업데이트 2020.05.06 queue url 추가
알고리즘이란이라는게 input 에 의해서 output 이 return 되는데 그 과정에서 효율적으로 작업하기 위해서 Data Structure 가 필요합니다.
전처리는 Data Structure 에 의해 전처리가 되고 그 전처리 된것이 input 에 들어가게 됩니다.
Typical Data Structure
- List(Array) Based Structure
- List- Stack
- Queue
- Deque
- Hash table
- Linked List Based Structure
- Signle(Double) Linked List- Tree
- Heap
자료구조란 ??
데이터에 편리하게 접근하고 , 변경하기 위해서 데이터를 저장하거나 조직하는 방법을 말한다.
모든 목적에 맞는 자료구조는 존재하지 않는다 .
따라서 자료구조가 갖는 장점과 한계를 아는것이 중요하다 .
자료구조는 언어별로 지원하는 양상이 다르다 . 따라서 각각의 언어가 가진 자료구조의 사용방법도 중요하지만 ,
무엇보다 각 자료구조의 본질과 컨셉을 이해하는것이 중요하다 .
왜 자료구조를 써야하는가 ??
만약 우리가 볼펜 하나를 챙긴다고 하면
큰 케리어가 필요할 필요가 없다.
물론 볼펜 하나는 케리어에 담으면 담기긴 하지만 ,
