
프로그램을 메모리에 올리기
메모리는 기본적으로 주소(Address)와 데이터(Data)로 이루어져 있다.
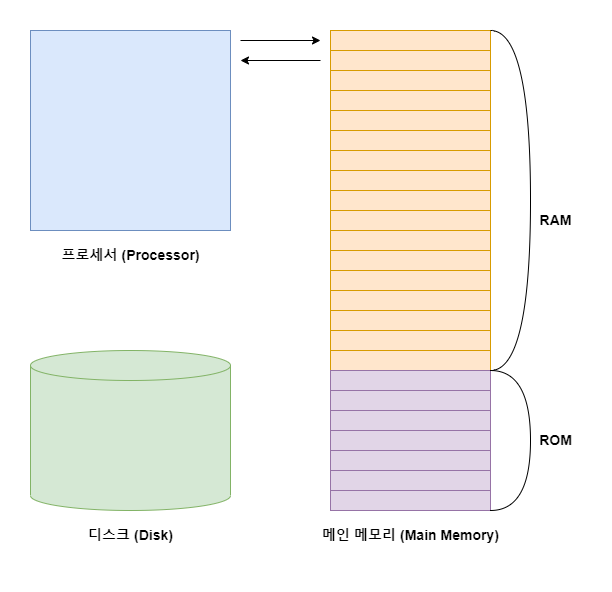
CPU가 읽고자 하는 데이터의 주소를 메모리에게 전달하면, 메모리는 그 주소에 해당하는 데이터를 CPU에게 다시 전달한다.
프로그램 개발 과정
프로그램은 다음과 같은 개발 과정을 밟는다.
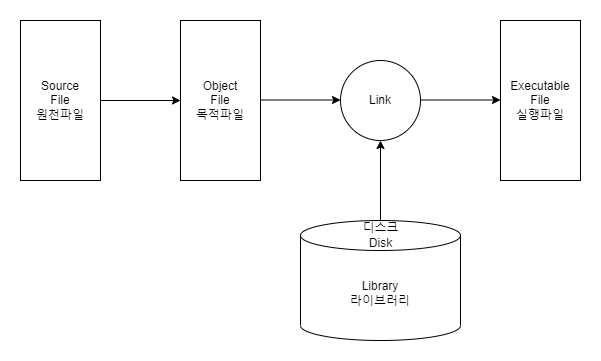
- 원천파일 (Source File) : 고수준언어 또는 어셈블리언어
- 목적파일 (Object File) : 컴파일 또는 어셈블의 결과
- 실행파일 (Executable File) : 링크 결과
- 원천파일은 컴파일러에 의해 Compile되어 목적 파일을 생성한다. 어셈블리어일 경우 어셈블러에 의해 기계어로 변경된다.
- 링크 단계에서 하드디스크로부터 라이브러리를 불러와 추가하여 실행 파일을 생성한다. (Link)
- 실행파일이 실행되면 Loader에 의해 메인 메모리에 할당되면서 실행된다.
이렇게 실행된 프로그램은 Code, Data, Stack 으로 이루어져있다. 프로그램 자체는 Code와 Data로만 이루어져있지만, 이 프로그램이 메인 메모리에 적재되고나서부터는 Stack 영역에 추가된다.
프로그램을 메모리에 올리기
실행 파일을 메모리에 올릴 때 이 파일을 메모리의 몇 번 주소에 넣을지를 결정해야한다. 이때 사용하는 것이 운영체제의 MMU (Memory Management Unit)와 그 안에 있는 재배치 레지스터 (Relocation Register)이다.
PC를 사용하다보면 여러 개의 프로그램이 메모리에 적재되고 내려가고를 반복하는데 어떤 프로그램을 메모리 상에 어느 위치에 배치할 지 결정하는 역할을 재배치 레지스터 (Relocation Register)가 수행한다. 또한 이 과정은 운영체제에서 전부 담당하므로 프로그래머가 신경쓸 일은 없다.
논리주소 vs 물리주소
프로그램이 메모리에 탑재될 때 주소값을 사용한다고 했다. 이 주소값은 2가지로 구별할 수 있
다.
