contents
텍스트 데이터 분석 사례
- 감성 분석 (Sentiment Analysis)
- 텍스트 자동 분류
- 텍스트 데이터 클러스터링
실습
summary
텍스트 데이터 분석 사례
1) 감성 분석 (Sentiment Analysis)
☑️ 텍스트 데이터를 활용한 감성 분석은 어떻게 진행될까요?

- 감성 분석은 글의 내용을 긍정과 부정, 그리고 중립으로 분류하는 분류 문제.
- 주로 리뷰나 댓글에 적용해 볼 수 있다.
- 어떤 영화의 리뷰를 대상으로 감성 분석을 하여, 해당 영화에 대한 사용자 반응을 살펴볼 수 있다.
- 제품 리뷰를 대상으로 감성 분석을 적용해 긍정적인 피드백 내용과 부정적인 피드백 내용을 분류할 수 있다.
- 감성 분석을 구현하는 방식은 크게 두 가지로 나눌 수 있다.
- 단어마다 긍정, 부정, 중립 점수를 부여하는 감성 언어 사전을 구축하여, 문장을 scoring하고 분류.
- 문장(리뷰)을 벡터화 한 뒤 문장의 label을 활용하여 분류 모델을 학습.
2) 텍스트 자동 분류
☑️ 카테고리가 명시된 문서를 자동으로 분류해봅시다.
- 카테고리가 붙어 있는 텍스트(문서)에 대해서 카테고리를 자동으로 분류하는 분류 모델을 생성해 볼 수 있다.
- 이는 문서를 자동으로 분류하기에 대량의 텍스트 데이터를 분류하여 살펴봐야 할 때 유용.
- 하루에 수만 개씩 쏟아지는 뉴스, 메일에 대한 자동 분류
- 대량으로 모은 의료, 특허, 판례 등에 대한 자동 분류
- labeling 된 문서를 대상으로 분류 모델을 학습하여 자동 분류 모델을 생성해 볼 수 있다.
3) 텍스트 데이터 클러스터링
☑️ 텍스트 데이터 클러스터링 = 고차원 데이터 클러스터링
- 텍스트 데이터를 벡터화하고 나면, 이후 클러스터링 과정은 정형 데이터 대상으로 분석했을 때와 동일.
- 정형화된 텍스트 데이터는 다른 데이터 대비 차원이 굉장히 큼.
- 그리고 데이터포인트별로 전체 차원 대비 값을 가지고 있는 차원의 수가 매우 적은 벡터일 가능성이 높다(sparse matrix)
- 이런 형태의 데이터에서 유클리디언 거리 기반의 클러스터링은 효과가 크게 떨어질 수 있다.
- 따라서, 유클리디언 거리보다는 코사인 거리를 활용하면 좋은 성능을 기대할 수 있다.
- 상대적으로 그렇다는 이야기입니다! 항상 정답은 없다.
- 코사인 거리를 활용한 클러스터링 방법 몇 가지를 소개.
