복습
파이썬의 데이터 타입은...
- Numeric
- Sequence
- Test Sequence
- Mapping
- Set
- Bool
python 은 Array를 지원하지 않기 때문에, 2차원, 3차원 표현이 불가능하다.
또한 python의 기본 자료구조인 list 의 경우, 많은 양의 데이터 처리를 함에 있어서 퍼포먼스가 떨어진다(속도가 안나오고, 메모리적으로도 효율이 좋지 못하다)
=> 이 점을 해결하기 위한 새로운 모듈이 등장하는데, 그게 바로 numpy 이다.
numpy 는 ndarray 라는, 배열 형태의 자료구조를 지원해준다.
a = 10 # scalar -> 값이 하나만 있을 떄에는 차원이 아니다. 즉 0차원을 의미하는 것이 scalar
b = [10, 20, 30] # 1차원 vector
c = [ [10, 20, 30], [40, 50, 60] ] # 2차원 matrix-행렬
d = [ [ [10, 20], [30, 40]], [ [50, 60], [70, 80] ] ] # 3차원Numpy
numpy 에서 임의의 ndarray 를 만드는 방법
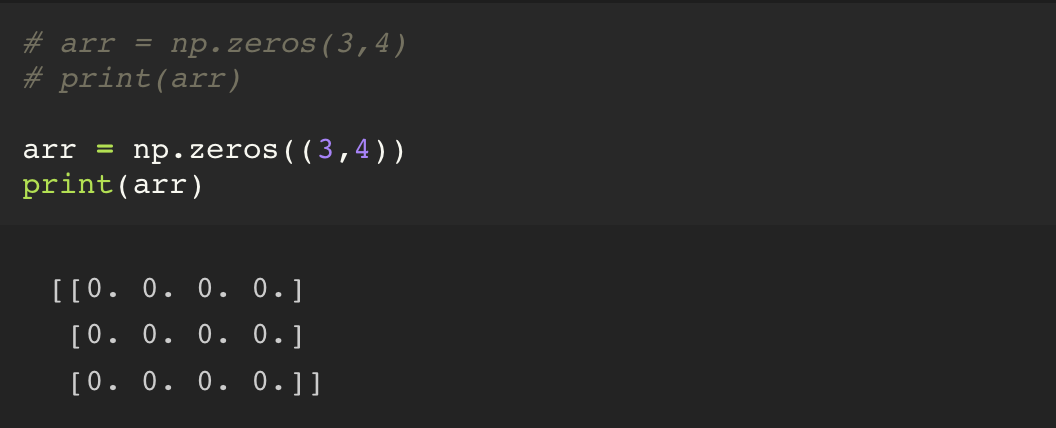
1. np.zeros( 튜플 )
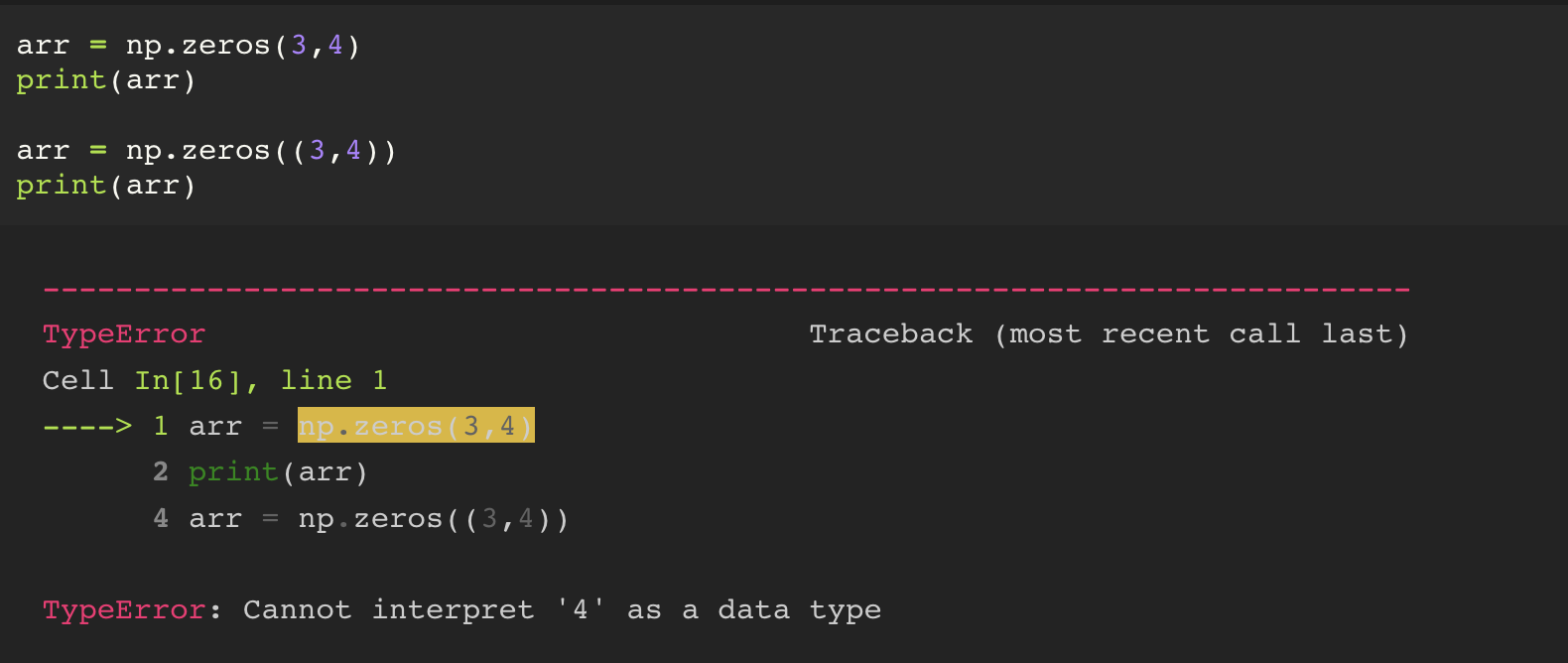
주의해야 할 점은, zeros 의 인자는 튜플 값이 들어가야 하기 때문에, (3,4) 괄호가 빠지게 될 경우 에러가 발생한다.
