
페이징 (Paging)
외부 단편화로 인해 사용 불가능할 정도의 메모리 낭비가 발생하고 Compaction으로는 효과적인 대응이 어렵다. 따라서 등장한 개념이 바로 페이징 (Paging)이다.
페이징이란 프로세스를 일정 크기 ( = 페이지)로 잘라서 메모리에 탑재하는 방식이다. 따라서 프로세스는 페이지 (Page)의 집합이 되며, 메모리는 프레임 (Frame)의 집합이 된다.
할당하는 방법
페이지를 프레임에 할당하는 과정은 MMU의 재배치 레지스터를 사용한다. 이를 통해, 실제 프로세스는 여러 개로 나뉘어서 메모리에 할당되지만 재배치 레지스터가 CPU를 속여서 CPU는 프로세스가 하나의 메모리 공간 안에 위치한다고 착각하는 것이다.
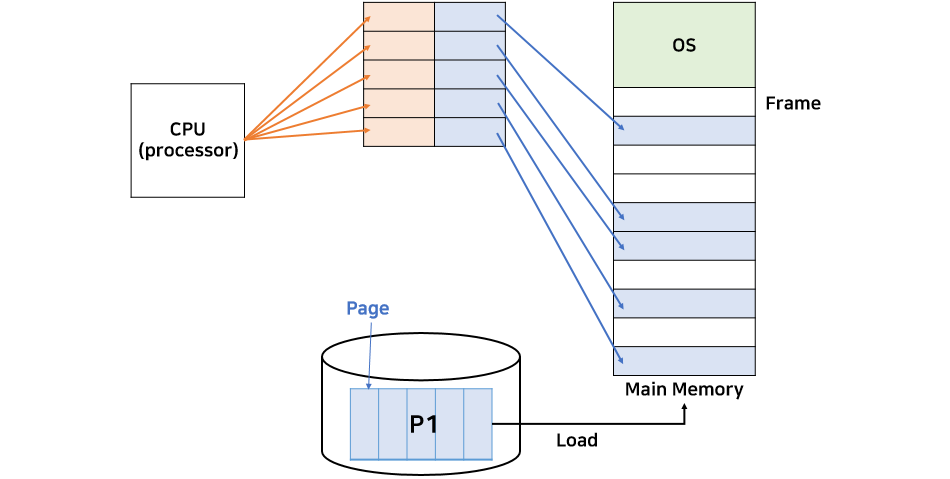
CPU는 원래 프로그램에 설정되어있는대로 하나의 연속된 주소값을 MMU에게 보내는데, MMU는 이 주소값을 여러개의 페이지로 쪼갠다. 그 후 페이지의 개수만큼 재배치 레지스터를 동작시켜서 메모리 (프레임)의 빈 공간으로 페이지들을 할당한다. 동시에 CPU에게는 "너가 원하는 주소로 잘 보냈어. 걱정하지마."라고 얘기하며 속인다. 이러한 역할을 수행하는 MMU를 페이지 테이블 (Page Table)이라고도 한다.
주소 변환 (Address Translation)
실제로 페이지 테이블에서 주소 변환이 어떻게 이루어지는지 살펴보자.
논리 주소 (Logical Address)
CPU가 내는 주소를 2진수로 표현하고 총 m비트가 있다고 하자. 여기서 하위 n 비트는 오프셋 (Offset) 또는 변위 (Displacement)라고 부른다. 그리고 상위 m-n 비트는 페이지 번호 (Page Number)에 해당한다. (n = d, m-n = p)
- d = Displacement
- p = Page Number
페이지 번호 p는 페이지 테이블의 인덱스 값이다. p에 해당하는 테이블 내용은 프레임 번호이고, 변위 (d)는 변하지 않는 값이다.
- 페이지 사이즈 : 4 bytes.
- 페이지 테이블 : 5, 6, 1, 2
- 논리 주소 13번지는 물리주소 몇 번지?
페이지 테이블은 다음과 같이 나타낼 수 있다.
| 인덱스 | 프레임 번호 |
|---|---|
| 0 | 5 |
| 1 | 6 |
| 2 | 1 |
| 3 | 2 |
논리 주소를 물리 주소로 변환하는 과정은 다음과 같다.
페이지 사이즈 4 bytes = 2^2 bytse => d는 2가 된다.
논리 주소 13을 2진수로 나타내면 1 1 0 1 이다.
d는 2이므로 1 1 0 1의 뒤에서 2개가 d가되고, 그 나머지가 p가 된다. 따라서 p는 1 1 즉, 3이된다.
13 = 1 1 0 1
p = 3
d = 2p = 3 이므로 페이지 테이블의 페이지 번호 3번을 가리키며, 따라서 프레임 번호 f는 2이다.