- AgglomerativeClustering의 metric을
cosine으로 설정 - Spherical K-means Clustering 활용
- AgglomerativeClustering의 metric을
(추가) LLM을 활용한 임베딩 방법
☑️ LLM의 강력한 임베딩 모델을 사용해 성능을 높여봅시다!![]
- LLM은 수많은 문서들을 학습한 결정체로, 모델 학습 단계에서 대량의 텍스트 데이터에 대한 임베딩이 선행되었다.
- 대부분의 LLM 모델이 제공하는 api 중에서는 텍스트를 임베딩하는 api가 포함되어 있다.
- API 호출을 통해 손쉽게 고성능의 텍스트 임베딩 결과물을 얻을 수 있다.
- 일부 비용이 들지만 생각보다 비싸진 않다..!
OpenAI에서 API key 발급받기
- https://openai.com/api/ 로 접속하여 api 키를 신청할 수 있다.
- 가입 후 Organization을 설정하고 신규 프로젝트를 생성
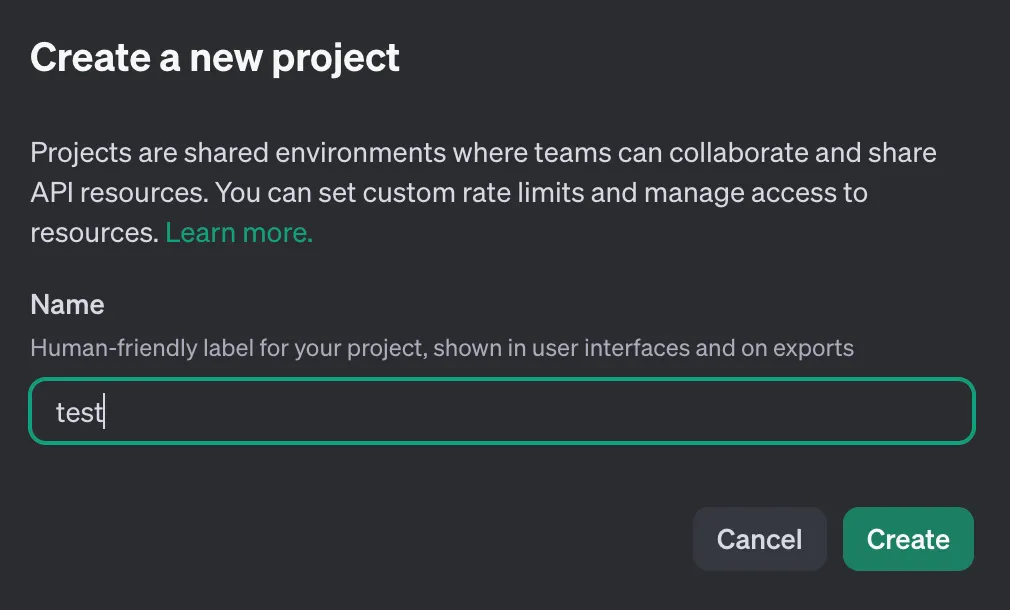
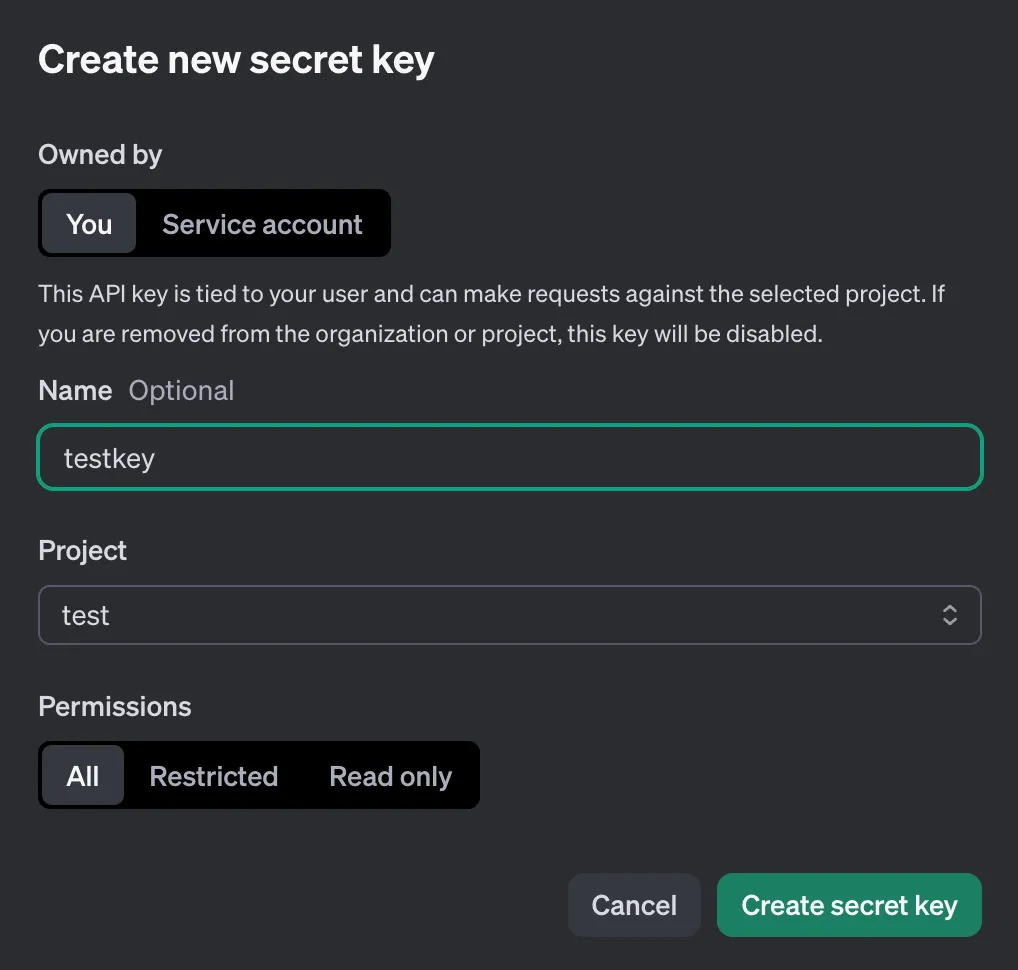
Secret key를 발급받고 해당 키값을 잘 저장해둡시다. 이 키를 활용해 api를 호출
Payment를 등록하고 credit을 결제하면 자유롭게 api를 호출할 수 있다.
임베딩 관련 API 호출에 대한 비용은 아래와 같다.

api 과금은 token 당 이루어진다. 여기서 token은 텍스트를 쪼개는 단위로, 지난 강의에서 다룬 것처럼 단어나 형태소 단위와는 조금 다르게 텍스트를 효율적으로 인코딩하는 방식을 따름.
key points
-
감성분석: 리뷰나 댓글에 주로 많이 사용할 수 있다.(지도 학습)
예)화해의 경우 댓글에 주로 나오는 특정 단어를 활용해 '발림성'이런 단어로 분류 및 분석. -
텍스트 자동 분석: 카테고리로 자동 분류
; 대량의 문서처럼 뉴스 처럼 카테고리가 있고(정치, 과학, 경제...)하루에도 엄청난 양이 존재하므로 자동 분류 가능(지도학습) -
클러스터링(비지도)
주로 유클리디언 거리를 사용하지만 사실 차원이 너무 큰 경우 오류 발생. 의미상 거리과 실제 거리에 오차가 존재한다. 그러므로 코사인 거리를 활용하면 더 좋은 성능을 기대할 수 있다.- 텍스트데이터의 경우는 비슷한 단어가 많이 쓰이는것이 중요하다. 거리보다는!거리보단 차원이 중요한거!

Be DBA