
목표
특징 메트릭이 임계치를 넣을 때, 수평 확장이 자동으로 진행되게 하는 것이 바람직함Auto Scaling Group (ASG)의 원리를 파악하고 주요 메트릭의 임계치 달성 시점을 경보 형태로 제공해야 함이를 SNS 및 람다를 통해 구현한다.
최소 요구 사항
- EC2 서버를 ASG를 통해 구성
- CloudWatch 알람을 통해 ASG의 스케일 인/아웃 진행
- 스케일 인/아웃 진행 시 디스코드 알람 전송
- 메트릭을 바탕으로 장애 발생 예상 시점에 디스코드 알람 전송=> CPU 사용률 (CPUUtilization) 값이 특정 값 이상일 때 경보 발생
시작 템플릿 구성
- 그룹정보원하는 용량 : 1최소 용량 : 1최대 용량 : 1
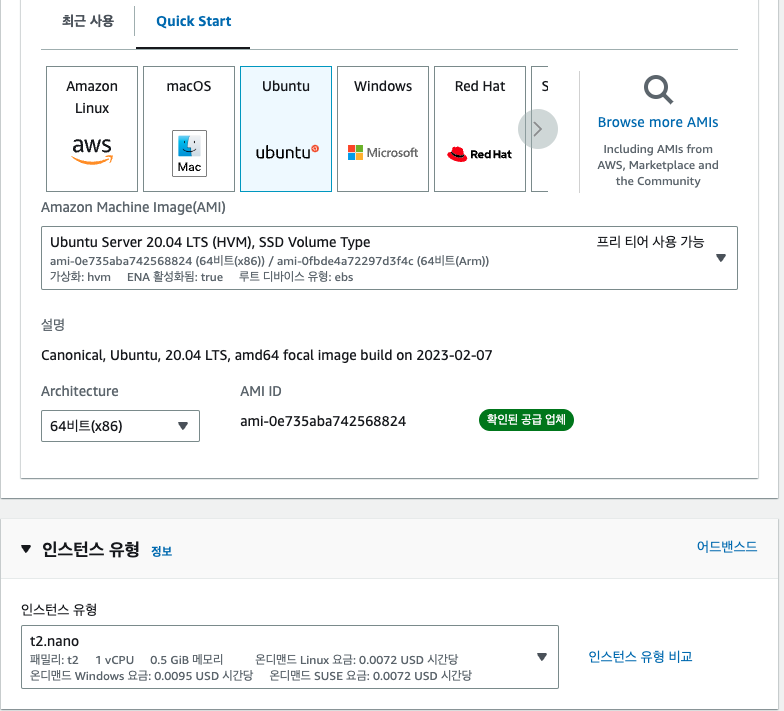
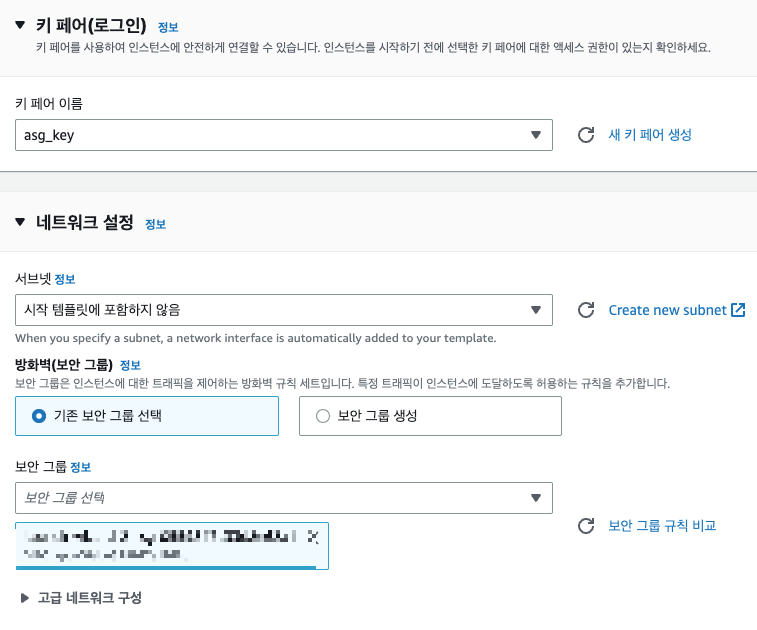
- 시작 템플릿 구성Ubuntu Server (LTS)t2.nano기존 혹은 신규 키 페어를 사용함보안그룹 : 인바운드 HTTP 및 SSH 허용사용자 데이터
#!/bin/bash
echo "Hello, World" > index.html
