Python
간단한 소개와 장, 단점
장점 : 배우기가 쉽다 => 문법도 간단하고, 데이터 처리로도 용이하다.
단점 : 들여쓰기(띄어쓰기 4칸)을 권장하고, {} 중괄호가 없다.
interactive 하게 실행이 가능하다. => 즉 전체 코드를 한 번에 실행시키는 것이 아니라, 부분부분마다 코드를 실행시켜보면서 어느 부분에서 에러가 발생하는지, 혹은 데이터를 분석하는 과정에서 처리 순서를 설정하고 실행하는 것이 용이하다.
데이터분석 용 라이브러리 지원이 훌륭하다. ex) numpy
python 은 버전이 존재하는데, 2버전과 3버전으로 나뉘어진다. 그 중에서 주로 사용하게 되는 건 3버전이다.
파이썬의 개발환경
IDE
- 파이참 : 데이터 분석이 가능은 하지만 django 를 이용한 웹 프로그래밍을 개발할 때 자주 사용하는 IDE
- jupyter notebook : 웹 기반의 개발 툴로, 데이터 분석이나 머신러닝, 딥러닝을 할 때 자주 사용하게 되는 IDE
- 로컬 컴퓨터에 환경 설정을 해서 사용하기
- 클라우드에 설정된 설정을 이용해서 사용하기(coLab) : 단점으로, 세션이 종료될 수도 있어서 작업의 안정성이 떨어지게 된다.
그러나 pyyhon 을 설치하고, jupyter notebook 을 개개로 설치하는 것 자체는 가능하지만, 의존성 문제로 인해 향후 문제가 발생할 가능성이 있다. 또한 다양한 라이브러리를 사용할 때 역시 의존성 관리 문제가 발생한다.
이러한 문제를 해결하기 위해서, 모든 의존성 관리를 해결해주는 하나의 platform 이 존재한다.
그게 바로 anaconda 이다.
cell : 입력할 수 있는 공간

주석처리


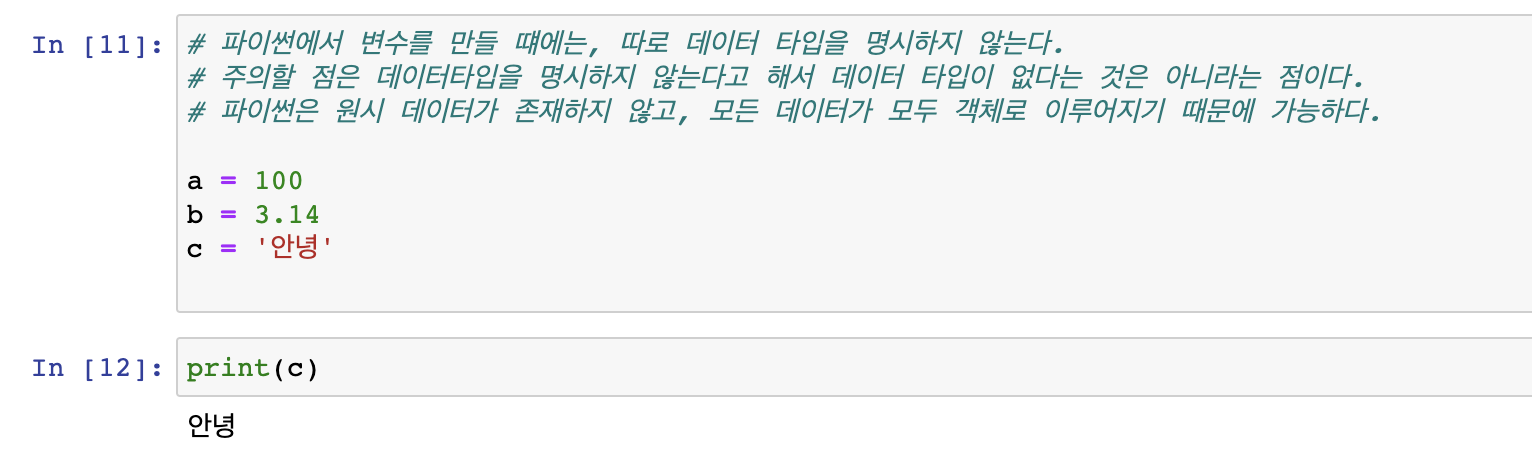
주피터 노트북에서 cell 이라는 단위가 있더라도, 각 cell 에서 선언된 변수나, 함수가 독립적인 것은 아니다. 다른 cell 에서 선언한 변수도 모두 실행이 가능하다.
python 의 built-in data type
python 의 경우, 범주로 데이터 타입을 나눈다.
1. Numeric : 숫자
정수, 실수, 복소수, 진수(8진수, 16진수...)
a = 123 # 정수
b = 3.1415926... # 실수둘 모두 데이터 타입은 Numeric
type 이라는 파이썬에서 제공하는 함수가 제공한다.
해당 함수를 사용하게 되면, 해당 변수의 데이터 타입을 알려준다.

