
Caravan Analogy
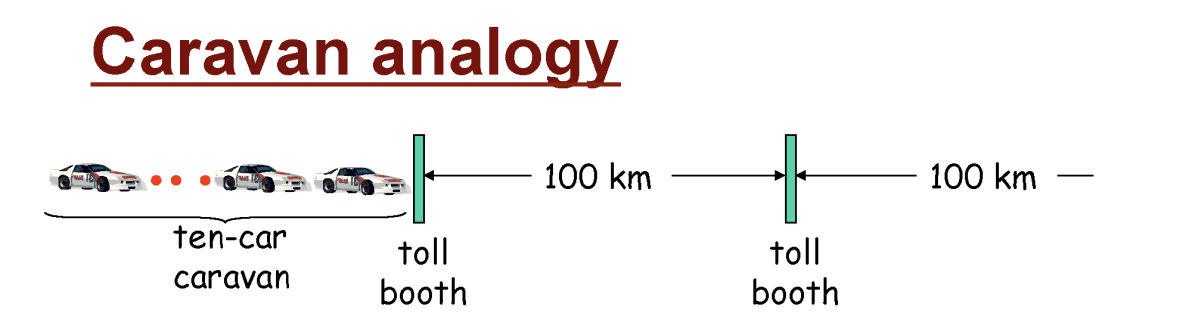
패킷과 딜레이의 관계를 차량과 톨게이트에 비유한 개념이다.
차량 1대 : 비트
차량 10대 (Caravan) : 패킷 (10비트)
차량 10대는 모두 동일한 속도로 움직인다.
Processing Delay와 Queueing Delay는 없다고 가정한다.
차량 1대가 이동하는 속도는 100km로, Propagation Delay와 같다.
차량 1대가 톨게이트를 지나는 시간은 12초로, Transmission Delay와 같다.
이때 한 패킷이 2번째 톨게이트에 전부 도달하기까지의 시간은 얼마나 될까?
차량 1대가 톨게이트를 통과하는 속도는 12초이므로, 차량 10대가 통과하는 속도는 120초가 된다. (Transmission Delay)
또한 자동차가 Propagate (전파) 즉, 이동하는 속도는 100km이므로, 100km/100km/h = 60분이 된다.
따라서 패킷의 Transmission Delay / Propagation Delay => 120secs + 60m = 62m이 된다.
중요한 점은 하나의 비트 (차량)이 도착했다고 바로 다음 라우터로 보내는 것이 아니라 모든 차량 (패킷)이 전부 도착해야 다음 라우터로 한꺼번에 보낸다는 점이다.
whenever the first car of the caravan arrives at a tollbooth, it must wait at the entrance to the tollbooth until all of the other cars in its caravan have arrived, and lined up behind it before being serviced at the toll booth.
즉, 패킷의 일부가 라우터에 도착하더라도 바로 통과하지 않고, 나머지 부분들이 모두 도착해서 패킷이 완전체가 되어야지만 라우터를 통과한다는 것이다.
앞서 패킷 스위칭은 일정한 데이터 블럭인 패킷을 교환기가 수신측의 주소에 따라 적당한 통신 경로를 선택하여 전송하는 교환방식이라고 했다. 즉, 전송하고자 하는 데이터를 일정한 크기로 분할한 후, 송수신 주소인 헤더를 각각에 부가한 패킷 단위로 전송하는 방식이다.
모든 차량이 톨게이트에 도착해야 통과하는 Caravan Analogy 과정으로 패킷 스위칭의 비유 설명이 가능하다.
네트워크 계층
네트워크는 크게 5가지 계층으로 볼 수 있으며 각각 다음과 같은 대표적인 프로토콜을 갖고 있다.
- Application Layer
- HTTP
- Transport Layer
- TCP/UDP
- Network Layer
- IP
- DataLink Layer
- WiFi
- LTE/3G
- Ethernet
- Physical Layer
라우터에는 네트워크 계층부터 데이터 링크 계층, 물리 계층까지만 존재한다.
