오늘 목표
- 기획서 초안 완성
- 크롤링 코드 구현
TIL
https://baka9131.tistory.com/14
https://qcoding.tistory.com/20
다이닝 코드의 robots.txt 파일
User-agent: *: 모든 웹 크롤러에 대해 적용됩니다.
Allow: /: 모든 페이지에 대한 크롤링을 허용합니다.
Disallow: /urlShortener: /urlShortener 경로에 대한 크롤링은 금지됩니다.
Disallow: /review: /review 경로에 대한 크롤링도 금지됩니다.
이 정보에 따르면, 다이닝 코드 웹사이트의 대부분의 페이지는 크롤링이 허용되지만, 특정 경로인 /urlShortener와 /review는 크롤링할 수 없습니다. 따라서, 이 두 경로를 제외한 다른 페이지에 대해서는 웹 크롤링이 가능하다는 것을 의미합니다.
import time
import csv
from selenium import webdriver
from bs4 import BeautifulSoup
# 웹 드라이버 설정 (Chrome을 예로 듭니다)
driver = webdriver.Chrome() # ChromeDriver 경로를 설정
# 웹 페이지 열기
driver.get('https://www.diningcode.com/list.dc?query=%EB%8C%80%EC%A0%84%20%EC%8B%9D%EB%8B%B9')
# 스크롤을 내리는 함수
def scroll_down(driver):
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 스크롤 내리기
scroll_down(driver)
# 페이지의 HTML 가져오기
html_content = driver.page_source
# BeautifulSoup을 사용하여 HTML 파싱
soup = BeautifulSoup(html_content, 'html.parser')
# 필요한 데이터 추출
restaurants = soup.find_all('a', class_='sc-cCzKKE eCxLqb PoiBlock')
# CSV 파일로 저장
with open('restaurants_2.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
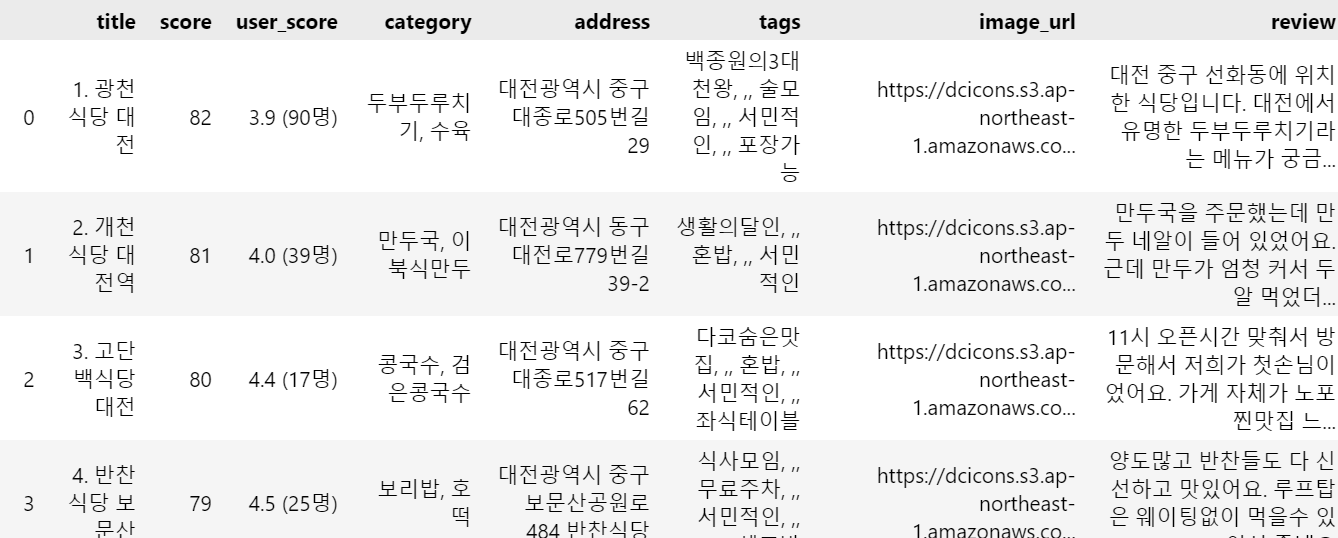
writer.writerow(['title', 'score', 'user_score', 'category', 'address', 'tags', 'image_url', 'review'])
for restaurant in restaurants:
try:
title = restaurant.find('h2').text.strip()
score = restaurant.find('p', class_='Score').find('span').text.strip() # 점수 추출
user_score = restaurant.find('p', class_='UserScore').text.strip() # 사용자 점수 추출
category = ', '.join([cat.text.strip() for cat in restaurant.find('p', class_='Category').find_all('span')]) # 카테고리 추출
address = restaurant.find('span', class_='Address').text.strip() # 주소 추출
tags = [tag.text.strip() for tag in restaurant.find('div', class_='Hash').find_all('span')] # 태그 추출
image_url = restaurant.find('img')['src'] if restaurant.find('img') else '' # 이미지 URL 추출
# 리뷰 추출
review = restaurant.find('span', class_='ReviewWrap').find('span', class_='Review').text.strip() if restaurant.find('span', class_='ReviewWrap') and restaurant.find('span', class_='Review') else '' # 리뷰 추출
writer.writerow([title, score, user_score, category, address, ', '.join(tags), image_url, review])
except Exception as e:
print(f"Error extracting data for a restaurant: {e}")
# 드라이버 종료
driver.quit()
해석
import time
import csv
from selenium import webdriver
from bs4 import BeautifulSouptime: 시간 관련 기능을 제공하는 모듈.
csv: CSV 파일을 읽고 쓰기 위한 모듈.
selenium: 웹 브라우저를 자동으로 조작할 수 있게 해주는 라이브러리.
BeautifulSoup: HTML 및 XML 문서를 파싱하기 위한 라이브러리.
driver = webdriver.Chrome() # ChromeDriver 경로를 설정Chrome 웹 브라우저를 자동으로 조작하기 위해 ChromeDriver를 사용하여 드라이버 객체를 생성
def scroll_down(driver):
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height이 함수는 페이지의 맨 아래로 스크롤을 내리며, 더 이상 스크롤할 수 없을 때까지 반복. 이는 동적으로 로드되는 콘텐츠를 모두 가져오기 위해 필요
html_content = driver.page_source현재 페이지의 HTML 소스를 가져오기.
오늘 수행하지 못한 일과 그 이유
크롤링 코드 수정
인사이트 및 회고
전공자나 개발자 직군들은 웹크롤링이 어렵지 않다고 말했지만, 나는 그분들 코드보면서 따라하기도 바쁘고, 이해하기엔 너무 힘들다는 것을 느낀하루였다...
계속된 오류로 인해..약간 지쳤....지만
다같이 다시 시도해보고, 튜터님의 도움도 받아 다시 생성해보면 좋을 것 같다.
