4. 데이터 집계하기
4.1 집계 함수란
데이터를 분석할 때 최댓값, 최솟값, 평균, 합계, 개수 등과 같은 통계적인 값이 필요할 때가 많습니다.
이러한 값을 구할 때 SQL의 집계 함수(Aggregate Function)를 사용하면 편리합니다.
4.1.1 집계 함수의 개념
집계 함수란 특정 칼럼 값을 입력받아 통계적 계산을 해 주는 함수로 최댓값, 최솟값, 합계, 평균 등을 구할 때 사용합니다. 집계 함수는 다음 표와 같이 '함수명(칼럼명)' 형태로 사용합니다.
| 집계 함수 | 의미 | 형식 |
|---|---|---|
| MAX() | 최댓값 반환 | SELECT MAX(칼럼명) FROM 테이블명; |
| MIN() | 최솟값 반환 | SELECT MIN(칼럼명) FROM 테이블명; |
| COUNT() | 튜플(행)의 개수 반환 | SELECT COUNT(칼럼명) FROM 테이블명; |
| SUM() | 합계 반환 | SELECT SUM(칼럼명) FROM 테이블명; |
| AVG() | 평균 반환 | SELECT AVG(칼럼명) FROM 테이블명; |
집계 함수 사용 형식
SELECT 함수명(칼럼명) FROM 테이블명;4.1.2 최댓값, 최솟값 구하기
MAX() 함수는 칼럼에서 가장 큰 값(최댓값)을 반환합니다.
MIN() 함수는 칼럼에서 가장 작은 값(최솟값)을 반환합니다.
최댓값, 최솟값 구하기 예제
-- 가장 비싼 버거와 가장 싼 버거의 price 조회
SELECT MAX(price), MIN(price)
FROM burgers;4.1.3 튜플의 개수 세기
COUNT() 함수는 특정 칼럼을 기준으로 전체 튜플(행)의 개수를 반환합니다.
튜플의 개수 세기 예제
-- 무게가 240을 초과하는 버거의 개수 세기
SELECT COUNT(*)
FROM burgers
WHERE gram > 240;COUNT() 함수의 입력값은 *을 넣을 수도 있고, 특정 칼럼명을 넣을 수도 있습니다.
COUNT(칼럼명): 지정된 칼럼에서 NULL 값을 제외한 튜플의 수를 셉니다.COUNT(*): NULL(널) 값을 포함한 전체 튜플의 수를 셉니다.
NULL이란
NULL이란 '데이터가 존재하지 않음'을 나타내는 특별한 값입니다. 이는 0, 빈 문자열(' '), 공백과는 다른 개념으로 아예 값 자체가 존재하지 않음을 뜻합니다.
4.1.4 합계 구하기
SUM() 함수는 특정 칼럼의 모든 값을 더한 합계를 반환합니다. SUM() 함수는 숫자형 칼럼에만 이용할 수 있습니다.
합계 구하기 예제
-- price 합계 구하기
SELECT SUM(price)
FROM burgers;4.1.5 평균 구하기
AVG() 함수는 특정 칼럼의 평균 값을 반환합니다. AVG() 함수는 SUM() 함수와 마찬가지로 숫자형 칼럼에만 사용할 수 있습니다.
평균 구하기 예제
-- price 평균 구하기
SELECT AVG(price)
FROM burgers;4.2 집계 함수 실습: 은행 DB
4.2.1 데이터셋 만들기
bank(은행) DB를 생성하고, transactions(거래) 테이블을 생성합니다.
- id(아이디): 매 거래 건을 구분할 수 있게 붙인 아이디로, 기본키입니다.
- amount(거래 금액): 거래를 통해 오고 간 금액으로, 양수이면 거래처로부터 입금받은 것이고, 음수이면 거래처로 출금한 것입니다.
- msg(거래처): 입출금할 때 남긴 메시지로, 누구와 거래했는지 알 수 있게 거래처가 적혀 있습니다.
- created_at(거래 일시): 거래가 발생한 날짜와 시간입니다.
