contents
- 텍스트 데이터 분석의 원리
- 텍스트 데이터 임베딩
- 텍스트 데이터 전처리
summary
- 텍스트 데이터 분석의 원리
☑️ 텍스트 데이터의 특징

- 전형적인 비정형 데이터 중 하나.
- 비정형 데이터란 구조화된 데이터가 아니기때문에 저희가 여태 해왔던 데이터 분석 방법론을 그대로 적용하기 어렵.
- 일반 사람들이 실생활에서 접하는 ‘정보’는 비정형 데이터 구조인 경우가 많다.
- 이미지, 동영상, 오디오, 문서 등
- 전처리를 통해 분석 가능한 형태로 변형하여 분석을 진행.
- 비정형 데이터 처리는 사실 쉬운 일이 아님.
- 데이터 형태가 다양하기에 구조화된 형태로 만드는 것이 어렵.
- 보통 비정형 데이터는 정형 데이터보다 용량이 매우 큰 편.
- 분석에 사용되는 컴퓨팅 자원이 많이 듦.
- 텍스트 데이터의 경우 자연어 처리(Natural Language Processing)를 통해 정형화된 정보를 추출하고, 이를 분석에 활용.
- 텍스트 데이터 임베딩
☑️ 임베딩이란?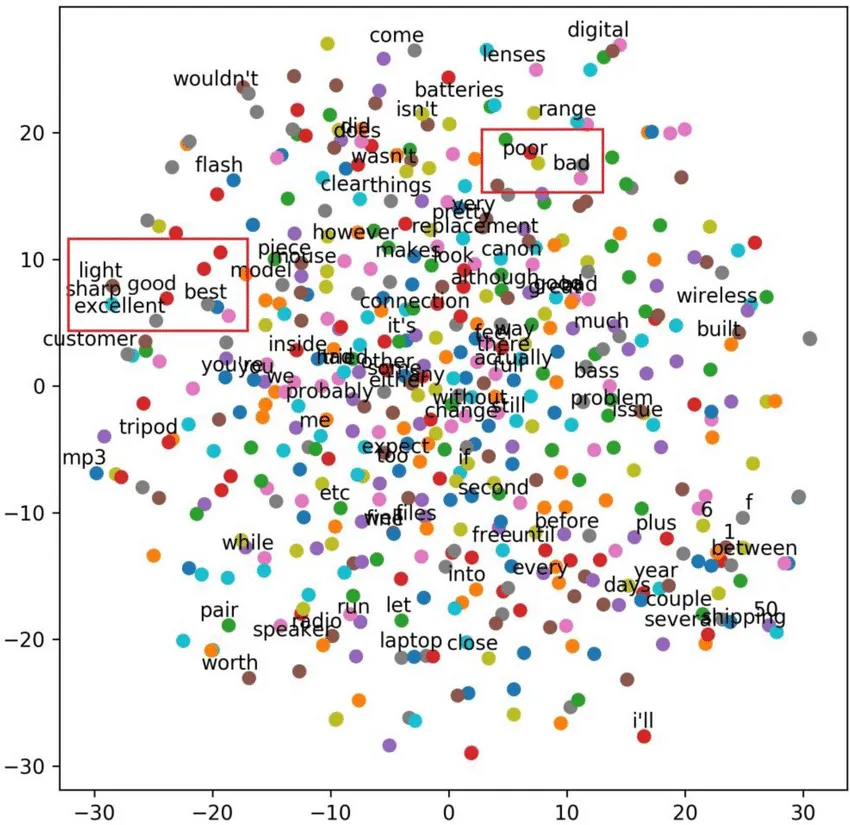
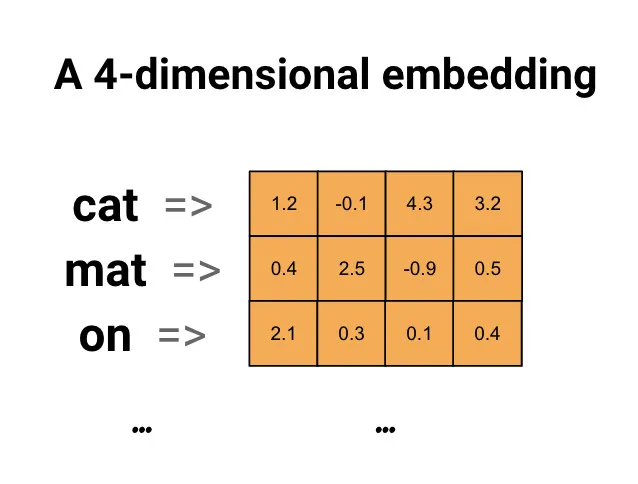
- 자연어를 기계가 이해할 수 있도록 숫자형태인 벡터로 바꾸는 과정 혹은 일련의 전체 과정을 임베딩이라고 함.
