
이 글은 Tali Garsiel의 "How Browsers Work: Behind the scenes of modern web browsers"를 번역한 글입니다.
HTML Parser
HTML 파서는 HTML 마크업을 파스 트리로 변환하는 역할을 합니다.
The HTML grammar definition
HTML의 어휘와 구문 규칙은 W3C에 의해 정의되었습니다.
Not a context free grammar
전에 언급했던 바와 같이, 구문 규칙은 일반적으로 BNF와 같은 형식으로 정의할 수 있습니다..
하지만 불행하게도 HTML에는 전통적인 파서는 사용할 수 없습니다. HTML은 context free grammger (문맥 자유 문법)으로 정의할 수 없습니다.
HTML-DTD 형식으로 정의할 수 있지만, 이것은 context free grammger (문맥 자유 문법)이 아닙니다.
XML파서는 이미 많습니다. HTML이 XML과 유사하고, XHTML과 같이 HTML을 XML 형태로 재구성한 점을 생각하면 처음에는 이상하게 느껴질 것입니다.
차이점은 HTML이 더욱 유연하다 라는 것입니다. HTML은 태그를 생략할 수 있습니다. 결론적으로 XML이 까다로운 문법을 가지고 있다면, HTML은 유연한 문법을 가지고 있습니다.
이러한 작은 차이가 큰 차이를 만들어 냅니다. HTML은 유연함 덕분에 XML보다 유명해졌지만, 공식적인 문법을 만들기는 어려워졌습니다. 결론적으로, HTML은 context free grammger (문맥 자유 문법) 이 아니기 때문에, XML 파서와 같은 전통적인 파서로 파싱할 수 없습니다.
HTML DTD
HTML은 DTD 형식으로 정의됩니다. DTD 형식은 SGML 계열의 언어를 정의하는 데 사용합니다. 이 형식은 사용할 수 있는 요소와 그들의 속성 그리고 중첩구조에 대한 정의를 포함합니다. 위에서 언급했듯이, HTML DTD는 context free grammger (문맥 자유 문법)이 아닙니다.
DTD에는 다양한 버전이 있습니다. 일반적으로 예전 브라우저의 마크업도 지원하지만, strict mode는 명세의 내용만 지원합니다. 예전 마크업도 지원하는 이유는 하위 호환성 때문입니다.
DOM
"파스 트리"는 DOM element와 속성 노드로 이루어진 트리입니다. DOM은 Document Object Model의 줄임말로, HTML 문서를 객체화한 것뿐만 아니라, JavaScript 같은 외부와 HTML 요소의 인터페이스 역할을 합니다. 파스 트리의 루트는 Document 객체입니다.
일반적으로 DOM과 마크업은 일대일로 대응합니다. 예를 들어,
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>위와 같은 마크업은 아래의 DOM 트리로 파싱됩니다.
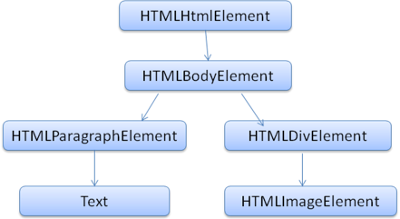
HTML과 마찬가지로, DOM의 명세는 W3C에서 정의합니다. 이것은 문서를 다루기 위한 일반적인 명세이며, 특정한 HTML 요소에 대한 설명도 포함합니다. HTML의 정의는 여기에서 확인 가능합니다.
DOM 인터페이스를 구현한 요소들로 이루어진 트리를 DOM 트리라고 부릅니다. 브라우저는 내부적으로 사용되는 자신만의 속성이 추가된 concrete implementation을 사용합니다.
The parsing algorithm
아래와 같은 이유로 HTML은 일반적인 Top down parser나 Bottom up parser로는 파싱할 수 없습니다.
1. 언어의 유연함
2. 잘 알려진 HTML 오류에 대한 브라우저의 관용
3. 변경에 의한 재파싱. HTML은 다른 언어와 다르게, document.write()와 같은 스크립트로 인해 토큰을 추가할 수 있습니다. 다시 말하면, 파싱이 인풋을 수정가능하다는 것입니다.
