Seaborn 이용한 데이터 시각화 코드 정리
세팅
라이브러리 불러오기
# anaconda 를 설치하게 되면, 다양한 패키지들이 함께 설치됨
# 그러나 이후에 패키지 업데이트를 위해서는 아래와 같은 작업이 필요함
!pip install -U seabornimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsseaborn에서 제공하는 기본 dataset의 목록은 sns.get_dataset_names로 확인
흔히 사용되는 iris 데이터를 이용해 보자
# dataset load
sns.load_dataset('iris')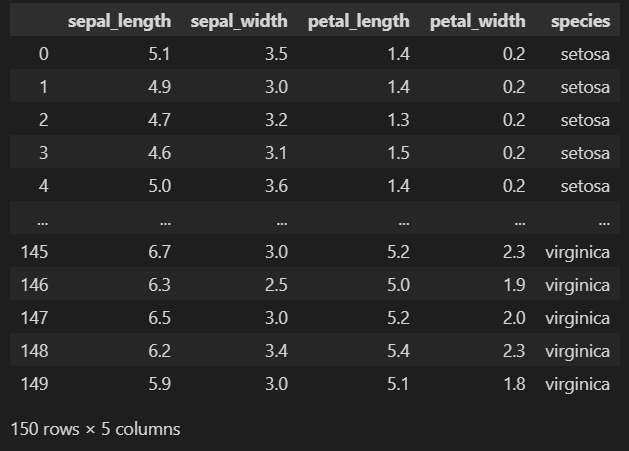
150행 5열의 데이터가 로드되었다.
iris = sns.load_dataset('iris')iris 변수에 불러온 데이터를 넣어주었다.
또한 데이터 종류마다 적용 가능한 차트의 종류가 다르니
총 4종의 데이터를 불러왔다.
titanic = sns.load_dataset('titanic')
diamonds = sns.load_dataset('diamonds')
tips = sns.load_dataset('tips')다양한 차트들
기본 차트
histogram : sns.hisplot
x 인자를 사용하면 수직 히스토그램, y 인자를 사용하면 수평 히스토그램 그려짐
예시는 아래와 같다
sns.histplot(data = titanic, x='age', bins = 16)
plt.show()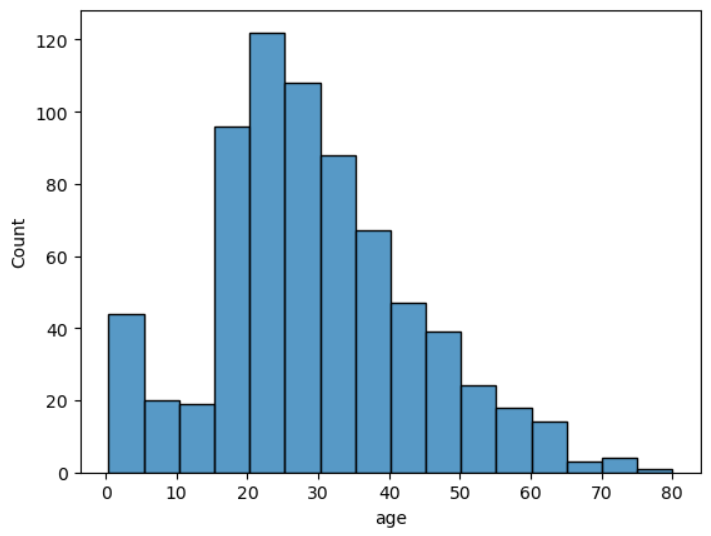
위 그래프는 기본 형태인데, https://seaborn.pydata.org/generated/seaborn.histplot.html
에서 제공하는 다양한 parameter을 조작해 그래프를 다채롭게 만들 수 있다.
