CONTNETNS
- API(Application Programming Interface)란 무엇인가?
- Requests로 API 요청 보내기
- 응답 데이터 처리 및 JSON 파싱하기
- 데이터 CSV 파일로 저장하기
- API 활용의 장단점
- Class로 만들어보자
SUMMARY
1. API(Application Programming Interface)란 무엇인가?
:서로 다른 소프트웨어 시스템이 통신할 수 있도록 도와주는 인터페이스.
데이터 분석에서는 웹사이트나 서버에서 제공하는 데이터를 API를 통해 요청하여 쉽게 가져올 수 있고, 일반적으로 JSON 형식으로 데이터를 응답하며, 이를 파싱하여 원하는 형태로 처리할 수 있다.
데이터분석가에게 API이란?
- 외부 서비스와의 통신을 통해 방대한 양의 데이터를 효율적으로 수집할 수 있는 강력한 도구.
- 실시간 데이터, 공공 데이터, 소셜 미디어 데이터 등 다양한 소스에서 분석에 필요한 자료를 신속히 확보할 수 있다.
- 구조화된 데이터를 활용하여 보다 정밀한 분석과 시계열 모니터링, 트렌드 분석이 가능.
- 데이터 분석가가 다양한 데이터 소스를 활용할 수 있는 능력을 키우는 데 중요한 기술.
- Requests로 API 요청 보내기
- requests 라이브러리를 사용하여 API에 요청하기
import requests
url = "https://api.example.com/data" # 예제 API URL
params = {
"key": "YOUR_API_KEY", # API 키 (실제 키로 교체)
"parameter1": "value1", # 예시 파라미터 값
"parameter2": "value2" # 예시 파라미터 값
}
response = requests.get(url, params=params)- API 키: 보안과 인증을 위해 API 키가 필요한 경우가 많다. 요청 시 키를 포함하여 인증 절차를 거치게 되며, 보통 API 제공자가 발급한 키를 사용. 제공하는 데이터 소스에 따라 해당 API KEY를 header에 붙여서 보내는 방법도 있다. 자세한 부분은 제공 업체의 API Documentation을 확인.
- 파라미터: 요청에 함께 전달하는 값으로, 특정 데이터나 필터링 조건을 지정할 수 있습다. 각 API 문서에서 요구되는 필수 및 선택 파라미터를 확인하여 사용하면 된다.
- 응답 데이터 처리 및 JSON 파싱하기
- 응답 데이터는 일반적으로 JSON(JavaScript Object Notation) 형식으로 제공.
- JSON 형식은 Python의 딕셔너리 형태와 매우 유사하며, 키-값 쌍으로 데이터를 저장하는 구조를 가지고 있다.
- JSON에서는 문자열로 된 키와 다양한 데이터 유형의 값을 사용할 수 있는데, 이는 Python 딕셔너리의 사용 방식과 거의 동일하여 변환과 활용이 쉽다.
data = response.json() # JSON 응답을 Python 딕셔너리로 변환
print(data)*예제: JSON 데이터에서 특정 값 추출하기
# 예제 데이터가 {'name': 'John', 'age': 30, 'location': 'Seoul'} 형식이라고 가정
name = data.get('name')
age = data.get('age')
location = data.get('location')
print(f"이름: {name}, 나이: {age}, 위치: {location}")🌍 실습: OpenWeather API 를 활용해 서울의 날씨 데이터 가져오기
1) API 문서 확인하기
1. 입력 파라미터: https://openweathermap.org/current#name
2. 응답 예시: https://openweathermap.org/current#example_JSON
2) .env 파일에 API_KEY 를 저장.
1. 중요한 정보(API KEY, DB 패스워드 등)를 숨기는데 중요한 .env 파일
3) requests를 사용하여 OpenWeather API에 요청을 보내고 응답을 가져온다.