그리고 결과를 찍어보면, int, float 라는, 변수가 어떤 클래스로부터 파생된 객체인지를 알려주게 된다.
즉 거듭 말하지만 파이썬의 변수는 범주로 나뉘게 되고, 기본적으로 모든 변수는 객체 타입이다.
따라서 객체를 만들기 위해서는 class 가 필요하고, type 함수는 해당 변수를 만들기 위한 클래스를 알려주게 된다.
연산
result = 3 / 4
print(result)
# java 의 경우 0
# python 은 0.75정수를 썼다 할 지라도, 내부적으로는 실수 타입으로 계산을 하게 된다. 그렇기 때문에 계산 시에는 0 이 아니라, 0.75 가 나오게 된다.
2. Sequence
기존에 알고 있는 데이터 타입이라는 것은, 데이터의 형태를 의미했다.
그런데 python 의 경우, 자료구조 역시 하나의 데이터 타입으로 인식한다.
즉 파이썬에서 등장하는 자료구조인 list, dictionary, set... 등은 모두 데이터 타입으로 구분된다.
Sequence 는 3가지가 존재한다.
2-1. list
: python 에서 가장 중요한 자료구조이자 data type
객체를 순서대로 저장하는 집합형 자료구조.
Java 의 arrayList 와 상당히 유사한 구조이다.
literal(표현방식)은 어떻게 되나요?
list_a = list() => 클래스의 constructer 를 이용해서 만드는 방법
list_b = [] => literal 표현방식
# 증첩 리스트도 가능하다
list_c = [list_a, 3, 5, []]2차원 배열.. 이런 식으로 예시하기 않는다. python 에는 차원 개념이 없고, 그저 리스트 안에 또 다른 리스트가 있다라고만 표현한다.
python 리스트만의 중요한 개념 중 하나로, index 를 통해 값을 가지고 올 때, 일반적인 0~ 인덱싱 뿐만 아니라 -1~ 인덱싱이 가능하다.
list[-1] 과 같은 표현의 경우에는 해당 리스트의 가장 마지막값에서부터 하나씩 추출하는 것을 표현한다.
indexing : 위치에 대한 숫자를 가지고 해당 위치의 요소를 내가 제어하는(가지고 오거나, 바꾸거나, 제거하는) 것을 의미한다.
slicing : 집합 자료구조에서 내가 원하는 요소만 잘라서 가지고 오는 것을 의미한다. 중요한 것은 slicing 은 원본의 데이터 형태, 결과가 동일하다.
즉 indexing 의 예시에서 list_c[3][2] 의 값은 3.14 이고, 이것은 int 클래스에서 파생된 Numeric 데이터 타입이다.
list_c[0:2] 의 경우 list_c 의 데이터 타입인 list 타입에서 0번, 1번 인덱스만을 가진 리스트를 가지고 오게 된다.
주의해야 할 점은, 슬라이싱의 앞쪽은 포함이고, 뒤쪽을 미포함이다.
리스트의 연산


2-2. Tuple
: 기본적으로 list 와 동일하지만, list와 다른 한 가지 특징이 있는데, read only 라는 점이다.
my_tuple = tuple() => 클래스의 constructer 를 이용해서 만드는 방법
my_tuple = () => literal 표현방식
my_tuple = (1,2,3,4)
print(myTuple)
a = (1)
소괄호 안에 데이터가 여러 개 있으면, 튜플임을 바로 인지할 수 있지만
소괄호 안에 하나의 데이터만 있으면, 그 것이 튜플인지 아닌지 구분하기가 어렵다.
그렇기 때문에 (1, ) 와 같은 형태로, 튜플임을 명시하기 위해 콤마를 찍어서 표현한다.
tuple 은 read only 이다. 즉 객체의 위치인 메모리주소를 가지고 값이 바뀌는지 아닌지를 구별한다. 때문에, tuple 내부에 list 값을 가지고 있다면, 해당 list 자체가 변하지 않는 이상 리스트가 갖고 있는 내부의 데이터를 변화시킬 수 있다.


