
5. 다양한 자료형 활용하기
데이터베이스에서 자료형(Data Type)이란 저장할 데이터의 유형과 크기를 결정하는 요소입니다.
각 자료형은 숫자, 문자, 날짜/시간 등 다양한 데이터 값을 효과적으로 저장하고 관리할 수 있도록 설계되었습니다.
5.1 자료형이란
5.1.1 자료형의 개념
자료형이란 데이터의 형태를 말하는 것으로, 데이터가 가질 수 있는 값의 종류와 그 값이 메모리에서 차지하는 크기를 정의합니다. 앞서 다룬 INTEGER(정수형), VARCHAR(문자형), DECIMAL(고정 소수점형), DATETIME(날짜와 시간형)은 모두 자료형의 한 종류입니다.
데이터를 저장할 때는 각 데이터의 특성에 맞는 자료형을 지정해야 합니다. 자료형을 잘 선택해야 데이터 저장의 효율성, 데이터 사용의 정확성을 높일 수 있습니다. 데이터베이스에 사용하는 자료형은 크게 숫자형, 문자형, 날짜 및 시간형으로 나뉩니다.
자료형의 주요 역할
- 데이터 크기 지정 (예: INT는 4바이트, VARCHAR(50)은 최대 50자 저장 가능)
- 데이터의 성격 결정 (숫자형, 문자형, 날짜형 등)
- 데이터 처리 방식 최적화 (날짜 연산, 문자열 비교 등)
컴퓨터의 저장 단위와 자료형의 크기
컴퓨터에서 데이터를 저장하는 최소 단위는 1비트(Bit)이며 0 또는 1을 저장합니다. 비트가 8개 모이면 1바이트(Byte)가 되고, 1바이트는 알파벳 한 글자를 저장할 수 있습니다. 바이트가 1,024개 모이면 1킬로바이트(KB), 킬로바이트가 1,024개 모이면 1메가바이트(MB), 메가바이트가 1,024개 모이면 1기가바이트(GB), 기가바이트가 1,024개 모이면 1테라바이트(TB)가 됩니다.
| 단위 | 크기 | 저장 예 |
|---|---|---|
| 비트(Bit) | 1Bit | True 또는 False 저장 |
| 바이트(Byte) | 1Byte (8Bit) | 알파벳 한 개 저장 |
| 킬로바이트(KB) | 1KB (1,024Byte) | 몇 개의 문단 저장 |
| 메가바이트(MB) | 1MB (1,024KB) | 1분 길이의 MP3 파일 저장 |
| 기가바이트(GB) | 1GB (1,024MB) | 30분 가량의 HD 영화 저장 |
| 테라바이트(TB) | 1TB (1,024GB) | 약 200편의 FHD 영화 저장 |
5.1.2 숫자형
숫자형은 숫자를 저장하기 위한 자료형으로 크게 정수형과 실수형이 있습니다.
정수형