4) 응답에서 날씨, 온도, 습도 정보 등을 추출.
import requests
import pandas as pd
import os
from dotenv import load_dotenv
load_dotenv()
# OpenWeather API 요청을 위한 기본 설정
# (https://openweathermap.org/api/one-call-3#current)
api_key = os.environ.get('API_KEY') # 본인의 API 키를 입력하세요.
city_name = "Seoul" # 도시는 "서울"로 설정
url = "http://api.openweathermap.org/data/2.5/weather"
params = {"q": city_name, "appid": api_key, "units": "metric"}
response = requests.get(url, params=params)
# API 응답 데이터 처리
data = response.json()
# 간단한 Pandas 전처리 수행
df_weather = pd.json_normalize(data) # JSON 데이터를 Pandas 형태로 변환
df_weather["measured_at"] = pd.to_datetime(df_weather["dt"], unit="s") # 기준시간
df_weather["dt"] = df_weather["measured_at"].dt.strftime('%Y%m%d') # 기준년월일 (YYYYMMDD)
df_weather["time"] = df_weather["measured_at"].dt.strftime('%H%M%S') # 기준년월일 (HHHHMMSS)
df_selected = df_weather[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={"name": "city", "main.temp": "temperature", "main.humidity": "humidity", "wind.speed": "wind_speed"}
)
df_selected- 데이터 CSV 파일로 저장하기
import pandas as pd
# 데이터 준비
df = pd.DataFrame(df_selected)
df.to_csv('weather_api.csv', index=False)
print("날씨 정보가 CSV 파일로 저장되었습니다.")- API 활용의 장단점
장점
- 데이터 수집의 용이성: API를 통해 데이터를 자동화하여 손쉽게 수집할 수 있다.
- 실시간 데이터: 최신 정보를 빠르게 가져와 실시간 분석이 가능.
- 일관된 데이터 형식: JSON 형식의 데이터로 제공되므로 파싱과 처리가 용이하다.
단점
- 요청 제한: 일부 API는 요청 수에 제한이 있어 과도한 요청 시 문제가 될 수 있다.
- 인증 필요: 보통 API 키나 인증 토큰이 필요.
- 데이터 접근 제한: 일부 데이터는 유료이거나 특정 권한이 필요할 수 있다.
- Class로 만들어보자
예시: WeatherApiClient 클래스 = 특정 도시의 날씨 정보를 API를 통해 가져오는 기능
import requests
class WeatherApiClient:
"""
OpenWeatherMap API 클라이언트를 사용하여 날씨 데이터를 가져오는 클래스입니다.
"""
def __init__(self, api_key: str):
self.base_url = "http://api.openweathermap.org/data/2.5"
if api_key is None:
raise Exception("API 키는 None으로 설정할 수 없습니다.")
self.api_key = api_key
def get_city(self, city_name: str, temperature_units: str = "metric") -> dict:
"""
지정된 도시의 최신 날씨 데이터를 가져옵니다.
Parameters:
- city_name (str): 날씨 정보를 조회할 도시 이름.
- temperature_units (str): 온도 단위 (기본값은 'metric'으로 섭씨 기준).
'metric'은 섭씨, 'imperial'은 화씨, 'standard'는 켈빈 단위를 의미합니다.
Returns:
- dict: 요청한 도시의 날씨 데이터가 포함된 JSON 응답을 반환합니다.
Raises:
- Exception: API 요청이 실패한 경우 상태 코드와 응답 메시지와 함께 예외가 발생합니다.
"""
params = {"q": city_name, "units": temperature_units, "appid": self.api_key}
response = requests.get(f"{self.base_url}/weather", params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(
f"Open Weather API에서 데이터를 추출하지 못했습니다. 상태 코드: {response.status_code}. 응답: {response.text}"
)__init__****: API 클라이언트 객체를 생성할 때 API 키를 초기화합니다. API 키가 없는 경우 예외를 발생시킨다.get_city****: 도시 이름과 온도 단위를 파라미터로 받아 해당 도시의 최신 날씨 데이터를 Open Weather API를 통해 가져온다. requests 라이브러리를 사용하여 API 요청을 보내고, 응답 상태 코드가 200인 경우 데이터를 반환.
*새로 만든 WeatherApiClient 를 활용해 API 를 통해 데이터를 요청하고 CSV 파일에 저장
import pandas as pd
from dotenv import load_dotenv
import os
load_dotenv()
weather_api_client = WeatherApiClient(api_key = os.environ.get("API_KEY"))
data = weather_api_client.get_city("Seoul")
# 간단한 전처리
df_weather = pd.json_normalize(data) # JSON 데이터를 Pandas 형태로 변환
df_weather["measured_at"] = pd.to_datetime(df_weather["dt"], unit="s") # 기준시간
df_weather["dt"] = df_weather["measured_at"].dt.strftime('%Y%m%d') # 기준년월일 (YYYYMMDD)
df_weather["time"] = df_weather["measured_at"].dt.strftime('%H%M%S') # 기준년월일 (HHHHMMSS)
df_selected = df_weather[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={"name": "city", "main.temp": "temperature", "main.humidity": "humidity", "wind.speed": "wind_speed"}
)
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(df_selected)
df.to_csv('weather_api.csv', index=False)KEY POINT
- 파라미터의 의미 잘 알고 있기!