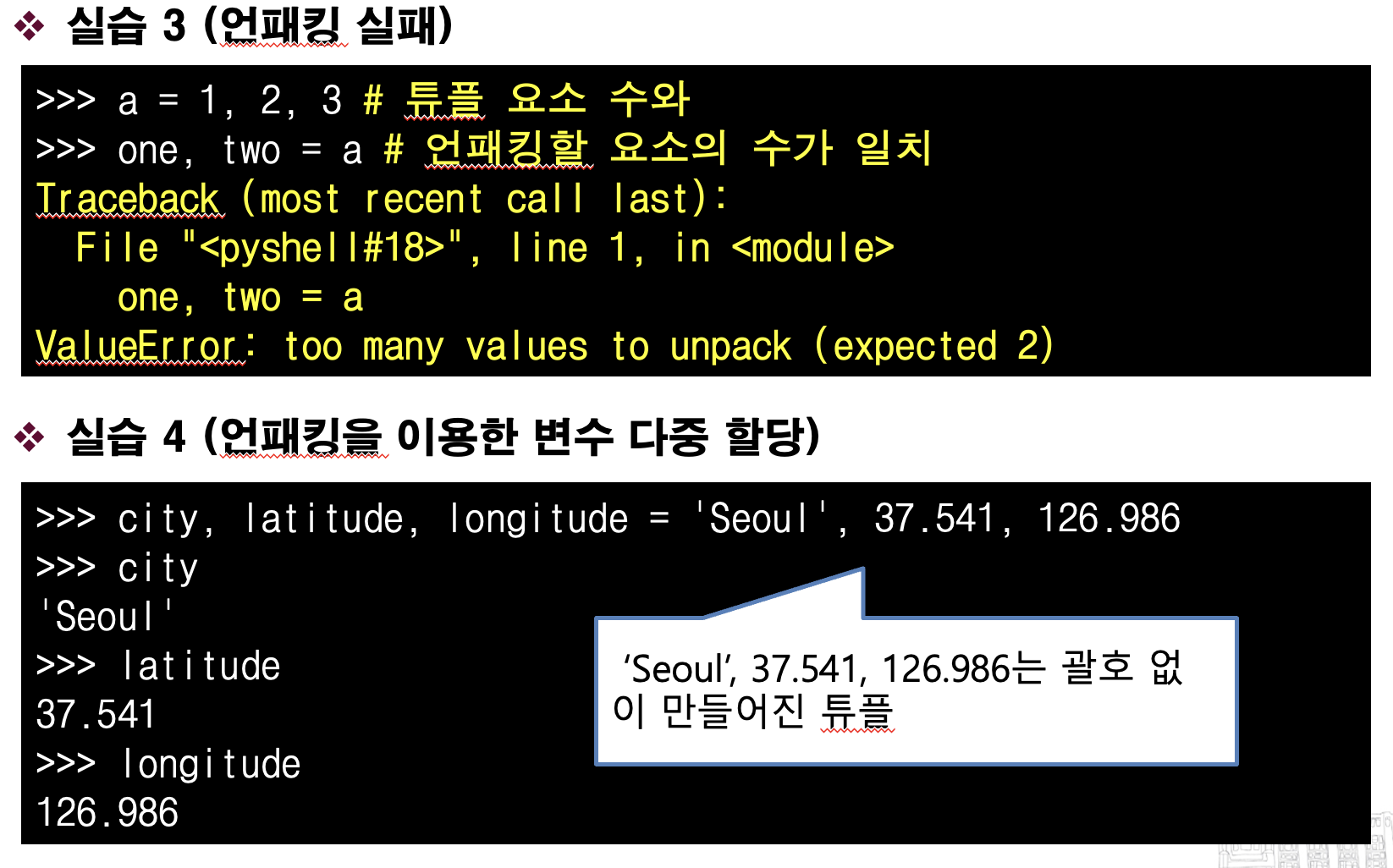
a,b,c = 1,2,3 과 같은 코드는 앞의 a,b,c 도 tuple 이고, 1,2,3 역시 튜플이다.