정수형은 -2, -1, 0, 1, 2 ...와 같이 소수점이 없는 숫자를 저장합니다. 차지하는 메모리 크기에 따라 TINYINT(타이니인트), SMALLINT(스몰인트), MEDIUMINT(미디엄인트), INTEGER 또는 INT(인티저 또는 인트), BIGINT(빅인트)의 세부 타입이 있습니다.
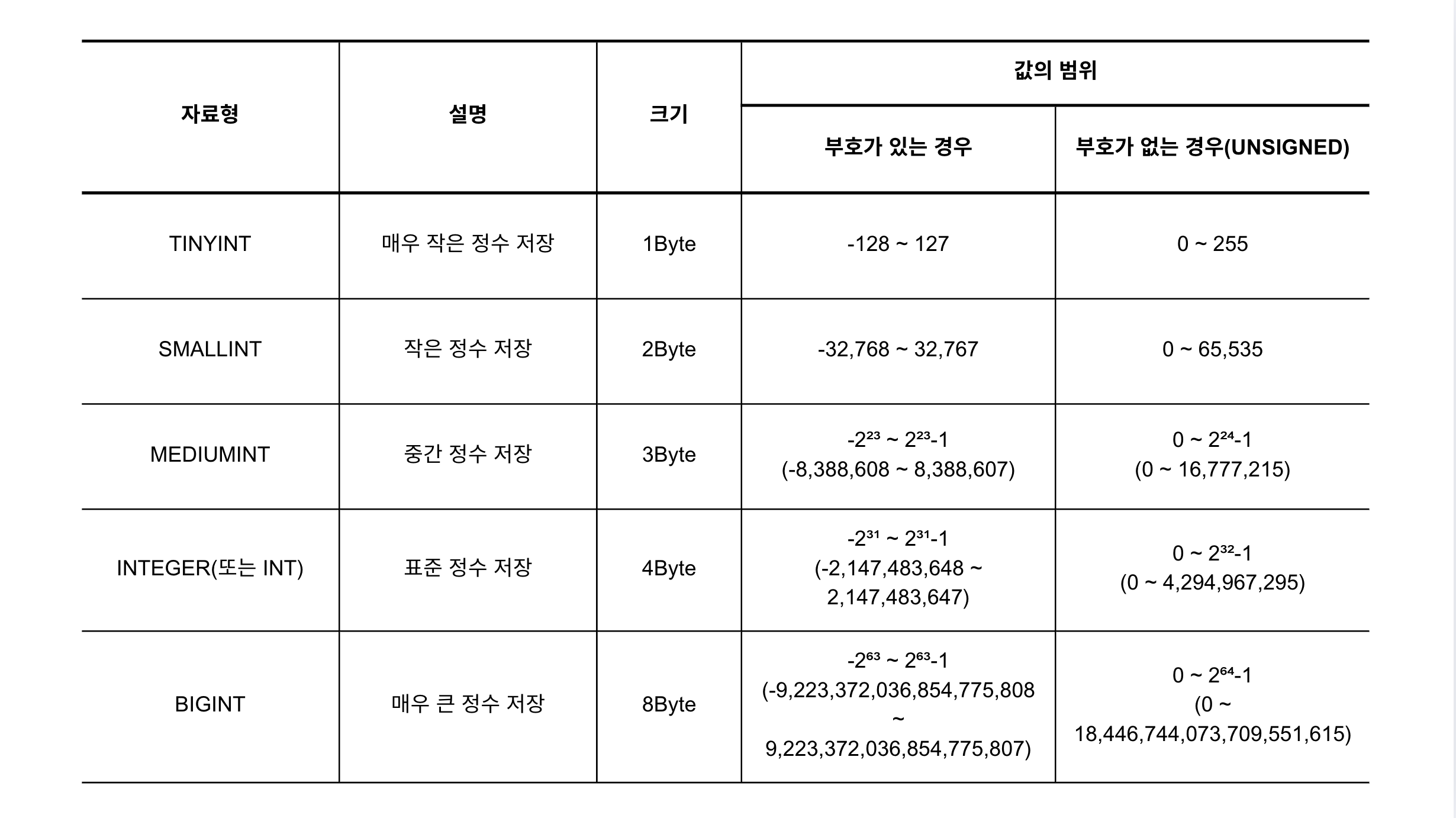
정수형을 선언할 때는 다음과 같이 UNSIGNED(언사인드) 제약 조건을 붙일 수 있습니다. UNSIGNED는 해당 칼럼에 음수 값을 허용하지 않고 0 이상의 정수만 저장하도록 제한하는 기능을 합니다.
형식
CREATE TABLE 테이블명 (
칼럼명 데이터타입 UNSIGNED
);예시
-- 유효성 보장: 나이는 0~255의 유효한 값만 저장
CREATE TABLE users (
age TINYINT UNSIGNED
);
-- 안전성 보장: 재고는 음수가 될 수 없으므로 INTEGER UNSIGNED 사용
CREATE TABLE products (
stock INTEGER UNSIGNED
);UNSIGNED를 사용하면 값의 범위를 0 이상의 정수로 제한할 수 있기 때문에 데이터 유효성과 안정성을 보장합니다.
실수형
실수형은 부동 소수점 방식과 고정 소수점 방식으로 나뉩니다.
실수형: 부동 소수점 방식
부동 소수점 방식은 실수를 저장하되, 소수점의 위치가 변하는 특징이 있습니다. 쉽게 말해서, 부동 소수점(floating point)은 소수점이 '떠다닐 수 있는' 숫자 표현 방식입니다.
예를 들어 1.234, 12.34, 123.4와 같이 소수점의 위치가 다른 세 수를 부동 소수점 방식으로 표현하면 다음과 같습니다. 여기서 x 기호 앞에 있는 수를 '가수', x 기호 뒤에 10의 거듭제곱 횟수를 나타내는 숫자를 '지수'라고 합니다.
- 1.234 → 1.234 x 10⁰ (가수: 1.234, 지수: 0)
- 12.34 → 1.234 x 10¹ (가수: 1.234, 지수: 1)
- 123.4 → 1.234 x 10² (가수: 1.234, 지수: 2)
- 0.01234 → 1.234 x 10⁻² (가수: 1.234, 지수: -2)
예에서 볼 수 있듯 부동 소수점 방식은 모든 수를 소수점 위 한 자리까지만 있는 가수로 바꾼 후 지수를 조정해 숫자를 표현합니다. 이렇게 부동 소수점 방식은 소수점 위치가 고정되지 않은 실수를 저장할 수 있습니다.