2. np.arange(start, end, step)
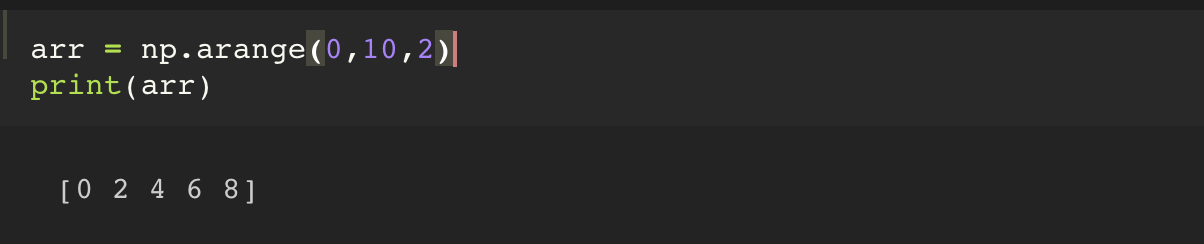
주의해야 할 건, python 의 range() 는 개념이라서, 실제 데이터를 메모리에 가지고 있지는 않는다. 하지만 numpy 의 arange() 는 실제 데이터를 메모리에 가지고 있다.
3. np.arange(12).reshape(reshape할 형태)
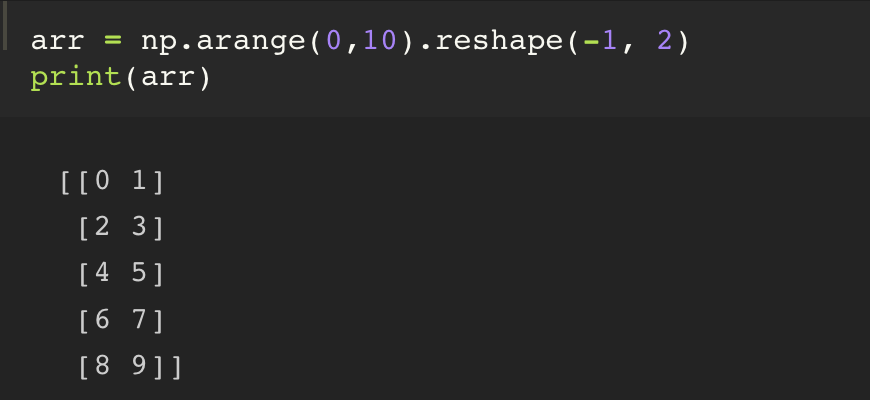
reshape의 인자에는 요소의 갯수와 일치하는 shape 의 형태로 값을 적어주면, 기존의 ndarray 혹은 list 의 차원을 변경시켜줄 수 있다.
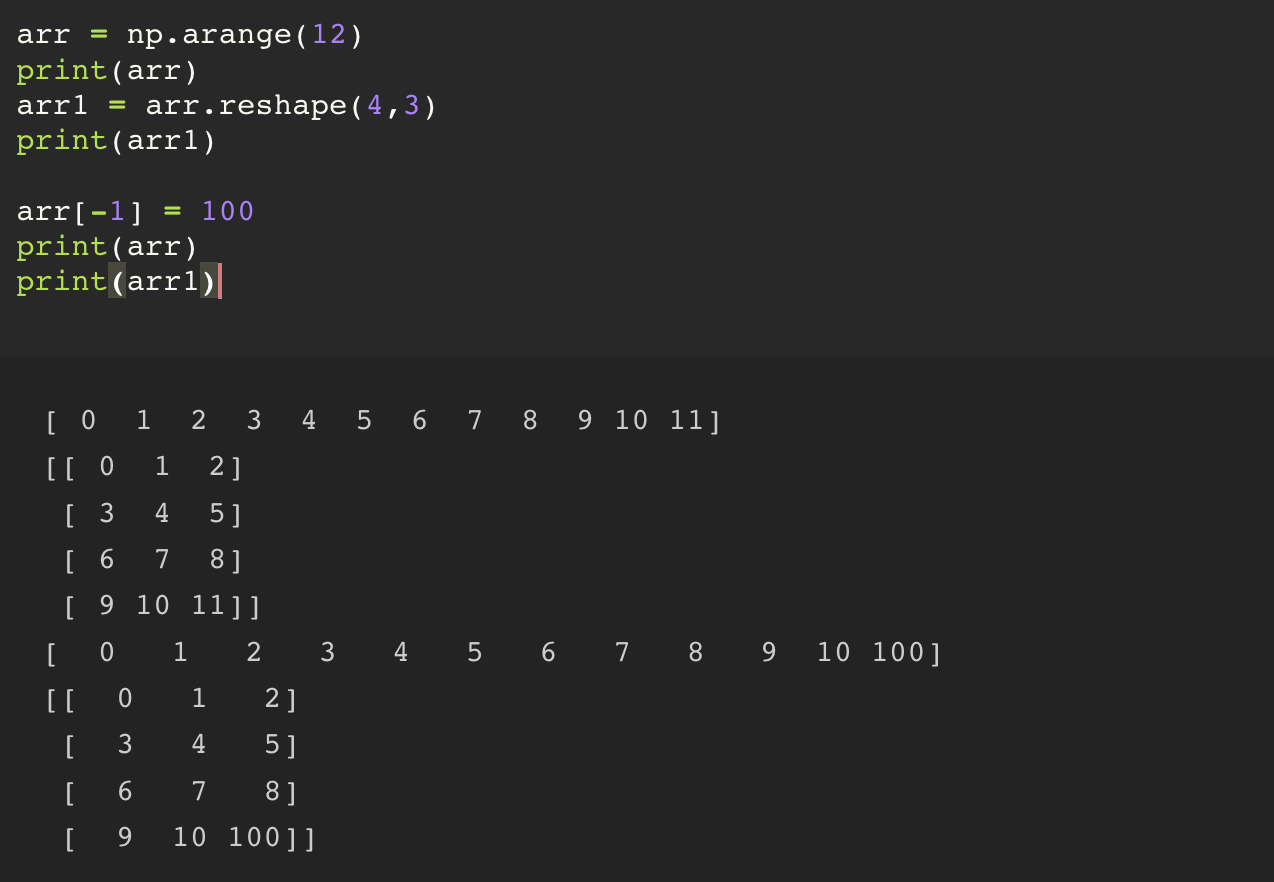
reshape 은 기존의 데이터를 복사해서 새로운 데이터를 만드는 것이 아니다. 기존의 데이터의 형태만 바꾸어서 표현을 해주는 것이다. 그렇기 때문에 기존의 데이터에서 값이 바뀌거나 혹은 reshape 한 데이터의 값이 바뀔 경우 원본 데이터의 값이 바뀌게 된다.
그렇기 때문에 reshape 를 하게 될 경우, view 가 만들어진다, 라는 개념이다.