- 벡터라고 표현한 이유는, 각각의 데이터 포인트가 크기와 방향을 가지기 때문.
- 임베딩 방법
- One Hot Encoding
- 하나의 단어가 하나의 차원(컬럼)이 된다.
- 문서에 해당 단어가 등장하면 1, 등장하지 않으면 0으로 표기.
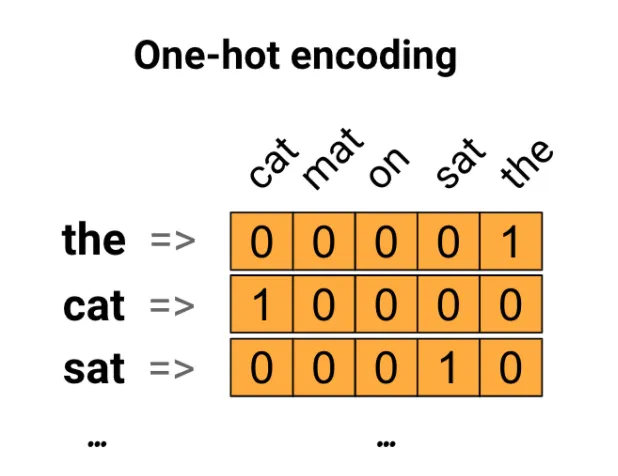
- One Hot Encoding
- Term Frequency
- 하나의 단어가 하나의 차원이 됨.
- One Hot Encoding과는 달리 단어가 등장한 횟수를 값으로 가지는 벡터를 만듦.
- scikit-learn의 CountVecotrizer를 활용.
- TF-IDF (Term Frequency - Inverse Document Frequency)
- 하나의 단어가 하나의 차원이 됨.
- TF만 따지게 되면 조사나 관사 등 의미없는 단어가 자주 등장할 가능성이 큼.
- 공통된 문서에서 자주 등장하는 단어는 페널티를 줘서 중요도를 낮추는 방법tf(w)
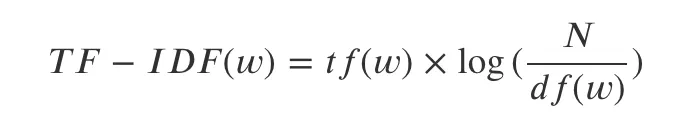
- 계산식은 위와 같다.
- tf(w): 단어 w의 Term Frequency
- df(w): 단어 w의 Document Frequency
- N: 총 문서의 개수
scikit-learn의 TfidfVectorizer를 활용.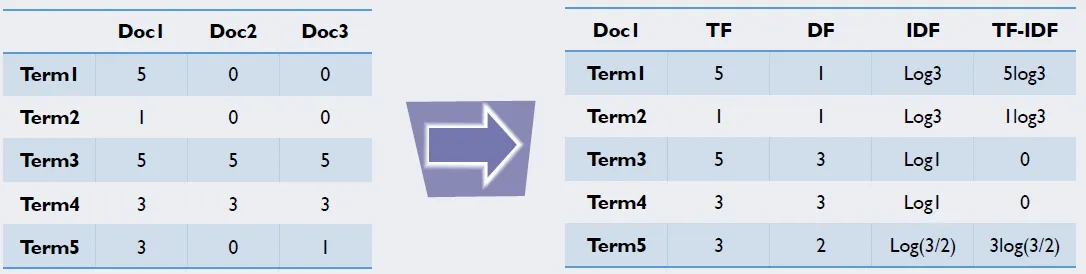
- Word Embedding
- 빈도 기반으로 단어를 벡터화하면 단어와 단어 사이의 관계, 문맥 등을 반영하기 어렵.
- 연관성 있는 단어를 가까운 곳에, 연관성이 떨어지는 단어를 먼 곳에 위치하게 벡터화를 하면 단어 사이 연관성을 파악하기 수월.
- 이런 관점에서 특정 문장에서 단어의 ‘주변 단어’를 활용하는 Word2Vec 알고리즘 등을 활용하여, 단어를 주어진 차원(하이퍼 파라미터)에 벡터화 할 수 있다.
