contents
- python, 라이브러리 개념학습 및 실습환경 준비
- python 활용 데이터 이상치, 결측치 처리 ✅
summary
- python, 라이브러리 개념학습 및 실습환경 준비
import pandas as pd
import numpy as np
import time
import warnings
# 오류 경고 무시하기
warnings.filterwarnings(action='ignore')- CSV 파일을 통한 테이블 LOAD
:pandas 라이브러리를 활용한 csv 파일 읽기
# pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("product_details.csv") # product_details.csv
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv- python 활용 데이터 결측치 처리 ✅
- 결측치 제거
#전체 데이터셋 확인
df3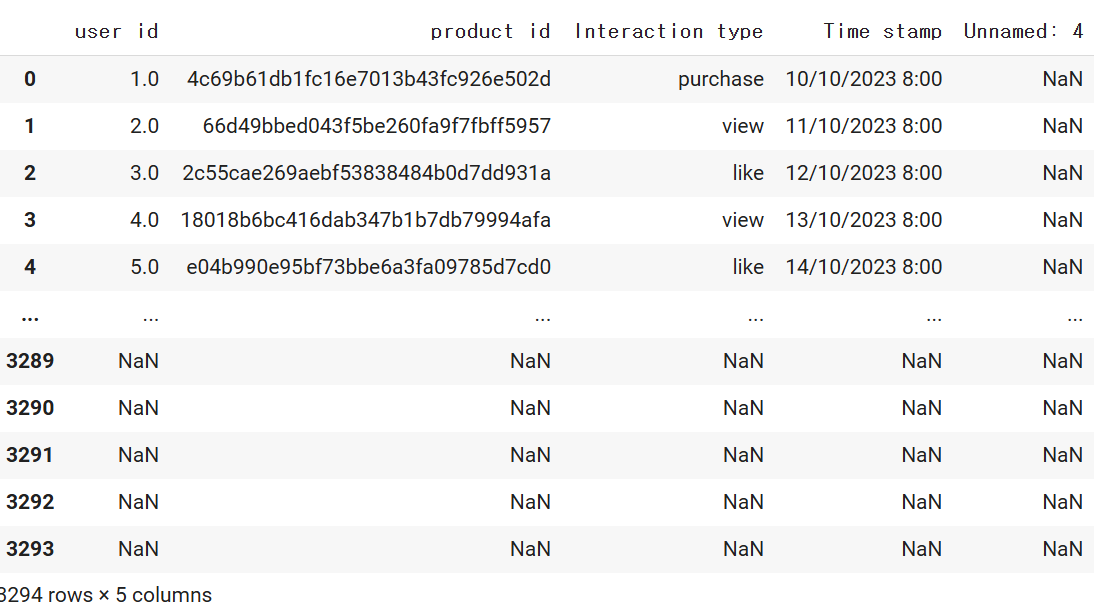
Unnamed: 4가 모두 nan인것을 확인 할 수 있다.
# 결측치 제거1 - 열 제거하기
df3 = df3.drop('Unnamed: 4', axis=1)
#선언을 하지 않으면 데이터가 저장되지 않을 수 있다!
#컬럼별 결측치 확인
df3.isnull().sum()user id 295
product id 295
Interaction type 423
Time stamp 295
dtype: int64
# 결측치 제거2 -결측치가 있는 행들은 모두 제거
df3.dropna(inplace=True)#원본데이터를 변경해준다.
df3.isnull().sum()user id 0
product id 0
Interaction type 0
Time stamp 0
dtype: int64
- 결측치 대체: 최빈값
# 데이터 불러오기
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv위에서 변경했으니, 데이터를 새로 불러온다.
# Interaction type 의 결측치: 423개
df3.isnull().sum()user id 295
product id 295
Interaction type 423
Time stamp 295
Unnamed: 4 3294
dtype: int64
423개의 결측치에 무언가를 채워넣고 싶음!
# 결측치는 카운트 되지 않습니다.
df3.groupby('Interaction type').count()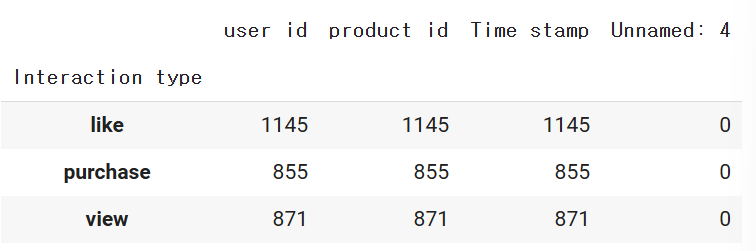
Interaction type중에 가장 많은 값으로 대체하고 싶은데, like가 제일 많이 나온것을 확인 할 수 있다.