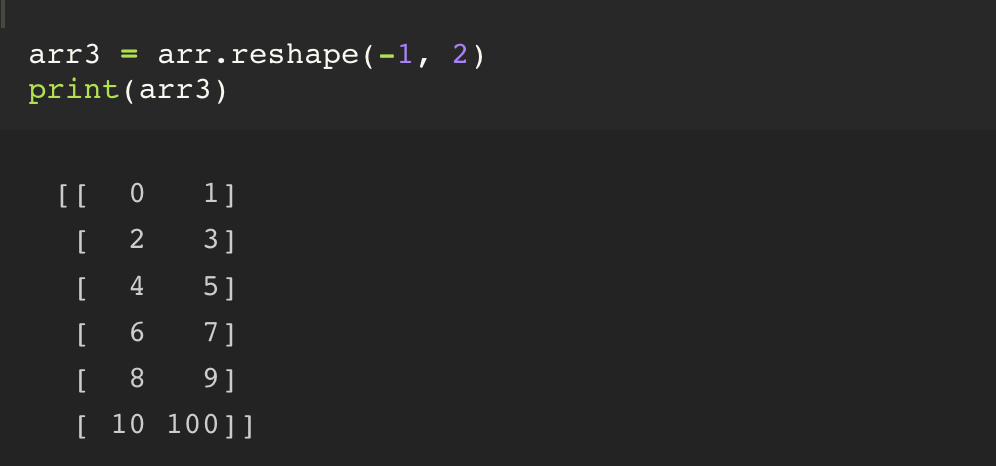
만약, reshape 의 인자 값으로 -1, 2 혹은 3, -1 과 같은 형태로 만들게 되면, 정수의 숫자로 입력된 행 or 열을 만든 뒤 그 것에 걸맞는 행 혹은 열을 만들게 된다.
즉 기존에 3,4 을 적는 다는 것은 3행-4열 로 reshape 를 하겠다는 의미였다면
-1,4 는 4열짜리를 만들고, 행은 가능한 만큼 모두 만들어주세요 라는 의미이다.
다만, -1 의 경우는 1개의 차원에만 적을 수 있다. 만약 3차원을 만드는데 (-1, -1, 3) 과 같은 형태로 적을 경우 에러가 발생한다.
4. np.random().randint(start, end, shape)
ndarray 를 만들 때, 난수를 이용해서 만들 수도 있다.
random 에는 randint() 를 사용해서 사용하고자 하는 난수의 값을 제한할 수 있다. 이 제한은 range 와 마찬가지로 start 는 inclusive, end 는 exclusive 해서 생성한다.
shape 는 tuple 형태로 쓰이기 때문에 괄호값이 필요하다.

다만, 랜덤이라고 해서 정말로 랜덤으로 생성되기보다는, seed 라는 key 를 값을 통해서 랜덤이 생성되게 된다. 따라서 seed 값을 통일할 경우 발생하게 되는 random 값이 예측할 수 있게 된다.

numpy 의 indexing과 slicing
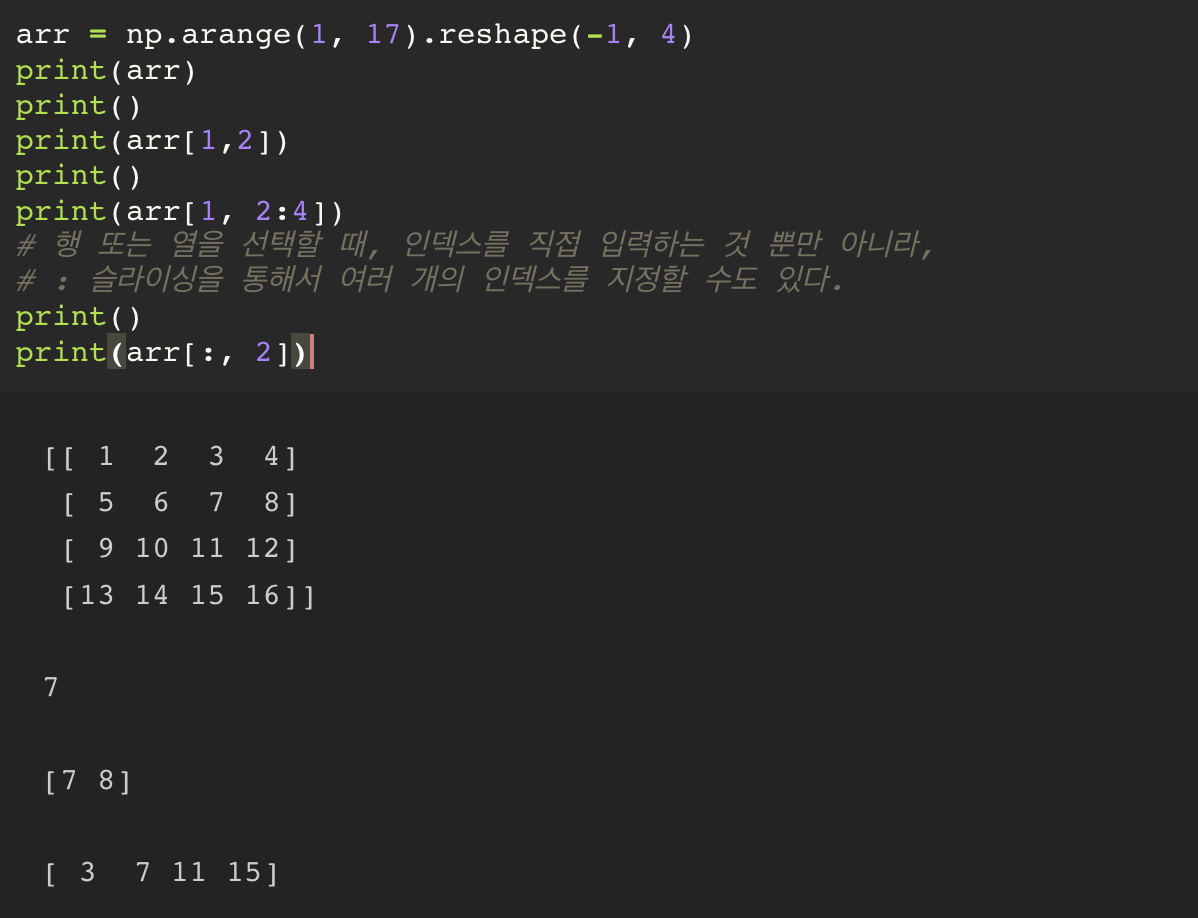
기본 indexing 과 slicing 은 python 과 동일하다. 그런데 numpy 에서 사용하는, 특이한 indexing 기법이 두 개가 더 존재한다.