어플리케이션이란 서로 다른 엔드 시스템들끼리 네트워크를 통해 통신하는 시스템을 의미한다. 예를 들어 웹 서버와 웹 브라우저가 HTTP를 통해 통신하는 경우가 있다.
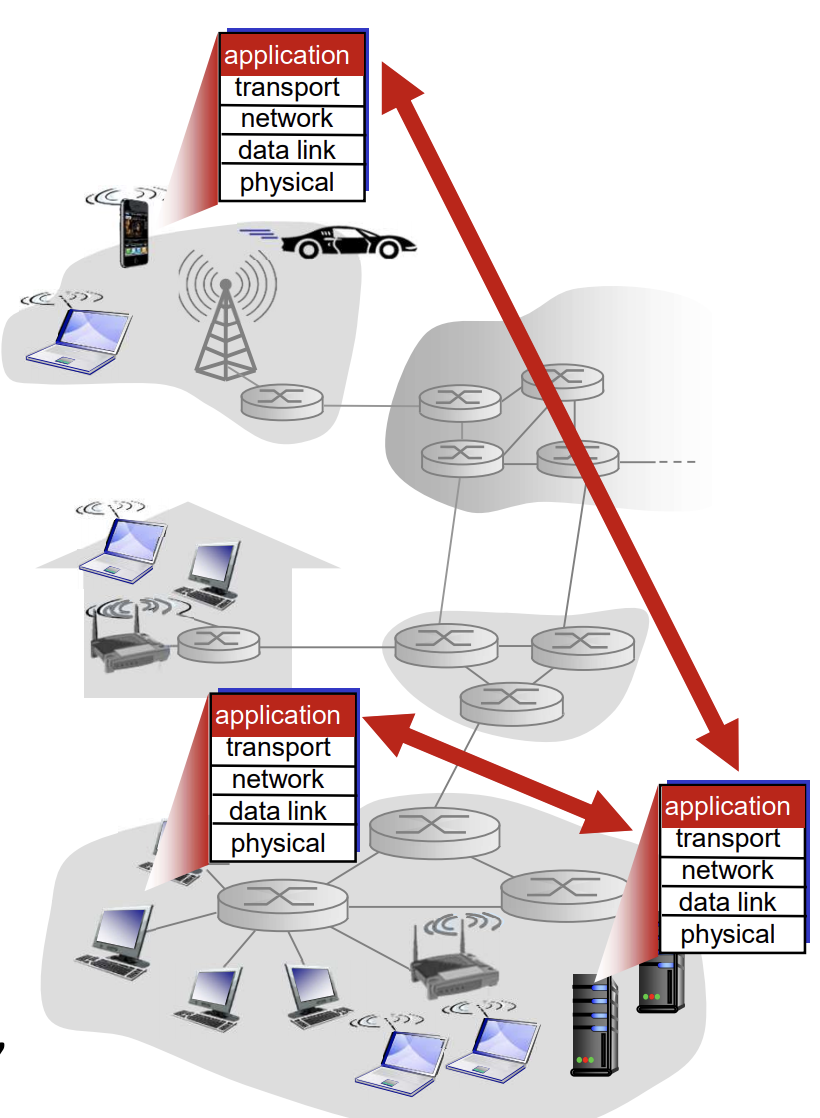
실질적으로 어플리케이션을 제작할 때에는 네트워크 코어 즉, 라우터가 어떻게 동작하는지까지는 신경쓰지 않고, 단지 어플리케이션끼리 어떠한 네트워크를 통해 통신하는지만을 신경써도 무리가 없다. 왜냐하면 네트워크 코어 쪽의 장치들은 실제 사용자가 사용하는 어플리케이션을 직접적으로 운영하지 않기 때문이다.