# 결측치가 있는 Interaction type 컬럼을 최빈값으로 대체하기 위해, 해당 컬럼의 최빈값을 구함
df3['Interaction type'].mode()0 like
Name: Interaction type, dtype: object
그룹바이를 확인하기 위해 모드함수를 사용! (굳이,그룹바이 사용하지 않아도 됨)
# mode 는 최빈값을 의미
# df3 의 Interaction type 컬럼을 fillna함수를 이용하여 채워주되, mode() 함수를 사용하여 최빈값으로 넣어줌
# mode 함수는 시리즈를 output으로 가집니다.
# 따라서,[0]을 통해 시리즈 중 단일값을 가져와야 합니다. 이 과정을 빼면 제대로 값이 나오지 않음.
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode()[0])df3 = df3['Interaction type'].fillna(): 채워넣어준다.
()안에 0,1,-1 등 다양하게 들어갈 수 있음.
*mode()[0]으로 채워야한다. 만약 [1]이면 에러! why? 모드의 값이 0 like이기에 1에는 값이 없기 때문!
# 연산 후 인덱스 재설정
df3= df3.reset_index()# 최빈값으로 대체된 데이터프레임 확인
df3.groupby('Interaction type').count()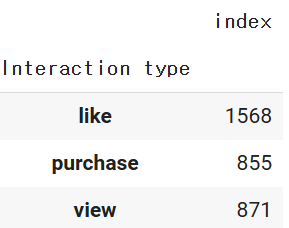
#최빈값 대체 완료 확인.
1568-1145=423
*확인하는 과정이 중요!
- 결측치 대체: 평균, 중앙값
# 데이터 불러오기
df = pd.read_csv("product_details.csv") # product_details.csv
# Shipping Weight 의 경우, 1138 개의 결측치가 있습니다.
# 13번째 인덱스, int 타입입니다.
df.isnull().sum()[13],df.isnull().sum()[13].dtype(1138, dtype('int64'))
# str.split 을 통해 문자열을 분리하고, 그 값 중 첫번째 인덱스를 가져옴
# df['sw'] = dd['Shipping Weight'].str.split().str[1]과 비교해보세요!
df['sw'] = df['Shipping Weight'].str.split().str[0]
->공백으로 분리하고 앞에꺼를 가져와야 하므로 [0]을 입력한다.
# string to float, 에러무시
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce')
# 평균값 대체
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].mean())
df.isnull().sum()
# 중간값 대체
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].median())
df.isnull().sum()
# 바로 위 값으로 대체
df['sw'] = df['sw'].fillna(method='ffill')
df.isnull().sum()
# 바로 아래 값으로 대체
df['sw'] = df['sw'].fillna(method='bfill')
#df.isnull().sum()- 결측치 대체: group by;기준에 따라 다른값 넣기
# 데이터 불러오기
df = pd.read_csv("product_details.csv") # product_details.csv
df['sw'] = df['Shipping Weight'].str.split().str[0]
# string to float, 에러무시
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce')
# group by 값으로 채워넣기 - 사전 데이터 확인
df.groupby('Is Amazon Seller')['sw'].median()Is Amazon Seller
N 2.45
Y 3.40
Name: sw, dtype: float64
#group by한 데이터를 데이터프레임의 컬럼으로 추가하기 위해
#transform 함수 사용
df['sw'] = df['sw'].fillna(df.groupby('Is Amazon Seller')['sw'].transform('median'))
df.isnull().sum()transform 함수:gg와 비슷하게 함수를 적용하는 메서드이지만,
단일 요소별로 함수를 동시에 적용할 수 있다는 장점이 있다. 마치 apply와 applymap의 차이와 비슷!
*기본 사용법
df.transform(func, axis=0, args, kwargs)
func : 함수입니다.
axis :{0 : index(row) / 1 : columns} 축입니다 0은 행, 1은 열 입니다.
arg : 함수의 인수 입니다.
kwargs : dict 형태의 함수의 인수입니다.
transform
Uniqe Id 0
Product Name 0
Brand Name 10002
Asin 10002
Category 830
Upc Ean Code 9968
List Price 10002
Selling Price 107
Quantity 10002
Model Number 1770
About Product 273
Product Specification 1632
Technical Details 790
Shipping Weight 1138
Product Dimensions 9523
Image 0
Variants 7524
Sku 10002
Product Url 0
Stock 10002
Product Details 10002
Dimensions 10002
Color 10002
Ingredients 10002
Direction To Use 10002
Is Amazon Seller 0
Size Quantity Variant 10002
Product Description 10002
sw 0
dtype: int64
3.python 활용 데이터 이상치 처리.
- 이상치 탐지: Z-SCORE
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("product_details.csv") # product_details.csv
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0)
# z-score 를 적용할 컬럼 선정
df1 = df[['sw']]
df1
df1 = df['sw']: 시리즈 형태
df1 = df[['sw']]: 데이터 프레임 형식!
from sklearn.preprocessing import StandardScaler
# 표준화 진행
# 표준화 : 평균을 0으로, 표준 편차를 1로
# 데이터를 0을 중심으로 양쪽으로 데이터를 분포시키는 방법
# 표준화를 하게 되면(=z값을 구하게 되면) 각 데이터들은 평균을 기준으로 얼마나 떨여져 있는지를 나타내는 값으로 변환
scale_df = StandardScaler().fit_transform(df1)
scale_df #스케일링이라고 부름외우기 보단 어떻게 사용할지정도 익혀주기.