- Skip-gram: 특정 단어가 주어졌을 때 주변 단어를 예측하는 모델
- C-Bow: 주변 단어가 주어졌을 때 빈 칸의 단어를 예측하는 모델
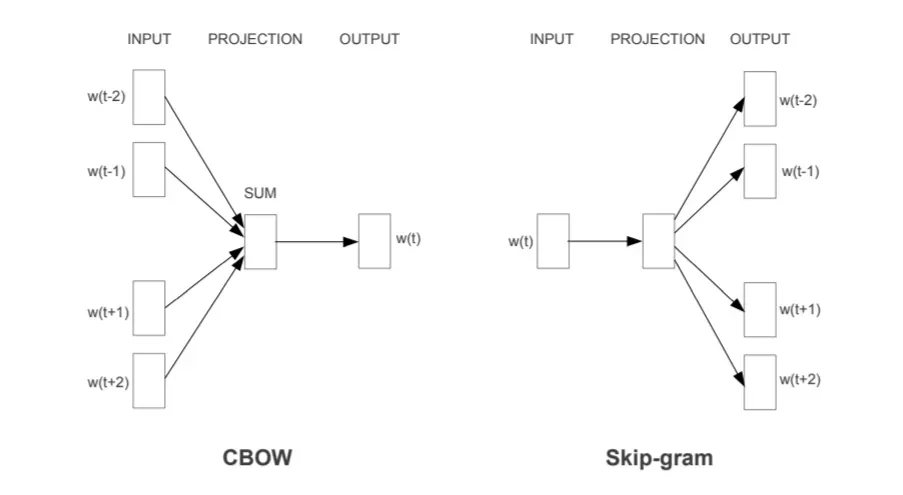
- gensim의 word2vec 모델을 사용하여 구현 가능.
-
LLM을 활용한 임베딩과 Vector DB
- ChatGPT와 같은 LLM(Large Language Model)은 수많은 텍스트 데이터를 학습하여 만들어진 결과물.
- 모델 학습 시 문장 간 단어 사이의 관계성을 계산하고 이를 학습하는 과정을 반복.
- 이미 학습된 LLM의 API 호출을 통해 텍스트를 벡터로 변환할 수 있다.
- ex) OpenAI Embeddings로부터 추출한 embedding vector는 (text-embedding-ada-002 모델 사용 시) 1,536차원에 해당.
- Vector DB는 벡터 형태 데이터를 효율적으로 다룰 수 있는 DB이며 벡터 형태의 검색이 가능하게끔 함.
- ChatGPT와 같은 LLM(Large Language Model)은 수많은 텍스트 데이터를 학습하여 만들어진 결과물.
-
텍스트 데이터 전처리
☑️ 텍스트 데이터 분석을 위한 전처리 과정
전처리를 통해서 분석 대상의 텍스트에서 최대한 중요한 정보를 남기려고 함. -
문장 분리(Sentence Segmentation)
- 문서처럼 긴 텍스트를 분석할 때는 문서를 우선 더 작은 문장 단위로 쪼개는 것이 좋다.
- 다만 문서 단위로 분석하는 것이 적절하거나, 하나의 문서의 길이가 짧은 경우(댓글, 리뷰 등)에는 굳이 적용하지 않아도 된다.
- 쉽게는 마침표(.)처럼 확실한 구분자(boundary)를 이용해 구분하는 방식이 있다.
- 분석 대상 언어마다, 그리고 분석 대상 글의 속성에 따라 적용할 수 있는 룰이 다름.
- 한글과 달리 일본어와 중국어에서는 고리점(。)을 마침표로 사용.
- 뉴스 기사는 문장 마지막에 마침표를 정확하게 찍는 반면, 커뮤니티 게시글은 마침표를 사용하지 않는 경우도 많다.
- 문서처럼 긴 텍스트를 분석할 때는 문서를 우선 더 작은 문장 단위로 쪼개는 것이 좋다.
-
불필요한 문자 제거(Text Cleaning)
- 불필요한 텍스트가 포함되어 있는 경우 이를 사전에 제거.
- 불필요한 텍스트 예시
- ‘ㅋㅋㅋㅋㅋㅋ’, ‘ㅎㅎㅎㅎㅎ’ 같이 불필요한 자음의 반복
- html tag
- 특수문자(#@%$[]{})
- 정규 표현식(Regex)를 활용하면 간편하게 특정 문자열을 제거할 수 있다.
-
토큰화(Tokenization)
- 문장을 의미있는 단위로 쪼개는 작업으로 전처리의 핵심.
- 영어같은 경우는 띄어쓰기 단위로만 쪼개도 각 토큰이 어느 정도 의미를 가지고 있다.
- 한글의 경우 띄어쓰기에 민감하지 않아 띄어쓰기가 잘 이루어지지 않는 경우도 많을 뿐더러, 띄어쓰기 단위인 ‘어절’로 쪼개도 의미 단위로 쪼개지지 않는다.
- 한글은 조사나 어미에 따라 그 의미가 달라지는 경우가 많기 때문.
- 스파르타는 / 스파르타에서 / 스파르타식
- 한글에서 뜻을 가지는 가장 작은 단위는 ‘형태소’.
- 따라서 한글 토크나이저는 형태소 단위로 쪼개는 형태소 분석기를 활용하는 경우가 대다수.
