contents
- 선형회귀 적용
summary
- 선형회귀 적용
☑️ 데이터 사이언스 파이썬 라이브러리
-
scikit-learn: Python 머신러닝 라이브러리 -
numpy: Python 고성능 수치 계산을 위한 라이브러리 -
pandas: 테이블 형 데이터를 다룰 수 있는 라이브러리 -
matplotlib: 대표적인 시각화 라이브러리, 그래프가 단순하고 설정 작업 많음 -
seaborn: matplot기반의 고급 시각화 라이브러리, 상위 수준의 인터페이스를 제공
☑️ 자주 쓰는 함수 -
sklearn.linear_model.LinearRegression: 선형회귀 모델 클래스coef_: 회귀 계수intercept: 편향(bias)fit: 데이터 학습predict: 데이터 예측
-
실습해보기
📌식당에서 파트타임으로 일하고 있는 머신이는 이번에는 tip 데이터를 가지고 적용해보기로 했습니다. 돈을 많이 벌고 싶었던 머신이는 전체 금액(X)를 알면 받을 수 있는 팁(Y)에 대한 회귀분석을 진행해볼 예정입니다. x: total_bill y: tip
tips_df = sns.load_dataset('tips')
tips_df.head(3)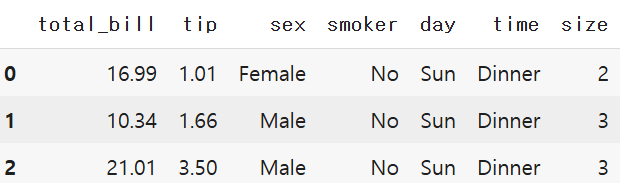
model_lr2 = LinearRegression()
x = tips_df[['total_bill']]
y = tips_df['tip']
model_lr2.fit(x,y)
sns.scatterplot(x='total_bill', y='tip', data=tips_df)
plt.title('Total Bill & Tip')
plt.xlabel('Total Bill')
plt.ylabel('Tip')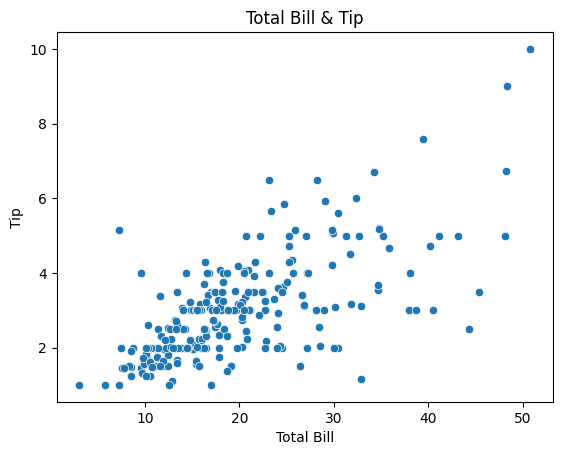
- 선형식 세우기
# y(tip) = w1*x(total_bill) + w0
w1_tip = model_lr2.coef_
w0_tip = model_lr2.intercept_
print('y = {}x + {}'.format(w1_tip.round(2),w0_tip.round(2)))y = [0.11]x + 0.92
-> 전체 금액이 1달러 오르면 팁은 약 0.11달러씩 오른다.
즉, 전체 금액이 100달러 오르면 팁은 11달러 정도 추가된다.
# 예측값 생성
y_true_tip = tips_df['tip']
y_pred_tip = model_lr2.predict(tips_df[['total_bill']])
y_true_tip
y_pred_tip
#오차
mean_squared_error(y_true_tip, y_pred_tip)1.036019442011377
r2_score(y_true_tip, y_pred_tip)0.45661658635167657
tips_df.head(3)
tips_df['pred'] = y_pred_tip
sns.scatterplot(x='total_bill', y='tip', data=tips_df)
sns.lineplot(x='total_bill', y='pred', data=tips_df, color = 'red')
plt.title('Total Bill & Tip')
plt.xlabel('Total Bill')
plt.ylabel('Tip')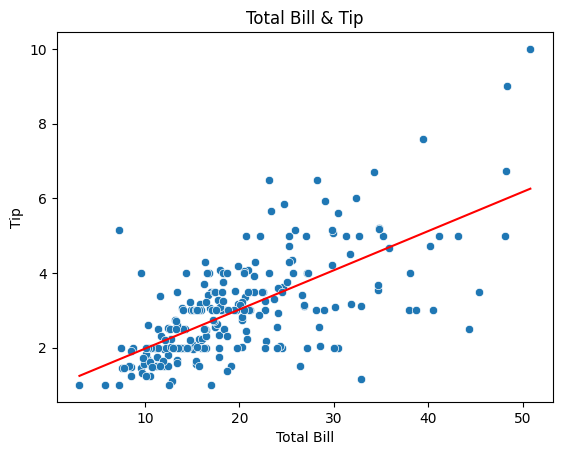
insight
머신러닝을 이용해 단일 선형관계를 가지는 변수들의 예측 모델을 그려보고, 시각화를 해보았다. 확실히 아직은 많이 어렵지만, 생각했던 것보다는 단순한 과정인것 같다.
다만, 아직 익숙하지 않은것!
많은 연습이 필요할것 같다!

Be DBA