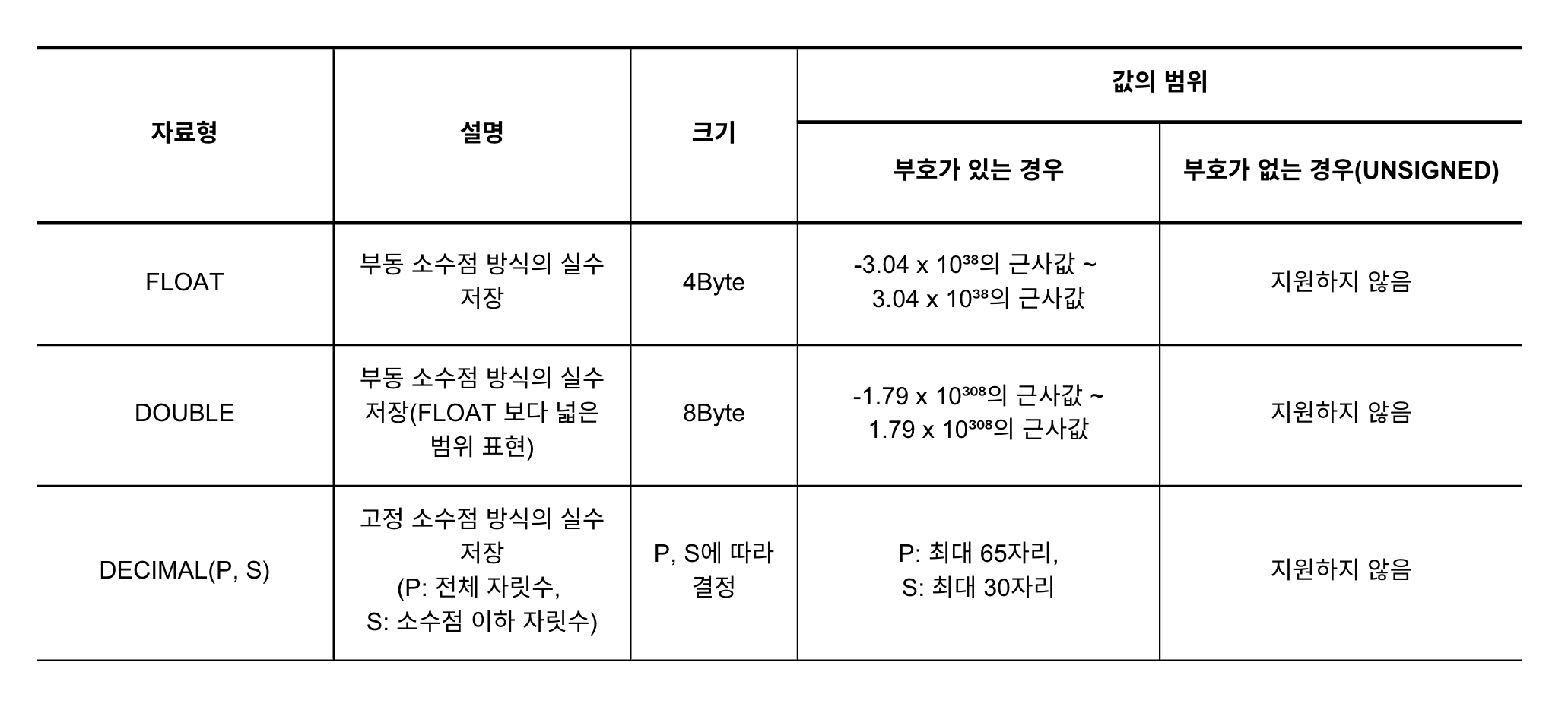
부동 소수점 방식을 사용하는 자료형에는 FLOAT(플로트, 단정밀도), DOUBLE(더블, 배정밀도)이 있습니다.
| 자료형 | 크기 | 유효 자리수 | 예제 |
|---|---|---|---|
| FLOAT | 4바이트 | 약 7자리 | 3.141592 |
| DOUBLE | 8바이트 | 약 15자리 | 3.14159265358979 |
FLOAT은 저장 크기가 작지만, 정밀도가 낮습니다.DOUBLE은 더 정밀하지만 저장 공간을 더 많이 차지합니다.
부동 소수점 방식이 필요한 이유
컴퓨터는 숫자를 2진수(0과 1)로 저장합니다. 정수는 단순히 2진수 변환을 하면 되지만, 실수(소수점이 있는 숫자)를 2진수로 정확하게 표현하는 것은 어렵습니다.
예를 들어, 123.4라는 숫자를 저장한다고 할 때, 소수점의 위치를 그대로 유지하면서 저장하는 것은 어렵습니다. 소수점이 있는 숫자를 저장하기 위해 소수점의 위치를 유지하면서 저장하는 방법이 필요합니다.
이를 해결하기 위해 부동 소수점 방식(floating point) 방식이 사용됩니다. 부동 소수점 방식은 '가수 x 10^지수' 형태로 표현하며, 소수점 위치를 유동적으로 조정할 수 있게 합니다.
부동 소수점 저장 방식
부동 소수점 방식으로 데이터를 저장할 때는 가수, 지수, 부호를 각각 저장하여 소수점이 유동적으로 이동할 수 있도록 합니다.
- 가수: 숫자의 실제 값을 의미하며, 2진수로 변환하여 저장합니다.
- 지수: 소수점의 위치를 저장하며, 2진수로 변환하여 저장합니다.
- 부호: 숫자가 양수인지 음수인지 저장하며, 0(양수), 1(음수)로 저장됩니다.
