
HTTP
HTTP는 웹 클라이언트와 서버간의 하이퍼텍스트 문서를 교환하기 위한 통신 규약이다.
웹에서만 사용하는 프로토콜이며 TCP/IP에 기반하여 클라이언트와 서버 간의 요청과 응답을 전송한다. 또한 Well-Known 포트인 80번 포트를 사용한다.
HTTP의 역사
HTTP/0.9
HTTP의 초기 버전이며 매우 단순하여 단일 프로토콜 (One-line)이라고도 한다.
Request Message
GET /text.htmlResponse Message
<HTML>
A very simple HTML page
</HTML>- 요청은 GET 메서드와 URL 으로만 구성되어있다.
- 응답은 시작줄, 헤더가 없이 본문만이 존재했다.
- HTML 파일만 전송이 가능했다.
- 상태 코드가 존재하지 않아 상태에 대한 설명을 파일 내부에 첨부하여 응답했다.
HTTP/1.0
HTTP/0.9에서 한단계 개선된 버전이다.
Request Message
GET /text.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)Response Message
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN?3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myImage.gif">
</HTML>- 버전 번호, HTTP 헤더 및 메소드, 멀티미디어 객체 처리가 추가되었다.
- 시각적인 효과를 가진 폼 (form)이 추가되었다.
HTTP/1.0이 흥행하기 시작하면서 몇 가지 기능이 더 추가된 HTTP/1.0+가 비공식적으로 나왔다.
- keep-alive Connection이 추가되었다.
- 가상 호스팅과 프록시 연결을 지원하기 시작했다.
HTTP 1.0 까지는 한 번의 연결은 한 번의 요청과 한 번의 응답만이 가능했다. 따라서 매번 새로운 연결을 수립해야했으므로 성능이 저하되고 서버의 Overhead가 증가했다.
이후 HTTP/1.1이 등장했으며 현재까지 표준 프로토콜로 자리잡고 있다.
HTTP 특징
HTTP는 TCP 기반의 통신 방식이기 때문에 TCP의 특징과 유사하다.
비연결 지향 (Connectionless)
한번의 요청과 응답이 이루어지면 연결을 종료한다. 따라서 데이터 전송 과정이 간단하기 떄문에 자원이 적게 필요하다.
하지만 연결이 지속적이지 않기 때문에 추후에 추가적인 요청이 올 때 어떤 사용자의 요청인지 알 수 없다는 문제가 있다.
또한 연결이 끊어짐에 따라 추후에 새로 연결할 때 다시 TCP/IP의 3-way-handshake 과정을 거쳐야하므로 소요 시간이 늘어난다. 가령 하나의 HTML 문서와 레퍼런스된 CSS, JS 파일을 받아오기 위해서는 HTML 문서를 받고 종료하고, 새로 연결해서 CSS를 받고 종료하고, 또 새로 연결해서 JS를 받고 종료하는 방식으로 통신해야한다.
이를 보완하기 위해 HTTP/1.1 부터는 지속적 연결과 파이프라이닝 방식이 도입되었다.
지속적 연결 (Persistent Connection)
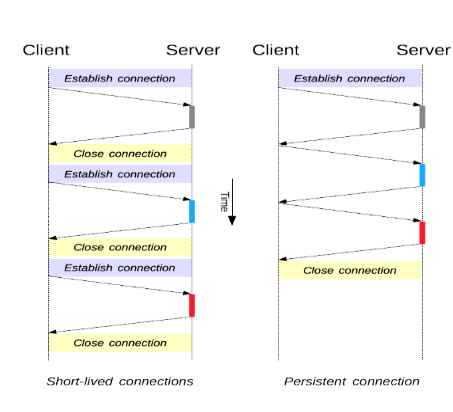
연결이 된 이후 일정 시간동안 연결을 유지하여 여러 번의 요청과 응답이 가능하다.
지속적 연결은 요청 Header에 Connection: keep-alive 속성을 추가하여 설정할 수 있다.
HTTP 1.1 부터는 지속적 연결 방식이 기본으로 설정되어있으며 이를 해제하기 위해 명시적으로 요청 Header를 수정해야한다.