1. Boolean Indexing
기본적으로 boolean mask 를 이용해서 indexing 하는 기법
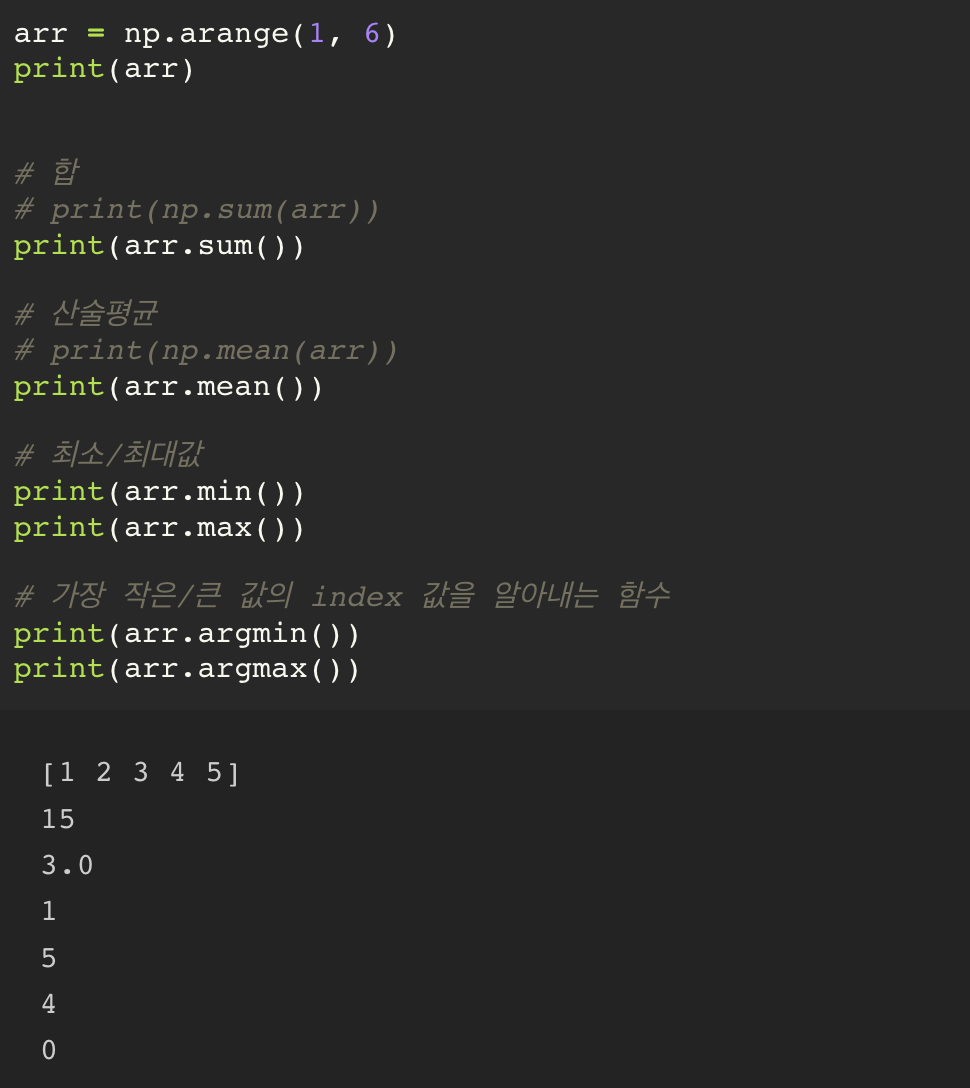
arr = np.arange(5)
print(arr)
# boolean mask : 내가 적용하는 ndarray 와 shape 이 같아야 하다.
boolean_mask = np.array([True, False, True, True, False])
print(arr[boolean_mask]) # [ 0 2 3 ]
true 위치에 있는 값들만 뽑아내는 방식
기존의 slicing 은 그 위치에 있는 index 값을 바탕으로 뽑아오는 방식.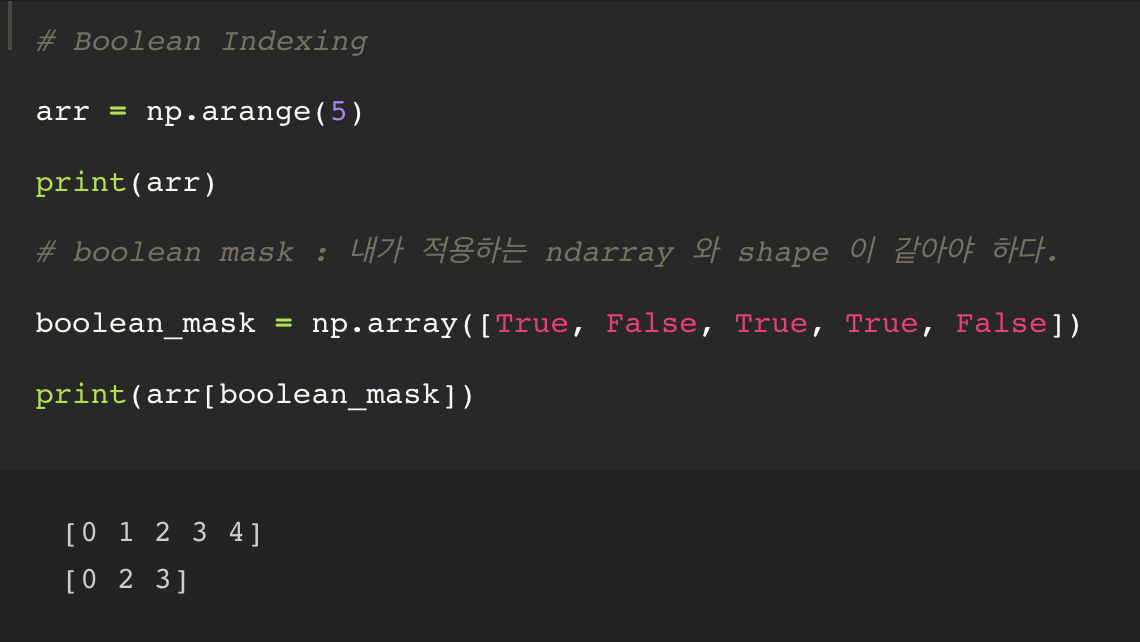
boolean mask 는 데이터 타입이 일치해야만 하고, 비교하려는 ndarray 의 shape 과 일치해야만 한다.