일반적인 파싱 기술을 사용할 수 없기 때문에, 브라우저는 HTML을 파싱하기 위해서 파서를 만들었습니다.
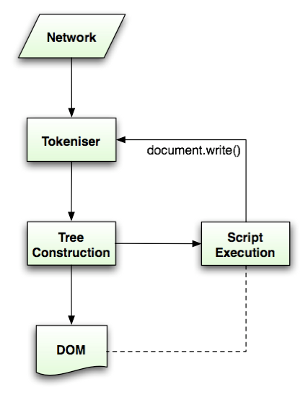
파싱 알고리즘은 HTML 5 명세에 자세히 설명되어 잇습니다. 파싱 알고리즘은 아래의 두 단계로 구성되어 있습니다.
1. Tokenization (토큰화)
2. Tree construction (트리 생성)
토큰화는 어휘 분석으로, 인풋을 토큰으로 파싱하는 과정입니다. HTML 토큰에는 시작 태그, 종료 태그, 속성 이름과 속성 값이 있습니다.
Tokenizer는 인식한 토큰을 트리 생성자에 전달하고 다음 토큰을 찾기 위해 다음 문자를 확인합니다. 이 과정은 인풋의 끝까지 반복합니다.
The tokenization algorithm
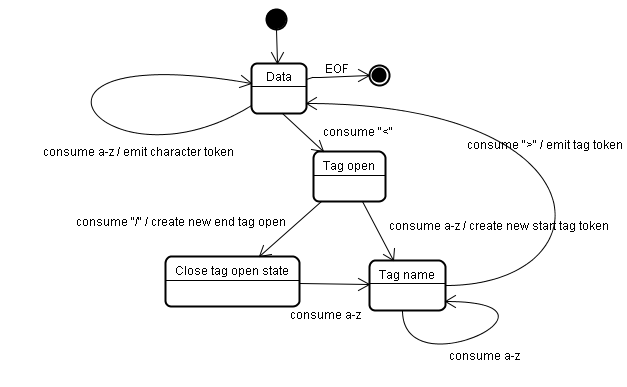
토큰화 알고리즘의 아웃풋은 HTML 토큰이다. 이 알고리즘은 State Machine 으로 표현할 수 있습니다. 각 state는 하나 이상의 문자를 입력받아 이에 따라 다음 state를 업데이트합니다. 토큰화 state와 트리 생성자의 state에 따라 다음 state가 결정됩니다. 다시 말해서, 인풋이 같더라도 현재의 state에 따라 다음 state는 달라질 수 있다는 것입니다. 자세히 설명하기엔 너무 복잡한 알고리즘으로, 원리를 이해할 수 있는 간단한 예시를 살펴보겠습니다.
아래의 HTML을 토큰화한다고 가정합시다.
<html>
<body>
Hello world
</body>
</html>초기 state는 Data state 입니다. '<' 를 만나면, state는 Tab open state 가 됩니다. 이 때, a-z 사이의 문자를 만나면 "시작 태그 토큰" 을 생성하고, Tag name state 가 됩니다. '>' 를 만나기 전까지는 state에 변화 없이 새로 생성된 토큰에 추가됩니다. 이 상황에는 "html" 토큰이 생성됩니다. '>' 를 만나면, 현재 토큰을 발행하고, 다시 Data state 로 돌아옵니다. body 태그도 동일한 과정을 거칩니다.
<html> 태그와 <body> 태그를 모두 토큰화하면, Data state 입니다. "Hello world" 의 'H' 는 "문자 토큰" 을 생성하고 발행합니다. 이 과정은 </body> 태그의 '/' 를 만날 때까지 반복되어, "Hello world"의 모든 문자를 "문자 토큰"으로 발행합니다.
이제 Tag open state 입니다. '/' 를 만나 "종료 태그 토큰" 을 생성하고, Tag name state 가 됩니다. 다시 한 번, '>' 를 만날 때가지 현 state에 머뭅니다. '>' 를 만나면, 새로운 토큰을 발행하고, Data state 가 됩니다. </html> 태그도 설명드린 바와 같이 동작할 것 입니다.