파이프라이닝 (Pipelining)
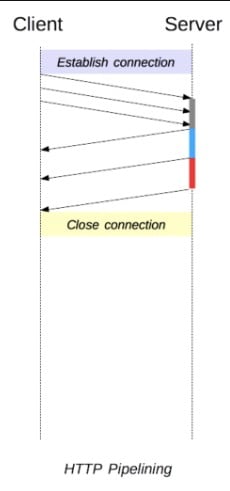
하나의 연결에서 응답을 기다리지 않고 순차적으로 여러 개의 요청을 연속적으로 보내고, 그 순서에 맞춰 응답을 받는 방식이다.
파이프라이닝을 통해 지연 시간 (Latency)를 줄일 수 있다.
단방향성
클라이언트의 요청에 따라 서버가 응답하는 과정이므로, 서버가 먼저 응답 또는 요청을 하지 않는다.
무상태 (Stateless)
서버는 클라이언트와 연결이 종료되면, 이전 상태를 보존하지 않는다. 즉, 연결이 한번 종료되면 서버는 이 클라이언트와 연결을 했었다는 기억 자체를 지워버린다. 따라서 추후에 똑같은 클라이언트가 다시 요청을 한다 해도 서버는 처음 보는 클라이언트인 것처럼 대한다.
클라이언트의 상태를 보존하지 않기 때문에 서버 자원의 사용량이 덜하며, 클라이언트의 요청이 대폭 증가한다 하더라도 서버를 증설해서 대응할 수 있다. 만약 서버가 클라이언트의 상태를 기억하는 Stateful 이라면, 한번 클라이언트-서버 연결이 이루어지면 이 클라이언트는 동일한 서버랑만 통신해야만 한다. 내 상태를 기억하는 서버는 이 서버가 유일하기 때문이다. 이렇게되면 추후에 클라이언트가 대폭 증가할 때 서버 입장에서는 큰 부담이 아닐 수 없다.
하지만 상태를 유지해야하는 경우도 있기 마련인데, 대표적인 케이스가 로그인이다. 클라이언트가 로그인을 하면, 이 클라이언트가 로그인을 한 인가된 사용자라는 상태가 기억이 되어야한다. 그래야 로그인이 유지가 되며 마이페이지 열람 같은 인가된 사용자만이 할 수 있는 요청을 수행할 수 있다. 이를 해결하기 위해 쿠키나 세션 또는 토큰 방식의 JWT 및 OAuth 같은 방식을 추가적으로 사용한다.
HTTP 메소드
클라이언트가 서버에게 요청할 때 보내는 요청 방법에 관한 메소드로, 클라이언트가 서버가 해주길 바라는 동작이다.
- GET : 서버에게 조회할 데이터를 요청한다. (READ)
- POST : 요청 본문 (Body)에 생성할 데이터를 삽입하여 서버에게 전송한다. (CREATE)
- PUT : 요청 본문에 (Body)에 수정할 데이터를 삽입하여 서버에게 전송한다. (UPDATE)
- DELETE : 서버에게 특정 데이터를 삭제할 것을 요청한다. (DELETE)
- PATCH : PUT과 비슷하지만 PUT은 전체 데이터를 수정하고 PATCH는 일부만 수정한다는 차이가 있다.
GET vs POST
GET
GET 방식에서는 데이터를 HTTP Request Message의 Header 부분에 있는 URL 상에 ? 뒤에 붙여서 요청한다. 따라서 URL이라는 공간에 담겨가기 때문에 전송할 수 있는 데이터의 크기가 제한적이다. 또한 데이터가 URL에 그대로 노출이 되기 때문에 보안이 필요한 데이터일 경우 GET 방식으로 보내는 것은 적절하지 않다.
POST
POST 방식에서는 데이터를 HTTP Request Message의 Body 부분에 담아서 전송한다. 따라서 보낼 수 있는 데이터의 크기가 GET 방식보다 크고 보안적으로도 더 유용하다.
또한 요청 헤더의 Content-Type에 전송하고자 하는 데이터 타입을 적어주어야 한다.
GET vs POST
GET은 서버로부터 데이터를 가져오는 메소드이다. 즉, 서버로부터 어떤 데이터를 가져와서 보여주는 용도이지 서버의 값이나 상태를 변경하는 용도가 아니다. (SELECT) 반면 POST는 서버의 값이나 상태를 변경하거나 새로운 데이터를 추가하기 위해 사용된다.