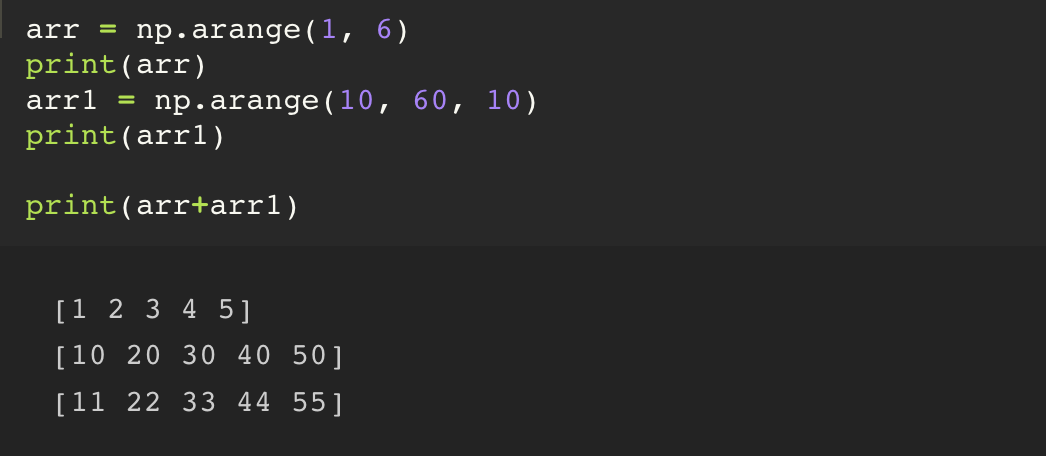
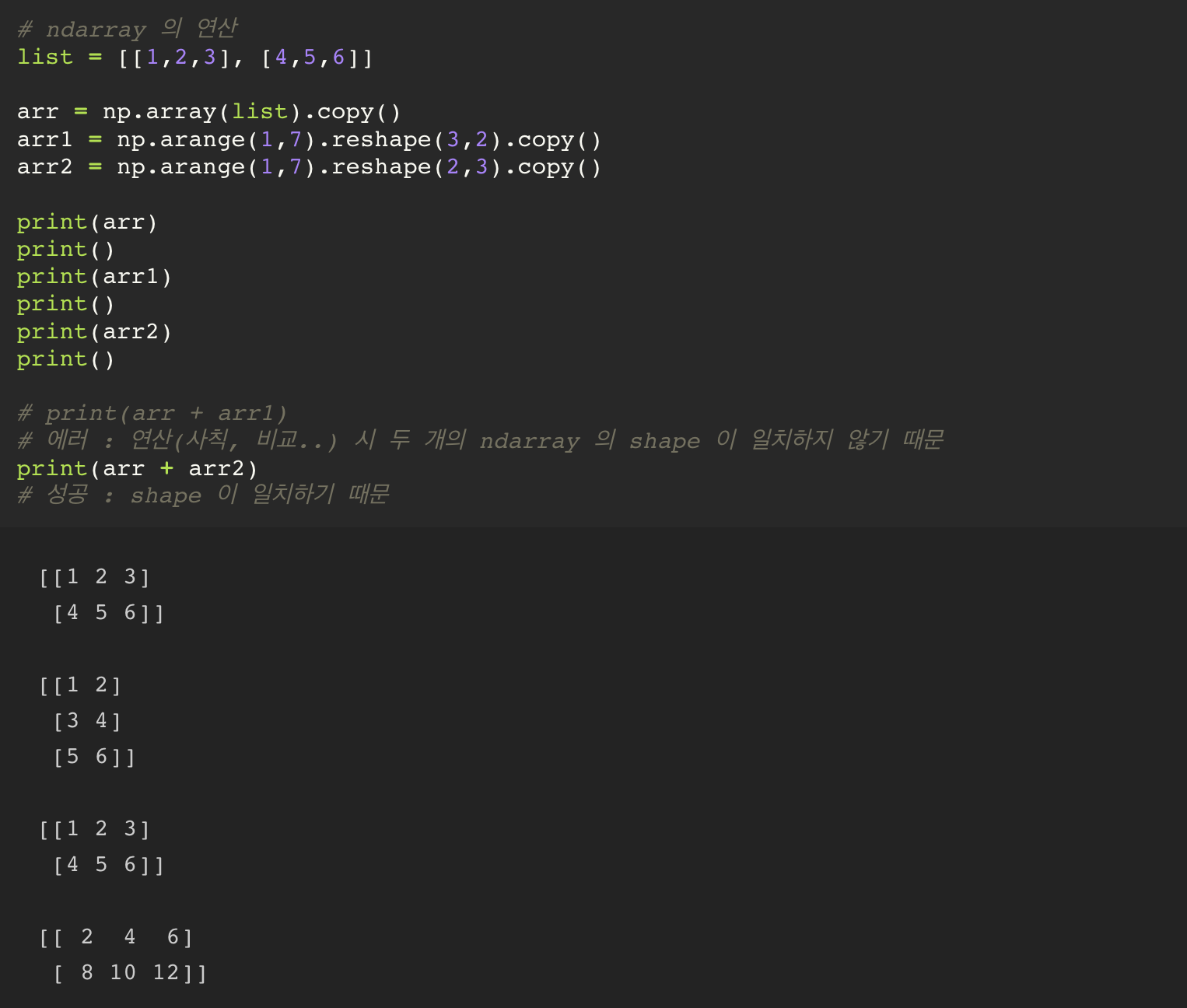
기존의 python 의 list 자료구조는 +, * 와 같은 연산을 하게 될 경우 concat 이 이루어졌다.
그런데 ndarray 의 경우에는 같은 위치에 있는 값들과 연산이 이루어진다.
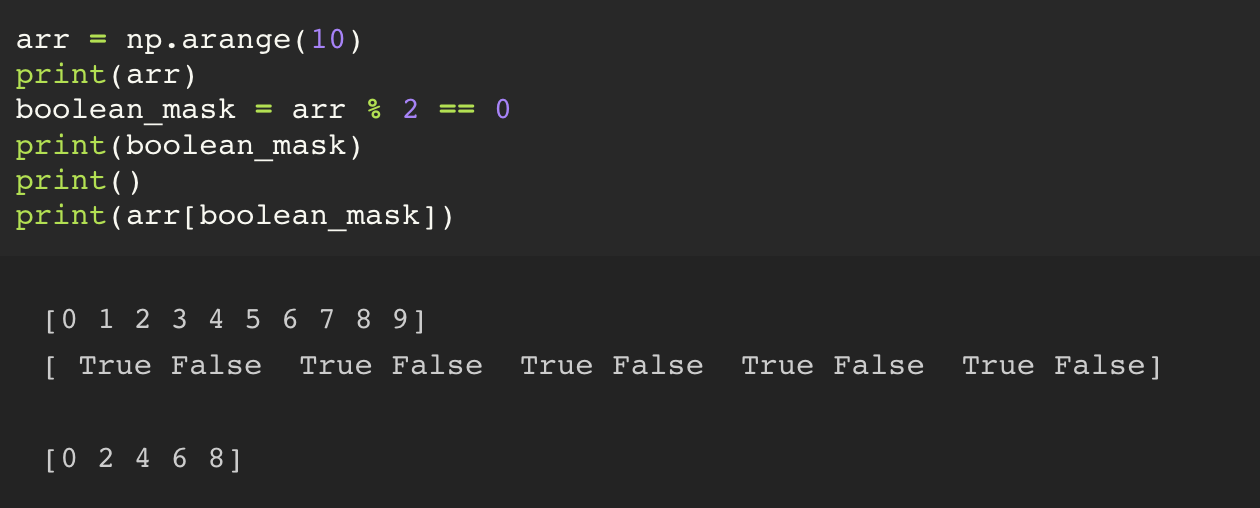
원본 arr 에서 모듈러 연산을 이용해서 0 과 1, 즉 홀수와 짝수를 찾고, 그 것을 활용해서 True/False 값을 가진 boolean_mask 를 만들어낸다.