예를 들어 hue parameter의 key값을 survived 로 설정하면,
sns.histplot(data = titanic, x='age', bins = 16, hue = 'survived')
plt.show()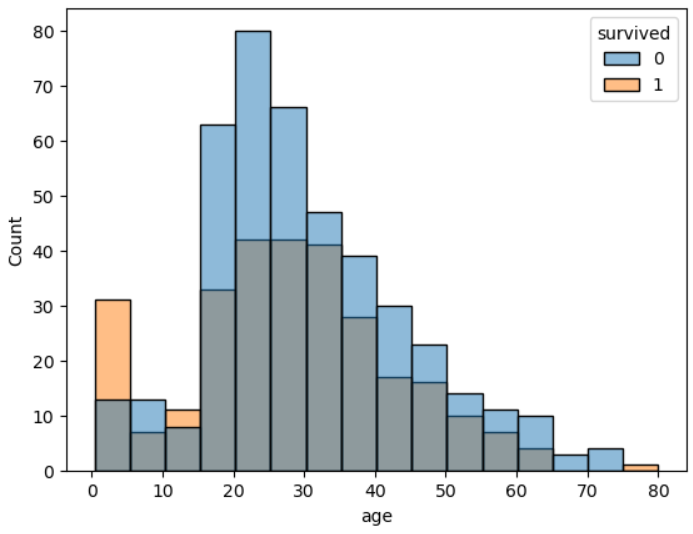
위와 같은 도표를 출력하게 된다.
densityplot : sns.kdeplot
sns.kdeplot(data = titanic, x = 'Age')
plt.show()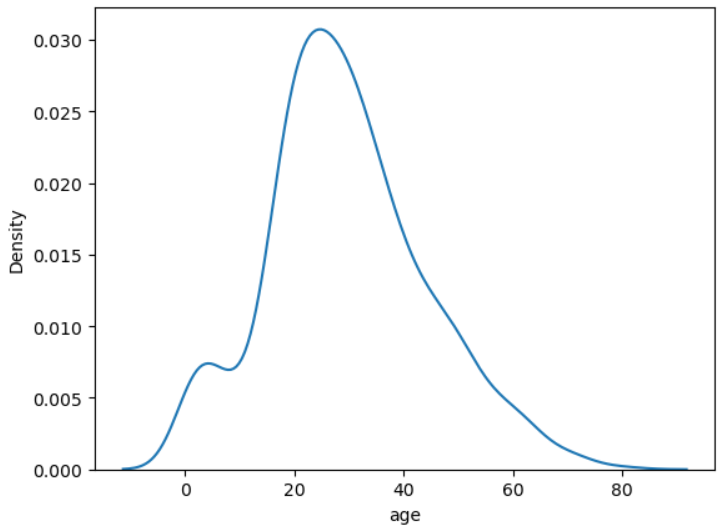
sns.kdeplot(data = titanic, x = 'age', hue = 'survived', common_norm = False)
plt.show()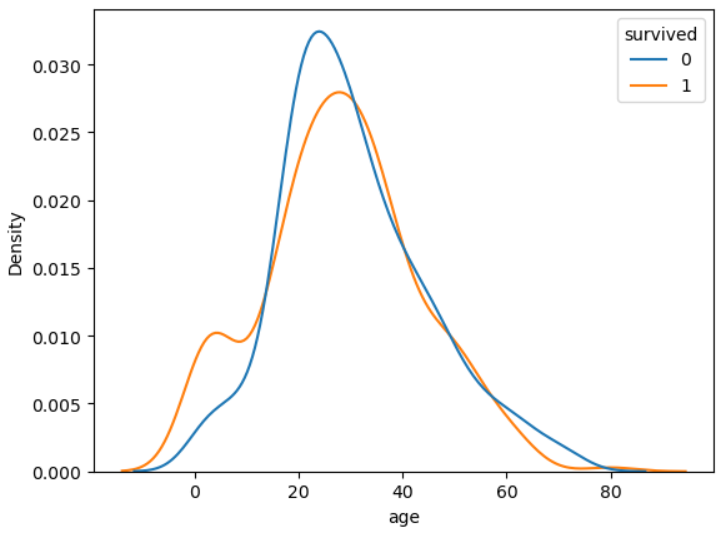
boxplot : sns.boxplot
sns.boxplot(data = titanic, x = 'age')