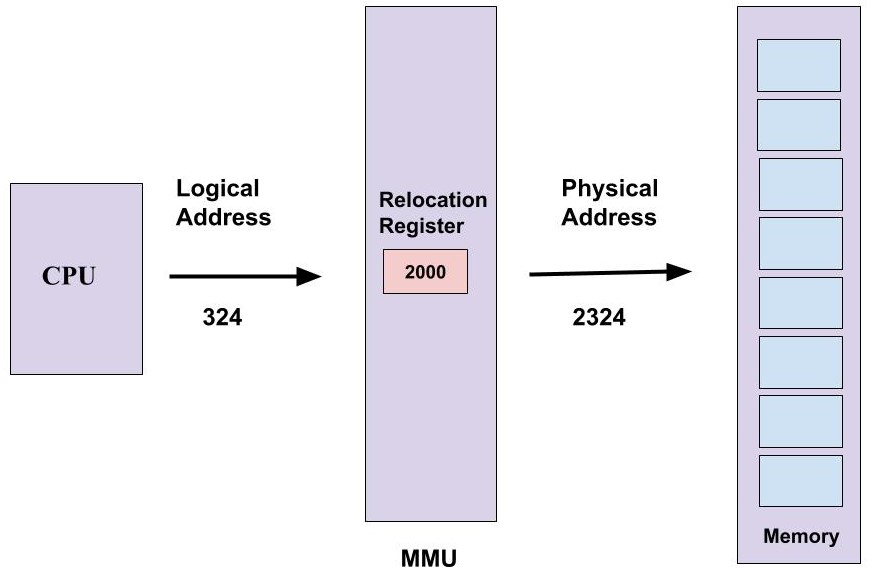
- 논리주소 (Logical Address) : CPU가 사용하는 주소
- 물리주소 (Physical Address) : 메모리가 사용하는 주소
MMU
MMU의 역할을 좀 더 세부적으로 살펴보면 다음과 같다.
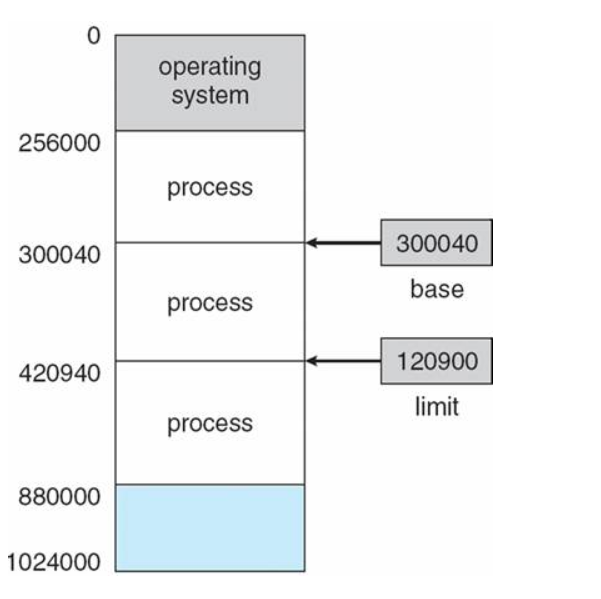
프로세스는 메모리의 특정 주소에 배치된다고 했다. 이때 이 프로세스가 시작하는 주소를 Base, 끝나는 주소를 Limit이라고 한다.
MMU에는 Base Register와 Limit Register가 있는데, 이들은 CPU가 요청한 주소가 Base ~ Limit 안에 있는 주소인지를 검사한다. 만일 이 범위를 벗어나는 요청이라면 MMU는 CPU에게 인터럽트를 보내고, CPU는 하던 작업을 멈추고 OS의 ISR로 점프해서 해당 프로그램을 종료시킨다.
프로그램을 메모리에 탑재할 때, 처음 설계 단계에서 설정한 주소와는 다른 주소로 탑재해야할 경우가 생길 수 있다. 이런 경우 재배치 레지스터는 프로그램의 CPU 주소 (논리주소)를 메모리 주소 (물리주소)로 변환해서 메인 메모리에 탑재한다. (Address Translation 과정)
이렇게하면 CPU는 원래 프로그램에 설정되어있는 주소를 계속해서 사용하는 줄 알고 있지만, 실제로는 MMU의 재배치 레지스터에 의해 다른 주소로 변환해서 사용되고 있는 것이다. 왜냐하면 CPU가 알고 있는 그 위치에는 다른 프로세스가 들어가있을 수도 있으니까.
