CONTENTS
- 웹크롤링(Web Crawling)이란 무엇인가?
- BeautifulSoup을 사용하여 HTML 파싱 및 데이터 추출
- 수집한 데이터를 CSV 파일로 저장
- 웹크롤링 장단점
- 객체지향 프로그래밍 Object Oriented Programming (OOP)
SUMMARY
- 웹크롤링(Web Crawling)이란 무엇인가?
- 웹 페이지의 데이터를 자동으로 수집하는 기술로, 다양한 웹사이트의 데이터를 효율적으로 모을 수 있다.
- 비정형 데이터를 정형 데이터로 변환하여 데이터 분석에 활용할 수 있는 중요한 도구.
- 특정 웹사이트를 탐색하며 데이터를 수집하고, 이를 분석하거나 저장할 수 있도록 도와준다.
*데이터 분석가가 다양한 데이터 소스를 활용할 수 있는 능력을 키우는 데 중요한 기술이기에 배워두면 좋다!
-requests 라이브러리를 사용하여 URL에 요청을 보내고 응답확인하기
import requests
url = "<URL>" # 예제 URL
response = requests.get(url)
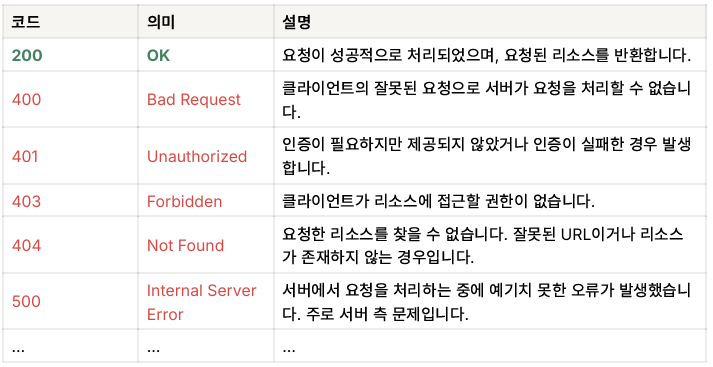
print(response.status_code) # 상태코드 출력- GET 요청 관련 상태 코드
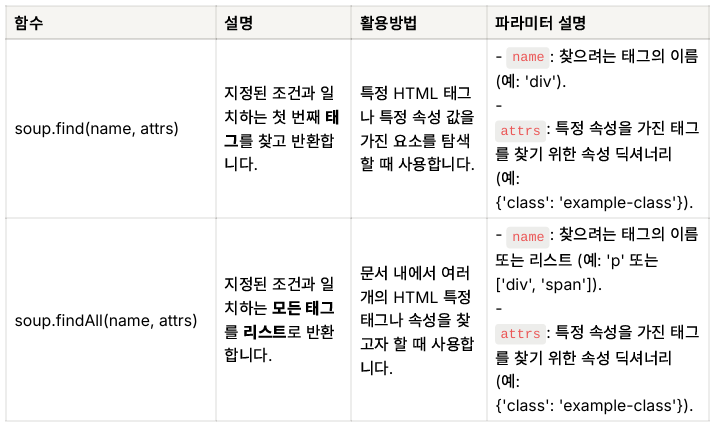
- BeautifulSoup을 사용하여 HTML 파싱 및 데이터 추출
:HTML에서 필요한 데이터 추출하기
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')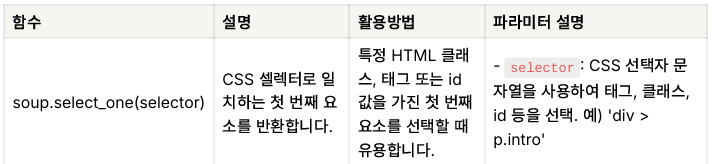
- 📝 예시: soup.select_one 메서드로 원하는 데이터 찾기
select_one: CSS 선택자를 사용하여 특정 조건을 만족하는 첫 번째 HTML 요소를 찾는 데 유용
soup.select_one('CSS 선택자')-
CSS 선택자: HTML 요소를 선택하기 위해 CSS 스타일의 선택자를 사용 (예:div.classname,span#idname,a[href="link"]등). -
🌤 실습: 네이버에서 “서울날씨” 정보 가져오기
request을 사용하여 네이버 날씨 페이지에 접속하여 HTML 응답을 가져온다.BeautifulSoup및select_one을 사용하여 체감온도, 습도, 서풍 정보를 추출한다.
url = "https://search.naver.com/search.naver?query=서울날씨"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
feel_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd').get_text()
humidity = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(2) > dd').get_text()
wind = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(3) > dd').get_text()
print("체감온도:", feel_temp)
print("습도:", humidity)
print("서풍:", wind)- 수집한 데이터를 CSV 파일로 저장
import pandas as pd
# 데이터 준비
data = [{'temperature': feel_temp, 'humidity': humidity, 'wind': wind}]
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(data)
df.to_csv('weather_webscraping.csv', index=False)
print("날씨 정보가 CSV 파일로 저장되었습니다.")- 웹크롤링 장단점
장점
- 데이터 수집 자동화: 대량의 데이터를 자동으로 수집할 수 있어 시간과 노력을 절약한다.