비효율적이다 .
간단하게 주머니에 넣거나 작은 가방을 넣으면 된다.
그래서 상황에 맞게 적절한 가방을 사용해야한다 .
자료구조도 똑같다 .
알맞는 데이터에 넣어서 관리를 하는것이다 .
노트북을 쇼핑백에 넣는거랑 백팩에 넣는것도 천지차이잖아 ?? 그치 ??
자료구조의 종류
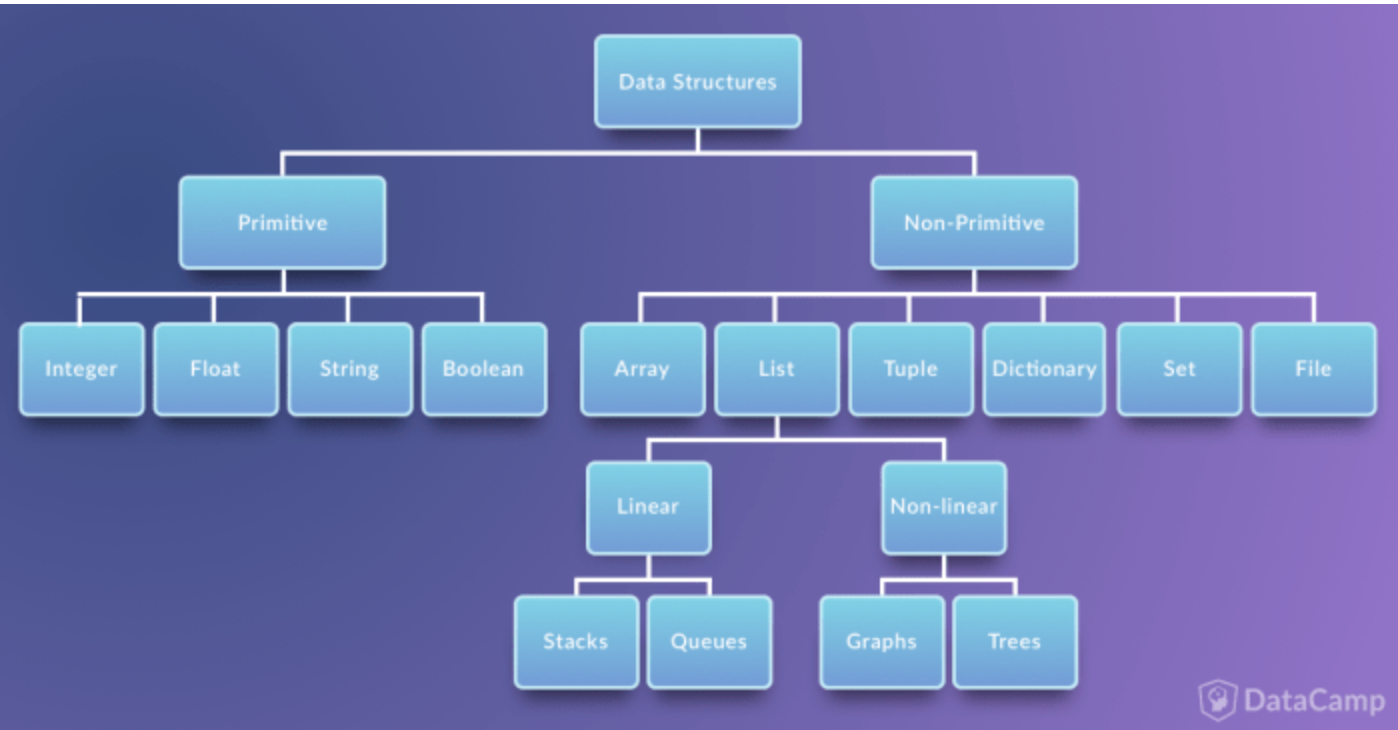
이 그림중에서 Non-Primitive 를 자료구조라고 한다.
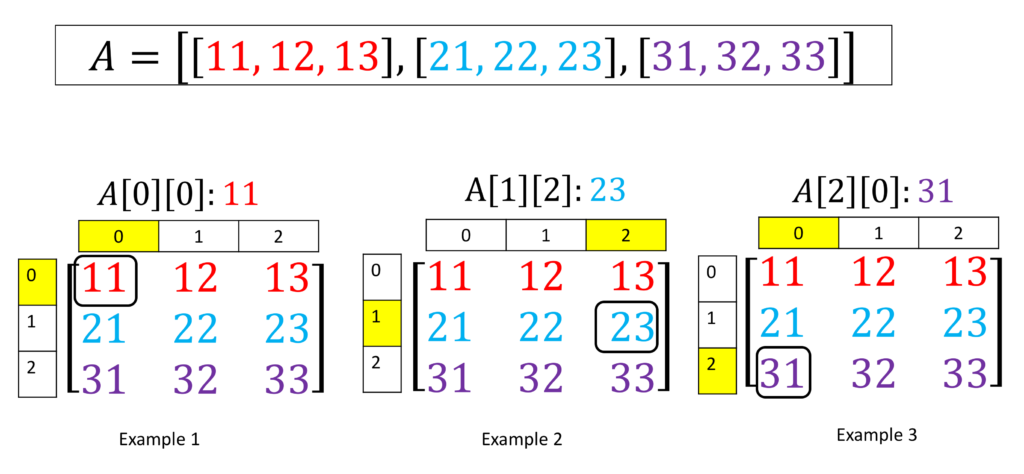
1. array or list
순서가 있는 자료구조다
순서가 있으니 index 가 존재한다 .
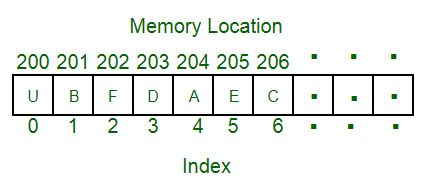
- 삽입(insertion) 순서대로 저장된다. (즉 , 새로 삽입되는 요소는 array 의 새로운 꼬리가 된다 . )
- 이미 생성된 리스트도 수정 가능하다. (mutable)
- 동일한 값도 여러번 삽입 가능하다.
위와 같은 사진은
Multi Dimentional Array 이다 .
위와같이 2차원 리스트가 많이 사용된다 .
단점
앞서 본대로 array 는 메모리의 실제 주소도 순차적으로 되어있습니다.
그럼으로 indexing 이 가능한 것을 비롯하여 여러 장점이 있지만 반대로 단점도 있다.