예제: 10.75를 부동 소수점 방식으로 저장
1. 10진수를 2진수로 변환
10.75(10진수) → 1010.11(2진수)
2. 정규화
부동 소수점 방식에서는 소수점 앞에 항상 1.이 오도록 변환합니다. 1010.11을 정규화하면 다음과 같이 됩니다.
1.01011 x 2³- 가수 = 01011(앞자리는 무조건 1이므로, 저장할 때 중복 저장을 피하고 메모리를 절약하기 위해
1.생략) - 지수 = 3(소수점이 오른쪽으로 3칸 이동)
소수점 왼쪽에 1 하나만 남도록 변환(1.)하는 과정에서 지수가 결정됩니다. 위의 1010.11에서 소수점 왼쪽에 1 하나만 남기 위해서는 소수점을 왼쪽으로 3번 이동해야 합니다. 이때 이동한 횟수인 3이 지수가 됩니다.
3. 지수 변환 및 저장
부동 소수점 방식에서는 지수를 직접 저장하지 않고 바이어스(Bias)를 적용하여 저장합니다. 지수를 부호 없는 형태로 저장하기 위해 바이어스를 더해주는 것입니다.
32비트 IEEE 754 표준에서는 바이어스 값이 127입니다.
3(지수) + 127(바이어스) = 130130(10진수)를 다시 2진수로 변환하여 저장합니다.
130(10진수) → 10000010(2진수)4. 부호 저장
양수는 0, 음수는 1로 저장합니다.
10.75는 양수이므로 부호 비트 = 0을 저장합니다.
5. 최종 저장 형태 (IEEE 754 32비트)
부호(S) | 지수(E) | 가수(M)
------------------------------------------
0 | 10000010 | 01011000000000000000000- 부호(S): 0 (양수)
- 지수(E): 10000010 (10진수 130)
- 가수(M): 01011000000000000000000 (정규화된 2진수,
1.생략)
가수 저장 시 남은 비트를 0으로 채워서 나머지 비트를 확보합니다.
IEEE 754 부동 소수점 표준 정리
IEEE 754는 컴퓨터에서 부동 소수점(소수점이 있는 숫자)을 저장하는 표준 방식입니다.
컴퓨터는 숫자를 2진수(0과 1)로 저장하지만, 실수(소수점이 있는 숫자)를 정확하게 표현하기 어려운 문제가 있습니다. 이를 해결하기 위해 IEEE 754 표준이 만들어졌으며, 단정밀도(32비트, FLOAT)와 배정밀도(64비트, DOUBLE) 방식으로 실수를 저장합니다.
IEEE 754 표준에서는 실수를 부동 소수점 방식으로 표현합니다. 이를 위해 부호(S) + 지수(E) + 가수(M) 형태로 저장합니다.
| 구분 | 단정밀도(32비트) | 배정밀도(64비트) |
|---|---|---|
| 부호(S) | 1비트 | 1비트 |
| 지수(E) | 8비트(바이어스 127) | 11비트(바이어스 1023) |
| 가수(M) | 23비트 | 52비트 |
| 총 비트 수 | 32비트 | 64비트 |
단정밀도와 배정밀도를 비교한 표는 아래와 같습니다.
| 구분 | 단정밀도 (Single Precision, 32비트) | 배정밀도 (Double Precision, 64비트) |
|---|---|---|
| 비트 수 | 32비트 | 64비트 |
| 자료형 (프로그래밍 언어에서 사용) | float | double |
| 메모리 사용량 | 4바이트(32비트) | 8바이트(64비트) |
| 소수점 정밀도 | 약 7자리 | 약 15~16자리 |
| 부호(S) 비트 수 | 1비트 | 1비트 |
| 지수(E) 비트 수 | 8비트 (Bias 127) | 11비트 (Bias 1023) |
| 가수(M) 비트 수 | 23비트 | 52비트 |
| 연산 속도 | 빠름 (32비트 연산 최적화) | 상대적으로 느림 (64비트 연산) |
| 사용 환경 | GPU, 게임, 모바일, 임베디드, 실시간 연산 | 과학 계산, 금융 연산, 정밀한 데이터 처리 |
| 사용 예시 | 그래픽 처리, 머신러닝, 물리 엔진 | 빅데이터 분석, 기후 모델링, 금융 연산 |
실수형: 고정 소수점 방식
고정 소수점 방식은 소수점 이하 자릿수가 고정된 실수를 저장합니다. 소수점 이하 특정 자릿수의 숫자를 정확하게 저장하지 못하는 부동 소수점 방식의 문제를 해결하기 위해 등장했습니다.
고정 소수점 방식은 표현할 수 있는 최대 자릿수를 나타내는 정밀도 P와 소수점 이하 자릿수를 나타내는 스케일 S로 실수를 표현합니다.
형식
DECIMAL(P, S)예시
DECIMAL(5, 2)위의 예시 DECIMAL(5, 2)는 소수점 이하 숫자를 포함해 최대 5자리를 표현할 수 있으며 그중 2자리는 소수점 이하 자리로 사용된다는 의미입니다.
