그래프는 계속 이해가 잘 되지않았고 , 언제가는 공부해야지 하다가 정리합니다.
그래프는 크게 두개로 나뉘게 된다.
- DFS(깊이 우선 탐색) : 스택 으로 구현되며 , 재귀 를 이용하면 좀 더 간단하게 구현할 수 있다.
- BFS(넓이 우선 탐색) : 큐 를 이용한 반복 구조로 구현한다. ( 덱 추천 )
비교적 BFS 보다 DFS 가 출제 빈도가 높다.
이미지 참고 : https://velog.io/@yusokk/algorithm-graph
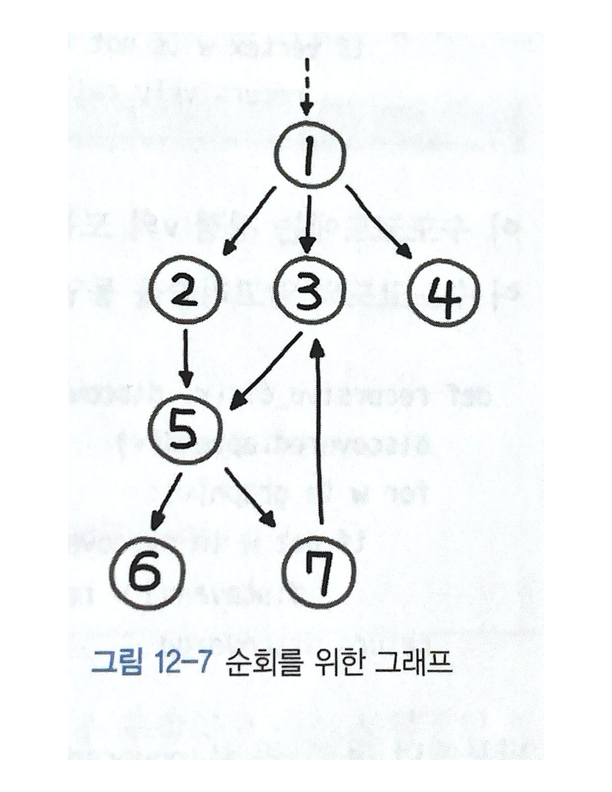
📌 DFS
👉 재귀를 이용한 구현
graph = {
1:[2,3,4],
2:[5],
3:[5],
4:[],
5:[6,7],
6:[],
7:[3],
}
def recursive_dfs(v,discovered=[]):
discovered.append(v)
for w in graph[v]:
if not w in discovered:
discovered = recursive_dfs(w , discovered)
return discovered
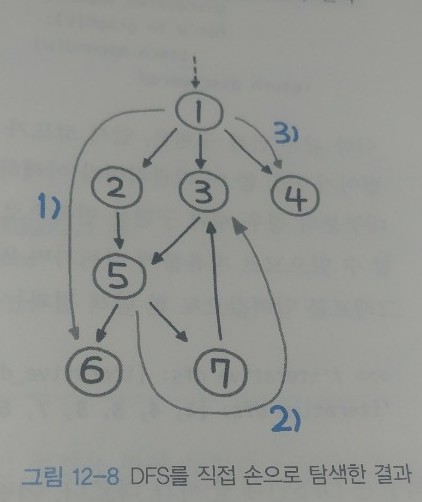
print(recursive_dfs(1)) # [1, 2, 5, 6, 7, 3, 4]- 1->2->5->6 까지 진행하고 다시돌아간다.
- 7->3 갔다가 다시 루트까지 거슬러 올라간다.
- 4
==> 1->2->5->6->7->3->4
https://leetcode.com/problems/permutations/
from typing import List
import numpy as np
nums = [1,2,3]
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
result = []
prev_elements = []
def dfs(elements):
if len(elements)==0:
result.append(prev_elements[:])
for e in elements:
next_elements = elements[:]
next_elements.remove(e)
prev_elements.append(e)
dfs(next_elements)
prev_elements.pop()
dfs(nums)
return result
solution = Solution()
print('result : ',solution.permute(nums))
하지만 이 풀이를 iteratools 를 사용하게되면 쉽게 풀수가 있다.
👉 itertools 를 통한 풀이
import itertools
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
return list(itertools.permutations(nums))이렇게 간단히 풀수있지만 기본개념을 반드시 숙지를 해야하기때문에 앞서 작성한 코드를 이해하도록하자.
👉 스택을 이용한 반복 구조 구현
graph = {
1:[2,3,4],
2:[5],
3:[5],
4:[],
5:[6,7],
6:[],
7:[3],
}
def iterative_dfs(start_v):
discovered = []
stack = [start_v]
while stack:
v = stack.pop()
if v not in discovered:
discovered.append(v)
for w in graph[v]:
stack.append(w)
return discovered
print(iterative_dfs(1)) # [1, 4, 3, 5, 7, 6, 2]스택으로 구현하기 때문에 , 가장 마지막에 삽입된 노드부터 꺼내서 반복하게 되고
이 경우 인접 노드에서 가장 최근에 담긴 노드 , 즉 가장 마지막부터 방문하기 때문이다.
📌 BFS
👉 큐를 이용한 반복 구조로 구현
graph = {
1:[2,3,4],
2:[5],
3:[5],
4:[],
5:[6,7],
6:[],
7:[3],
}
def iterative_bfs(start_v):
discovered = [start_v]
queue = [start_v]
while queue:
v = queue.pop(0)
for w in graph[v]:
if w not in discovered:
discovered.append(w)
queue.append(w)
return discovered
print(iterative_bfs(1)) # [1, 2, 3, 4, 5, 6, 7]조금 더 최적화를 위해서는 데크 같은 자료형을 사용해 보는것을 추천한다.
숫자 순으로 실행됬다.
1부터 순서대로 각각의 인접 노드를 우선으로 방문하는 BFS 가 실행됬다.
📌 백트랙킹
- 완전탐색처럼 모든 경우를 탐색하나 , 중간 중간에 조건에 맞지 않는 케이스를 가지치기 하여 탐색 시간을 줄이는 기법
- 탐색 중 조건에 맞지않는 경우 이전 과정으로 돌아가야하기때문에 재귀를 많이 사용함
- 조건을 어떻게 설정하고 , 틀렸을 시 어떤 시점으로 돌아가야 할지 설계를 잘 해야 함

꾸준함이란 ... ?