그 후 만들어낸 boolean_mask 를 사용해서 boolean Indexing 을 사용해서 값을 추출한다.
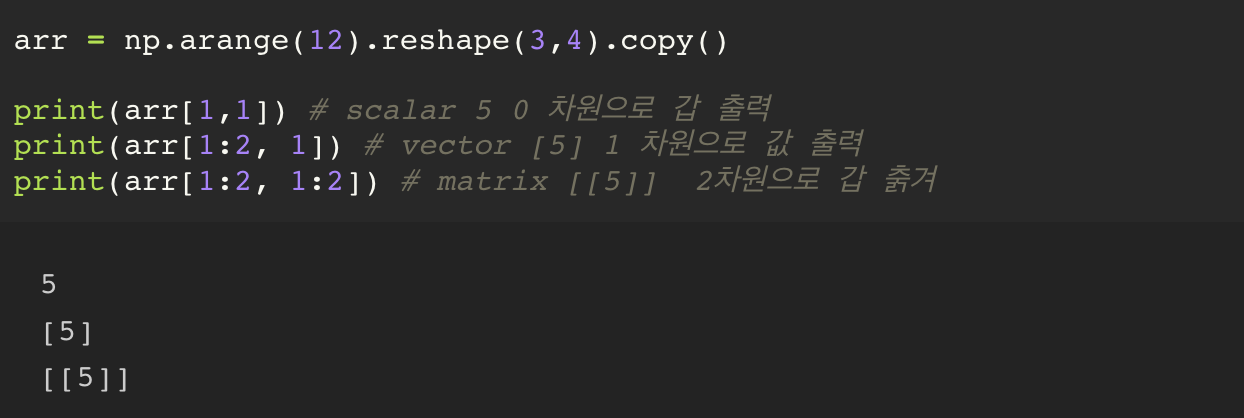
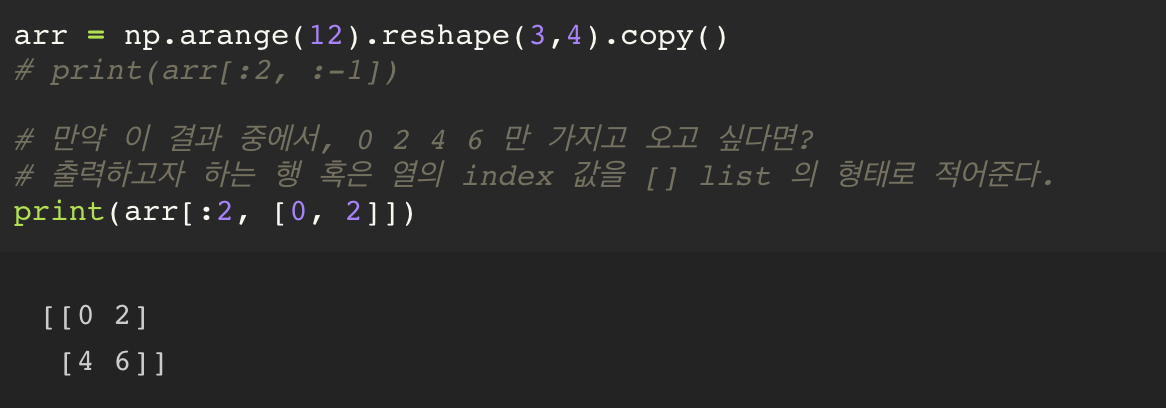
2. Fancy Indexing
행을 슬라이싱 하는 순간, 1개의 스칼라를 뽑는다고 하더라도, 그 형태를 1차원 으로 출력이 이루어진다.
EDA => 탐색적 데이터 분석
Numpy 의 연산
BroadCasting(브로드캐스팅)
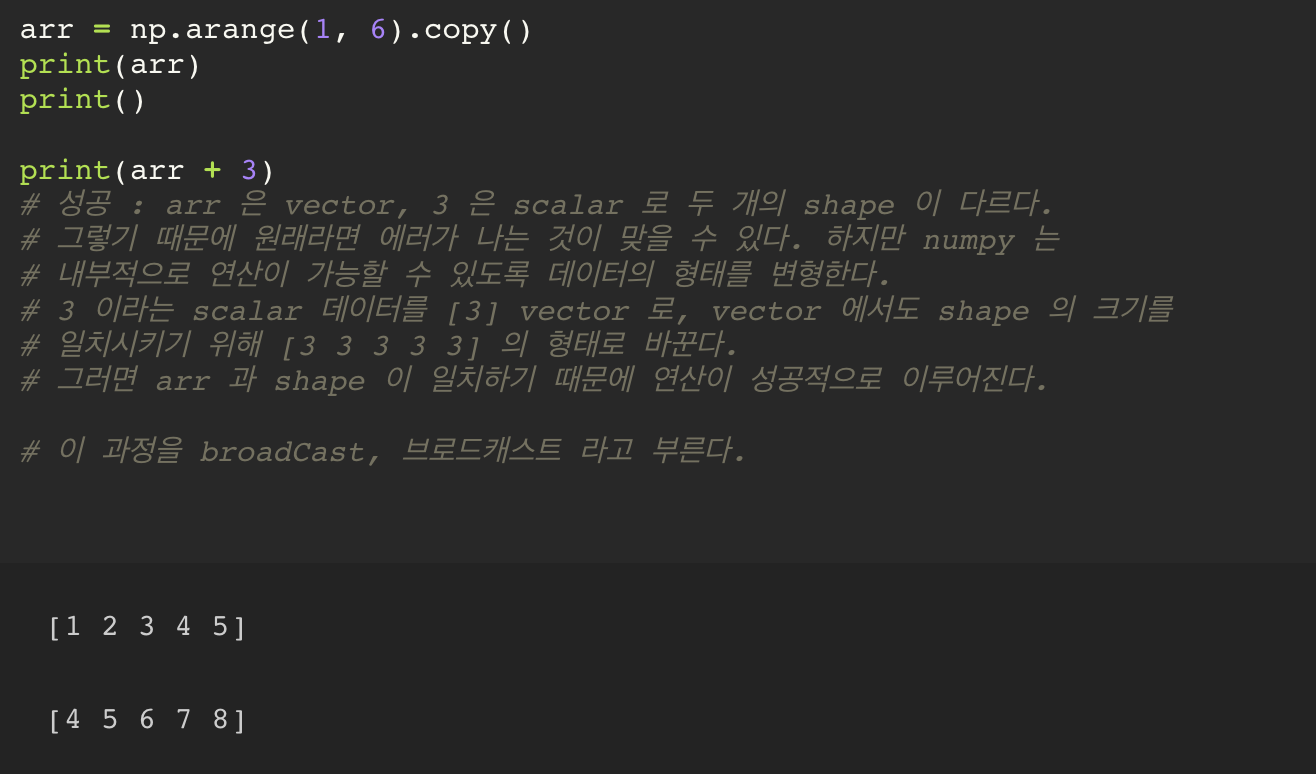
이러한 브로드캐스팅는 스칼라 형태가 가장 손쉽게 이루어지지만, 1차원 혹은 2차원이라 할 지라도, 그 원본의 데이터를 그대로 복사x복사.. 를 거듭해서 더하려는 데이터의 shape 과 형태가 일치시킬 수만 있다면 연산이 가능해진다.