2-3. range
: 숫자 범위
range 는 literal 로 쓰지 않는다.
a = range(10)
# 시작은 0부터 시작하고, 10이 되기 전까지 1씩 증가하는 숫자의 범위.
b = range(1, 8)
range 라는 것은 실제 데이터를 가지고 있는 것이 아니라, 해당 숫자 범위를 표현하는 것이다. 따라서 print(a) 를 하더라도 실제 데이터 값이 찍히지는 않는다.

다만 range 에서도 indexing 을 찍는 순간, 해당하는 값을 출력해준다.

2부터 2씩 증가해서 20보다 작은 숫자의 범위의 값을 뽑아주는 for 문을 작성할 수도 있다.
3. Text Sequence
str
: 문자열을 의미하고, 사용하는 클래스는 str 이다.
literal 은 '', "" 둘 다 사용이 가능하다. (default는 '')
따라서, 파이썬은 문자의 개념이 없고, 모두 문자열로 판단을 한다.
Text Sequence의 기반 역시 list 기반이다. list 안에 문자열이 들어가게 되는 구조라고 볼 수 있다.
따라서 list 의 성질을 그대로 이어받아서 사용이 가능하다.
a = '홍' 문자열 => text sequence => list 기반
b = '길동' 문자열 => text sequence => list 기반
print(a+b) # 홍길동 => list+list 는 이어붙이기.python 에서 in 이라는 키워드를 통해 리스트 내에 해당 값이 있는지 없는지를 구분하고, 결과값을 True, False 로 출력한다.
주의해서 알아야 할 것은 java는 true/false 인 반면, python 은 True/False 라는 대문자라는 점이다.

4. Mapping
key-value 로 데이터를 저장하는 구조.
파이썬에서는 이러한 자료 구조를 dictionary 라고 부른다.
당연히 사용하는 class 는 dict() 이다.
a = dict()
b = {}
... ex)
c = {'name' : 'hong', 'age' : 20 }특정 dictionary 에 새로운 key-value 를 추가하거나, dictionary 안에 있는 요소를 참조할 때에는 [] 를 사용한다.

해당 dictionary 에 있는 key 들을 출력하는 메소드로 dict.keys() 라는 메소드가 있다. 해당 메소드를 실행하면, list와 거의 똑같은, 그러나 list 는 아닌! dict_keys 라는 자료구조가 만들어진다. 그리고, 해당 자료구조 안에 keys 가 담기게 된다.

여기서 유사 list 이다, 라는 개념이 중요한 이유는 list 에서 사용이 가능한 다양한 메소드/함수들을 사용할 수 없기 때문이다.
5. Set
순서가 없고 중복을 허용하지 않는 자료구조, java의 set과 특징이 거의 동일하다.
my_set = set() => 클래스의 constructer 를 이용해서 만드는 방법
my_set = {} => literal 표현방식
리터럴로 표현하는 방식이 dictionary 와 동일하다.
하지만, set 은 key-value 가 없고, dictionary 는 key-value 가 존재한다.
6. Bool
True or False : 대문자 첫글자로 시작한다.
controll statement(제어문)
대표적인 제어문으로 if, for, while 이 존재한다.
if 문
area = ['서울', '부산', '제주']
if '서울' in area:
print('서울이 존재합니다.')
else:
print('서울이 존재하지 않습니다.')
기본적으로 python 은 제어문을 사용할 때, : 을 사용한다.