메모리 낭비 방지
메모리의 공간을 낭비하지 않는 일은 매우 중요하고 여러가지의 방법이 있다.
동적 적재 (Dynamic Loading)
동적 적재는 프로그램 실행에 반드시 필요한 루틴 또는 데이터만 적재하는 방법이다. 프로그램이 갖고 있는 모든 루틴 (Routine)과 데이터 (Data)는 한번에 전부 사용되지 않는다. 필요에 따라 일부가 조금씩 사용되는 경우가 대부분이다. 따라서 동적 적재란 프로그램을 실행할 때 필요한 부분만을 메모리에 올린다.
반대되는 개념으로는 정적 적재 (Static Loading)가 있으며, 모든 루틴과 데이터를 적재하는 것을 의미한다.
현대 운영체제는 대부분 동적 적재를 사용한다.
동적 연결 (Dynamic Linking)
여러 프로그램에서 공통으로 사용되는 라이브러리가 있을 수 있다. 이 프로그램이 메모리에 올라갈 때마다 라이브러리를 같이 올린다면 메모리의 낭비가 심해질 수 있다.
동적 연결은 중복된 라이브러리가 메모리에 올라가는 것을 막기 위해 링크 (Link) 작업을 뒤로 미루고, 오직 하나의 라이브러리만을 메모리에 올린다.
기존에는 실행 파일을 만들기 직전에 Link 단계를 실행했는데, 이를 미뤄서 실행 파일을 메모리에 먼저 올리고, 이미 메모리에 올라가있던 공통 라이브러리와 Link한다.
이처럼 메모리에 미리 올라가있는 라이브러리를 Linux에서는 공유 라이브러리 (Shared Library), Windows에서는 동적 연결 라이브러리 (Dynamic Linking Library)라고 한다.
Swapping
Swapping은 쉽게 말해 사용하지 않는 프로세스를 내리고, 사용할 프로세스를 다시 올리는 방법이다.
메모리에 적재되어있지만 현재 사용하지 않는 프로세를 이미지 형태로 만들고, 이를 하드디스크의 Backing Store ( = Swap Store)로 내려보낸다. 이를 Swap-Out이라고 한다. 반대로 Backing Store에 있던 프로세스 이미지를 다시 메모리로 갖고 오는 과정을 Swap-In이라고 한다.
이때 만약에 프로세스 1을 Swap-Out했다고 하자. 그리고 그 공간에 프로세스 2가 들어와있다고 하자. 한참 뒤에 다시 프로세스 1을 Swap-In하려고 했는데 이미 프로세스 2가 들어와있으면 어떻게될까? 원래는 오류가 발생해야 정상이지만 MMU의 재배치 레지스터로 인해 문제 없이 사용할 수 있다. 실제 메모리 상에는 다른 주소로 배치되지만 CPU는 여전히 같은 주소에 배치되어있다고 착각하기 때문이다.
현재는 프로세스의 크기가 커지고, 하드 디스크는 메인 메모리에 비해 속도가 매우 느리므로 Swapping에 대한 Overhead가 크다. 하지만 Swapping은 매우 중요한 작업이므로 대부분의 운영체제에서 사용되고 있다.
속도가 매우 중요한 서버 혹은 슈퍼 컴퓨터는 더 빠른 저장 장치를 Backing Store로 사용하기도 한다.
연속 메모리 할당 (Contiguous Memory Allocation)
메모리 단편화 (Memory Fragmentation)
예전에는 메모리에 프로세스가 하나만 올라가는 방식이었지만 현재는 메모리에 여러개의 프로세스가 올라가는 다중 프로그래밍 환경이 대부분이다.