Client-Server Architecture (클라이언트-서버 모델)
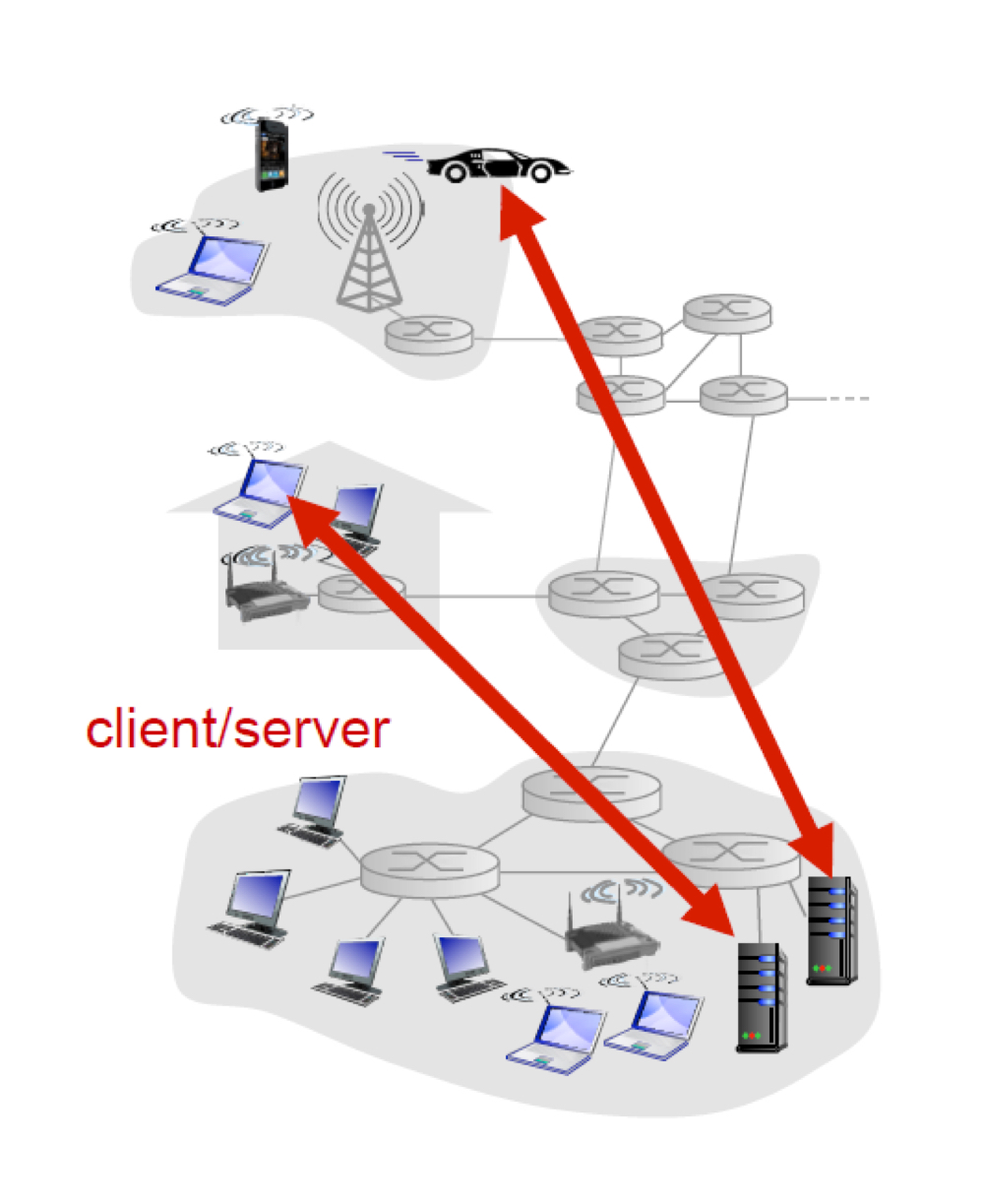
클라이언트-서버 모델은 쉽게 말해 클라이언트 프로세스와 서버 프로세스간의 통신이 이루어지는 모델이다.