또한 GET 요청은 브라우저에서 Caching할 수 있기 때문에 POST 방식으로 요청해야 할 것을 보내는 데이터의 크기가 작고 보안 문제가 없다는 이유로 GET 방식을 통해 요청한다면, 응답으로 기존에 Caching 된 데이터가 올 수 있다.
HTTP 응답 상태코드
서버는 클라이언트로부터 요청을 받고 응답을 줄 때, 이 요청을 어떻게 처리했는지를 명시하는 상태 코드를 포함하여 보내준다.
1xx (요청에 대한 정보)
요청을 받았으면 작업을 계속 한다.
2xx (성공)
요청을 성공적으로 수행했다.
- 200 : 요청을 성공적으로 수행했다.
- 201 : 새로운 데이터를 작성했다.
- 202 : 요청을 접수했지만 아직 처리하지 않았다.
3xx (리다이렉션)
클라이언트가 요청을 마치기 위해 추가적인 동작을 취해야한다.
- 300 : 여러 개의 응답이 있으며 클라이언트가 선택해야한다.
- 301 : 클라이언트가 요청한 페이지로 영구 이동한다.
- 302 : 임시로 다른 페이지로 이동한다.
4xx (클라이언트 오류)
클라이언트 상에 오류가 있다.
- 401 : 클라이언트가 권한이 없다.
- 403 : 클라이언트는 현재 요청한 데이터에 권한이 없다. (접근 금지)
- 404 : 클라이언트가 요청한 데이터를 찾을 수 없다.
5xx (서버 오류)
서버 상에 오류가 있다.
- 500 : 서버에 내부적인 오류가 발생했다.
- 501 : 클라이언트의 요청을 수행할 기능이 없어 메소드를 인식할 수 없다.
- 503 : 클라이언트가 요청한 서비스는 현재 사용할 수 없다.
헤더 (Header)
요청과 응답의 헤더에는 다양한 항목이 존재한다.
요청 헤더
- Host : 서버의 도메인 이름과 TCP 포트 번호. (표준 포트는 생략 가능하다.)
- Content-Type : POST 또는 PUT을 사용할 때 본문의 타입.
- If-Modified-Since : 명시된 날짜 이후에 변경된 데이터만 획득 가능하다.
- Origin : 요청이 어느 도메인에서 왔는지 명시한다.
- Cookie : 서버의 Set-Cookie로 설정된 쿠키의 값.
응답 헤더
- Access-Control-* : CORS를 허용하기 위한 웹사이트를 명시한다.
- Set-Cookie : 클라이언트에 쿠키를 설정한다.
- Last-Modified : 요청한 데이터가 마지막으로 변경된 시각.
- Location : 상태 코드가 3xx (리다이렉션)일 때, 리다이렉트되는 주소
- Allow : 요청한 리소스에 대해 사용 가능한 메소드.
HTTP/1.1 동작 과정
서버 접속 -> 클라이언트의 요청 -> 서버의 응답 -> 연결 종료
- 사용자가 웹 브라우저에 URL 주소를 입력한다.
- DNS 서버에 웹 서버의 호스트 이름을 IP 주소로 변경 요청한다.
- 웹 서버와 TCP 연결을 수립한다. (3-Way-Handshake)
- 클라이언트가 서버에게 요청을 보낸다.
- HTTP 요청 메시지 : 요청 Header + 빈 줄 + 요청 Body.
- 요청 Header : 요청 메소드 + 요청 URI + HTTP 프로토콜 버전.
- 빈 줄 : 모든 메타 데이터가 전송되었음을 알리는 용도.
- 요청 Body : POST, PUT, PATCH 등 데이터 추가 및 업데이트 요청과 관련된 내용.
- HTTP 요청 메시지 : 요청 Header + 빈 줄 + 요청 Body.
- 서버가 클라이언트에게 응답을 보낸다.
- HTTP 응답 메시지 : 응답 Header + 빈 줄 + 응답 Body.
- 응답 Header : HTTP 프로토콜 버전 + 응답 상태코드 + 응답 메시지
- 빈 줄 : 모든 메타 데이터가 전송되었음을 알리는 용도.