만약 if 문에서 true 일 때, 아무것도 시행하지 않고 넘어가기를 원한다면, pass 라는 키워드를 이용한다.
for문
# for ~ in range()
for i in range(5):
print(i, end=' ')
해당 코드의 경우, 반복하려는 횟수를 명시적으로 지정할 때 주로 이용한다.
# for ~ in list, dict
for node in area:
print(node, end=' ')
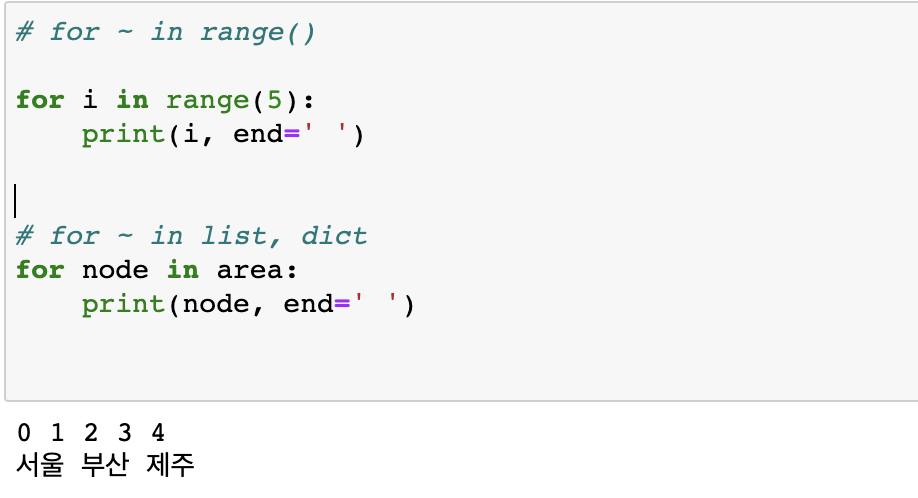
print()
: 인자로 들어온 문자열을 출력하고, 한 줄을 띄우는 함수이다. 그런데 인자로 end 을 사용하게 되면, 띄어쓰기 대신 end에 적은 문자를 사용한다.
for i in range(10):
print(i, end=', ')
#1, 2, 3, 4, 5, 6, 7, 8, 9파이썬에서 함수를 사용하는 방법

Anaconda
아나콘다를 설치하게 되면, 가장 기본적인 환경으로 base 라는 이름을 가진 환경설정이 주어지게 된다.
파이썬 설치
brew install python
아나콘다 설치
brew install --cask anaconda
아나콘다의 환경변수 설정
export PATH='/opt/homebrew/anaconda3/bin:PATH'
sources ~/zshrc
터미널을 종료헀다가 다시 켰을 때 conda 명령어를 사용할 수 있도록 하는 명령어
conda init zsh
새로운 가상환경 생성
conda create -n pyenv python=3.8
or
conda create --name pyenv python=3.8
데이터분석을 위한 기반이 되는 라이브러리가 3가지 존재한다.
- numpy

conda install numpy
- pandas

conda install pandas
- matplotlib

데이터를 분석하면, 숫자들이 나열된다. 그럼 그 숫자를 그림으로 시각화하는 작업이 필요한데, 그 때 사용하는 시각화 모듈이 여러 가지 존재한다. 그 중에서도 가장 기본이 되는 것이 matplotlib 이다.
conda install matplotlib
주피터 노트북을 conda 를 이용해 설치
conda install nb_conda
혹은
conda install jupyter notebook
주피터 노트북 시작 디렉토리 설정