서버는
- 항상 열려있어야 한다. (Always on host)
- 자신만의 고정된 식별 주소를 갖고 있어야한다. (Permanent Ip Address)
클라이언트는
- 서버와 통신한다. (Communicate with server)
- 간헐적으로 껐다 켰다 할 수 있다. (Maybe intermittently connected)
- 동적 IP 주소를 가질 수 있다. (May have dynamic IP address)
- 서로 다른 클라이언트끼리 직접적으로 통신하지 않는다. (Do not communicate directly with each other)
Process Communicating (프로세스 통신)
Process (프로세스)
프로세스란 하나의 호스트 안에서 동작하는 프로그램이다.
같은 호스트 안에 있는 여러가지의 프로세스들은 Inter-process communication (프로세스 간의 통신)을 통해 상호작용한다. 이때 Inter-process communication 방식은 운영체제에 의해 정의된다.
서로 다른 호스트의 프로세스는 메시지를 주고 받으면서 통신한다.
Client Process
클라이언트 프로세스는 통신을 시작하는 프로세스이다.
Server Process
클라이언트로부터 통신이 오기를 기다리는 프로세스이다.
P2P
Peer to Peer 모델에서 각 호스트는 서로 직접 통신하므로, 클라이언트가 될 수도 있고 서버가 될 수도 있다.
Sockets (소켓)
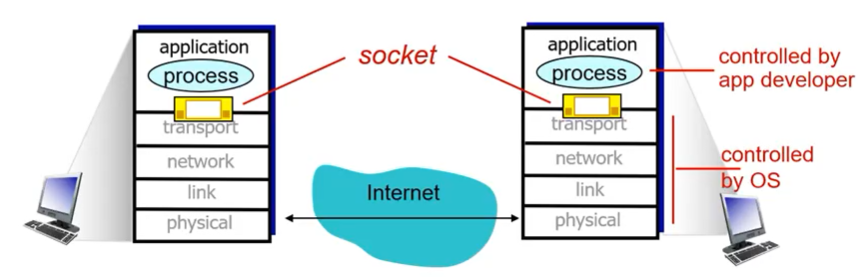
프로세스는 소켓을 통해 메시지를 주고 받는다. 따라서 소켓은 메시지를 주고 받는 인터페이스라고 할 수 있다.
서로 다른 프로세스끼리 연결할 때는 서로를 식별할 수 있는 수단이 필요하다. 이때 필요한 것이 IP주소와 PORT 이다.
IP 주소와 PORT
IP 주소 : 인터넷 상에 존재하는 컴퓨터를 지칭하는 주소.
PORT : 특정 컴퓨터 안의 특정 프로세스를 지칭하는 주소.
네이버에 접속하기 위해 웹브라우저 주소창에 www.naver.com을 입력했다고 가정해보자.
사실 네이버에 접속하기 위해서는 네이버 서버의 IP주소와 사용하고자 하는 프로세스의 포트번호를 입력해야 접속이 가능하다. 하지만 IP주소와 포트번호는 사람들에게 익숙하지 않다. 따라서 사람들을 위해서 www.naver.com 식의 주소만을 입력해도 접속이 가능하도록 설정했다. 이렇게 주소가 입력되면 DNS에서 이를 판독하여 알맞은 곳으로 접속시켜준다.
현재 시중에 나와있는 대부분의 서비스는 80번 포트를 사용하고 있다. 왜 다들 공통된 포트를 사용하는걸까? 서버는 24시간 켜져있어야하고 주소가 일정해야한다. 즉, 주소는 불변해야한다.
각 서비스마다 사용하는 주소는 서로 다르다. 따라서 DNS가 알맞은 주소로 보내주는데, 만약 포트 넘버까지 전부 다르다면? 과정이 더욱 복잡해질 것이다. 따라서 최소한 포트 넘버는 통일하자는 약속하에 대부분 80번의 포트를 사용하고 있다.