고정 소수점 방식은 전체 자릿수와 소수점 이하 자릿수가 고정돼 있기 때문에 표현할 수 있는 실수의 범위가 제한적입니다. 하지만 정확한 실수 값을 저장할 수 있고 계산 속도도 빨라서 금융 분야처럼 정확히 계산해야 하는 경우에 많이 사용합니다.
부동 소수점 방식과 고정 소수점 방식의 자료형을 정리하면 다음 표와 같습니다. 세 자료형 모두 UNSIGNED 제약 조건은 지원하지 않습니다.
5.1.3 문자형
문자형은 한글, 영어, 기호, 문자화한 숫자 등을 저장하기 위한 자료형으로 CHAR(차), VARCHAR(바차), TEXT(텍스트), BLOB(블롭), ENUM(이넘) 등의 세부 타입이 있습니다.
CHAR와 VARCHAR
CHAR와 VARCHAR는 문자열을 저장하는 대표적인 자료형입니다. 둘의 차이점은 고정 길이 vs 가변 길이입니다.
CHAR (고정 길이 문자)
CHAR는 고정 길이의 문자를 저장하는 자료형으로 지정된 길이만큼의 메모리 공간을 차지합니다.
예를 들어 CHAR(10)은 문자를 10개 담을 수 있는데, 여기에 'aaaa'를 저장하면 고정 길이 10칸을 채우기 위해 aaaa를 저장하고 뒤에 6칸에는 공백으로 채워 aaaa______로 저장합니다. CHAR는 최대 255개 문자를 저장할 수 있으며 자릿수가 고정된 우편번호나 국가 코드 등을 저장하기 좋습니다.
CREATE TABLE users (
country_code CHAR(3) -- 예: 국가 코드 저장 ("USA", "KOR" 등)
);VARCHAR (가변 길이 문자)
VARCHAR는 가변 길이의 문자를 저장하는 자료형으로 실제 입력한 길이만큼만 메모리 공간을 차지합니다.
예를 들어 VARCHAR(500)은 문자를 최대 500개 담을 수 있지만 'a'를 저장하면 메모리는 한 문자를 저장할 수 있는 공간만 할당됩니다. VARCHAR는 문자를 최대 65,535개 저장할 수 있으며 길이가 일정하지 않은 문자열을 저장하기 좋습니다.
CREATE TABLE customers (
name VARCHAR(50) -- 예: 고객 이름 저장
);TEXT (긴 문자열)
TEXT는 긴 문자열을 저장하기 위한 자료형으로 주로 VARCHAR가 저장할 수 있는 문자열보다 더 긴 문자열을 저장할 때 사용합니다.
TEXT는 저장할 수 있는 최대 크기에 따라 TINYTEXT(타이니텍스트), TEXT(텍스트), MEDIUMTEXT(미디엄텍스트), LONGTEXT(롱텍스트)의 세부 타입이 있습니다.
TEXT는 블로그 게시글, 댓글, 리뷰 등 긴 문장을 저장할 때 사용합니다.
| 데이터 타입 | 최대 저장 용량 |
|---|---|
| TINYTEXT | 255바이트 |
| TEXT | 65,535바이트 (64KB) |
| MEDIUMTEXT | 16,777,215바이트 (16MB) |
| LONGTEXT | 4,294,967,295바이트 (4GB) |
예제
CREATE TABLE articles (
title VARCHAR(200), -- 제목 (가변 길이 문자: 최대 200자)
short_description TINYTEXT, -- 짧은 설명 (최대 255Byte)
comments TEXT, -- 댓글 (최대 64KB)
content MEDIUMTEXT, -- 본문 (최대 16MB)
additional_info LONGTEXT -- 추가 정보 (최대 4GB)
);BLOB (대용량 바이너리 데이터)
BLOB(Binary Large Object)은 크기가 큰 파일을 저장하기 위한 자료형으로 이미지, 오디오, 비디오 파일 같은 멀티미디어 데이터를 저장할 때 사용합니다.
최대 저장 범위에 따라 TINYBLOB(타이니블롭), BLOB(블롭), MEDIUMBLOB(미디엄블롭), LONGBLOB(롱블롭)의 세부 타입으로 나뉩니다.
| 데이터 타입 | 최대 저장 용량 |
|---|---|
| TINYBLOB | 255바이트 |
| BLOB | 65,535바이트 (64KB) |
| MEDIUMBLOB | 16,777,215바이트 (16MB) |
| LONGBLOB | 4,294,967,295바이트 (4GB) |
예제
CREATE TABLE images (
id INT PRIMARY KEY,
photo BLOB -- 예: 이미지 데이터 저장
);ENUM (목록형 데이터)
ENUM은 주어진 목록 중 하나만 선택해 입력할 수 있는 자료형입니다.
예를 들어 특정 칼럼의 자료형을 ENUM('bronze', 'silver', 'gold')라고 선언했다면 이 칼럼에는 'bronze', 'silver', 'gold'의 3가지 값만 입력할 수 있습니다. ENUM은 입력 가능한 목록을 제한함으로써 잘못된 입력을 예방할 수 있습니다.
ENUM은 성별, 상태 값, 등급 같은 선택지가 정해진 데이터를 저장할 때 사용됩니다.