- 다양한 데이터 확보 가능: 웹 페이지에서 다양한 형태의 데이터(텍스트 등)를 가져올 수 있다.
- 빠른 데이터 수집: 특정 웹사이트에서 데이터를 실시간으로 빠르게 수집할 수 있다.
단점
- 법적/윤리적 문제: 일부 웹사이트는 크롤링을 금지하며, 무단 크롤링은 법적 문제를 야기할 수 있다.
- 웹 구조 변경에 취약: 웹페이지 구조가 변경되면 크롤링 코드가 작동하지 않을 수 있다.
- 서버 부하 유발: 지나친 크롤링은 대상 웹사이트에 과부하를 줄 수 있으며, IP 차단 등의 조치를 당할 수 있다.
- 데이터 품질 문제: 비구조적이고 일관되지 않은 데이터로 인해 추가적인 전처리가 필요할 수 있다.
- 객체지향 프로그래밍 Object Oriented Programming (OOP)
:OOP는 데이터를 관리하고 재사용 가능한 코드를 작성하는 데 중요한 역할을 한다. 데이터 수집 파이프라인을 구축할 때도 OOP 개념을 활용하면 더 견고하고 확장 가능한 코드를 만들 수 있다.
- 특징
-현실 개념을 코드로 모델링 가능: 클래스와 객체를 사용하여 현실의 개념과 행동을 코드로 표현할 수 있다.
-코드 재사용성과 유지보수성 향상: 한 번 작성한 클래스를 여러 객체에 재사용할 수 있으며, 유지보수가 쉽다.
-복잡한 문제 해결에 유리: 코드의 모듈화로 문제를 작은 단위로 나눌 수 있어 시스템을 보다 쉽게 관리할 수 있다.
-캡슐화, 상속, 다형성 지원: 데이터 보호, 재사용성 증가, 유연한 동작을 가능하게 한다.
📝 예시: 학생(Student)이라는 객체를 만들어보자!
1) 학생을 처음 정의(__init__)할때 name (이름)과 age (나이)를 설정
2) 학생은 인사(introduce)를 할 수 있다.
3) 학생을 print할때는 학생 정보가 출력.
# 클래스 정의
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"안녕하세요, 저는 {self.name}이고, 나이는 {self.age}살입니다.")
def __str__(self):
return f"!학생에 대한 정보입니다!\n이름: {self.name}\n나이: {self.age}"
# 객체1, 홍길동 생성
student1 = Student("홍길동", 20)
student1.introduce()
print(student1)
# 객체2, 이영희 생성
student2 = Student("이영희", 22)
student2.introduce()
print(student2)KEPY POINS
웹크롤링은 데이터 수집을 자동화 할 수 있는 편리함이 있지만, 단점도 많고 여러 복합적인 문제가 존재한다.
그렇기 때문에 API를 가져오는 방법을 우선적으로 하고, API를 가져올 수 없는 경우 우회적으로 웹크롤링을 실행한다.
*웹크롤리의 사용을 권유하기는 애매!
INSIGHT
- 숙제
https://news.naver.com/breakingnews/section/101/258
이 링크에 있는 기사 제목 다 가져오기!