- 응답 Body : 응답 리소스 데이터.
- HTTP 응답 메시지 : 응답 Header + 빈 줄 + 응답 Body.
- 클라이언트와 서버의 연결이 종료된다.
- 웹브라우저가 웹 문서를 출력한다.
HTTP/1.1 문제점
HOLB (Head Of Line Blocking)
파이프라이닝 방식에서 나타나는 문제이다. 현재 요청의 처리 시간이 오래 걸릴 경우, 그 다음 요청은 꼼짝없이 기다려야만 한다. 왜냐하면 요청한 데이터의 순서를 지켜야되는 특성 때문이다. 이러한 문제를 Head Of Line Blocking 이라고 한다.
이로 인해 대기 시간 (Latency)이 증가한다는 문제가 발생했다.
헤더 구조의 중복
연속된 요청일 경우, 각 요청의 헤더에 중복되는 부분이 많음에도 불구하고 그대로 전송해버린다. 따라서 이러한 중복된 헤더 구조로 인해 데이터의 크기가 커진다.
HTTP/2.0
HTTP/1.1의 여러 문제점을 보완하기 위해 2015년 등장한 HTTP의 새로운 버전이다.
HTTP/2.0 특징
제일 중요한 변화점은 HTTP 메시지 전송 방식의 변화이다.
멀티플렉싱 (Multiplexing)
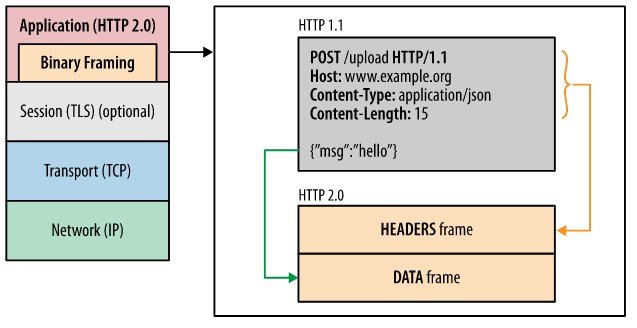
HTTP/1.1 까지는 일반적인 텍스트 형식으로 메시지를 보냈다면 HTTP/2.0 부터는 요청 데이터의 헤더와 본문을 각각 프레임 (Frame)이라는 단위로 지정하여 분할하고, 바이너리로 인코딩한다. 이를 바이너리 프레이밍이라고 한다.
바이너리 프레이밍을 통해 파싱과 전송 속도가 향상되고 오류 발생 가능성이 낮아진다.
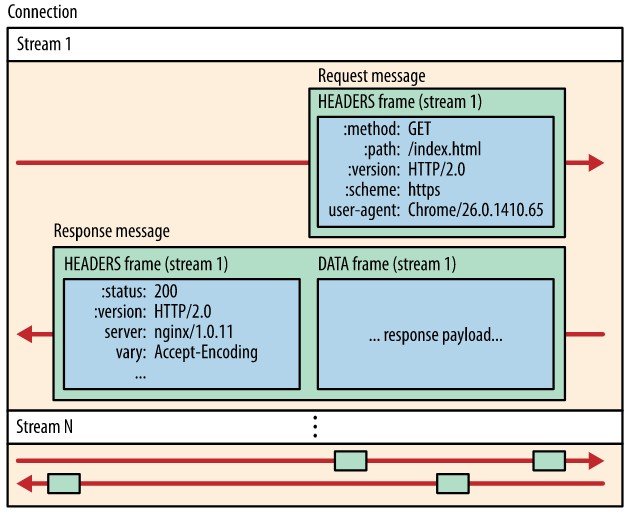
이 프레임들을 TCP 연결 안에서 스트림 (Stream)이라는 양방향 연결 흐름 단위를 통해 전송한다. 각각의 프레임들이 하나로 합쳐저서 요청/응답 메시지를 구성한다. 또한 하나의 스트림은 요청과 응답으로 구성되고 여러 개의 스트림을 생성할 수 있다.
HTTP/2.0은 이처럼 패킷을 프레임 단위로 세분화하여 순서에 상관없이 전송하며, 수신측에서 순서에 맞게 재조립하도록 설계되었다.