Removing Elements
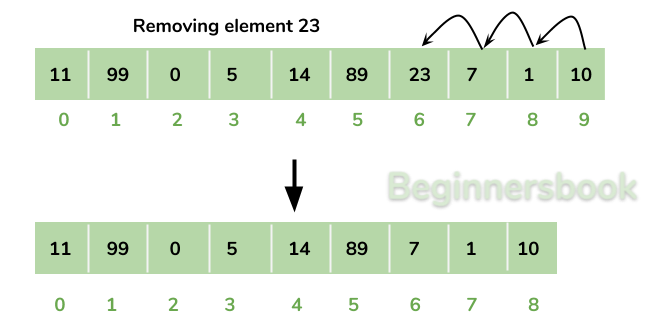
이러한 문제들이 있지만
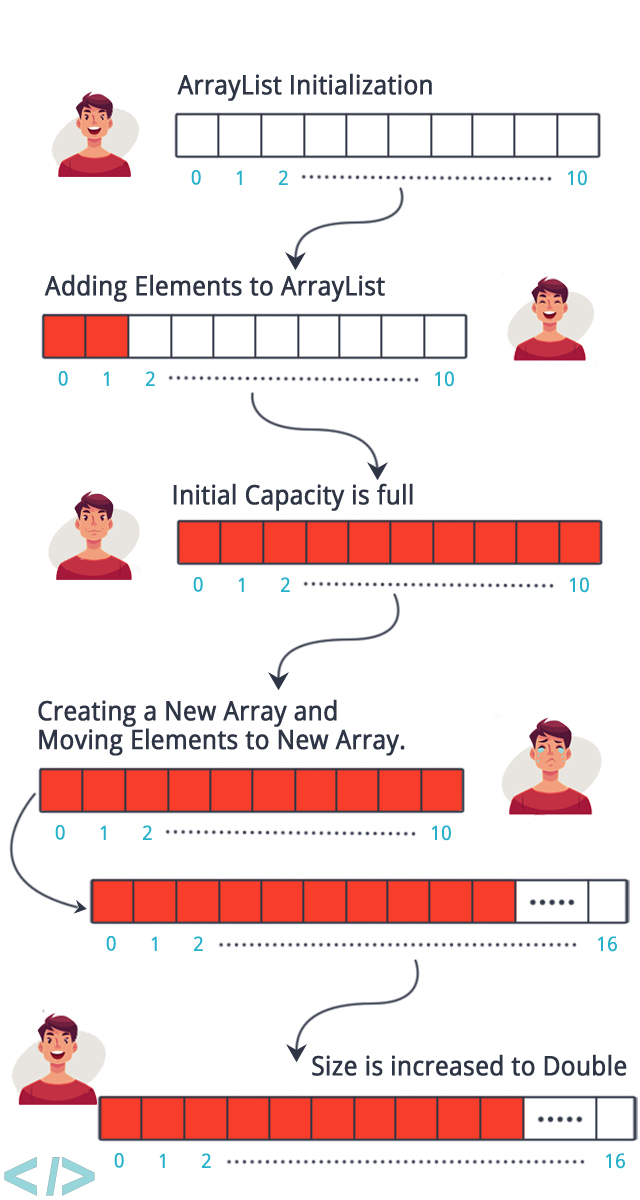
가장 큰 문제점은 array Resizing 이 가장 큰 문제이다 .
list 는 처음 생성될때 어느정도 미리 할당해 놓는다 .
그러니 사이즈가 잘 예측이 안될경우는 list 를 사용하게 되면 안좋다.
tuple
list 와 마찬가지로 데이터를 순차적으로 저장할 수 있는 순열 구조이다 .
하지만 list 와 틀리게 수정할 수없다 (immutable)
주로 2나 3개 정도의 소규모 데이터를 저장할 때 쓰인다.
tuple 은 간단한 값들을 빨리 표현하고 싶을때 많이 사용한다.
set
set 은 array 나 list 처럼 순열 자료구조 이다 .
