DeepML CS231n - Lecture 2
♣ 드디어 대망의 DeepML 풀잎이 시작됐습니다!
♣ 간단하게 아이스 브레이킹 후 바로 강의수강 시작했습니다~
♣ 당시 조원이 저 포함해서 3명이었는데.. 제가 먼저 발표하게 되었는데, 아무래도 처음 만나는 강의였던지라 이해하기 좀 어려웠던 부분도 많았던 거 같네요.. 이 참에 영어 공부..?!
- Image Classification : 이미지 분류를 의미하며 컴퓨터 비전(CV)에서 핵심 기술이다.
- 픽셀은 3가지의 숫자로 표현되며, 픽셀에 대한 RGB 값을 제공한다.
- 시맨틱 갭(Sementic Gap) : 고급 언어로 표현한 것과 실제로 표현된 것이 상반되어 나타나는 문제를 일컫는다.
- (???) Data-Driven Approach (데이터 기반 접근법) : 이미지나 라벨에 대한 데이터셋을 수집하고 분류 대상에 대한 학습 목적으로 머신러닝을 사용하고 학습된 새로운 이미지의 분류 대상을 평가한다.
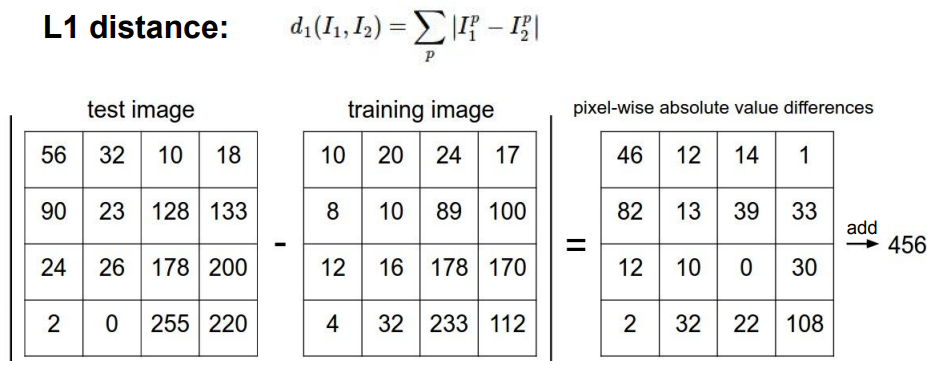
- L1 Distance - 맨하탄 거리 : 아래는 간단한 4×4 픽셀의 맨하탄 거리를 구하는 과정이다. 테스트 이미지와 학습 이미지 간의 차의 절댓값을 취해 계산하여 나온 총 16개의 수를 모두 더하면 456이 나온다. 이 수치는 두 이미지 간의 차이이다.
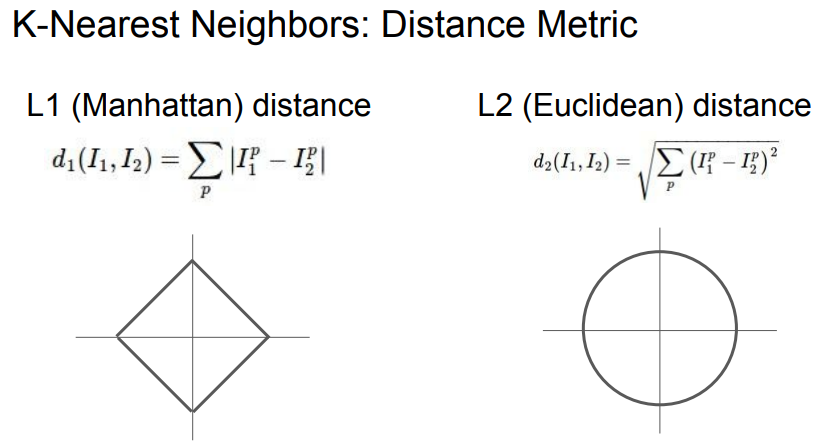
- L1 Distance, L2 Distance 도식
- 추가 : 둘 모두 비지도학습의 클러스터링과 연관이 깊다.
- Linear Classification : '선형 분류' 라고 칭하여 인공지능 신경망을 구축하는 데 많은 도움을 주는 메서드이다.

날개를 달고 날아오르자!