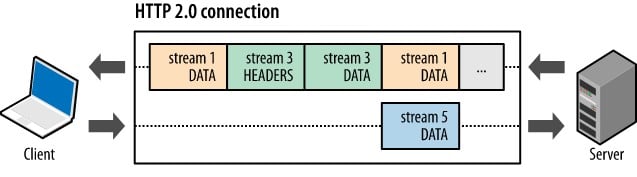
이러한 방식으로 요청과 응답에서 다중화 (Multiplexing)이 가능해졌으며 HOLB 문제를 해결할 수 있게 되었다.
Stream Prioritization
리소스 간의 우선 순위를 설정하여, 먼저 필요한 리소스의 우선 순위가 높게 설정되어 먼저 보내진다.
서버 푸시 (Server Push)
원래는 브라우저의 요청 없이는 서버의 응답이 없지만, 요청한 HTML 문서에 추가 리소스가 레퍼런스 되어있는 경우 서버가 알아서 추가적으로 응답해주는 방식이다.
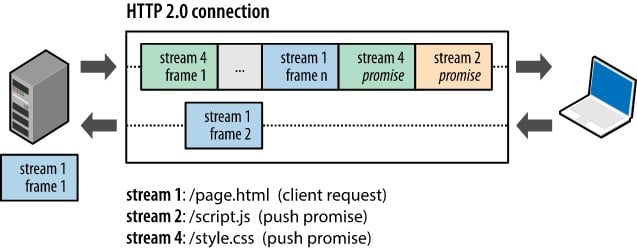
예를 들어, HTML 문서를 요청했는데 그 안에 CSS, JS 파일이 포함되어있으면, 클라이언트가 이를 요청하지 않아도 서버가 알아서 응답 (Push)해준다.
헤더 압축 (Header Compression)
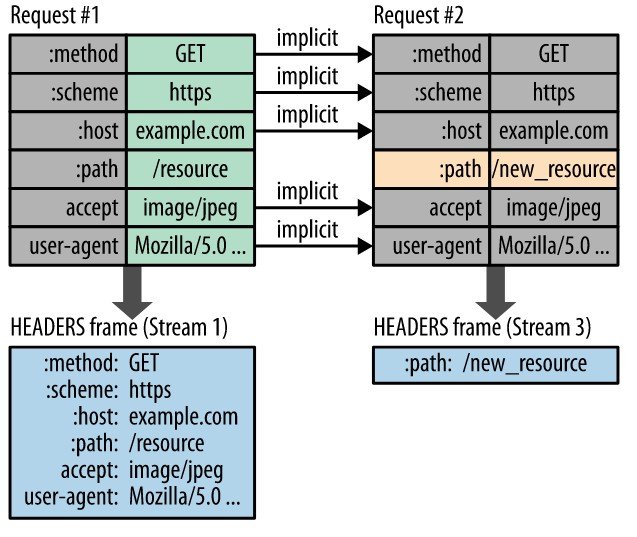
헤더 테이블 (Header Table)을 사용해서 이전 헤더 정보를 유지한다.
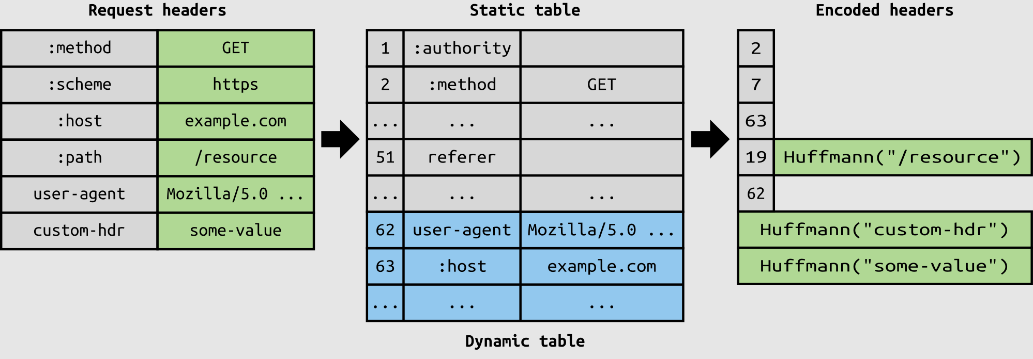
또한 중복되는 부분은 허프만 인코딩 기법으로 헤더를 압축해서 전송하여 중복과 크기를 줄인다.