다중 프로그래밍 환경에서 부팅 직후 메모리에는 운영체제와 Big Single Hole이 탑재된다. Hole이란 메모리에 비어있는 공간을 의미하며 처음 부팅되면 운영체제 외에는 아무런 프로세스가 올라가지 않아있으므로 이 공간을 Big Single Hole이라고 한다. 이후 프로세스가 생성되고 종료되고를 반복하면서 이 Big Single Hole이 채워지고 비워지고를 반복한다. 이 상태가 지속되면 메모리는 다음과 같이 된다.
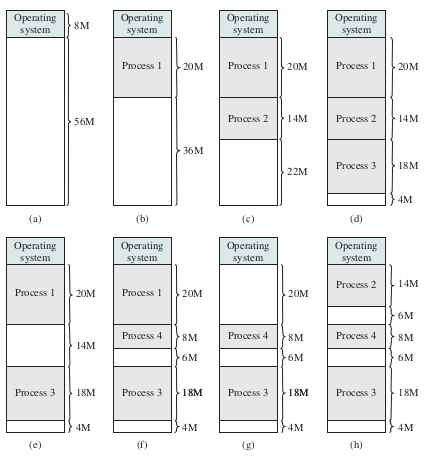
(h)에서 보는 것 처럼 프로세스와 프로세스 사이에 있는 빈 공간이 Hole이며, 이렇게 작은 여러개의 작은 Hole 흩어지듯 분포하게 된다. 이때 작은 Hole들을 Scattered Holes라고 하며, 이 상황 자체를 메모리 단편화 (Memory Fragmentation)라고 한다.
Scattered Holes가 있으면 기본적으로 프로세스의 원할한 적재가 불가능하다. 20M 크기의 프로세스를 올려야하는데 남은 공간이 6M, 4M 이런식으로 남아있기 때문에 넣을 공간이 없기 때문이다. 이러한 현상을 외부 단편화 (External Fragmentation)라고 한다. 메모리의 원할한 사용을 위해서는 당연히 외부 단편화를 최소화해야한다.
연속 메모리 할당
외부 단편화를 최소화 하기 위해 메모리를 할당하는 방법으로는 크게 3가지가 있다.
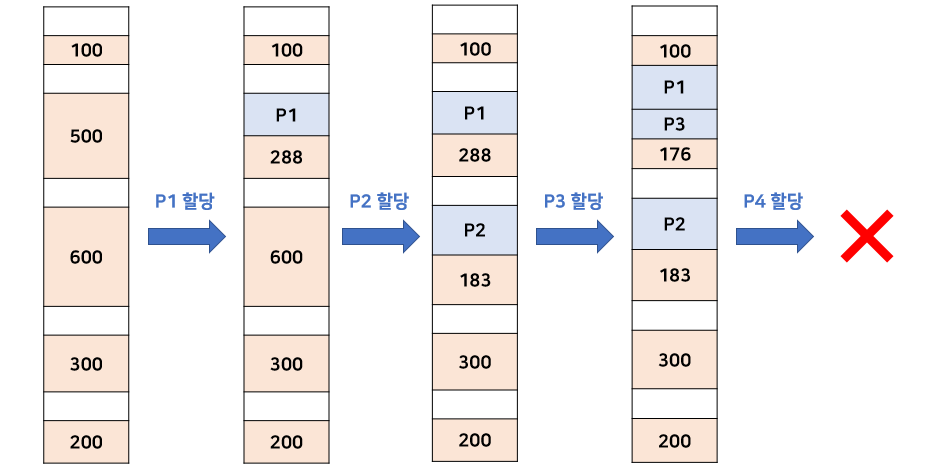
최초 적합 (First-Fit)
할당하고자 하는 프로세스보다 크거나 같은 Hole을 탐색해서 가장 먼저 찾은 Hole에 할당한다. 이때 위에서 아래로 찾던지 아래에서 위로 찾던지 방향은 관계없다.