물리주소는 f와 d를 합쳐서 만들 수 있다. f = 2, d = 2 즉, 1 0 0 1이 물리주소가 되고 10진수로 변환하면 9가 된다.
결과적으로 메모리의 9번지에 실제 프로세스의 페이지가 위치하게 된다.
이러한 페이징 방식으로 외부 단편화를 해결할 수 있다. 하지만 페이징은 내부 단편화를 유발한다.
내부 단편화 (Internal Fragmentation)
내부 단편화는 프로세스의 크기가 페이지 크기의 배수가 아니라면, 마지막 페이지는 한 프레임을 다 채울 수 없게 된다. 결국 이렇게 남은 공간은 메모리의 낭비로 이어진다.
프로세스의 크기가 9이고 페이지 크기가 2 bytes라고 하자. 2bytes 2bytes 2bytes 2bytes씩 할당하면 프로세스의 남은 크기는 1bytes이므로 2bytes 짜리 페이지에 넣으면 1bytes가 남게 된다. 결국 이렇게 남은 1bytes 공간은 낭비된다.
내부 단편화는 해결할 방법이 없다. 하지만 그 수준이 최대 페이지 사이즈 - 1이므로 매우 미미하다. 따라서 보통 무시한다.
페이지 테이블 만들기
페이지 테이블을 만드는 방법은 여러 가지가 있다.
CPU 레지스터
먼저 CPU 내부에 있는 여러 개의 레지스터로 페이지 테이블을 만들 수 있다. 장점은 주소 변환의 속도가 빠르다. 하지만 CPU 내부의 레지스터는 한정된 자원이므로 페이지 테이블 크기가 제한된다.
메모리
메모리 내부에서 페이지 테이블을 생성할 수 있다. 장점은 페이지 테이블의 크기를 무제한으로 만들 수 있다. 하지만 주소 변환의 속도가 느리다. 메모리의 페이지 테이블에서 한 번, 실제 주소로 또 한 번 총 2차례에 걸쳐 메모리에 접근해야하므로 속도 역시 2배로 느려진다.
TLB (Translation Look-aside Buffer)
페이지 테이블을 별도의 칩 (SRAM)으로 만들어서 CPU와 메모리 사이에 위치시키는 방법이다. 이렇게 만든 테이블을 TLB라고 한다. 장점은 CPU보다 테이블 크기가 크고 메모리보다 변화 속도가 빠르다. 단점은 CPU보다 변화 속도가 느리고 메모리보다 테이블 크기가 작다.
TLB의 성능은 유효 메모리 접근 시간 (EMAT, Effective Memory Access Time) 을 통해 효율성을 측정할 수 있다.
Tm : 메모리를 읽은 시간.
Tb : TLB를 읽는 시간.
h : TLB에 유효한 페이지 엔트리가 있을 확률.EMAT = h * (Tb + Tm) + (1 - h) * (Tb + Tm + Tm) 로 계산할 수 있다.
가령
Tm : 100ns.
Tb : 20ns.
hit ratio (h) : 80%라고 했을 때 EMAT는 140ns라고 측정할 수 있다.
보호와 공유 (Protection and Sharing)
보호 (Protection)
모든 주소는 페이지 테이블을 경유하므로 페이지 테이블 엔트리마다 몇 가지 비트값을 추가해서 해킹 등을 방지할 수 있다.
추가되는 비트값은 다음과 같다.
R비트 : Read
W비트 : Write
X비트 : Execute비트 값은 1 또는 0으로 나타낼 수 있다. 해당 작업 (Read, Write, Execute)이 가능하면 1, 불가능하면 0으로 설정한다. 따라서 만약 비트가 0으로 꺼져있는데 해당 작업을 시도하면 CPU 인터럽트가 발생하고 ISR로 이동해서 해당 프로세스를 종료한다.
공유 (Sharing)
메모리 낭비를 방지하기 위해 자원을 공유할 수 있다.
같은 프로그램을 쓰는 여러 개의 프로세스가 있다고 하자. 메모리에 탑재된 프로세스는 Code + Data + Stack을 갖고 있는데 여기서 Code는 공유가 가능하다. 단 이때 이 프로세스는 코드가 변하지 않는 프로그램이어야만 한다. 이를 Non-Self Modifying Code, REentrant Code, Pure Code라고 한다. 예를 들어, Process 1, 2가 Code를 공유한다고 할 때, Process 1이 Code를 사용하는 과정에서 Code가 변경된다면, Process 2가 사용하는 시점에서 오류가 발생하거나 동작하지 않을 수 있다.