예제
CREATE TABLE users (
membership ENUM('bronze', 'silver', 'gold') -- 예: 멤버십 등급 제한
);문자형 데이터 타입 비교 표
| 자료형 | 저장 길이 | 주요 특징 | 사용 예시 |
|---|---|---|---|
| CHAR(n) | 최대 255자 | 고정 길이 (속도 빠름) | 국가 코드, 우편번호 |
| VARCHAR(n) | 최대 65,535자 | 가변 길이 (메모리 절약) | 이름, 이메일 |
| TEXT | 최대 4GB | 긴 문자열 저장 (인덱스 제한) | 게시글, 댓글 |
| BLOB | 최대 4GB | 바이너리 데이터 저장 | 이미지, 오디오, 비디오 |
| ENUM | 최대 65,535개 값 | 정해진 목록 중 하나만 선택 가능 | 성별, 등급 |
5.1.4 날짜 및 시간형
날짜 및 시간형은 말 그대로 날짜와 시간 값을 저장하기 위한 자료형으로 DATE, TIME, DATETIME, YEAR의 세부 타입이 있습니다.
DATE (날짜)
DATE는 날짜를 저장하기 위한 자료형으로, YYYY-MM-DD 형식으로 날짜를 저장합니다. 예를 들어 2019년 3월 20일은 2019-03-20, 2024년 12월 28일은 2024-12-18로 저장합니다.
특징
- 유효 범위: 1000-01-01 ~ 9999-12-31
- 형식: YYYY-MM-DD
- 크기: 3바이트
- 용도: 회원가입 날짜, 생년월일, 계약일 등 날짜 정보 저장
예제
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE
);
INSERT INTO orders (order_id, order_date) VALUES (1, '2025-02-02');
SELECT * FROM orders;TIME (시간)
TIME은 시간을 저장하기 위한 자료형으로, hh:mm:ss 형식으로 시간을 저장합니다. 예를 들어 아침 8시 50분 25초는 08:50:25, 저녁 10시 7분 2초는 22:07:02로 저장합니다.
특징
- 유효 범위: -838:59:59 ~ 838:59:59
- 형식: hh:mm:ss
- 크기: 3바이트
- 용도: 출퇴근 시간, 예약 시간, 특정 이벤트 발생 시간 등 저장
예제
CREATE TABLE work_schedule (
employee_id INT PRIMARY KEY,
work_start TIME,
work_end TIME
);
INSERT INTO work_schedule (employee_id, work_start, work_end)
VALUES (101, '09:00:00', '18:00:00')
SELECT * FROM work schedule;DATETIME (날짜 + 시간)
DATETIME은 날짜와 시간을 함께 저장하기 위한 자료형으로, YYYY-MM-DD hh:mm:ss 형식으로 날짜와 시간을 저장합니다. 예를 들어 2025년 2월 22일 저녁 7시 30분 00초는 2025-02-22 19:30:00으로 저장합니다.
특징
- 유효 범위: 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
- 형식: YYYY-MM-DD hh:mm:ss
- 크기: 8바이트
- 용도: 결제 시간, 예약 일정, 데이터 생성 시간 등 날짜와 시간이 필요한 데이터 저장
예제
CREATE TABLE event_logs (
event_id INT PRIMARY KEY,
event_time DATETIME
);
INSERT INTO event_logs (event_id, event_time)
VALUES (1, '2025-03-13 12:40:34');
SELECT * FROM event_logs;YEAR (연도)
YEAR는 4자리 연도를 저장하기 위한 자료형으로, YYYY 형식으로 연도를 저장합니다. 연도를 알 수 없거나 명시하지 않은 경우를 표현하기 위해 0000도 YEAR로 지정할 수 있습니다.
특징
- 유효 범위: 1901 ~ 2155
- 형식: YYYY
- 크기: 1바이트
- 용도: 자동차 연식, 제품 출시 연도 등 연도 정보 저장
예제
CREATE TABLE car_models (
model_id INT PRIMARY KEY,
model_year YEAR
);
INSERT INTO car_models ()
VALUES ();TIMESTAMP (자동 입력 가능 날짜 + 시간)
TIMESTAMP는 날짜와 시간을 저장하지만, 자동으로 현재 시간을 입력할 수 있는 기능이 있습니다. 형식은 YYYY-MM-DD hh:mm:ss로 저장됩니다.
TIMESTAMP는 기본적으로 현재 시간을 자동 입력할 수 있어 로그 데이터나 시간 기록이 필요한 데이터에 많이 사용됩니다.