Transport Service
네트워크 계층에서 모든 하위 계층은 그 상위 계층에게 자신의 서비스를 제공한다.
우리가 어플리케이션 계층에서 어떤 기능을 사용하면 어플리케이션 계층은 그 밑에 있는 트랜스포트 계층에서 필요한 서비스를 불러와 사용한다.
이때 트랜스포트 계층에서는 다음과 같은 서비스를 제공해줄 필요가 있다.
Data Integrity
데이터가 유실되지 않고 100% 온전하게 전송될 필요가 있다.
파일 전송이나 웹에서의 상호작용과 같은 어플리케이션은 데이터 전송의 신뢰도가 100% 필요하다. 즉, 데이터가 유실되면 안되는 경우가 있다.
Timing
데이터가 정해진 시간 안에 도착해야한다.
인터넷 통신 또는 실시간 게임과 같은 어플리케이션은 효율적으로 동작하기 위해서 딜레이가 낮아야한다.
Throughput
주고 받는 데이터는 최소한의 용량을 가져야한다.
멀티미디어같은 어플리케이션은 효율적으로 동작하기 위해 적은 양의 데이터가 전송되어야한다.
Security
주고 받는 데이터는 보안을 갖춰야한다.
현실
현재 트랜스포트 계층에서 제공하는 서비스는 TCP에 의해 제공되는 Data Integrity가 유일하며 나머지 3개는 제공해주지 않는다.
또한 Timing과 Throughput은 다음과 같은 차이점이 있다.
- Timing : 전송한 패킷이 정해진 시간 안에 도착해야 하는 것.
- Throughput : 1초에 어느 정도 크기의 데이터가 전송되어야 하는지에 관한 것.
즉, Throughput은 데이터의 양에 관한 것이고, Timing은 각 데이터의 전송 시간에 관한 것이다.
HTTP (Hypertext Transfer Protocol)
Web and HTTP (웹과 HTTP)
웹 페이지는 여러 개의 객체로 구성되어있다. 객체는 HTML 파일, JPEG 이미지, 오디오 등등이 있다.
웹 페이지는 HTML 파일이 기본적으로 갖춰져있으며, 각 HTML 파일은 다른 여러 객체를 레퍼런스하고 있다.
HTML 파일은 주소를 통해 접속할 수 있다.
예를 들어 www.someschool.edu/someDept/pic.gif라는 주소가 있을 때, www.someschool.edu는 호스트이고, someDept/pic.gif는 경로이다.
HTTP
HTTP란 Hypertext를 전송하기 위한 프로토콜이다. 이때 Hypertext란 중간 중간에 링크가 포함되어있는 텍스트를 의미한다.
웹의 어플리케이션 계층에서 동작하는 프로토콜이며, 클라이언트와 서버가 통신할 때 사용한다.