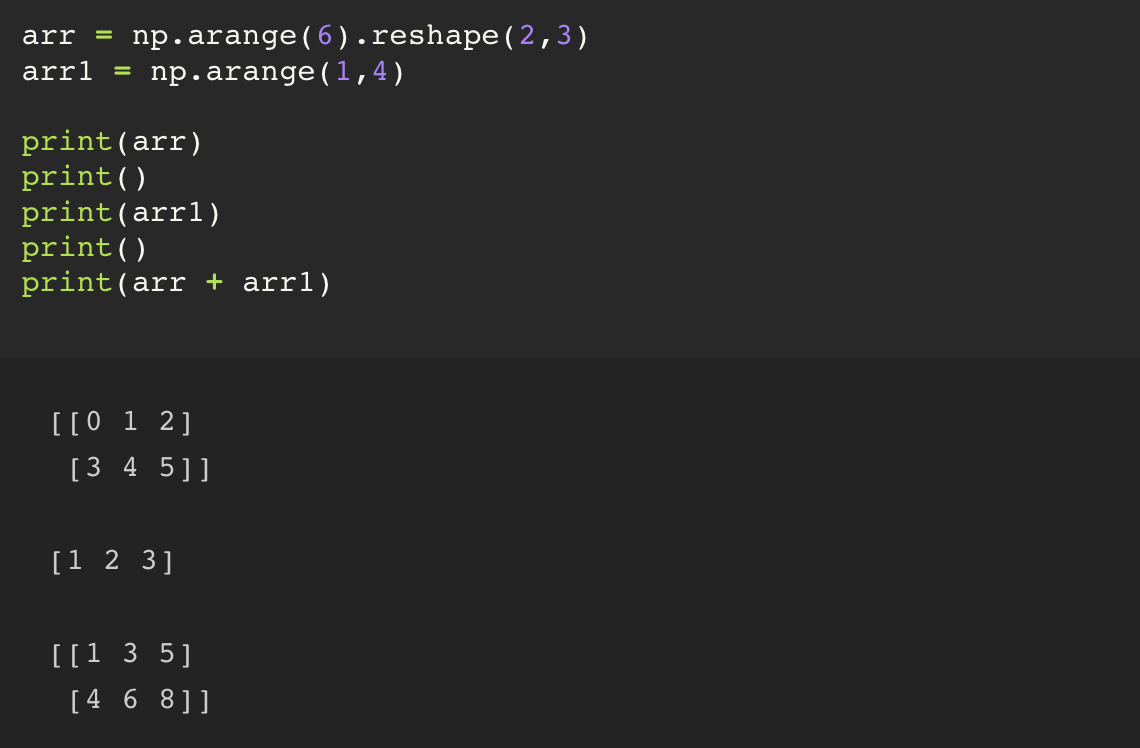
여기서는 arr1 은 [1 2 3] 이라는 1차원 ndarray 였는데, 더하려는 arr 는 2차원의 ndarray 였다.
그렇기 때문에 arr1 은 내부적으로 [[1 2 3] [1 2 3]] 이라는 2차원 ndarray 로 바뀐 뒤에 더하기가 이루어진다.
행렬의 연산
사칙연산(+,-,*,/) 과 비교연산(<,>,=) 이 가능해진다. 또한 행렬곱연산이 가능해진다.
행렬곱연산(Matrix Multiplication) -> `product` 로 간단하게 부른다. 행렬곱연산의 표현은 검정색 동그라미.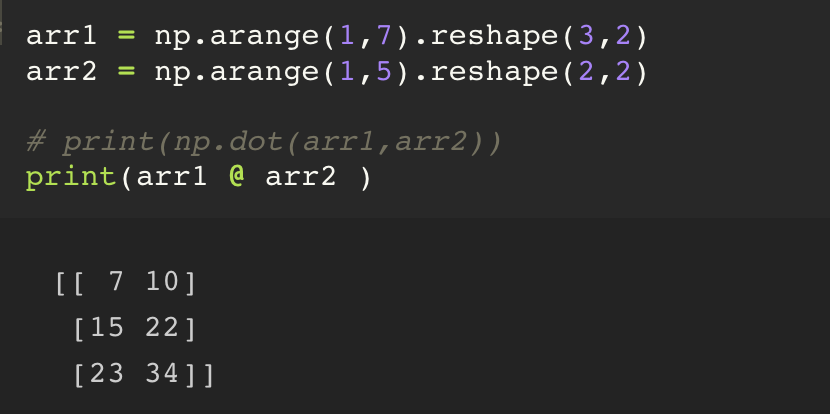
Numpy 에서는 행렬곱연산을 위한 함수를 제공하는데, 그 함수는 dot() 이다.
python 3.5 버전 이상부터는, @ 를 이용해서 행렬곱연산이 가능하다.
