📌정렬
정렬 알고리즘은 순서가 없던 데이터를 순서대로 바꾸어 나열하는 알고리즘입니다.
- 선택정렬
- 삽입정렬
- 병합정렬
- 퀵정렬
👉Selection Sort(선택정렬)
선택정렬은 정렬되지 않은 데이터 중 가장 작은 데이터를 선택해서 맨 앞에서부터 순서대로 정렬해 나가는
알고리즘입니다.
- 주어진 데이터 중 , 최소값을 찾음
- 해당 최소값을 데이터 맨 앞에 위치한 값과 교체함
- 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함
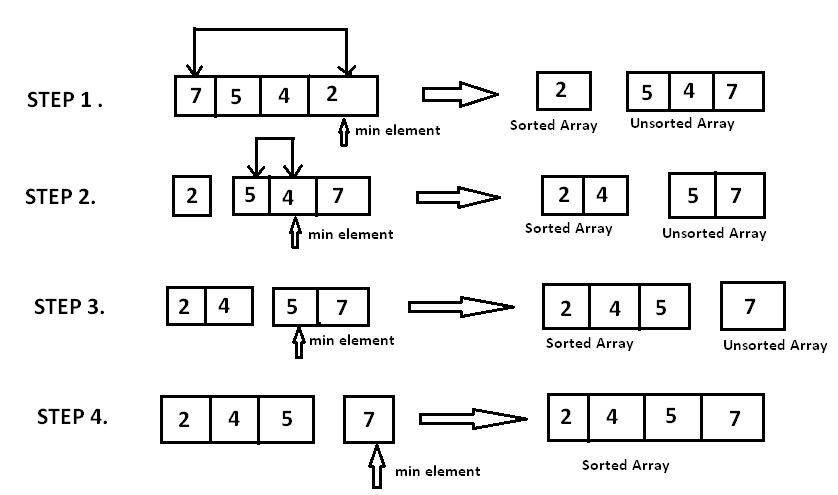
정렬을 해야하는 배열은 [7,5,4,2] 입니다.
첫 번째 loop에서는 index 0부터 3까지 확인하며 가장 작은 수를 찾습니다.
2 이므로 index 0의 7과 교체합니다. -> [2,5,4,7]
두 번째는 index 1부터 3까지 확인하며 가장 작은 수를 찾습니다.
4이므로 index 1의 5와 교체합니다 -> [2,4,5,7]
세 번째는 index 2부터 3까지.. 이런식으로 가장 작은 수를 선택해서 순서대로 교체하는 것을 선택정렬이라고 합니다.
참고자료
https//visualgo.net/en/sorting
def selection_sort(data):
for stand in range(len(data) - 1):
lowest = stand
for index in range(stand+1 , len(data)):
if data[lowest] > data[index]:
lowest = index
data[lowest] , data[stand] = data[stand] , data[lowest]
return data
import random
data_list = random.sample(range(100) , 10)
print(selection_sort(data_list))👉삽입정렬
삽입 정렬은 모든 요소를 앞에서부터 정렬 범위를 확장시켜나가며 , 정렬을 진행한다.
차례대로 이미 정렬된 배열 부분과 확장된 범위 부분을 비교하며 , 자신의 위치를 찾아 삽입함으로써 정렬을 완성시키는 알고리즘

array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def insertion_sort(arr):
for end in range(1 , len(arr)):
for i in range(end , 0 ,-1):
if arr[i-1] > arr[i]:
arr[i] , arr[i-1] = arr[i-1] , arr[i]
return arr
print(insertion_sort(array))
👉병합 정렬
병합 정렬은 분할 정복 의 진수를 보여주는 알고리즘이다.
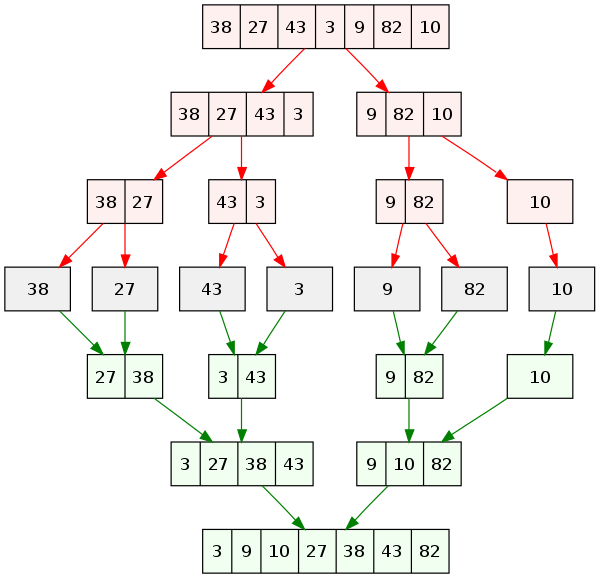
대부분의 경우 퀵 정렬보다는 느리지만 일정한 실행 속도뿐만 아니라 무엇보다도 안정적인 정렬 이라는 점에서 여전히 상용 라이브러리에 많이 쓰이고 있다.
우선 분할 부터 먼저하고 분할이 끝나면 정렬하면서 정복해 나간다.
arr = [1, 5, 3, 4, 2, 88, 4, 7, -1, 0]
def merge(left, right):
i = 0
j = 0
sorted_list = []
while i < len(left) and j < len(right):
if left[i] < right[j]:
sorted_list.append(left[i])
i = i+1
else:
sorted_list.append(right[j])
j = j+1
while i < len(left):
sorted_list.append(left[i])
i = i+1
while j < len(right):
sorted_list.append(right[j])
j = j+1
return sorted_list
def merge_sort(unsorted_list):
n = len(unsorted_list)
if n <= 1:
return unsorted_list
else:
mid = n // 2
left = merge_sort(unsorted_list[:mid])
right = merge_sort(unsorted_list[mid:])
return merge(left, right)
print(merge_sort(arr))
# [-1, 0, 1, 2, 3, 4, 4, 5, 7, 88] 👉퀵 정렬 (quick sort)
퀵 정렬은 병합 정렬과 마찬가지로 분할 정복 알고리즘이며 ,
pivot 을 기준으로 좌우를 나누는 특징 때문에 파티션 교환 정렬 이라고도 한다.
pivot 보다 작으면 왼쪽 , 크면 오른쪽과 같은 방식으로 파티셔닝 하면서 쪼개 나간다.
