GPT와 BERT 간략 소개
Transformer
- Attention Is All You Need 논문에서 처음 제시된 모델입니다. (Link)
- 인코더 디코더 구조로 구성되어 있으며 병렬 처리가 가능해 기존 Recurrent 기반 모델보다 효율적입니다.
- 자연어 처리(NLP)에서 뛰어난 성능을 발휘하며 BERT, GPT등의 다양한 Transformer 기반 모델들이 개발되었습니다.
- 최근에는 멀티모달 모델로 확장되어 CLIP, DALL·E와 같은 모델을 통해 텍스트와 이미지 간의 상호작용을 처리하는 등 딥러닝의 판도를 크게 바꿨습니다.
아키텍처
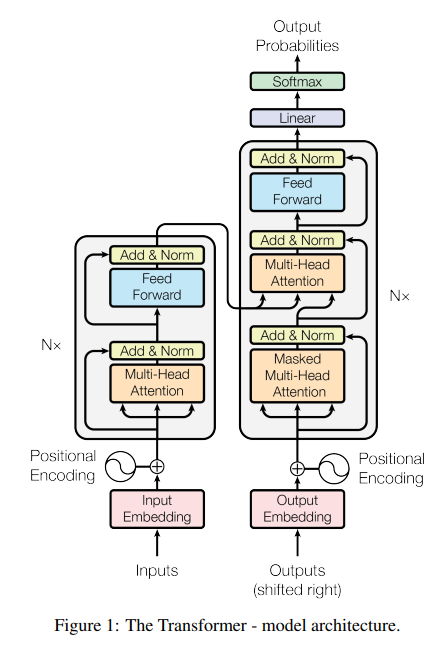
Encoder
1. 총 6개의 동일한 layer 구성되어 있습니다.
2. 각 layer 안에 multi-head self-attention mechanism으로 만든 layer와 단순한 position-wise fully connected feed forward layer 총 2개의 sub layer를 가집니다.
3. 각 sub layer에는 residual connection과 layer normalization을 사용합니다.
Decoder
1. 총 6개의 동일한 layer 구성되어 있습니다.
2. 각 layer 안에는 2개의 multi-head attention layer와 1개의 feed forward layer 총 3개의 sub layer를 가집니다.
3. encoder와 유사하게 residual connection과 layer normalization 사용합니다.
4. multi-head attention layer 중 하나는 encoder의 출력을 받아 multi-head attention을 수행하는 부분입니다. (= encoder-decoder attention layer)
5. self-attention을 수행하는 sub layer의 경우 masking을 적용해 해당 위치보다 미래의 정보는 참조하지 않도록 설계되었습니다.
Attention
Attention
- Attention은 query와 key-value 쌍을 통해 중요한 정보를 선택하는 mechanism입니다.
- query와 key의 유사도를 계산하여 value에 가중치를 부여하고 중요한 정보에 더 높은 비중을 둡니다.
👏 query : 현재 우리가 집중할 단어
👏 key : 모든 단어의 특징
👏 value : key에 해당하는 정보를 담고 있는 값
Self-Attention
- 동일한 시퀀스 내의 각기 다른 위치에 대해 Attention mechanism을 적용하여 문맥 정보를 추출합니다.
- Transformer 모델에서는 encoder-decoder attention layer와는 별개로 encoder와 decoder에 각각 self-attention layer를 포함합니다.
Multi-Head Attention
- Attention을 병렬로 여러 번 수행하게 해줍니다.
- 모델의 전체 차원 크기만큼 Attention을 한 번 적용하는 것보다 더 작은 차원에서 병렬로 여러 번의 Attention을 실행하고 결과값을 concatenate한 뒤 projection하는 것이 더욱 유리합니다.
- 각기 다른 representation subspaces로부터 다양한 정보를 가져와 결합할 수 있기 때문입니다.
- 조별과제를 하는 이유로 생각해보시면 좋습니다.