plt.show()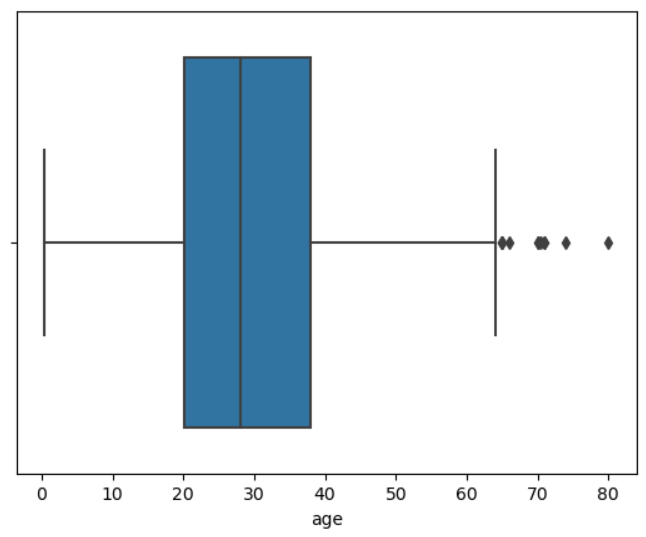
sns.boxplot(data = titanic, y = 'age', x = 'survived')
plt.show()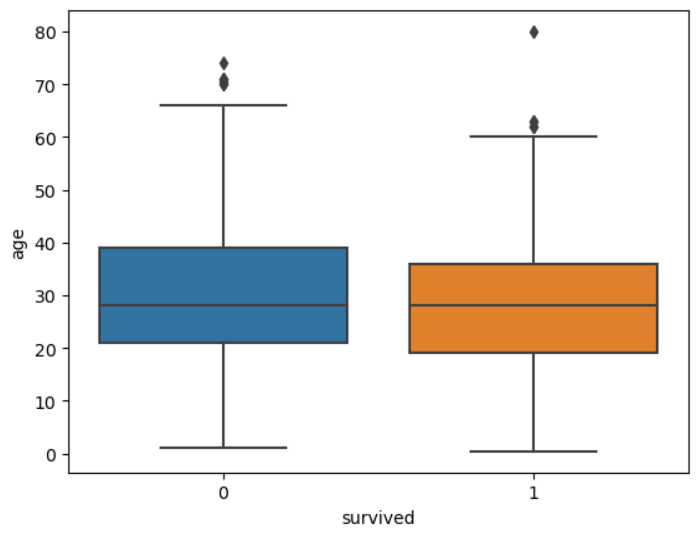
jointplot : scatter + histogram(or density plot)
https://seaborn.pydata.org/generated/seaborn.jointplot.html
- 두 숫자형 변수의 분포를 한꺼번에 비교하여 보여줌
- Seaborn의 가장 큰 특징은 hue 옵션으로 범주 차원을 추가해서 볼 수 있음
sns.jointplot(x='petal_length', y='petal_width', data = iris)
plt.show()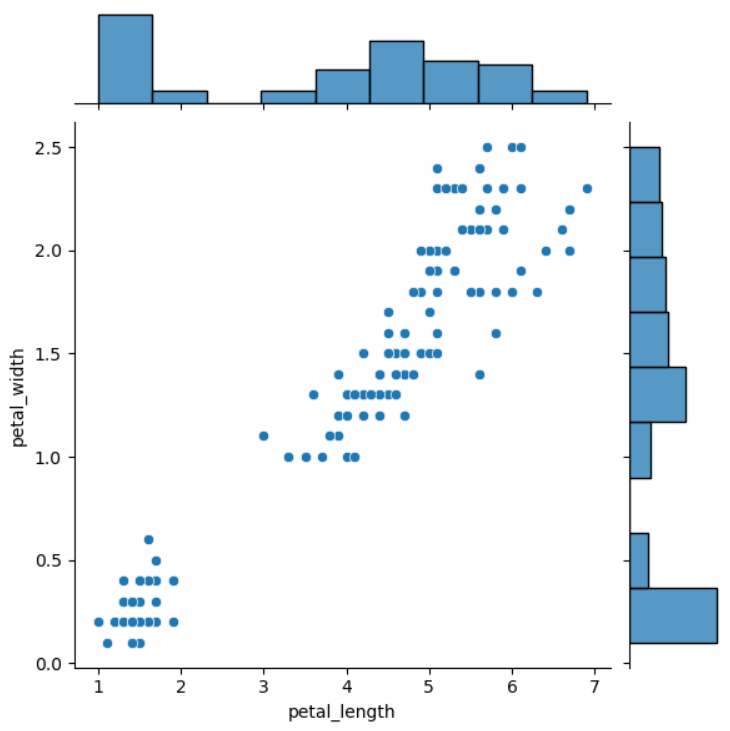