HTTPS
HTTP의 문제점
- 평문 통신이기 때문에 도청이 가능하다. (메시지가 데이터 그 자체)
- 통신 상대를 확인하지 않기 때문에 위장이 가능하다.
- 완전성을 증명할 수 없기 때문에 변조가 가능하다.
평문 통신이기 때문에 도청이 가능하다.
HTTP가 기반하고 있는 TCP/IP 모델의 통신은 전부 통신 경로 상에서 엿볼 수 있다. 오가는 패킷을 획득하는 것 만으로도 도청이 가능하다. 따라서 평문으로 통신되는 메시지가 탈취될 경우 그 메시지의 의미가 파악될 수 있기 때문에 암호화가 필요하다.
통신 상대를 확인하지 않기 때문에 위장이 가능하다.
HTTP의 통신은 요청하는 사람이 누구인지 확인하는 과정이 없기 때문에 누구든지 요청을 보낼 수 있다. 서버 역시 특별히 액세스 제한이 없을 경우 요청이 오면 누가 보냈던지 간에 응답을 보낸다.
이 경우
- 요청을 보낸 곳의 서버가 원래 응답을 보내야 하는 서버인지 알 수 없다.
- 응답을 반환한 곳의 클라이언트가 원래 요청을 보내야하는 곳의 클라이언트인지 알 수 없다.
- 지금 통신하고있는 상대가 인가된 상대인지 알 수 없다.
- 어디서 누가 요청을 보내는지 알 수 없다.
- 의미없는 요청까지도 수신하기 때문에 Dos 공격을 방지할 수 없다.
완전성을 증명할 수 없기 때문에 변조가 가능하다.
수신측이 받은 데이터가 전송측에서 보낸 데이터와 똑같은 데이터인지 아니면 위변조된 데이터인지 알 수 없다. 따라서 중간자 공격 (Main-in-the-middle) (해커가 요청 또는 응답을 가로채어 변조하는 공격)을 방지할 수 없다.
HTTPS
이러한 문제점을 보완하기 위해 HTTPS가 등장했다. HTTPS는 HTTP에 암호화, 인증, 완전성 보호를 더한 방식이다.
HTTPS는 완전히 새로운 어플리케이션 계층의 프로토콜이 아니라 SSL이 더해진 HTTP이다. HTTP의 통신 소켓을 SSL (Security Socket Layer) 또는 TLS (Transport Layer Security)로 대체하여 전송한다.
기존에 TCP와 직접 통신하던 HTTP와 달리, HTTPS에서 HTTP는 SSL과 먼저 통신하고, SSL이 TCP와 통신을 한다. 이러한 방식을 통해 암호화와 증명서, 완전성 보호를 보장할 수 있다.
또한 구글은 HTTPS를 적용한 웹사이트에 더 가산점을 주기 때문에, SEO를 고려한다면 HTTPS는 거의 필수 요소로 자리매김 하고 있다.
SSL
SSL 프로토콜은 Netscape Communications Corporation에서 웹 서버와 브라우저간의 통신에 보안을 위해서 만들어졌다. 인증기관 (CA : Certificate Authority)로부터 서버와 클라이언트가 인증을 받아서 통신이 이루어진다.
SSL은 서버와 브라우저 사이에서 암호화된 연결을 만들 수 있게 도와주고, 서버와 브라우저가 민감한 정보를 주고 받을 때 해당 정보가 도난당하는 것을 막아준다.
- 공개키 (Public Key) : 모두가 볼 수 있는 키.
- 개인키 (Private Key) : 소유자만이 가지고 있는 키.
- 인증 기관 (CA : Certificate Authority) : 클라이언트가 접속을 요청한 서버가 의도한 서버가 맞는지 인증해주는 기관.
대칭키 암호화
클라이언트와 서버가 암호화/복호화에 동일한 개인키를 사용하는 방식. 따라서 단순함 덕분에 속도는 빠르지만 누구든지 개인키를 가지고 있다면 해당 데이터를 복호화 할 수 있다.
비대칭키 (공개키) 암호화
클라이언트와 서버가 암호화/복호화에 각각 다른 비밀키를 사용하는 방식. 암호화에는 공개키를, 복호화에는 개인키를 사용한다.