하지만 set 은 순서라는 개념이 존재하지 않는다.
- 데이터를 비 순차적으로 저장 할 수 있는 순열 자료구조이다.
- 삽입 순서대로 저장되지 않는다 . 즉 특정한 순서를 기대할 수 없는 자료구조
- 수정 가능하다
- 동일한 값을 여러번 삽입 불가능하다 .동일한 값이 여러번 삽입 되면 하나의 값만 저장된다.
- Fast Lookup 이 필요할때 주로 쓰인다.
>>> my_set = {1, 2, 3, 4, 5, 1, 2}
>>> my_set
{1, 2, 3, 4, 5}
>>> for i in my_set:
... print(i)
...
1
2
3
4
5
>>> my_set.append(7)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'set' object has no attribute 'append'
>>> my_set[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
>>> my_set.add(7)
>>> my_set
{1, 2, 3, 4, 5, 7}
>>>
>>> 5 in my_set # look up
True
array 와 달리 set 은 요소들을 순차적으로 저장하지 않는다 .
set 에서 요소들이 저장될 때 순서는 다음과 같다.
- 저장할 요소의 값의 hash 값을 구한다.
- 해쉬값에 해당하는 공간에 값을 저장한다.
이렇게 set 은 저장하고자 하는 값의 해쉬값에 해당하는 bucket 에 값을 저장하기 때문에 순서가 없다. 순서가 없기때문에 indexing 도 없다.
set 은 언제사용해야하나 ?
- 중복된 값을 골라내야 할때
- 빠른 look up 을 해야 할때
- 그러면서 순서는 상관 없을때
hash 는 단방향 암호화 이다 . 단방향이란 한번 암호화 하면 복호화가 안된다는 뜻인데 , 실제 값의 길이와 상관없이 hash 값을 일정한 길이를 가진다. 그럼으로 Hash 는 주로 임의의 길이를 갖는 임의의 데이터에 대해 고정된 길이의 데이터로 매핑할 때 사용한다.
딕셔너리 / 해시맵 / 해시테이블
딕셔너리(다른 언어에서는 hashmap 이나 hash table 이라고 하기도 함) 는
key-value 형태의 값을 저장할 수 있는 자료구조이다 .
이름은 정우성 등 실제 데이터 값과 데이터를 설명하는 key 의 대응 관계를 표현할때 유용하다
예를들어 Json 을 사용하게 될때 주로 사용한다.
딕셔너리 의 특성은 다음과 같다 .
-
set 과 마찬가지로 특정 순서대로 데이터를 리턴하지 않는다.
-
key 의 값은 중복 될 수 없다. 만일 중복된 key 가 있으면 먼저 있던 key 와 value 를 대체한다.
-
수정 가능하다 (mutable)
>>> my_dict = {1 : "one", "two" : 2, 3 : 3.0, 1: "one_one"}
>>> my_dict
{1: 'one_one', 'two': 2, 3: 3.0}
>>> for key, value in my_dict.items():
... print(f"{key} : {value}")
...