- class를 작성하는 법 익히기!
INSIGHT(실습)
- 시드니의 정보 조회하기
# OpenWeather API 요청을 위한 기본 설정
# (https://openweathermap.org/api)
# API 키 가져오기
api_key = os.environ.get('API_KEY')
city_name = "Sydney"
# API 요청 URL
url = f"http://api.openweathermap.org/data/2.5/weather?q={city_name}&units=metric&appid={api_key}"
response = requests.get(url)
response
# 상태 코드 확인
print(f"Status Code: {response.status_code}")
if response.status_code == 200:
data = response.json()
print("Weather Data:", data)
else:
print("Error:", response.json())Status Code: 200
Weather Data: {'coord': {'lon': 151.2073, 'lat': -33.8679}, 'weather': [{'id': 500, 'main': 'Rain', 'description': 'light rain', 'icon': '10d'}], 'base': 'stations', 'main': {'temp': 18.75, 'feels_like': 18.95, 'temp_min': 17.69, 'temp_max': 20.17, 'pressure': 1020, 'humidity': 87, 'sea_level': 1020, 'grnd_level': 1012}, 'visibility': 10000, 'wind': {'speed': 5.14, 'deg': 170}, 'rain': {'1h': 0.32}, 'clouds': {'all': 100}, 'dt': 1731650678, 'sys': {'type': 2, 'id': 2018875, 'country': 'AU', 'sunrise': 1731609820, 'sunset': 1731659764}, 'timezone': 39600, 'id': 2147714, 'name': 'Sydney', 'cod': 200}
# 테이블화
pd.json_normalize(data)
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(df_selected)
df.to_csv('weather_api.csv', index=False)
print("날씨 정보가 CSV 파일로 저장되었습니다.")날씨 정보가 CSV 파일로 저장되었습니다.
- Class로 만들기
import requests
class WeatherApiClient:
"""
OpenWeatherMap API 클라이언트를 사용하여 날씨 데이터를 가져오는 클래스입니다.
"""
def __init__(self, api_key: str):
self.base_url = "http://api.openweathermap.org/data/2.5"
if api_key is None:
raise Exception("API 키는 None으로 설정할 수 없습니다.")
self.api_key = api_key
def get_city(self, city_name: str, temperature_units: str = "metric") -> dict:
"""
지정된 도시의 최신 날씨 데이터를 가져옵니다.
Parameters:
- city_name (str): 날씨 정보를 조회할 도시 이름.
- temperature_units (str): 온도 단위 (기본값은 'metric'으로 섭씨 기준).
'metric'은 섭씨, 'imperial'은 화씨, 'standard'는 켈빈 단위를 의미합니다.
Returns:
- dict: 요청한 도시의 날씨 데이터가 포함된 JSON 응답을 반환합니다.
Raises:
- Exception: API 요청이 실패한 경우 상태 코드와 응답 메시지와 함께 예외가 발생합니다.