import requests
url = "https://news.naver.com/breakingnews/section/101/258"
response = requests.get(url)
print(response.status_code) # 상태코드 출력200
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
url = "https://news.naver.com/breakingnews/section/101/258"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
first_title = soup.select_one('.sa_text_strong').get_text(strip=True)
print(first_title) # 첫 번째 기사 제목만 출력[스팟]코스피 65.49포인트(2.64%) 내린 2417.08 마감
# 모든 기사 제목 가져오기
titles = soup.select('.sa_text_strong')
for title in titles:
print(title.get_text(strip=True))[스팟]코스피 65.49포인트(2.64%) 내린 2417.08 마감
“코스피 부진은 삼성전자 급락 착시... 삼전 외 종목은 하락 룸 아직 많다”
[속보] 코스피 2.64% 급락 2,417.08 마감…시총 2천조 아래로
[코스피] 65.49p(2.64%) 내린 2417.08 마감
다날, 에이블리와 4910에 휴대폰결제 단독 제공
“공모펀드, 주식·ETF처럼 상장 거래”…금융위, 혁심금융 서비스 신규 지정
[코스닥] 20.87p(2.94%) 내린 689.65(장종료)
[속보] 코스피, 2.64%↓마감…시총 120조 증발
코스피, 코스닥 지수 큰 폭으로 하락
"배춧값 낮추는 데 써주세요"… 대상, 농협 배추 할인 후원
코스닥 지수, 2개월 만에 700선 붕괴
주총 표대결 직행하는 고려아연…표심 잡을 핵심 주장은
비트코인, 단숨에 5만→9만달러…포모 vs 우상향
한온시스템 3분기 영업이익 937억원…작년 동기 대비 391.1%↑(종합)
KB자산운용, 민자발전 기여 공로 경제부총리 표창 수상
윤병운 NH證 대표 "K증시 변동성에 통찰력 필요"
경동제약, 3Q 매출액 496억원…전년동기比 27%↑ "매출·수익성 개선"
비트코인 '2억원' 시대 열리나
국내 전기차 시장 '충전 완료'…올 누적 판매, 성장세 첫 전환
키움증권, 세전 연 4.4% 하나은행 채권 특판
이석우 두나무 대표 "국경없는 가상자산…韓 산업 글로벌 경쟁력 키워야"
케이피에스, '전문의약품 강자' 한국글로벌제약 인수…"내년 매출액 2000억 목표"
케이피에스, 전문의약품 한국글로벌제약 인수 "내년 매출액 2000억 목표"
스맥, 3분기 영업이익 209억원…전년 동기 대비 25%↑
코스피 2% 넘게 하락…삼성전자 5만원 선 위협
데이터 기반 실적주 투자, 임채욱 "양자암호, AI 산업 주목"
케이피에스, '전문의약품 강자' 한국글로벌제약 인수 "내년 매출액 2000억 목표"
에이비엘바이오, 주가상승에 '깜짝' 놀란 이유
NH증권, 내년 증시 및 투자전략 포럼 개최… "코스피 2250~2850"
장중 2%대 하락한 코스피
흘러내리는 코스피
흘러내리는 코스피
달러 1400원
개회사 하는 이석우 두나무 대표
고려아연, 유상증자 계획 철회에도 13% 하락…"호재 소멸?"[핫종목]
"패닉 셀링"…코스피 시가총액 2000조원 밑으로 [장중시황]
➕기사의 클래스명 가져오기!
1. f12누른뒤 개발자 도구 열기
2. 맨 왼쪽에 화살표 모양 누르기
3. 원하는 기사 제목 누르기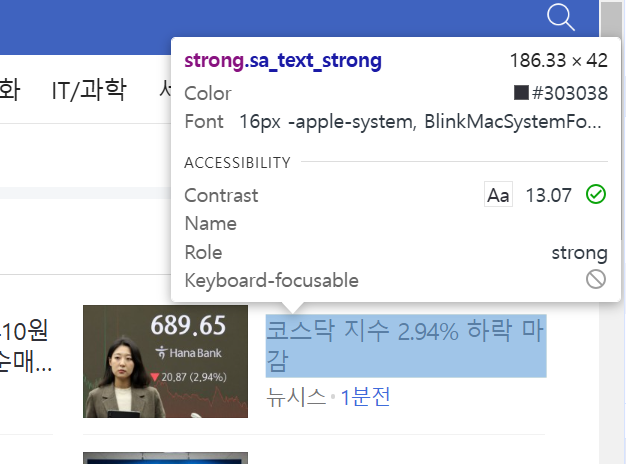
4.<class = "sa_text_strong"> 부분 확인하기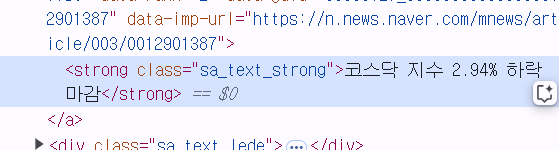
5. sa_text_strong 앞에 .만 붙여주기! .sa_text_strong가 클래스명!
➕get_text(strip=True)와 get_text()의 차이
get_text(strip=True)
- strip=True 옵션을 사용하면 문자열 앞뒤에 있는 공백이 제거된다.
- HTML 요소에서 텍스트를 가져올 때, 앞뒤에 있는 불필요한 공백을 자동으로 제거하고 깔끔하게 출력된다.
- 예를 들어, " 제목 텍스트 "와 같은 요소에서 get_text(strip=True)를 사용하면 "제목 텍스트"로 출력.
get_text()
-
get_text()는 strip 옵션 없이 텍스트를 그대로 가져온다.
-
이 경우, HTML 요소의 텍스트 앞뒤에 공백이 남아 있을 수 있다.
-
" 제목 텍스트 "와 같은 요소에서 get_text()를 사용하면 " 제목 텍스트 "처럼 앞뒤 공백이 포함된 채로 출력.
-
csv파일로 저장하기
import pandas as pd
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(titles)
df.to_csv('naver_headline.csv', index=False)
print("기사제목이 CSV 파일로 저장되었습니다.")기사제목이 CSV 파일로 저장되었습니다.

잘 저장된 것을 확인할 수 있다!