sudo apt update
sudo apt install stress
nohup busybox httpd -f -p 80 &CloudWatch와 조정 정책
- CloudWatch를 통한 Auto Scaling 그룹 지표 수집 활성화 필요
- Scale-in 조건 : CPU 40% 이하
- Scale-out 조건 : CPU 50% 이상
- (로드 밸런서 설정 X)
아키텍처 구성
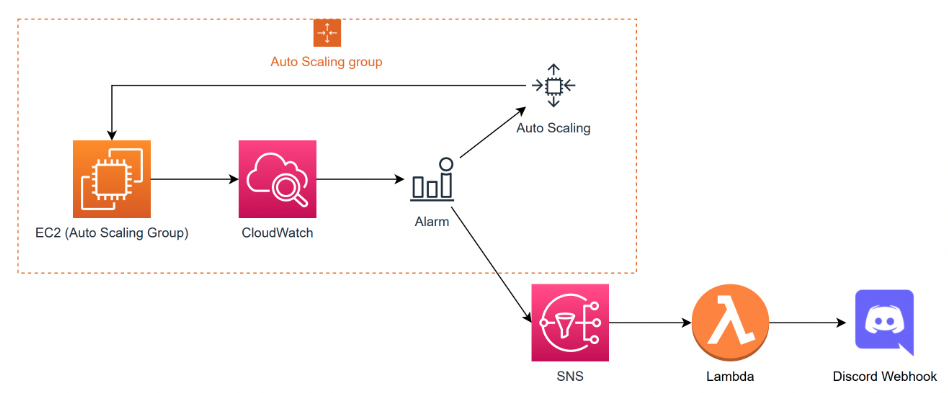
- 경보 생성 레퍼런스
CPU 사용량 경보 생성 - Amazon CloudWatch
- 제공받은 Lambda를 활용한 람다 함수 생성 (Python 3.x 버전)
부하 테스트
% stress -c 1// CPU 사용량 증가 - top 명령어를 통한 CPU 사용량 확인#1. Auto Scaling 그룹 생성
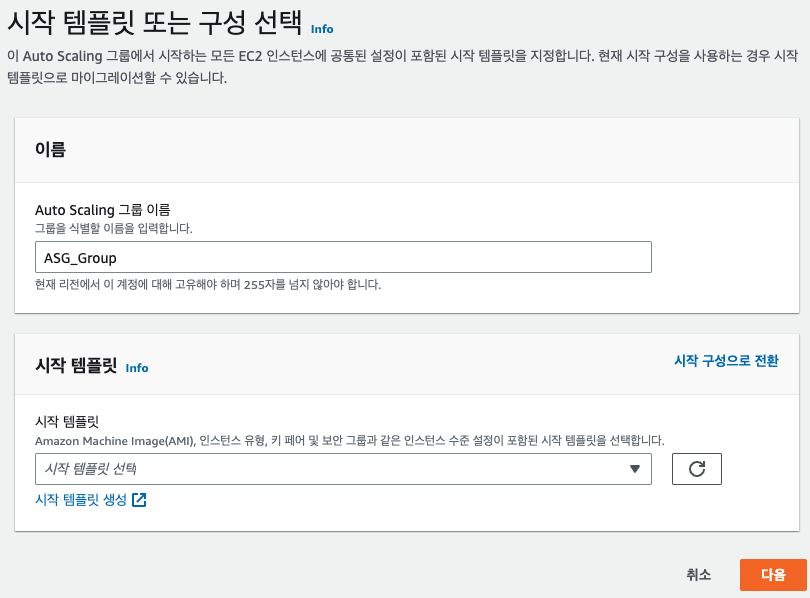
- 시작 템플릿 생성
=> ubuntu 20.04 LTS // t2.nano
- 키페어 및 보안그룹 선택 또는 생성
- 고급 세부 정보 -> 사용자 데이터 입력

