이 글은 Tali Garsiel의 "How Browsers Work: Behind the scenes of modern web browsers"를 번역한 글입니다.
Parsing-genenral
파싱한다는 것은 문서를 코드가 읽을 수 있는 구조로 변환하는 것을 의미합니다. 파싱의 결과는 대부분 문서 구조를 나타내는 노드로 이루어진 트리입니다. 이 트리는 parse tree 혹은 syntax tree라고 불립니다.
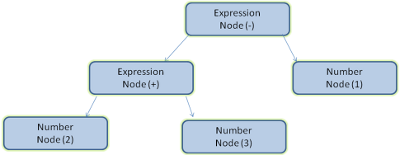
예를 들어, 2 + 3- 1 이라는 식을 파싱하면 아래와 같은 트리가 나옵니다.
Grammers
파싱은 문서가 따르는 구문 규칙(문서에 쓰인 언어나 형식)을 기반으로 진행합니다. 파싱할 수 있는 형식은 정해진 어휘와 구문 규칙으로 이루어진 결정론적 문법이 있어야 합니다. 이를 context free grammer(문맥 자유 문법) 이라 부릅니다. 자연어는 위의 특성을 지니지 않으므로, 일반적인 파싱 기술로는 파싱할 수 없습니다.
Parser-Lexer combination
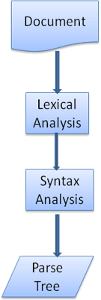
파싱은 두 가지의 과정으로 나뉠 수 있습니다.
1. Lexcial Analysis (어휘 분석)
2. Syntax Analysis (구문 분석)
어휘 분석은 주어진 값을 토큰으로 분리하는 과정입니다. 토큰은 유효한 구성 요소의 모임으로 자연어에서의 단어와 같은 것을 의미합니다.
구문 분석은 구문 규칙을 적용하는 과정입니다.
파서는 주어진 값을 유효한 토큰으로 변환하는 lexer(어휘 분석기)와 문서에 구문 규칙을 적용하여 파스 트리를 생성하는 parser로 이루어져 있습니다. lexer는 공백이나 줄바꿈과 같이 무의미한 문자를 제거합니다.
파싱은 반복됩니다. 파서는 lexer로부터 새로운 토큰을 받아 알맞는 구문 규칙을 적용합니다. 알맞은 규칙을 발견하면, 토큰을 노드로 변환하여 파스 트리에 추가하고 lexer에게 다른 토큰을 요청합니다.
만약 알맞은 규칙이 없다면, 파서는 토큰을 저장하고, 저장된 모든 토큰과 맞는 규칙을 발견할 때까지 토큰을 요청합니다. 이 때까지 파서가 규칙을 발견하지 못한다면 문서에 syntax error가 있다는 예외를 발생시킵니다.
Translation
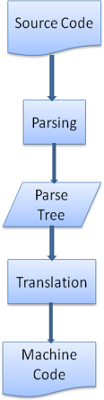
일반적으로 파스 트리는 최종 결과물이 아닙니다. 파싱은 문서를 다른 형식으로 변환하는 과정에 포함됩니다. 대표적으로, 컴파일러가 코드를 기계어로 변환하기 위해 먼저 코드를 파스 트리로 파싱하고 이를 기계어로 변환합니다.
Parsing example
간단한 수학적 언어를 정의하고 파싱 과정을 살펴보겠습니다.
-
Vocabulary: 정수, 더하기, 빼기
-
Syntax:
1. 기본 구성 요소는 표현식, 항, 연산자입니다.- 표현식의 수에는 제한이 없습니다.
- 표현식은
/[항][연산자][항]/과 같은 구조를 따릅니다. - 연산자는 + 나 - 입니다.
- 항은 정수 토큰이나 표현식으로 이루어져 있습니다.
2 + 3 - 1의 파싱 과정을 살펴보겠습니다.
규칙에 맞는 첫 번째 문자열는 2 입니다. 5번 규칙에 따라, 이는 하나의 항입니다. 두 번째 문자열은 2 + 3으로 3번 규칙에 의해 표현식입니다. 2 + 3 - 1은 3번 규칙과 5번 규칙에 의해 표현식입니다.
Formal definitions for vocabulary and syntax
어휘는 일반적으로 정규 표현식으로 나타냅니다.
위의 예시는 아래와 같은 정규 표현식으로 나타낼 수 있습니다.
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUSE: -구문 규칙은 BNF라 불리는 형식으로 정의됩니다.
위의 예시는 아래와 같이 표현됩니다.
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expressioncontext free grammer(문맥 자유 문법)은 regular parser가 파싱할 수 있습니다. context free grammer(문맥 자유 문법)을 간단하게 표현하면, BNF로 모두 표현 가능한 문법입니다.
Types of parsers
파서에는 Top down parser와 Bottom up parser가 있습니다.
Top down parser는 알맞은 규칙을 찾기 위해서 트리의 위로부터 순회하는 것이고,
Bottom up parser는 인풋에서 시작해 점진적으로 맞는 구문 규칙으로 변환하는 것입니다.
위의 예시를 각각의 파서가 어떻게 파싱하는 지 살펴보겠습니다.
Top down parser는 높은 수준의 규칙부터 시작합니다. 2 + 3을 표현식으로 인식하고, 2 + 3 -1을 표현식으로 인식합니다.
Bottom up parser는 알맞은 규칙을 찾을 때까지 인풋을 스캔합니다. 알맞은 규칙을 찾으면 이를 인풋과 바꿉니다. 이 과정은 인풋의 끝까지 반복됩니다. 부분적으로 매칭되는 표현식은 파서의 스택에 쌓입니다.
| Stack | Input |
|---|---|
| 2 + 3 - 1 | |
term | + 3 - 1 |
term operation | 3 - 1 |
expression | - 1 |
expression operation | 1 |
expression | - |
bottom up parser는 인풋의 포인터가 오른쪽으로 이동하면서 점진적으로 구문 규칙으로 변환되기 때문에 shift-reduce parser 라고 불리기도 합니다.
Generating parsers automatically
파서를 생성하는 여러 툴이 있습니다. 어휘와 구문 규칙을 입력하면, 파서를 생성합니다. 파서를 만드는 것은 파싱에 대한 깊은 이해가 필요하고 직접 최적화하기는 상당히 어려우므로 파서 생성기는 매우 유용합니다.
Webkit 은 lexer 를 만들기 위해 Flex 를, parser 를 만들기 위해 Bison 을 사용합니다. Flex의 인풋은 토큰의 정규 표현식을 포함한 파일이고, Bison의 인풋은 BNF 형식의 구문 규칙입니다.
참고 자료
How Browsers Work: Behind the scenes of modern web browsers
브라우저는 어떻게 동작하는가?
TIL no.97 - WEB - 3 - How Browsers Work