jupyter notebook --generate-config
: 환경설정이 적혀있는 파일 위치를 알려주는 코드

해당 위치로 접속해서 jupyter_notebook_config.py 파일을 연 뒤
c.NotebookApp.notkbook_dir = '' 을 활성화시키고 원하는 폴더 위치를 잡는다.
주피터 노트북 실행
jupyer notebook
Numpy
Numetical Python ==> numpy
파이썬의 기본이 리스트이다보니, 데이터를 가공하고, 연산할 때 효율성이 떨어지게 된다. 그래서 그 점을 보완하기 위해 외부에서 라이브러리를 가져다가 사용하게 되는데, 그 모든 것의 근간이 되는 라이브러리가 numpy 이고, numpy 의 ndArray 이다.
데아터 분석, 머신 러닝, 딥러닝 과 같은 분야를 할 때, 가장 시간이 많이 걸리고, 잘 해야만 하는 것이 데이터 수집 과 정제 이다.
pandas(데이터 분석 module) 와 matplotlib(시각화모듈) 의 base 가 되는 기본 자료구조를 제공하는 것이 numpy
nbarray
numpy 는 딱 하나의 자료구조를 제공한다. 그 자료구조가 nbarray 이다.
nbarray 란 n-dimensional array => 다차원배열
이 다차원배열을 사용하는 이유는 많은 량의 데이터를 보다 적은 메모리를 사용해서 빠른 속도로 처리하기 위함이다.
a = range(10)
arr = np.array(a)
인자로는 python 의 list 타입을 넣어준다.
print(a) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(arr) # [1 2 3 4 5 6 7 8 9]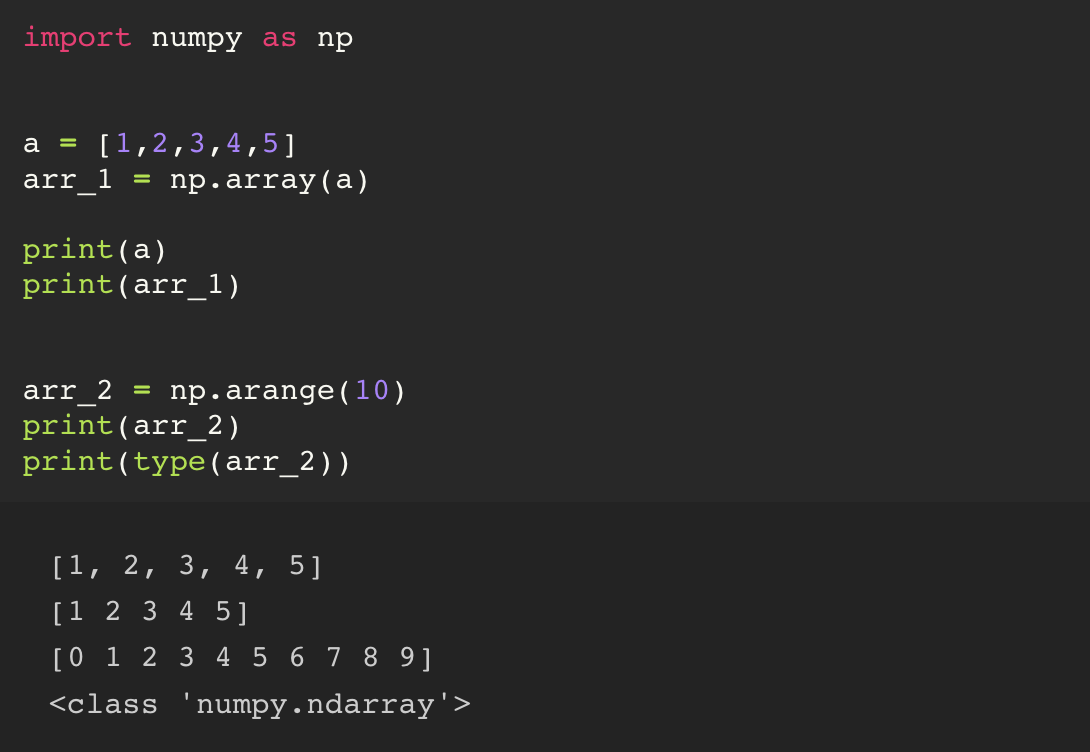
nbarray의 특징으로 기억해야 할 특징이 있다.
기존의 list 의 경우, 데이터 타입의 구분 없이 모든 데이터가 들어갈 수 있다.
ex) list = [1, 3.14, '홍길동', True]그러나, nbarray 의 경우에는 무조건 같은 타입의 데이터만으로 이루어질 수 있다.
그렇기 때문에 만약 list 의 데이터 타입이 정수-실수가 섞여있다면, nbarray 는 내부적으로 모든 데이터를 실수로 변환해서 처리한다.
d = np.array([1, 2, 3.14, 4, 5])
print(d)
numpy 내부적으로 dtype 이라는 속성이 존재하는데, 해당 속성을 통해, 현재 nbarray 안에 들어가 있는 데이터의 타입을 알 수 있다.
nbarray 가 list 와 가장 크게 차이나는 것은 차원을 표현할 수 있다는 점이다.