공개키로 암호화한 데이터는 오직 개인키로만 복구할 수 있기 때문에 공개키의 유출은 위협이 되지 않는다.
비대칭키 암호화 방식은 대칭키 방식보다 암호화 연산 시간이 더 소요되어 비용이 크다.
결론적으로 대칭키 암호화 방식의 단점이 비대칭키 암호화 방식의 장점이 되고, 비대칭키 암호화 방식의 단점이 대칭키 암호화 방식의 장점이 된다.
SSL은 이처럼 대칭키와 비대칭키의 장단점을 서로 보완하기 위해 두 방식을 전부 사용하여 암호화와 복호화를 진행한다.
암호화와 복호화는 유출되면 큰 피해를 유발할 수 있는 비밀번호, 개인정보 등에 보통 적용된다.
SSL 통신 과정
SSL은 공개키 방식으로 대칭키를 전달한다. 그리고 이 대칭키를 활용해서 암호화/복호화를 진행한 후, 서버-브라우저 간 통신을 진행한다.
호스트 A와 B가 SSL로 통신한다고 가정해보자.
- A는 B에게 접속 요청을 보낸다.
- B는 A에게 자신의 공개키를 전송한다.
- A는 자신의 대칭키를 B에서 전달받은 B의 공개키로 암호화한다.
- A는 암호화한 자신의 대칭키를 B에게 전달한다.
- B는 A의 대칭키를 자신의 개인키로 복호화하여 A의 대칭키를 얻는다.
- 이렇게 얻은 대칭키를 활용해서 안전하게 통신한다.
즉, 데이터 암호화/복호화에 필요한 한 쪽의 대칭키를 다른 쪽의 공개키로 암호화해서 전송하면, 반대편에서 자신의 개인키로 복호화하여 대칭키를 확보하고, 서로 대칭키를 활용해서 통신하는 방식이다.
HTTPS와 SSL
실제로 HTTPS에서 SSL을 활용하는 과정은 다음과 같다.
- 사이트는 인증 기관으로부터 사이트 인증서를 받아온다. 이를 위해 사이트에서 인증기관에게 사이트 정보, 사이트 공개키를 전달한다.
- 인증기관은 전달 받은 데이터를 검증한다. 검증을 완료하면 사이트 인증서를 생성하기 위해 사이트 데이터를 자신의 개인키로 서명한다. 이렇게 생성한 인증서를 사이트에게 전달한다.
- 인증기관은 사용자에게 자신의 공개키를 전달한다. 사용자가 전달받은 인증기관의 공개키는 브라우저에 자동으로 내장된다.
- 사용자가 사이트에 접속을 요청한다.
- 사이트는 자신의 신뢰성을 증명하기 위해 사용자에게 자신의 인증서를 전달한다.
- 사용자는 브라우저에 있는 인증기관의 공개키로 사이트의 인증서를 복호화한다.
- 이렇게 얻은 사이트 정보와 사이트 공개키로 사용자는 자신의 대칭키를 암호화한다.
- 사용자는 암호화한 자신의 대칭키를 사이트에게 전달한다.
- 사이트는 자신의 개인키로 사용ㅏ로부터 전달받은 암호문을 해독해서 사용자의 대칭키를 얻는다.
- 이렇게 얻은 대칭키를 활용하여 사용자와 사이트는 서로 암호문을 주고받는다.
HTTPS의 한계
기존 HTTP의 평문 통신에 비해 암호화 통신은 CPU나 메모리 등에 더 많은 Overhead를 유발한다. 통신할 때 마다 암호화의 과정을 거치면 추가적인 자원을 소모하기 때문에 서버가 처리할 수 있는 요청의 수가 상대적으로 줄어들게 된다.
하지만 최근에는 하드웨어의 발달로 HTTPS를 사용하더라도 Overhead로 인한 속도 저하가 거의 발생하지 않으며, HTTP 2.0을 사용할 시 오히려 HTTP보다 HTTPS가 더 빠르게 동작한다.
따라서 과거에는 민감한 정보에만 HTTPS를 적용하였지만 현재는 모든 웹 페이지에 HTTPS를 적용하는 방식으로 바뀌어가고 있다.