특징
- 유효 범위: 1970-01-01 00:00:01 UTC ~ 2038-01-19 03:14:07 UTC
- 형식: YYYY-MM-DD hh:mm:ss
- 크기: 4바이트
- 자동 입력 기능:
DEFAULT CURRENT_TIMESTAMP사용 - 용도: 데이터 생성 시간, 회원가입 시간, 로그 기록 등
예제
CREATE TABLE user_logins (
user_id INT PRIMARY KEY,
login_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO user_logins (user_id) VALUES (1);
SELECT * FROM user_logins;날짜 및 시간형 데이터 타입 비교 표
| 자료형 | 저장 값 | 형식 | 유효 범위 | 바이트 크기 | 특징 |
|---|---|---|---|---|---|
| DATE | 날짜 | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 | 3바이트 | 날짜만 저장 |
| TIME | 시간 | hh:mm:ss | -838:59:59 ~ 838:59:59 | 3바이트 | 시간만 저장 |
| DATETIME | 날짜 + 시간 | YYYY-MM--DD hh:mm:ss | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8바이트 | 날짜와 시간 함께 저장 |
| YEAR | 연도 | YYYY | 1901 ~ 2155 | 1바이트 | 연도만 저장 |
| TIMESTAMP | 날짜 + 시간 | YYYY-MM-DD hh:mm:ss | 1970-01-01 00:00:01 UTC ~ 2038-01-19 03:14:07 UTC | 4바이트 | 자동으로 현재 시간 입력 가능 |
5.2 자료형에 따른 필터링 실습: 상점 DB
5.2.1 데이터셋 만들기
store(상점) DB를 생성하고, orders(주문) 테이블을 생성합니다.
-- store DB 생성 및 진입
CREATE DATABASE store;
USE store;
-- orders 테이블 생성
CREATE TABLE orders (
id INTEGER, -- 아이디(표준 정수)
name VARCHAR(255), -- 상품명(가변 길이 문자: 최대 255자)
price DECIMAL(10, 2), -- 가격(고정 소수점 방식 실수)
quantity INTEGER, -- 주문 수량(표준 정수)
created_at DATETIME, -- 주문 일시(날짜 및 시간형)
PRIMARY KEY (id) -- 기본키 지정: id
);
-- orders 데이터 삽입
INSERT INTO orders (id, name, price, quantity, created_at)
VALUES
(1, '생돌김 50매', 5387.75, 1, '2024-10-24 01:19:44'),
(2, '그릭 요거트 400g, 2개', 7182.25, 2, '2024-10-24 01:19:44'),
(3, '냉장 닭다리살 500g', 6174.50, 1, '2024-10-24 01:19:44'),
(4, '냉장 고추장 제육 1kg', 9765.00, 1, '2024-10-24 01:19:44'),
(5, '결명자차 8g * 18티백', 4092.25, 1, '2024-10-24 01:19:44'),
(6, '올리브 오일 1l', 17990.00, 1, '2024-11-06 22:52:33'),
(7, '두유 950ml, 20개', 35900.12, 1, '2024-11-06 22:52:33'),
(8, '카카오 닙스 1kg', 12674.50, 1, '2024-11-06 22:52:33'),
(9, '손질 삼치살 600g', 9324.75, 1, '2024-11-16 14:55:23'),
(10, '자숙 바지락 260g', 6282.00, 1, '2024-11-16 14:55:23'),
(11, '크리스피 핫도그 400g', 7787.50, 2, '2024-11-16 14:55:23'),
(12, '우유 900ml', 4360.00, 2, '2024-11-16 14:55:23'),
(13, '모둠 해물 800g', 4770.15, 1, '2024-11-28 11:12:09'),
(14, '토마토 케첩 800g', 3120.33, 3, '2024-11-28 11:12:09'),
(15, '계란 30구', 8490.00, 2, '2024-12-11 12:34:56'),
(16, '해물 모듬 5팩 묶음 400g', 9800.50, 4, '2024-12-11 12:34:56'),
(17, '칵테일 새우 900g', 22240.20, 1, '2024-12-11 12:34:56'),
(18, '토마토 케첩 1.43kg', 7680.25, 1, '2024-12-11 12:34:56'),
(19, '국내산 양파 3kg', 5192.00, 1, '2024-12-11 12:34:56'),
(20, '국내산 깐마늘 1kg', 9520.25, 1, '2024-12-11 12:34:56');5.2.2 문자열 필터링하기
상품명에 '케첩'이 포함된 주문을 조회합니다. 칼럼 값에 특정 패턴이 포함됐는지 확인하려면 WHERE 절에 LIKE 연산자를 사용합니다.
name(상품명)에 '케첩'이 포함된 주문은 다음과 같이 조회합니다.
-- name에 '케첩'이 포함된 주문 조회
SELECT *
FROM orders
WHERE name LIKE '%케첩%';LIKE 연산자
LIKE 연산자는 칼럼 값이 특정 패턴과 완전히 일치하거나 특정 패턴을 포함하는지 확인할 때 사용합니다.
SELECT *
FROM
WHERE 칼럼명 LIKE 찾는패턴;와일드 카드
특정 패턴을 찾는 데 사용하는 다음의 기호를 와일드 카드라고 합니다.
- % (퍼센트) 기호: 0개 또는 그 이상의 임의의 문자를 의미합니다.
- _ (언더 스코어): 정확히 1개의 임의의 문자를 의미합니다.