array([[ 0.13758775],
[-0.0951741 ],
[ 0.21054296],
...,
[-0.13686279],
[-0.02221889],
[ 0.47804538]])
# array 형태로 반환된 것을 dataframe 으로 받아줍니다.
scale_df = pd.DataFrame(scale_df)
# 기존 raw 값과 표준화 이후 데이터를 비교하기 위해 merge 진행
merge_df = pd.concat([df1, scale_df],axis=1)
# 표준화 된 데이터를 확인할 할 수 있게 되었습니다.
merge_df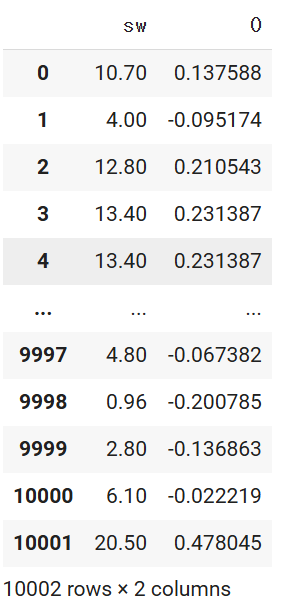
#컬럼명 바꿔줌
merge_df.columns = ['Shipping Weight', 'zscore']# 이상치 감지
# Z-SCORE 기반, -3 보다 작거나 3보다 큰 경우를 이상치로 판별
mask = ((merge_df['zscore']<-3) | (merge_df['zscore']>3))
# mask 메소드 사용
strange_df = merge_df[mask]
strange_df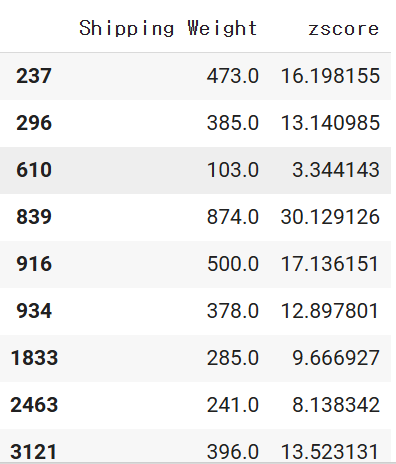
# 총 55 건 탐지
strange_df.count()Shipping Weight 55
zscore 55
dtype: int64
->평균으로 부터 너무 많이 떨어진것이 55개이다!
- 이상치 탐지: IQR
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("product_details.csv") # product_details.csv
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0).astype(int)
# 이상치를 감지할 컬럼 선정
df1 = df[['sw']]# Q3, Q1, IQR 값 구하기
# 백분위수를 구해주는 quantile 함수를 적용하여 쉽게 구할 수 있음
# 데이터프레임 전체 혹은 특정 열에 대하여 모두 적용이 가능
q3 = df1['sw'].quantile(0.75)
q1 = df1['sw'].quantile(0.25)
iqr = q3 - q1
q3, q1, iqr(7.0, 1.0, 6.0)
# 이상치 판별 및 dataframe 저장
# Q3 : 100개의 데이터로 가정 시, 25번째로 높은 값에 해당합니다.
# Q1 : 100개의 데이터로 가정 시, 75번째로 높은 값에 해당합니다.
# IQR : Q3 - Q1의 차이를 의미합니다.
# 이상치 : Q3 + 1.5 * IQR보다 높거나 Q1 - 1.5 * IQR보다 낮은 값을 의미
def is_outlier(df1):
score = df1['sw']
if score > 7 + (1.5 * 6) or score < 1 - (1.5 * 6):
return '이상치'
else:
return '이상치아님'
# apply 함수를 통하여 각 값의 이상치 여부를 찾고 새로운 열에 결과 저장
df1['이상치여부'] = df1.apply(is_outlier, axis = 1) # axis = 1 지정 필수
df1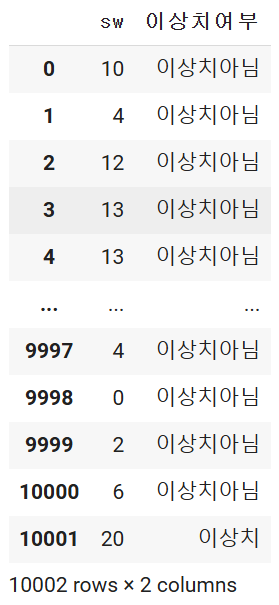
# IQR 방식으로 구한 이상치 개수는 349 개
df1.groupby('이상치여부').count()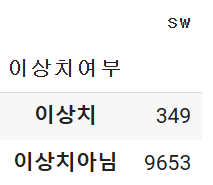
key point
전처리과정에 답은 없다!
비지도 학습의 핵심으로 전처리 과정은 다양한 방법이 존재하고, 그 결과도 다양하게 나온다. 그 중에 정답은 없다. 각 상황에 맞게 선택해야하고, 그렇기에 결측치를 어떤것으로 대체할지는 여러 사항을 구해보고 비교해본뒤 결정!
이와 마찬가지로 이상치를 판단할때 z점수와 IQR 방식으로 진행하면 다른 결과가 나온다.
그렇기에 어떤 것이 더 올바르다고 말할 수는 없다.