1 : one_one
two : 2
3 : 3.0
>>> my_dict[1]
'one_one'
>>> my_dict.get("two")
2
>>> my_dict[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 5
>>> my_dict.get(5, 0)
0
>>> my_dict[7] = "Seven"
>>> my_dict
{1: 'one_one', 'two': 2, 3: 3.0, 7: 'Seven'}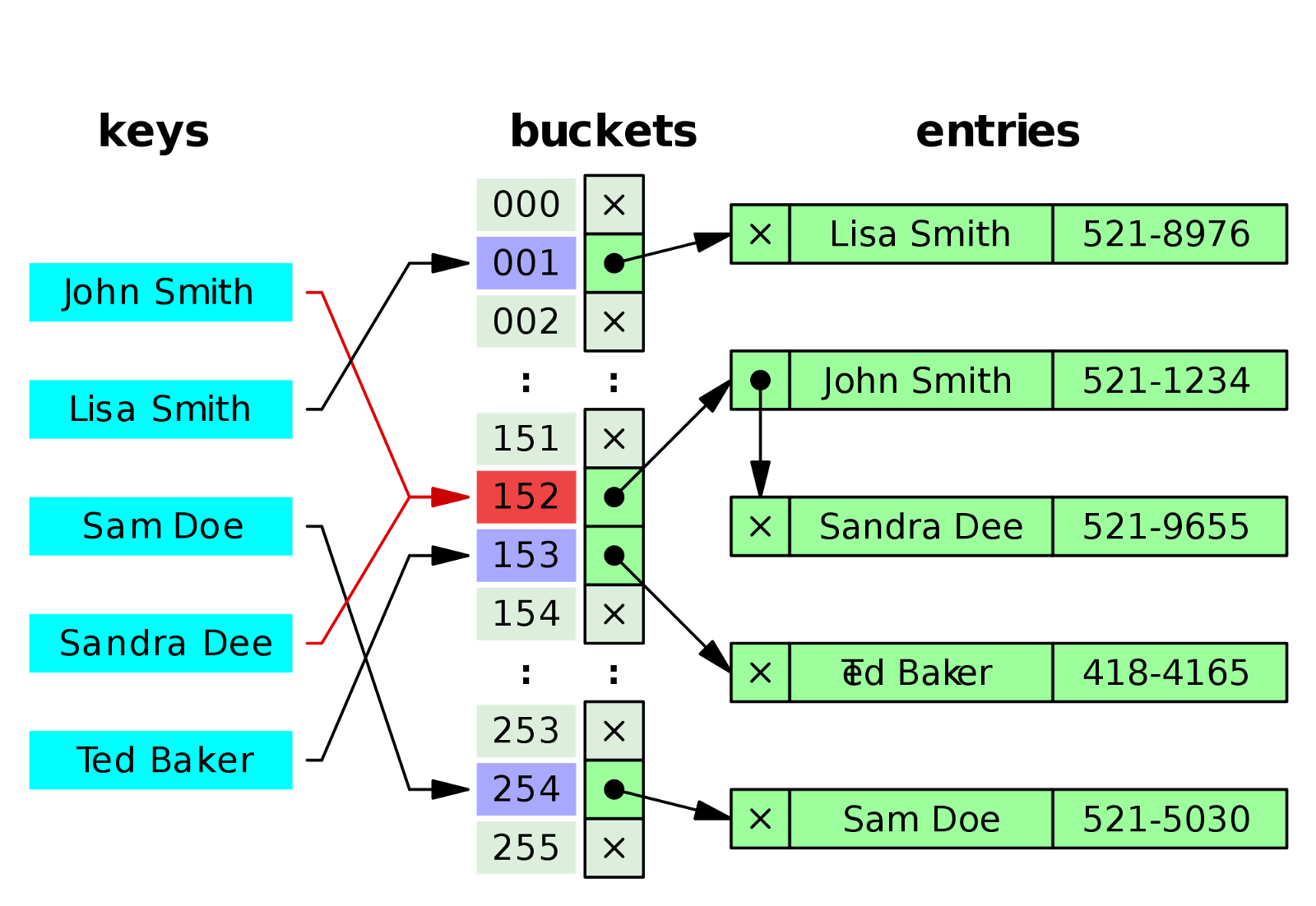
set 와 비슷하게 key 값의 해쉬값을 구한 후 해쉬값에 속해있는 bucket에 값을 저장한다.
그럼으로 set 와 마찬가지로 순서가 없고 중복된 key 값은 허용 되지 않는다.
딕셔너리는 언제사용하나 ?
마치 데이터베이스 처럼 키와 값을 묶어서 데이터를 표현해야 할때 유용하다 .
실제로 데이터베이스에서 읽어들인 값을 딕셔너리로 변환해서 사용 자주함
Stack & Queue
Stack 과 Queue 는 비슷한 구조인데 , 자료를 읽어들이는 순서가 틀린다.