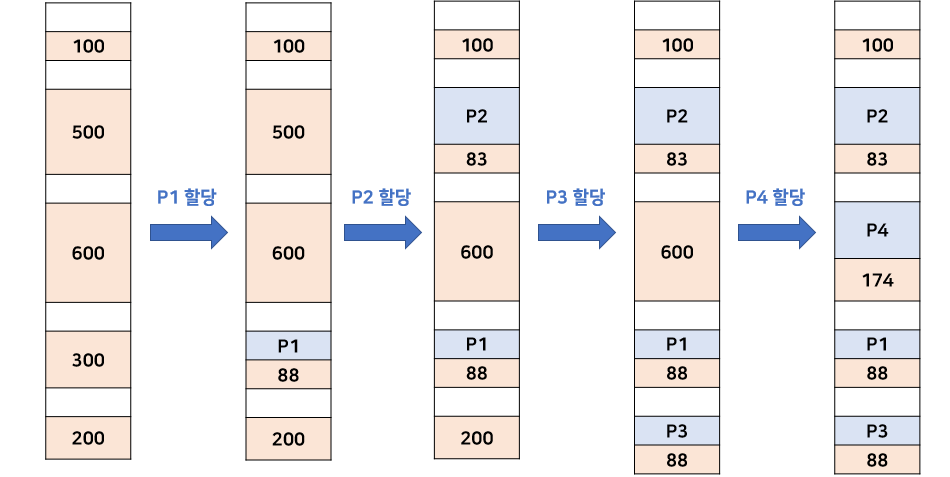
최적 적합 (Best-Fit)
할당하고자 하는 프로세스와 크기가 최대한 같은 Hole에 할당한다. 이때 Hole은 프로세스와 크기가 같아서도 안되고 무조건 커야한다.
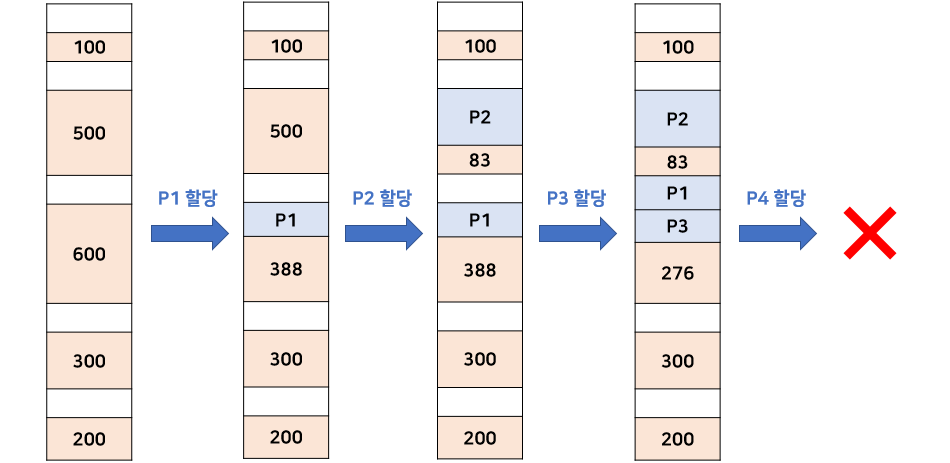
최악 적합 (Worst-Fit)
할당하고자 하는 프로세스와 크기가 제일 많이 차이나는 Hole에 할당한다.
성능 비교
3가지 할당 방식을 속도 및 메모리 이용률에 기반해서 비교해보면 다음과 같다.
속도 면에서는 최초 적합 (First-Fit)이 제일 우세하다.
메모리의 효율적인 이용률에서는 최초 적합 (First-Fit)과 최적 적합 (Best-Fit)이 비슷하게 우세하다.
최악 적합 (Worst-Fit)은 어떤 기준에서도 제일 비효율적이다.
하지만 아무리 효율적인 방식이더라도 외부 단편화를 아예 막는 것은 불가능하고, 이렇게 막지 못한 외부 단편화로 인해 보통 전체 메모리의 1/3 수준이 낭비된다. 이 정도 수준은 메모리 사용이 불가능한 수준이다.
이러한 낭비에 대응하는 또다른 방법은 Compaction이다. Compaction은 여러 곳에 흩어져있는 Hole들을 강제로 하나로 합치는 방법이다. 하지만 메모리에서 Hole들을 이동시키는 것은 Overhead가 굉장히 클 뿐만 아니라 어느 Hole을 어떻게 움직여야 가장 최적의 속도로 합칠 수 있는지 결정하는 최적 알고리즘이 전무하다는 단점이 있다.