"""
params = {"q": city_name, "units": temperature_units, "appid": self.api_key}
response = requests.get(f"{self.base_url}/weather", params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(
f"Open Weather API에서 데이터를 추출하지 못했습니다. 상태 코드: {response.status_code}. 응답: {response.text}"
)
import pandas as pd
from dotenv import load_dotenv
import os
load_dotenv()
weather_api_client = WeatherApiClient(api_key = os.environ.get("API_KEY"))
data = weather_api_client.get_city("Sydney")
# 간단한 전처리
df_weather = pd.json_normalize(data) # JSON 데이터를 Pandas 형태로 변환
df_weather["measured_at"] = pd.to_datetime(df_weather["dt"], unit="s") # 기준시간
df_weather["dt"] = df_weather["measured_at"].dt.strftime('%Y%m%d') # 기준년월일 (YYYYMMDD)
df_weather["time"] = df_weather["measured_at"].dt.strftime('%H%M%S') # 기준년월일 (HHHHMMSS)
df_selected = df_weather[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={"name": "city", "main.temp": "temperature", "main.humidity": "humidity", "wind.speed": "wind_speed"}
)
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(df_selected)
df.to_csv('weather_api.csv', index=False)
+추가로 네이버에서 특정검색어 결과 뽑기
- 네이버 api 가져오기
import requests # HTTP 요청을 보내고 응답을 받기 위함
import pandas as pd # 테이블 형식으로 데이터 정리를 위함
def search_naver_blog(query, client_id, client_secret):
base_url = "https://openapi.naver.com/v1/search/blog" # 검색 API 기본 URL 주소
headers = {
"X-Naver-Client-Id": client_id,
"X-Naver-Client-Secret": client_secret
}
params = {
"query": query, # 검색어
"display": 10 # 검색 결과 개수
}
response = requests.get(base_url, headers=headers, params=params)
if response.status_code == 200:
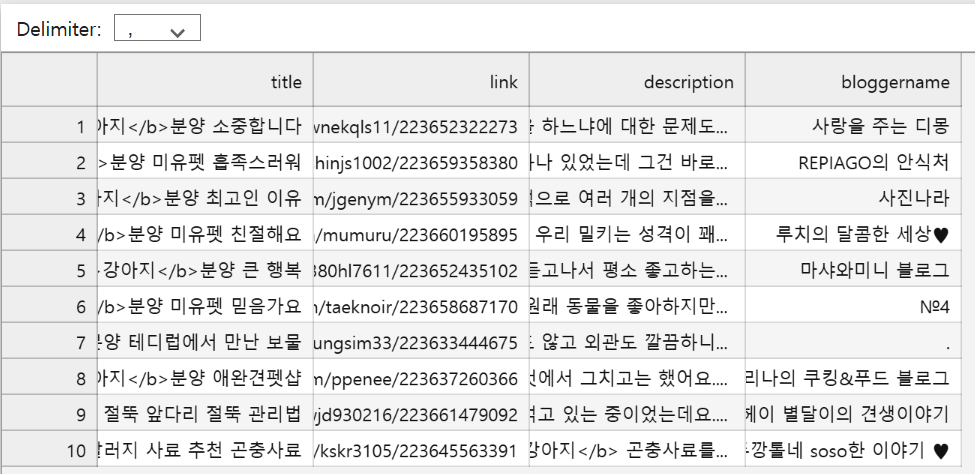
data2 = response.json() # JSON 형식으로 파싱
items = data2['items']
# pd.json_normalize()를 사용하여 JSON 데이터를 DataFrame으로 변환
df2 = pd.json_normalize(items)
# 특정 열 선택 (필요한 경우)
df3 = df2[['title', 'link', 'description', 'bloggername']]
# DataFrame 출력
print(df3.to_markdown(index=False)) # 깔끔한 테이블 출력
# CSV 파일로 저장
csv_filename = "naver_blog_search_results.csv"
df3.to_csv(csv_filename, index=False, encoding='utf-8-sig') # utf-8-sig 인코딩으로 저장하여 한글 문제 방지