arr1 = np.arange(1,7).reshape(3,2)
arr2 = np.arange(1,5).reshape(2,2)
1. np.dot(arr1, arr2)
2. arr1.dot(arr2)
3. arr1 @ arr2집계함수
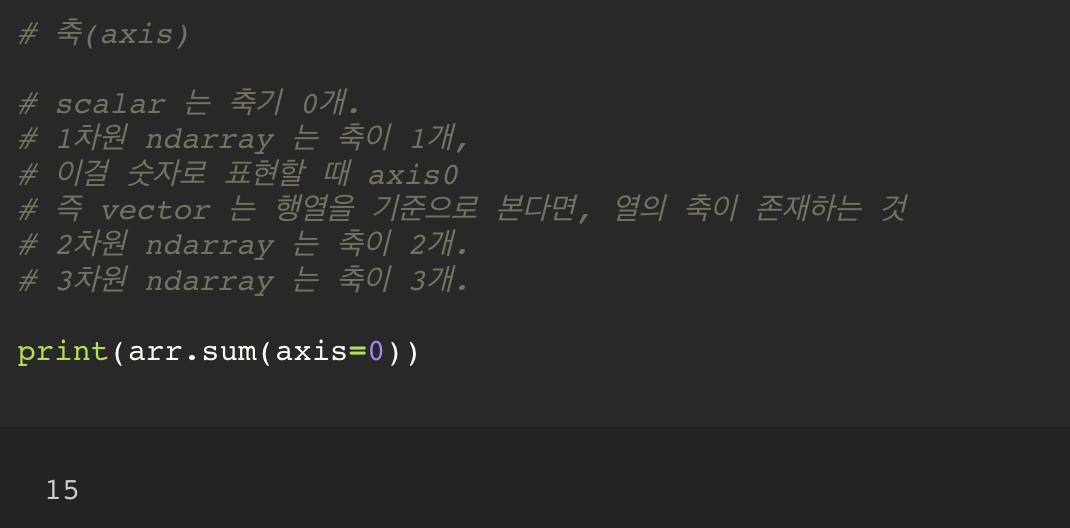
축(axis)
1차원의 경우에는 axis가 딱 1개 존재한다.
즉 차원의 개념이 올라갈수록, axis(축)이 증가하게 된다.
그리고 어느 축을 기준으로 두고 집계함수를 쓰는지 구별할 수 있게 된다.
특히 조심해야 하는 것은, 내가 어떤 차원을 사용하느냐에 따라서 축이 달라진다는 것을 명심해야만 한다.
1차원의 경우, 1가지 axis 를 사용한다.
axis0 는 열 방향을 기준으로 한다.
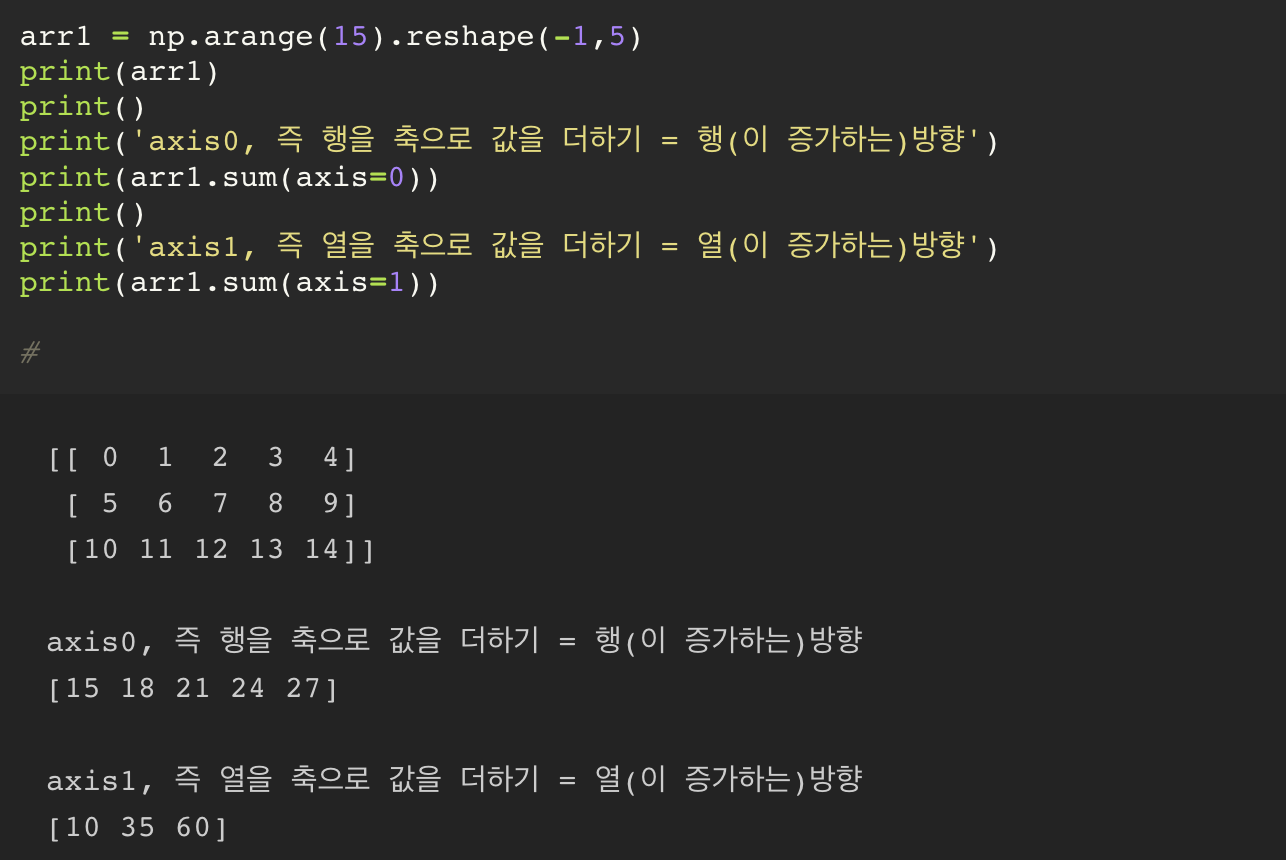
2차원의 경우, 2가지 axis 를 사용한다.
axis0 은 행 방향을 의미한다. 즉 1차원의 axis0 과는 의미가 달라진다.
axis1 은 열 방향을 의미한다. 즉 2차원의 axis1 은 1차원의 axis0 과 동일해진다.
예제
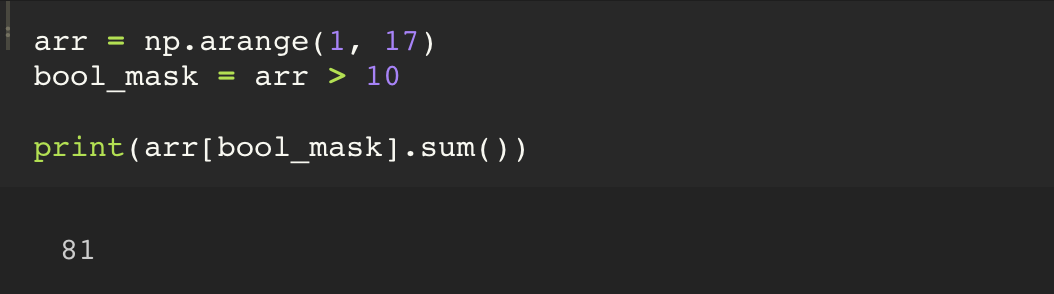
ndarray 에서 10보다 큰 값의 합을 구하세요.