- 이후 VPC & subnet 설정 + CloudWatch 그룹 지표 수집 활성화
- 그룹 크기 설정 및 생성 마무리

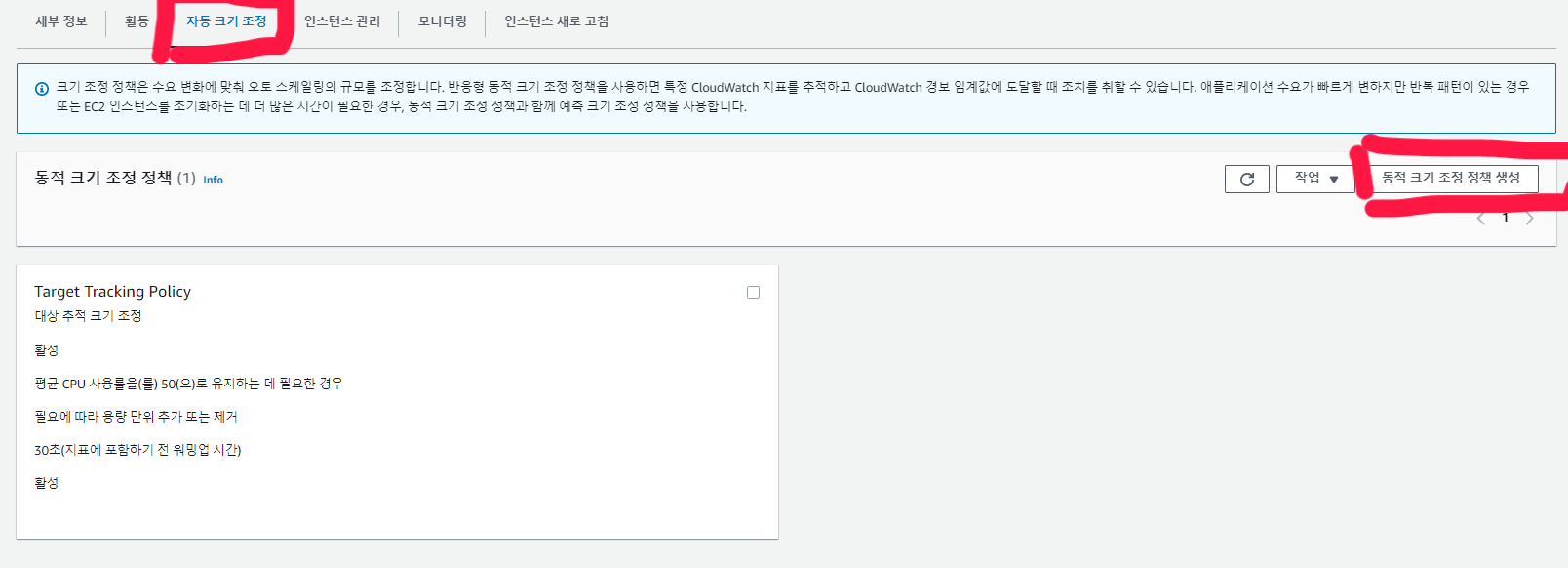
- 동적 크기 조정 정책 생성
#2. 람다 함수 생성
- python 3.x 확인

- 람다 코드 수정 및 배포
- 구성 -> 환경변수 추가
#3. SNS 생성 및 구독 생성 (람다)
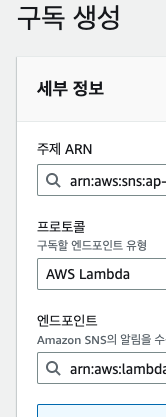
#4. CloudWatch 내 경보 생성
- 생성 -> 지표선택 -> EC2 -> 인스턴스별 지표
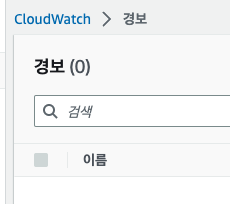
- EC2 찾기 + CPUUtilization 선택

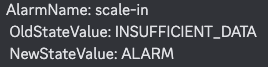
- sacle-out, scale-in으로 총 2개 생성
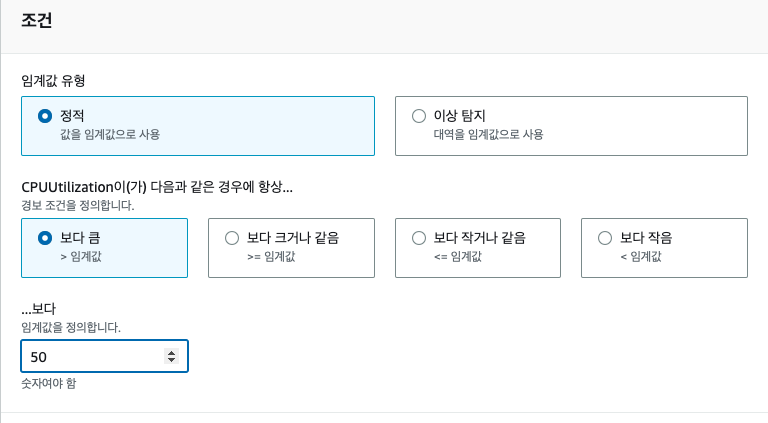
- SNS 연결
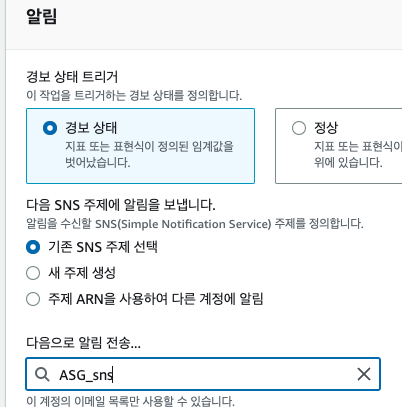
- Scale-out, Scale-in 생성

#5. EC2 접속 및 CPU 사용량 증가 시키기
$ stress -c 1- scale-out 확인 후 stress 명령어 종료
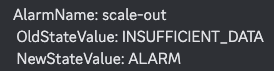
- scale-in 확인

기록하고 공유하려고 노력하는 DevOps 엔지니어