BERT vs GPT-1
BERT는 Transformer의 encoder 부분을 사용한 대표적인 Autoencoding model입니다.(Link)
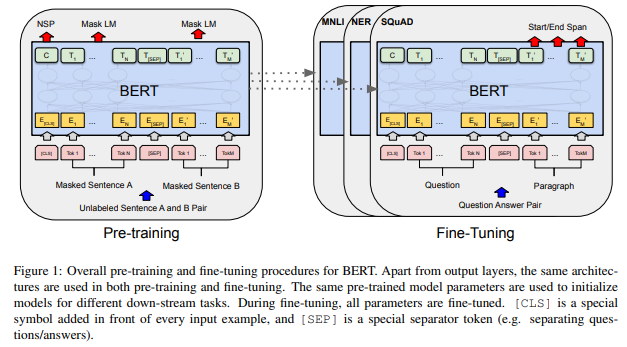
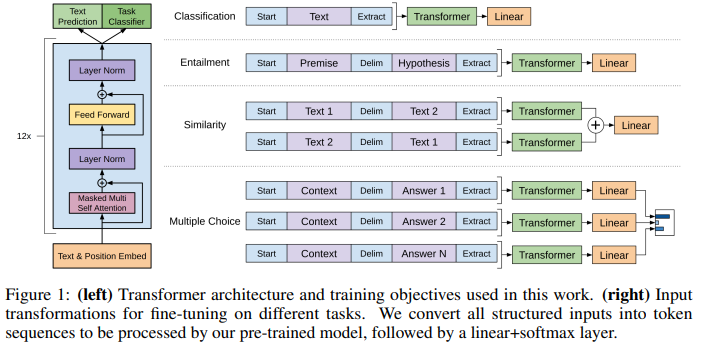
GPT-1은 Transformer의 decoder 부분을 사용한 대표적인 Autoregressive model입니다.(Link)
encoder 모델의 특징
- Self Attention
- Bi-Directional
양방향으로 문맥 정보를 모두 사용하여 단어의 의미를 더욱 깊게 이해합니다. - NLU(Natural Language Understanding)
단어 사이의 관계나 상호의존성을 이해하는 데 특화되었습니다. - Maksed Language Modeling
문장 내에서 특정 부분을 가리고 그 단어를 예측하는 방식으로 학습합니다. - 대표적인 활용 사례
- sequence classification
- question answering
- masked language modeling
decoder 모델의 특징
- Masked Self Attention
미래의 정보를 보지 않도록 마스킹을 적용합니다. - Unidirectional
왼쪽 방향의 문맥만 참고합니다. - NLG(Natural Language Generation)
자연어를 생성해내는 태스크에 특화되었습니다. - Causal Language Modeling
순서대로 텍스트를 읽고 다음에 나올 단어를 예측하는 사전학습 태스크에서 미래에 등장할 토큰은 가려놓습니다. - 대표적인 활용 사례
- text generation
- machine translation
- summarization
1. Architecture
BERT : Transformer의 Encoder를 베이스로 모델을 구성
→ Mask 단어와 두 문장간의 관계를 예측해야하는 BERT의 특성 때문입니다.
GPT-1 : Transformer의 Decoder를 베이스로 모델을 구성
→ 다음 단어를 예측해야하는 GPT-1의 특성 때문입니다.
2. 학습 방법
BERT :
1. MLM(Masked Language Model)
입력 텍스트 일부를 마스킹한 후 해당 부분을 예측하는 방식으로 학습합니다.
2. NSP(Next Sentence Prediction)
두 문장이 주어졌을 때 두 문장의 관계를 예측하는 방식으로 학습합니다.
GPT-1 :
1. NWP(Next Word Prediction)
주어진 문장의 다음에 나올 단어를 예측하는 방식으로 학습합니다.
3. 기능
BERT : 다양한 NLP Task에서 더 좋은 성능을 내도록 설계되어 GPT-1보다 대부분의 NLP문제에서 좋은 성능을 보입니다.
GPT-1 : 텍스트 생성 작업에 특화되었습니다.
4. 데이터 처리 방식
BERT : 양방향으로 데이터를 해석합니다.
GPT-1 : 단방향으로 데이터를 처리합니다.