기본적인 python 의 리스트 자료 구조에서 중첩 리스트 형태인 myList 가 존재한다. 이것을 numpy 를 이용해서 변환하게 되면, 2차원 배열로 변환이 가능해진다.
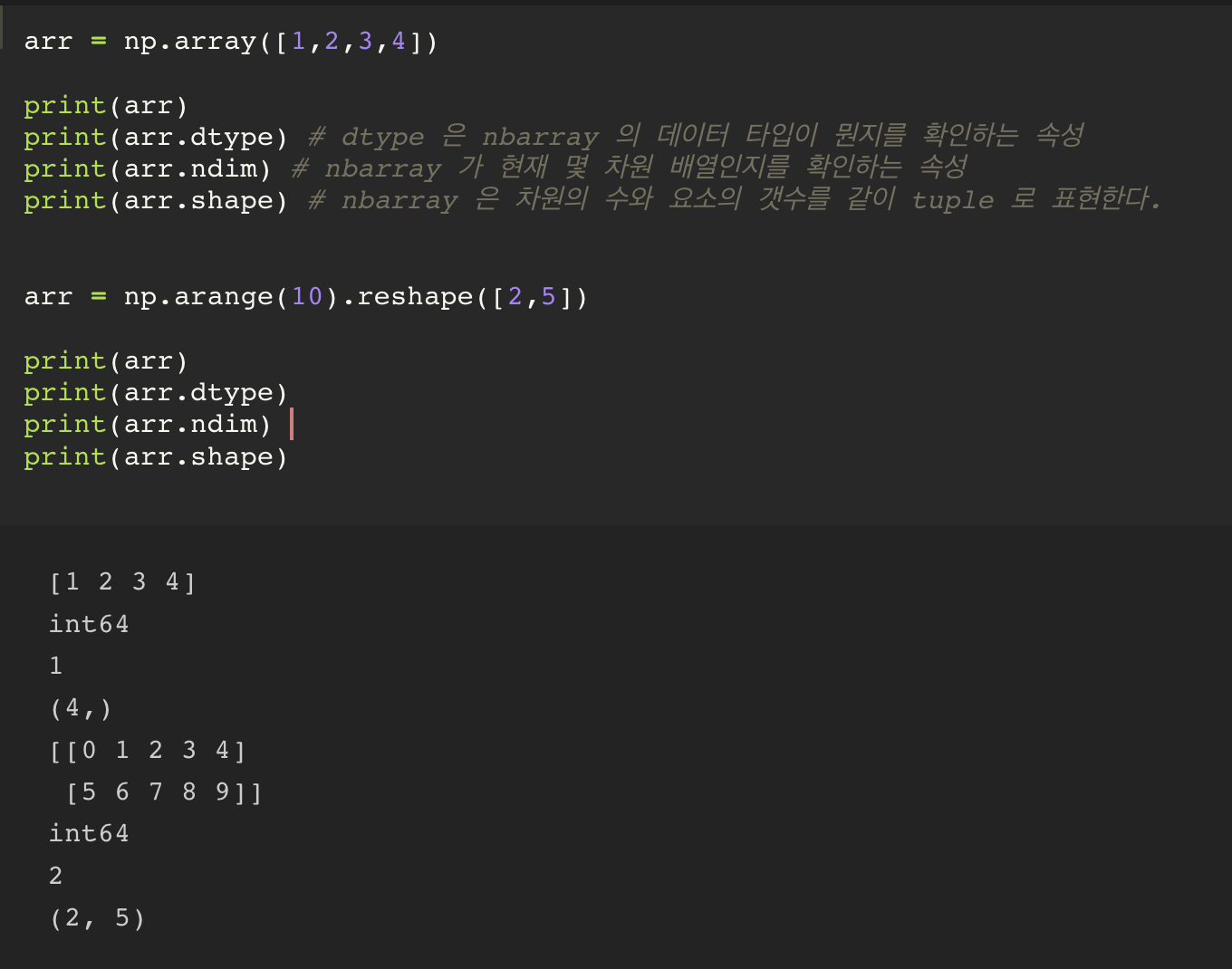
reshape([]) : 기존의 nbarray 를 다른 차원으로 변환하는 속성. 괄호 안에 axis0(행)의 갯수, axis1(열)의 갯수, axis2(깊이)의 갯수..... 를 콤마를 기준으로 구분자를 넣는다.
만약 기존의 데이터가 reshape() 하기에 데이터량이 부족하다면 에러를 내뱉는다.