-- bank DB 생성 및 진입
CREATE DATABASE bank;
USE bank;
-- transactions 테이블 생성
CREATE TABLE transactions (
id INTEGER, -- 아이디
amount DECIMAL(12, 2), -- 거래 금액
msg VARCHAR(15), -- 거래처
created_at DATETIME, -- 거래 일시
PRIMARY KEY (id) -- 기본키 지정: id
);
-- transactions 데이터 삽입
INSERT INTO transactions (id, amount, msg, created_at)
VALUES
(1, -24.20, 'Google', '2024-11-01 10:02:48'),
(2, -36.30, 'Amazon', '2024-11-02 10:01:05'),
(3, 557.13, 'Udemy', '2024-11-10 11:00:09'),
(4, -684.04, 'Bank of America', '2024-11-15 17:30:16'),
(5, 495.71, 'PayPal', '2024-11-26 10:30:20'),
(6, 726.87, 'Google', '2024-11-26 10:31:04'),
(7, 124.71, 'Amazon', '2024-11-26 10:32:02'),
(8, -24.20, 'Google', '2024-12-01 10:00:21'),
(9, -36.30, 'Amazon', '2024-12-02 10:03:43'),
(10, 821.63, 'Udemy', '2024-12-10 11:01:19'),
(11, -837.25, 'Bank of America', '2024-12-14 17:32:54'),
(12, 695.96, 'PayPal', '2024-12-27 10:32:02'),
(13, 947.20, 'Google', '2024-12-28 10:33:40'),
(14, 231.97, 'Amazon', '2024-12-28 10:35:12'),
(15, -24.20, 'Google', '2025-01-03 10:01:20'),
(16, -36.30, 'Amazon', '2025-01-03 10:02:35'),
(17, 1270.87, 'Udemy', '2025-01-10 11:03:55'),
(18, -540.64, 'Bank of America', '2025-01-14 17:33:01'),
(19, 732.33, 'PayPal', '2025-01-25 10:31:21'),
(20, 1328.72, 'Google', '2025-01-26 10:32:45'),
(21, 824.71, 'Amazon', '2025-01-27 10:33:01'),
(22, 182.55, 'Coupang', '2025-01-27 10:33:25'),
(23, -24.20, 'Google', '2025-02-03 10:02:23'),
(24, -36.30, 'Amazon', '2025-02-03 10:02:34'),
(25, -36.30, 'Notion', '2025-02-03 10:04:51'),
(26, 1549.27, 'Udemy', '2025-02-14 11:00:01'),
(27, -480.78, 'Bank of America', '2025-02-14 17:30:12');4.2.2 거래 금액의 합계 구하기
Google과 거래한 금액의 합계를 구합니다.
-- Google과 거래한 금액의 합계 구하기
SELECT SUM(amount)
FROM transactions
WHERE msg = 'Google';4.2.3 거래 금액의 최댓값/최솟값 구하기
PayPal과 거래한 내역 중 가장 큰 거래 금액과 가장 작은 거래 금액을 찾습니다.
-- PayPal과 거래한 금액의 최댓값/최솟값 구하기
SELECT MAX(amount), MIN(amount)
FROM transactions
WHERE msg = 'PayPal';4.2.4 거래 횟수 세기
Coupang 및 Amazon과 거래한 총 횟수를 구합니다.
-- Coupang 및 Amazon과 거래한 횟수 세기
SELECT COUNT(*)
FROM transactions
WHERE msg = 'Coupang' OR msg = 'Amazon';또는
-- Coupang 및 Amazon과 거래한 횟수 세기
-- IN 연산자 사용
SELECT COUNT(*)
FROM transactions
WHERE msg IN ('Coupang', 'Amazon');IN 연산자
앞의 쿼리에서 거래처가 'Coupang' 또는 'Amazon'인 튜플을 찾기 위해 OR 연산자를 사용했습니다. 이 경우 OR 연산자 대신 IN 연산자를 사용할 수도 있습니다.
IN 연산자는 어떤 칼럼의 값이 주어진 목록 중 하나에 해당하는지 찾아줍니다.
-- OR 연산자: 칼럼A가 값1이거나 값2인 튜플 필터링
WHERE 칼럼A = 값1 OR 칼럼A = 값2;
-- IN 연산자: 칼럼A가 (값1, 값2) 목록 값 중 하나에 해당하는 튜플 필터링
WHERE 칼럼A IN (값1, 값2);4.2.5 입금 금액의 평균 구하기
Google 및 Amazon에서 입금받은 금액의 평균을 구합니다. 거래처로부터 입금받은 금액은 양수이므로 이를 고려하여 조건을 설정합니다.
-- Google 및 Amazon에서 입금받은 금액의 평균 구하기
SELECT AVG(amount)
FROM transactions
WHERE msg IN ('Google', 'Amazon') AND amount > 0;4.2.6 거래처 목록 조회하기
거래처 목록을 조회합니다. 조회에서 중복을 제거하고 유일한 값만 남기고 싶을 때는 DISTINCT 키워드를 사용합니다.
DISTINCT 키워드: 중복 제거
DISTINCT 키워드는 쿼리 실행 결과에서 중복된 값을 제거하고 고유한 값만 반환할 때 사용합니다.
SELECT DISTINCT 칼럼명
FROM 테이블명예제: DISTINCT 키워드 미사용
-- 이 쿼리를 실행하면 중복을 포함한 모든 칼럼이 조회됩니다.
SELECT msg
FROM transactions;
DISTINCT 키워드 사용
-- 중복을 제거한 msg 목록 조회
SELECT DISTINCT msg
FROM transactions;
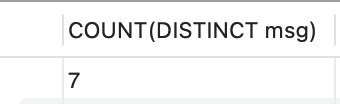
만약 거래처 목록을 조회하는 것이 아니라 거래처 목록의 수를 세고 싶다면, 다음과 같이 COUNT() 함수와 DISTINCT 키워드를 조합하면 됩니다.
-- 중복을 제거한 msg 수 세기
SELECT COUNT(DISTINCT msg)
FROM transactions;