Tree construction algorithm
파서가 생성되면서 Doucment object가 생성됩니다. 트리 생성 단계에서, 문서를 루트로 하는 DOM 트리는 수정되고, 요소가 추가됩니다. Tokenizer에 의해 생성된 노드는 트리 생성자를 거칠 것입니다. 각 토큰의 명세는 어떤 DOM 요소와 관계가 있고, 생성될 것인지를 나타냅니다. 요소는 DOM 트리에 추가되거나, open elements stack 에 추가됩니다. 이 스택은 부정확한 중첩이나 미종료 태그를 수정합니다. 이 알고리즘도 State machine 으로 표현됩니다. states 는 insertion modes 라고 부릅니다.
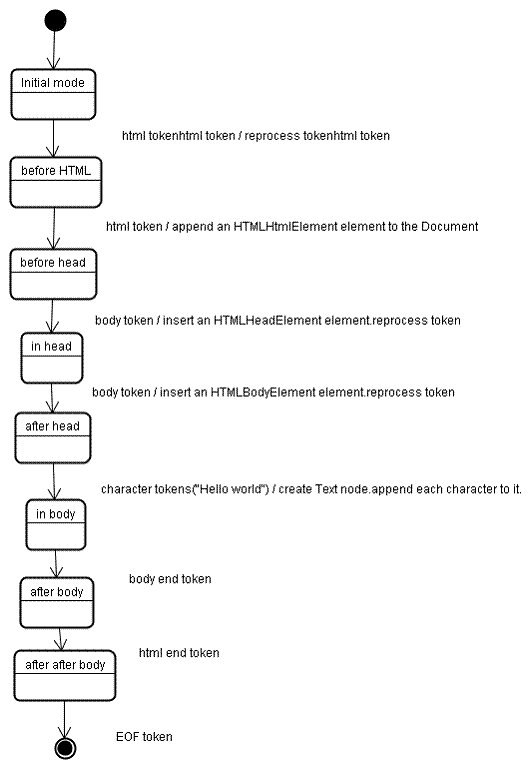
아래의 HTML의 트리 생성 과정을 살펴 보겠습니다.
<html>
<body>
Hello world
</body>
</html>트리 생성 단계의 인풋은 토큰화 단계에서 발생한 토큰입니다. 시작 단계는 initial mode 입니다. "html 토큰" 을 받아 before html 이 되고, "html 토큰" 을 처리합니다. 이 과정은 HTMLHtmlElement 를 만들고 Document object의 루트에 추가됩니다.
state는 before head 가 됩니다. "body 토큰" 을 전달받습니다. 이 때, "head 토큰" 이 없더라도 HTMLHeadElement가 생성되어 트리에 추가됩니다. 그리고, in head 와 after head 로 순차적으로 state가 바뀝니다.
이제, "body 토큰" 을 처리하여 HTMLBodyElement 를 생성하여 트리에 추가하고, in body 가 됩니다.
"Hello world"의 "character 토큰들" 을 전달 받습니다. 첫 토큰은 Text node 를 생성하여 트리에 추가하고, 나머지는 노드에 추가됩니다.
"body end 토큰" 을 전달 받아 after body state 가 됩니다. 이제, "html end 토큰" 에 의해 after after body state가 될 것 입니다. 마지막으로, "end of file 토큰" 을 받아 파싱이 종료됩니다.
Actions whne the parsing is finished
파싱이 완료되면, 문서와 상호작용이 가능해지고, 문서가 파싱된 이후에 실행 되어야 하는 deferred 스크립트 태그를 파싱하기 시작합니다. 문서는 complete state가 되고, load 이벤트가 발생합니다.
토큰화와 트리 생성과 관련된 상세한 알고리즘은 여기서 확인 가능합니다.
Browsers' error tolerance
HTML 페이지에서 "Invalid Syntax" 라는 에러는 본 적이 없을 것입니다. 브라우저에서 오류난 부분을 고치기 때문입니다.