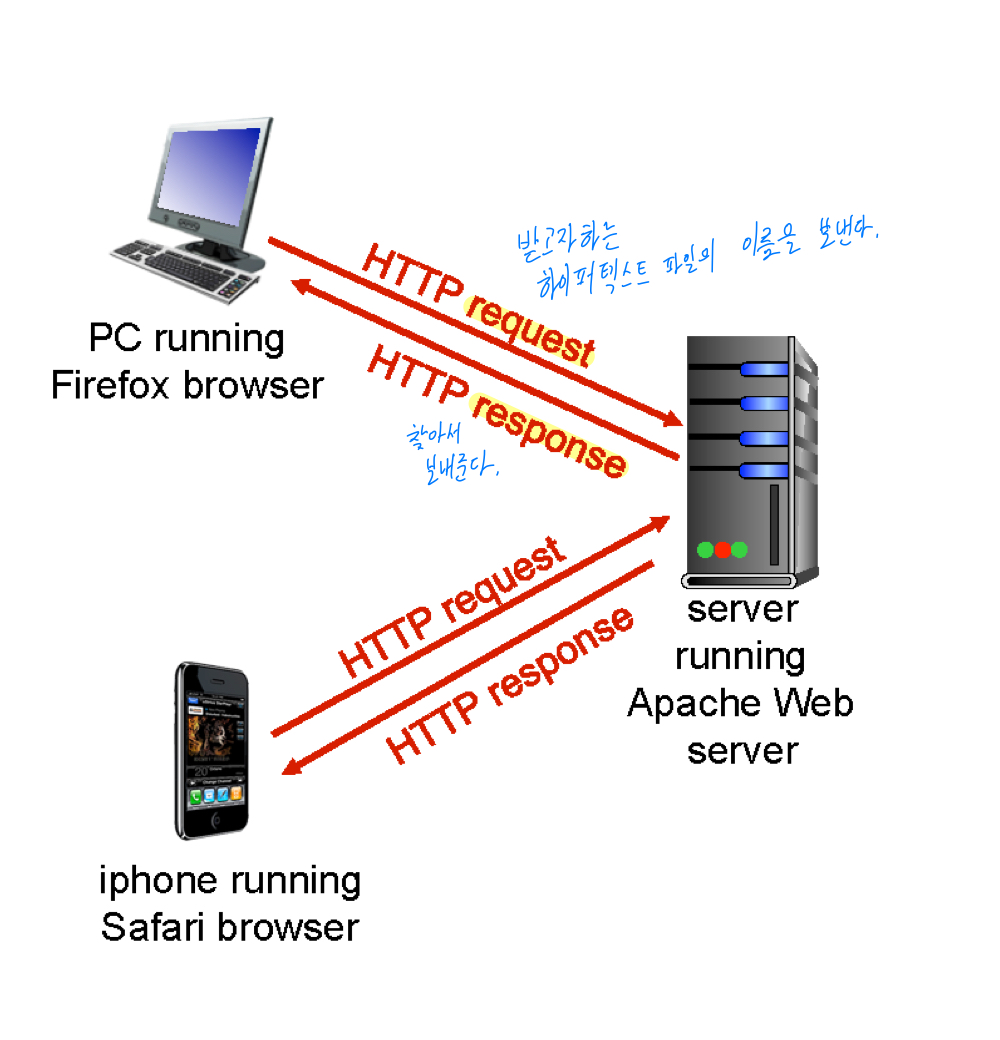
클라이언트는 HTTP를 통해 요청과 응답을 받고 웹브라우저에 객체를 표시한다.
서버는 HTTP를 통해 요청에 대한 응답으로 객체를 전송한다.
HTTP uses TCP
HTTP는 TCP를 통해서 통신하며 그 과정은 다음과 같다.
- 클라이언트는 소켓을 생성하여 서버와 TCP 연결을 시작한다. 이때 사용하는 포트는 80번이다.
- 서버는 클라이언트로부터 TCP 통신을 받고 접속한다.
- HTTP 메시지 (어플리케이션 계층의 프로토콜 메시지)가 웹 브라우저 (HTTP 클라이언트)와 웹 서버 (HTTP 서버) 사이에서 교환된다.
- 통신이 끝나면 TCP 연결이 종료된다.
이처럼 한번 통신이 끝나면 연결을 종료하는 성질을 Connectionless라고 한다.
HTTP is "Stateless"
HTTP는 상태가 없다.
서버는 HTTP request 들어오면 HTTP response를 보내주는 작업에만 집중하며, 이전의 클라이언트 요청 정보를 따로 저장해두지 않는다.
HTTP는 Connectionless로 인해 클라이언트가 이전 요청과 같은 데이터를 원한다고 하더라도 다시 서버에 연결을 하여 동일한 요청을 보내야한다.