와일드 카드 사용 예
| 와일드 카드 | 사용 예 | 설명 | 결과 예시 |
|---|---|---|---|
| % | LIKE '케첩%' | '케첩'으로 시작하는 임의의 문자 | 케첩 소스, 케첩병 |
| % | LIKE '%케첩' | '케첩'으로 끝나는 임의의 문자 | 토마토 케첩, 꿀케첩 |
| % | LIKE '%케첩%' | 가운데에 '케첩'을 포함하는 임의의 문자 | 케첩 소스, 토마토 케첩, 토메토 케첩 소스, 케첩병, 꿀케첩 |
| _ | LIKE '케첩_' | '케첩'으로 시작하는 3글자 | 케첩병 |
| _ | LIKE '_케첩' | '케첩'으로 끝나는 3글자 | 꿀케첩 |
5.2.3 날짜 필터링하기
11월에 주문받은 상품 개수의 합은 다음과 같이 조회합니다. 이때 날짜 함수를 사용합니다.
-- 11월에 주문받은 상품 개수의 합계
SELECT SUM(quantity)
FROM orders
WHERE MONTH(created_at) = 11;날짜 함수
날짜 함수는 입력받은 날짜 데이터에서 연도, 월, 일을 추출하는 함수입니다. YYYY-MM-DD 형식의 DATE 값 또는 YYYY-MM-DD hh:mm:ss 형식의 DATETIME 값을 입력받아 결과를 반환합니다.
| 함수 | 설명 | 사용 예 | 결과 |
|---|---|---|---|
| YEAR(날짜) | 입력 날짜의 '연도' 추출 | YEAR('2025-01-24') | 2025 |
| MONTH(날짜) | 입력 날짜의 '월' 추출 | MONTH('2025-01-24') | 1 |
| DAY(날짜) | 입력 날짜의 '일' 추출 | DAY('2025-01-24') | 24 |
| EXTRACT(필드 FROM 날짜) → 필드: YEAR, MONTH, HOUR, MINUTE, SECOND | 입력 날짜에서 특정 '필드' 추출 | EXTRACT(YEAR FROM '2025-01-24') | 2025 |
5.2.4 시간 필터링하기
오전에 주문받은 매출의 합계는 다음과 같이 조회합니다. 이때 시간 함수를 사용합니다.
-- 오전에 주문받은 매출의 합계
SELECT SUM(price * quantity)
FROM orders
WHERE HOUR(created_at) < 12;시간 함수
시간 함수는 입력받은 시간 데이터에서 시, 분, 초 등을 추출합니다. hh:mm:ss 형식의 TIME 또는 YYYY-MM-DD hh:mm:ss 형식의 DATETIME 값을 입력받아 결과를 반환합니다.
| 함수 | 설명 | 사용 예 | 결과 |
|---|---|---|---|
| HOUR(시간) | 입력 시간의 '시' 추출 | HOUR('2025-01-24 08:30:45') | 8 |
| MINUTE(시간) | 입력 시간의 '분' 추출 | MINUTE('2025-01-24 08:30:45') | 30 |
| SECOND(시간) | 입력 시간의 '초' 추출 | SECOND('2025-01-24 08:30:45') | 45 |
| TIME_TO_SEC(시간) | 입력 시간의 시, 분, 초를 '초'로 환산 | TIME_TO_SEC('08:30:45') | 30645 |
TIME_TO_SEC()함수는 날짜 데이터가 아닌 시간 데이터만 입력받아야 하므로TIME값만 사용할 수 있습니다.
5.2.5 특정 범위 필터링하기
상품 가격이 10,000원부터 20,000원 사이에 있는 주문은 다음과 같이 조회합니다. 이때 BETWEEN 연산자를 사용합니다.
SELECT *
FROM orders
WHERE price BETWEEN 10000 AND 20000;BETWEEN 연산자
BETWEEN 연산자는 두 값 사이에 속하는지 확인할 때 사용하는 연산자입니다. BETWEEN 연산의 결과, 시작 값과 마지막 값을 포함해 두 값 사이에 속하는 모든 튜플이 필터링됩니다.
형식
SELECT *
FROM 테이블명
WHERE 칼럼명 BETWEEN 시작값 AND 마지막값;BETWEEN 연산자는 날짜 및 시간 자료형에도 사용할 수 있습니다. 예를 들어 2024년 11월 15일부터 2024년 12월 15일까지 받은 주문 개수의 합계는 다음과 같이 구합니다.
-- 2024-11-15 ~ 2024-12-15 사이의 주문 개수의 합계
SELECT COUNT(quantity)
FROM orders
WHERE created_at BETWEEN '2024-11-15' AND '2025-12-15';BETWEEN 연산자는 문자형 데이터에도 사용할 수 있습니다. name(상품명)의 첫 글자가 'ㄱ'으로 시작하는 주문을 찾으려면 BETWEEN 연산자의 시작 값을 'ㄱ', 마지막 값을 '깋'으로 작성하면 됩니다. 그러면 상품명의 첫 글자가 'ㄱ' 부터 '깋' 사이에 있는 모든 주문이 필터링됩니다.
-- 상품명의 첫 글자가 'ㄱ'으로 시작하는 주문 조회
SELECT *
FROM orders
WHERE name BETWEEN 'ㄱ' AND '깋';