- 형태소 분석기를 이용해 나뉘어진 토큰은 품사 태그(Part-of-speech, POS) 정보를 포함하고 있어 이를 분석에 활용할 수 있다.
- 한글은 조사나 어미에 따라 그 의미가 달라지는 경우가 많기 때문.
- 영문의 경우 표제어 추출(Lemmatization), 어간 추출(Stemming) 기법을 활용하기도 함.
- 표제어 추출: 기본 사전어 단어로 변환
- 예시
- am, are , is → be
- knives → knife
- 예시
- 어간 추출: 단어 생성 규칙에 따라 어간만 남기는 방법
- 예시
- normalization, normalize → normal
- numerical → numeric
- 예시
- 표제어 추출: 기본 사전어 단어로 변환
-
불용어 제거(Stopword)
- 토큰 중에서 불필요한 토큰을 제거하는 단계.
- 불용어를 모아둔 집합을 ‘불용어 사전’이라고 함.
- 불용어 사전은 보편적으로 많이 제거되는 대명사나 조사, 접미사 등을 포함하고 있으며 사용자가 직접 정의할 수도 있다.
- 불용어 예시
- 이 / 그 / 저 / 또 / 결국 / 한다
- 웹 상에 보편적으로 정리되어 있는 불용어 사전을 활용해도 됨. 하지만 상황에 따라 불용어는 달라질 수 있으므로 사용 전에 꼭 확인.
이렇게 전처리한 텍스트를 임베딩을 통해 벡터화하고 나면, 이후에는 정형 데이터를 다루는 것과 동일하게 분석 모델에 활용할 수 있다.
key points
- 텍스트 데이터의 특징
비정형 데이터: 구조화되지 않아 기존 데이터 분석 방법론을 적용하기 어려움.
전처리 필요: 분석 가능한 형태로 변형해야 함.
자원 소모: 비정형 데이터는 용량이 크고, 분석에 많은 컴퓨팅 자원이 필요. - 텍스트 데이터 임베딩
임베딩: 자연어를 숫자 형태의 벡터로 변환하는 과정.
임베딩 방법:
One Hot Encoding: 단어의 존재 여부를 0과 1로 표현.
Term Frequency: 단어의 등장 횟수를 벡터로 표현.
TF-IDF: 단어의 중요도를 반영하여 벡터화.
Word Embedding: 단어 간의 관계를 반영하여 벡터화 (예: Word2Vec).
LLM 활용: 대형 언어 모델을 통해 텍스트를 벡터로 변환. - 텍스트 데이터 전처리
문장 분리: 긴 텍스트를 문장 단위로 나누기.
불필요한 문자 제거: 불필요한 텍스트(예: 특수문자, 반복 자음) 제거.
토큰화: 문장을 의미 있는 단위로 쪼개기 (형태소 분석기 사용).
불용어 제거: 분석에 필요 없는 단어(예: 대명사, 조사) 제거.
이러한 전처리 과정을 통해 텍스트를 임베딩하고, 이후 정형 데이터와 동일하게 분석 모델에 활용할 수 있다.
- 자연어 처리(NLP) 기술이 영어에 비해 한글에서 더 어려운 이유
-
언어 구조의 차이
형태소 언어: 한글은 형태소 언어로, 조사나 어미에 따라 단어의 의미가 달라짐. 다양한 형태의 단어를 처리하기 위한 복잡한 형태소 분석 필요.
어순의 유연성: 한글은 주어-목적어-서술어(SOV) 구조를 가지며, 어순이 유연함. 문장의 의미 파악에 어려움 초래. -
띄어쓰기 문제
띄어쓰기의 불규칙성: 한글은 띄어쓰기가 영어보다 덜 규칙적임. 조사나 어미가 붙은 단어의 띄어쓰기가 잘 이루어지지 않아, 토큰화 과정에서 어려움 발생. -
불용어와 조사
조사와 어미: 한글은 조사와 어미가 많아 불용어 정의가 복잡함. 조사와 어미가 문장의 의미를 결정짓기 때문에 단순 제거가 어려움. -
데이터 부족
학습 데이터의 부족: 영어는 다양한 데이터셋과 리소스가 존재하지만, 한글에 대한 데이터는 상대적으로 부족함. 모델 학습에 필요한 양질의 데이터 확보 어려움. -
기술적 지원의 차이
도구와 라이브러리: 영어에 비해 한글을 지원하는 자연어 처리 도구와 라이브러리가 적고, 성능이 떨어지는 경우가 많음. 연구자와 개발자들의 한글 NLP 접근성 낮춤.
이러한 이유들로 인해 한글 자연어 처리 기술은 영어에 비해 더 많은 도전과제를 안고 있으며, 이를 극복하기 위한 연구와 개발이 지속적으로 필요함.
