https://www.youtube.com/watch?v=y-0DZ1MFN1g
컴퓨터에 저장된 모든 내용은 결국 숫자이다.
메모리나 파일시스템이 결과적으로 2진수이니깐
그 2진수를 저장된 것을 어떻게 해석의 문제이다.
각 숫자에 대한 의미에 따라 해석을 해서 , 출력되는것이다.
우리가 식당에 갔는데 , 룸이 있는 식당이 존재한다.
룸마다 고유한 번호가 있다.. 1 2 3 4 ... 이렇게 있다고 하면
룸에는 손님들이 주문을 했을때 우리는 이 번호를 찾아서 아~ 어느방에 무슨 주문을했구나
바로 알수가 있다. 하지만 만약에 이렇게 번호( key ) 가 없다면
우리는 룸을 다 열어봐서 누가 주문을 했는지 다 찾아봐야 할 것이다.
그래서 속도가 빨라진다. O(1)
해시 테이블은 키와 밸류를 기반으로 데이터를 저장한다.
python 에서는 딕셔너리가 key-value 형태의 값을 저장할 수 있는 자료구조이다.
-
set 과 마찬가지로 특정 순서대로 데이터를 리턴하지 않는다.
-
key 의 값은 중복 될 수 없다. 만일 중복된 key 가 있으면 먼저있던 key 와 value 를 대체한다.
-
수정 가능하다 ( mutable )
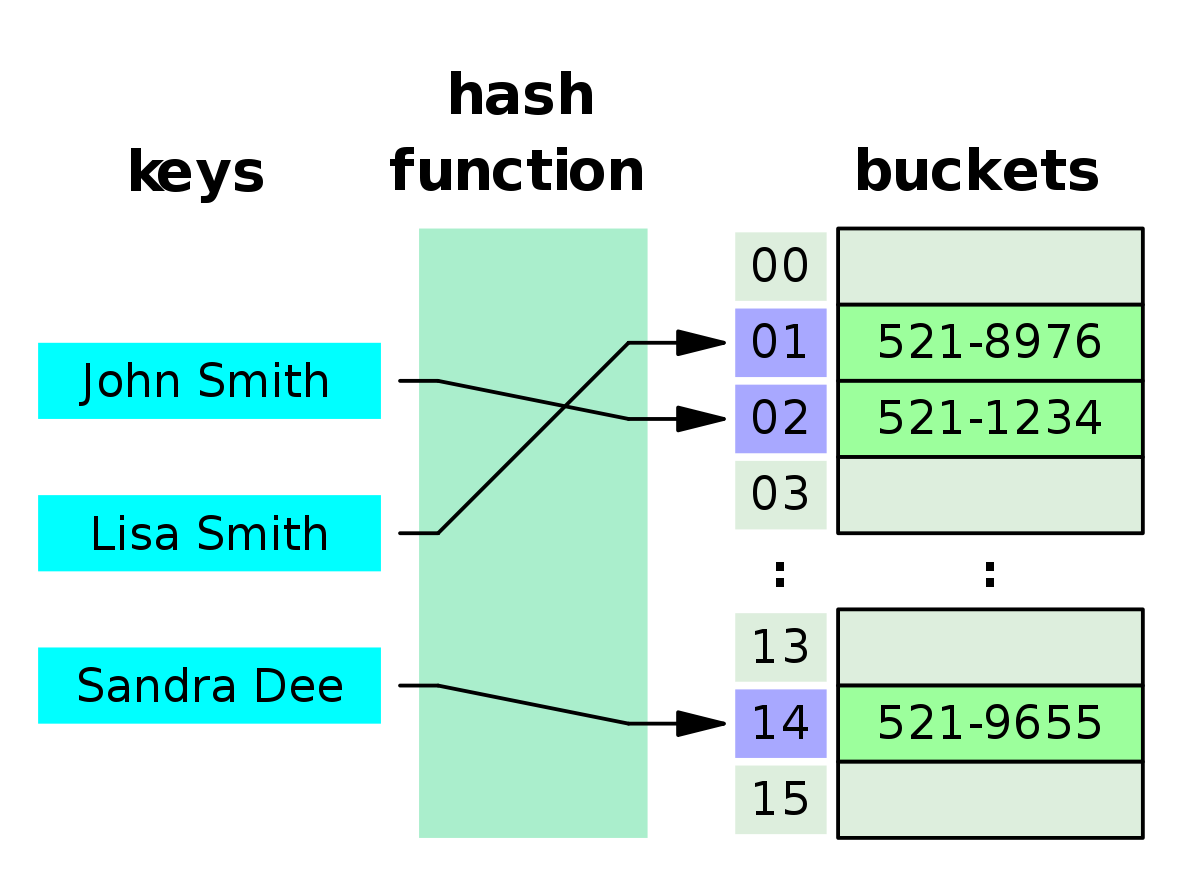
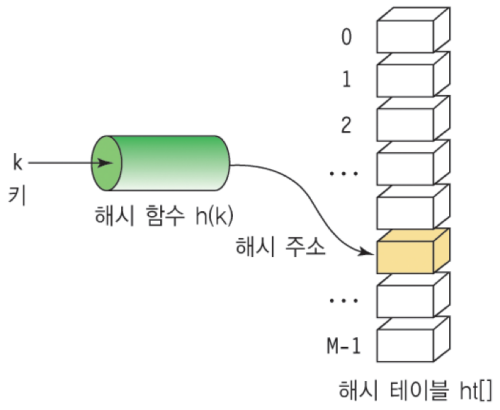
해시 , 해시테이블 , 해싱 함수
해시 : 임의 값을 고정 길이로 변환하는것
해시 테이블 : 키 값의 연산에 의해 직접 접근이 가능한 데이터구조
해싱 함수 : key 에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
해쉬 값 or 해쉬 주소 : key 를 해싱함수로 연산해서 , 해쉬 값을 알아내고 , 이를 기반으로 해쉬 테이블에 해당 key 에 대한 데이터 위치를 일관성 있게 찾을 수 있음
>>> my_dict = {1 : "one", "two" : 2, 3 : 3.0, 1: "one_one"}
>>> my_dict
{1: 'one_one', 'two': 2, 3: 3.0}
>>> for key, value in my_dict.items():
... print(f"{key} : {value}")
...
1 : one_one
two : 2
3 : 3.0
>>> my_dict[1]
'one_one'
>>> my_dict.get("two")
2
>>> my_dict[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 5
>>> my_dict.get(5, 0)
0
>>> my_dict[7] = "Seven"
>>> my_dict
{1: 'one_one', 'two': 2, 3: 3.0, 7: 'Seven'}장단점
장점
- 데이터 저장/읽기 속도가 빠르다 ( 검색 속도가 빠르다. )
- 해쉬 는 키에 대한 데이터가 있는지 (중복) 확인이 용이하다.
단점
- 일반적으로 저장공간이 좀더 많이 필요하다
- 여러 키에 해당하는 주소가 동일할 경우 충돌을 해결하기 위한 별도 자료구조가 필요함
주요 용도는
검색이 많이 필요할 경우
저장 , 삭제 , 읽기가 빈번할 경우