아래의 HTML이 있다고 가정합시다.
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>존재하지 않는 "mytag" 사용, "p" 태그와 "div" 태그의 잘못된 중첩관계와 같은 다양한 오류가 있는 HTML 문서입니다. 그러나, 브라우저는 이를 올바르게 표시합니다. 그 이유는 파서가 실수를 교정해주기 때문입니다.
브라우저가 에러를 핸들링하는 방식은 예전부터 일반적이었지만, HTML 명세에는 포함되지 않습니다. 북마킹이나, 이전/다음 버튼처럼 몇 년간 브라우저 내부에서 개발된 것입니다. 많은 사이트에서 반복되는 HTML 오류들이 있는데, 브라우저는 다른 브라우저들이 했던 것처럼 이를 수정합니다.
HTML5 명세에는 이와 관련된 몇 가지 요구사항을 정의합니다.
아래는 Webkit 에서 HTML 파서 클래스의 시작부분에 이와 관련해서 주석으로 남긴 부분입니다.
파서는 문서를 파싱하여 토큰화하고, DOM 트리를 생성합니다. 문서에 오류가 없다면, 파싱은 수월하게 진행됩니다.
불행하게도, 우리는 오류가 있는 HTML 문서를 다뤄야 하기 때문에, 파서는 에러에 대해 유연하게 처리해야 합니다.
우리는 적어도 아래에 적힌 오류는 처리해야 합니다.
- 태그 내부에 추가하려는 태그가 금지된 태그일 때, 추가하려는 태그가 허용될 때까지 외부 태그를 닫고 태그를 추가합니다.
- 문서 제작자가 실수로 생략한 태그를 추가하는 경우 외에는 파서가 태그를 추가하면 안 됩니다. HTML, HEAD, BODY, TBODY, TR, TD, LI 가 이 케이스에 속합니다.
- 인라인 태그 안에 블록 태그를 추가하려는 경우, 블록 태그가 나올 때까지 인라인 태그를 닫습니다.
- 위의 방법이 도움이 되지 않는다면, 태그를 추가할 수 있거나, 무시할 수 있을 때까지 모든 태그를 닫습니다.
Webkit이 오류를 처리하는 몇 가지 경우를 살펴보겠습니다.
</br> insted of <br>
몇몇 사이트는 <br> 대신 </br> 을 사용합니다. Firefox와 호환성을 위해 Webkit에서는 이를 <br> 으로 처리합니다.
처리 과정:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}에러는 내부적으로 처리하고, 사용자에게 알리지 않습니다.
A stray table
Stray table은 아래와 같이 테이블 안에 테이블이 th나 td 외부에 있는 경우를 의미합니다.
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>Webkit은 아래와 같이 두 개의 형제 테이블로 중첩 구조를 바꿀 것입니다.
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>처리 과정:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);Webkit은 현재 요소의 내용을 처리할 때 스택을 사용합니다. outer table의 스택에서 inner table을 pop하면 두 테이블은 형제가 됩니다.
Nested form elements
사용자가 form 안에 form 을 추가하는 경우, 두 번째 form은 무시합니다.
처리 과정
if (!m_currentFormElement)
m_currentFormElement = new HTMLFormElement(formTag, m_document);
A too depp tag hierarchy
주석에는 아래와 같이 적혀있습니다.
www.liceo.edu.mx 는 1500개의 <b> 태그가 중첩된 사이트입니다. 우리는 같은 태그의 중첩을 최대 20개까지 허용하고, 나머지는 무시합니다.
처리 과정
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}Misplace html or body end tags
주석에는 아래와 같이 적혀 있습니다.
몇몇의 멍청한 페이지는 실제 문서가 끝나기 전에 body 태그를 닫기 때문에 우리는 body 태그를 절대로 닫지 않습니다. 대신 종료를 하기 위해 end() 를 호출합니다.
처리 과정
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;참고 자료
How Browsers Work: Behind the scenes of modern web browsers
브라우저는 어떻게 동작하는가?