Stack 에서 데이터 저장은 push 라고 한다.
데이터를 읽어들이는 건 pop 이라고 한다.
다만 pop 은 읽어들임과 동시에 stack 에서 삭제가 된다.
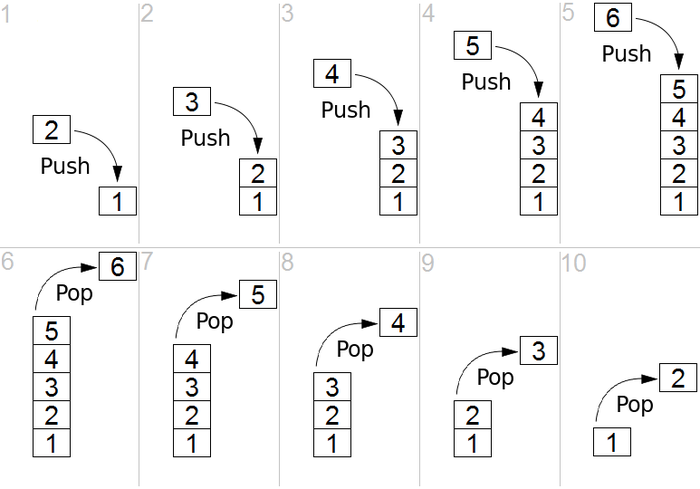
Stack 은 밑단에 array 를 사용한다 .
그런데 거기에 약간의 로직을 더해진다.
언제 stack 을 사용하나 ?
-
프로그램에서 함수 호출 기록을 stack 으로 저장한다.
그래서 StackOverflow 에러 라는거솓 있는거다 . -
Web brower 내역 혹 등 내역인데 최신 내역이 먼저 나와야 하는 경우
Queue
queue 는 Stack 과 반대로 FIFO(First in First Out) 이다 .
즉 먼저 push 된게 먼저 pop 된다는 말이다.
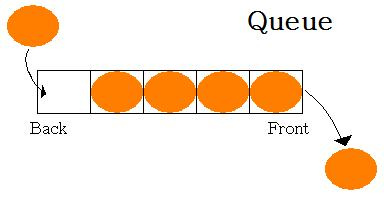
일반적인 queue 말고도 double ended queue , priority queue 등도 있다 .
줄서기를 생각해보면 먼저 줄은 서서 기다린 사람이 먼저 식당에 들어가야한다.
priority queue 는 머지 ??
http://www.daleseo.com/python-priority-queue/
https://docs.python.org/ko/3.7/library/queue.html
언제 Queue 를 사용하나 ?
- 맛집 예약 시스템
- OS 프로세스 스케쥴링 시스템
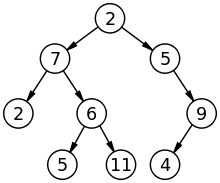
Tree
Tree 자료구조는 데이터를 마치 나무(거꾸로된) 형태로 저장하는 자료구조이다.
Tree 자료구조는 여러 유형이 있지만 , 그중 가장 기본은 binary tree(이즌트리) 자료구조이다 .
이진 트리는 두개의 자식 노드를 가진 트리 형태이다.
주로 효과적으로 탐색 하기 위해서 사용된다.
이진트리는 앞서 언급한대로 각 노드가 최대 2개의 자식 노드를 가질 수 있다 .
이 2개의 노드를 left node 그리고 right node 라고 한다.
left node 는 부모 node 의 값 보다 적은 값이 저장되고 right node 는 같거나 큰 값을 저장한다 .
마지막 정리
1 . 리스트와 set 차이
리스트는 순서가 있고 set 은 순서가 없다.
리스트는 그래서 index 가 있고 slicing 같은것도 할 수있다.
set 은 중복 허용이 안된다.
-
stack 순서대로 쌓는다
-
queue 는 먼저온것이 나간다.
-
tree 는 오른 쪽 왼쪽 으로 이진트리로 나눈다 .