print(f"검색 결과가 '{csv_filename}' 파일로 저장되었습니다.")
else:
print(f'Error: {response.status_code}')
# 발급받은 ID, SECRET -> 본인이 발급받은 id, secret 입력하기
client_id = "_ZaMUbBH38sTsY8X7pdN"
client_secret = "C6t7kuo0Kr"
query = input('검색어를 입력하세요: ')
search_naver_blog(query, client_id, client_secret)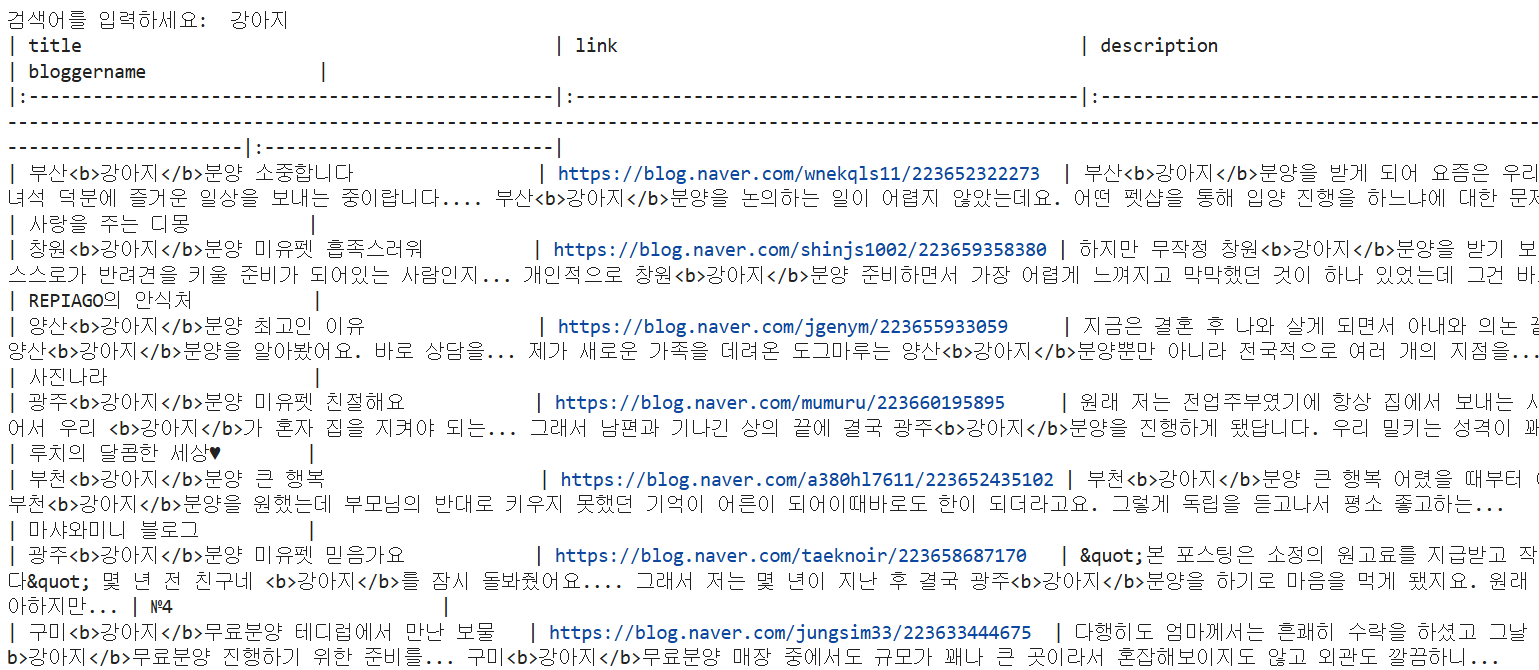
- NaverBlogSearchClient class만들기
import requests
import pandas as pd
class NaverBlogSearchClient:
"""
네이버 블로그 검색 API를 사용하여 검색 결과를 가져오는 클라이언트입니다.
"""
def __init__(self, client_id: str, client_secret: str):
self.base_url = "https://openapi.naver.com/v1/search/blog"
if not client_id or not client_secret:
raise ValueError("Client ID와 Client Secret은 필수 입력값입니다.")
self.client_id = client_id
self.client_secret = client_secret
def search_blog(self, query: str, display: int = 10) -> pd.DataFrame:
"""
지정된 검색어로 네이버 블로그 검색 결과를 가져옵니다.
Parameters:
- query (str): 검색어
- display (int): 가져올 검색 결과의 개수 (최대 100개까지)
Returns:
- pd.DataFrame: 검색 결과를 포함한 DataFrame
"""
headers = {
"X-Naver-Client-Id": self.client_id,
"X-Naver-Client-Secret": self.client_secret
}
params = {
"query": query,
"display": display
}
response = requests.get(self.base_url, headers=headers, params=params)
if response.status_code == 200:
data = response.json()
items = data.get('items', [])
# DataFrame 변환
df = pd.json_normalize(items)
df = df[['title', 'link', 'description', 'bloggername']] # 주요 열만 선택
return df
else:
raise Exception(f"네이버 블로그 검색 API 요청 실패. 상태 코드: {response.status_code}. 응답: {response.text}")
# 사용 예시
if __name__ == "__main__":
client_id = "_ZaMUbBH38sTsY8X7pdN" # 네이버 API 클라이언트 ID
client_secret = "C6t7kuo0Kr" # 네이버 API 클라이언트 시크릿
naver_client = NaverBlogSearchClient(client_id, client_secret)
try:
query = input("검색어를 입력하세요: ")
result_df = naver_client.search_blog(query)
# 검색 결과 출력
print(result_df.to_markdown(index=False))
# CSV로 저장
csv_filename = "naver_blog_search_results.csv"
result_df.to_csv(csv_filename, index=False, encoding='utf-8-sig')
print(f"검색 결과가 '{csv_filename}' 파일로 저장되었습니다.")
except Exception as e:
print(f"오류가 발생했습니다: {e}")