
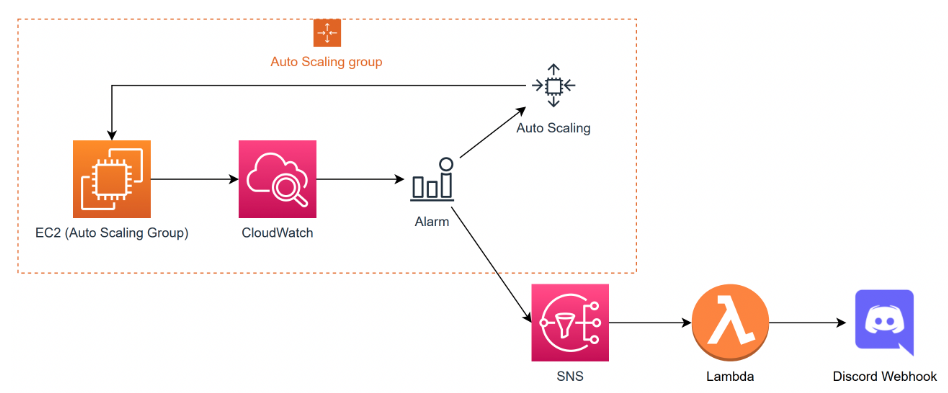
이전에 했던 CloudWatch와 autoscaling을 이용한 scale-out시에 알람이 울리고 sns를 이용해서 람다에 트리거를 부여해서 Discord Message를 남기는 실습이다.
main.tf
# Terraform AWS provider 설정
provider "aws" {
region = "ap-northeast-2" # 사용할 AWS 리전 설정
}
# 오토스케일링 그룹 정의
resource "aws_launch_configuration" "example" {
name = "example-launch-configuration"
image_id = "ami-0970cc54a3aa77466" # 사용할 AMI ID 입력
security_groups = [aws_security_group.instance.id]
instance_type = "t2.micro" # 인스턴스 유형
user_data = <<-EOF
#!/bin/bash
echo "Hello, World" > index.html
nohup busybox httpd -f -p 80 &
EOF
key_name = "sprintkey" # 사용할 키 페어 이름
}
# 오토스케일링 그룹 정의
resource "aws_autoscaling_group" "example" {
vpc_zone_identifier = [
aws_subnet.public_subnet_1a.id,
aws_subnet.public_subnet_2b.id
]
name = "example-asg"
max_size = 10 # 최대 인스턴스 수
min_size = 1 # 최소 인스턴스 수
desired_capacity = 2 # 초기 인스턴스 수
health_check_type = "EC2" # 인스턴스 상태 확인 유형
launch_configuration = aws_launch_configuration.example.name # Launch Configuration 연결
lifecycle {
create_before_destroy = true
}
}
# 오토스케일링 정책 정의
resource "aws_autoscaling_policy" "example" {
name = "example-policy"
autoscaling_group_name = aws_autoscaling_group.example.name
policy_type = "TargetTrackingScaling"
target_tracking_configuration {
predefined_metric_specification {
predefined_metric_type = "ASGAverageCPUUtilization"
}
target_value = 70.0
}
}
# CloudWatch Metric Alarm 정의
resource "aws_cloudwatch_metric_alarm" "example" {
alarm_name = "example-alarm"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 1
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = 60
statistic = "Average"
threshold = 70
alarm_description = "CPU utilization is greater than 70%"
alarm_actions = [aws_sns_topic.example.arn]
dimensions = {
AutoScalingGroupName = aws_autoscaling_group.example.name
}
}
# SNS Topic 정의
resource "aws_sns_topic" "example" {
name = "example-topic"
}
# SNS 구독 정의 (이메일 알림)
resource "aws_sns_topic_subscription" "example" {
topic_arn = aws_sns_topic.example.arn
protocol = "email"
endpoint = "hansungmoon1002@gmail.com" # 이메일 주소 입력
}- 이외에 사용할 VPC나 서브넷 라우트 테이블 보안그룹을 따로 작성해줘야한다.
마주쳤던 문제점
오토스케일링 정책 정의에서
resource "aws_autoscaling_policy" "example"으로 해야 했으나
resource "aws_appautoscaling_policy" "example"으로 공식문서를 찾아보고 코드들을 가져와서 사용했으나, 애초에 resource가 다르니 리소스안의 설정코드들이 계속해서 에러를 발생시켰다.
Error: creating Application Auto Scaling Policy (example-policy): ValidationException: 2 validation errors detected: Value 'autoscaling' at 'serviceNamespace' failed to satisfy constraint: Member must satisfy enum value set: [comprehend, rds, sagemaker, appstream, elasticmapreduce, dynamodb, lambda, ecs, cassandra, ec2, neptune, kafka, custom-resource, elasticache]; Value 'autoscaling:autoScalingGroup:DesiredCapacity' at 'scalableDimension' failed to satisfy constraint: Member must satisfy enum value set: [cassandra:table:ReadCapacityUnits, cassandra:table:WriteCapacityUnits, dynamodb:index:ReadCapacityUnits, dynamodb:index:WriteCapacityUnits, appstream:fleet:DesiredCapacity, comprehend:document-classifier-endpoint:DesiredInferenceUnits, ec2:spot-fleet-request:TargetCapacity, rds:cluster:ReadReplicaCount, elasticache:replication-group:Replicas, sagemaker:variant:DesiredProvisionedConcurrency, dynamodb:table:WriteCapacityUnits, kafka:broker-storage:VolumeSize, ecs:service:DesiredCount, sagemaker:variant:DesiredInstanceCount, comprehend:entity-recognizer-endpoint:DesiredInferenceUnits, dynamodb:table:ReadCapacityUnits, lambda:function:ProvisionedConcurrency, custom-resource:ResourceType:Property, neptune:cluster:ReadReplicaCount, elasticache:replication-group:NodeGroups, elasticmapreduce:instancegroup:InstanceCount]
│
│ with aws_appautoscaling_policy.example,
│ on main.tf line 55, in resource "aws_appautoscaling_policy" "example":
│ 55: resource "aws_appautoscaling_policy" "example" {aws scalable_dimension관련 자료
scalable_dimension을 설정해주는 코드에서 계속해서 같은오류가 발생했었으나 이후에 리소스를 바꿔서 코드를 수정해주니 에러가 더이상 발생하지 않았다.

기록하고 공유하려고 노력하는 DevOps 엔지니어