Stateless로 인해 서버는 단순하게 동작할 수 있고, 상태를 저장해야 하는 부담을 덜 수 있다. 하지만 로그인 상태 유지와 같이 클라이언트의 상태를 저장해둬야할 경우가 필요한데 이때는 쿠키, 세션, JWT 등을 통해 상태를 기억해야한다. 이는 따로 정리할 생각이다.
HTTP Connections
HTTP는 2가지 방식으로 통신한다.
Persistent HTTP
한번의 통신 후 연결을 끊지 않고 계속 유지한다. 따라서 이후의 HTTP 메시지는 동일한 연결을 통해 전송된다.
또한 클라이언트-서버가 한번 연결하면 다수의 객체를 주고 받을 수 있으며, HTML 파일의 레퍼런스들을 바로바로 요청해서 받아올 수 있다.
Non-persistent HTTP
한번의 TCP 통신에서는 최대 한개의 객체만이 전송되며, 전송이 끝나면 연결은 종료된다.
만약 다수의 객체를 주고 받아야한다면 그 수 만큼의 새로운 TCP 연결이 필요하다.
예를 들어서, 사용자가 www.someSchool.edu/someDepartment/home.index로 접속했다고 했을 때, Non-persistent HTTP는 다음과 같은 과정을 거친다.
(이때 home.index의 HTML 파일에는 10개의 jpeg 이미지가 레퍼런스되어있다고 가정한다.)
- HTTP 클라이언트는
www.someSchool.edu의 80번 포트에 위치한 서버와 HTTP 연결을 시작한다. www.someSchool.edu의 HTTP 서버는 80번 포트에서 TCP 연결을 기다리고 있다가, 연결에 접속하고 클라이언트에게 이를 알린다.
- HTTP 클라이언트는
- HTTP 클라이언트는 TCP 소켓 안에 HTTP 요청 메시지를 담아서 서버에게 전송한다. 이때 메시지는
클라이언트가 someDepartment/home.index 라는 객체를 받기를 원한다.라는 내용을 포함하고 있다. - HTTP 서버는 요청 메시지를 받고 응답 메시지를 생성하여 전달한다. 이때 응답 메시지에는 클라이언트가 요청한 객체가 포함되어있다. 응답 메시지는 소켓에 포함되어 전송된다.
- HTTP 서버는 TCP 연결을 종료한다.
- HTTP 클라이언트는 HTML 파일이 포함된 응답 메시지를 전달받아서 이를 브라우저에 표시한다. 동시에 이 HTML 파일을 파싱하면서 브라우저 안에 포함되어있는 10개의 이미지 레퍼런스를 찾아낸다.
- 10개의 이미지 레퍼런스에 대해 각각 1 ~ 5 의 과정을 통해 전달받는다.
이때 10개의 이미지를 매번 하나씩 갖고오는 것 보다는, 10개의 HTTP 요청을 한번에 보내고, 10개의 HTTP 응답을 한번에 받는 파이프라인 방식 + Persistant HTTP 방식이 더 효율적이다.
Non-persistant HTTP의 응답 시간
RTT (Round Trip Time)
작은 패킷 하나가 클라이언트에서 서버로 이동하고 다시 돌아오기까지 걸리는 시간
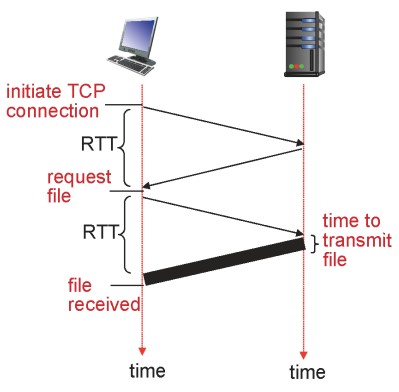
RTT는 다음과 같은 때 발생한다.
- TCP 연결을 시작할 때 한 번 발생.
- HTTP 요청이 전달되고 응답이 도착했을 때 한 번 발생.
HTTP 응답 시간은 다음과 같이 구할 수 있다.
Response Time = 2RTT + File Transmission Time (파일 전송 시간)