sns.jointplot(x='petal_length', y='petal_width', data = iris, hue = 'species')
plt.show()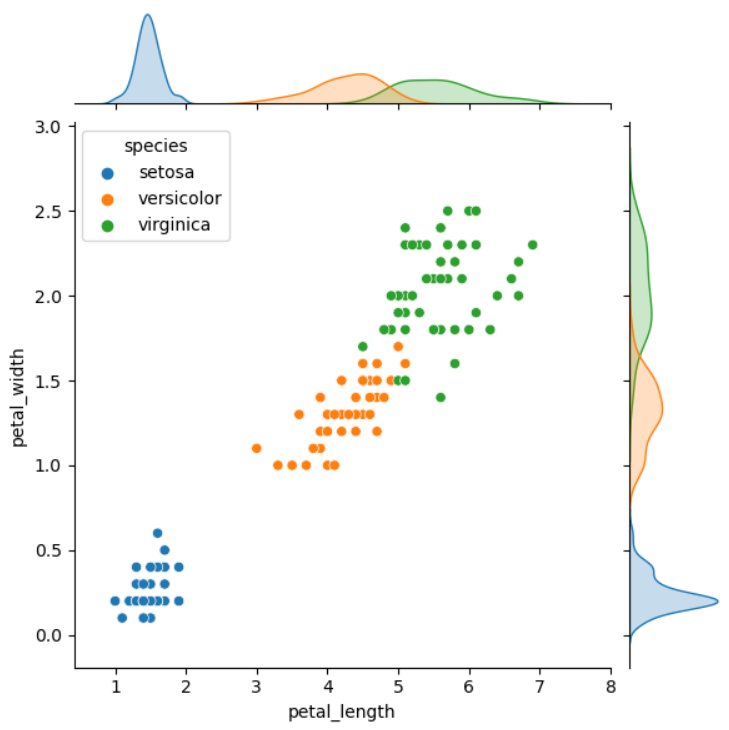
regplot : scatter + regression
https://seaborn.pydata.org/generated/seaborn.regplot.html
- 두 숫자형 변수의 산점도와 회귀선을 한꺼번에 비교하여 보여줌
sns.regplot(x='petal_length', y='petal_width', data = iris)
plt.show()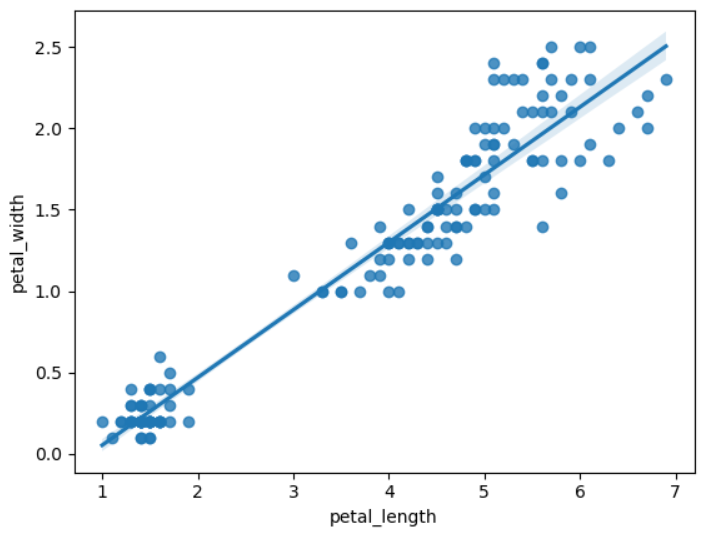
pairplot : scatter + histogram(or density plot) 확장
https://seaborn.pydata.org/generated/seaborn.pairplot.html
- 모든 숫자형 변수들에 대해서 서로 비교하는 산점도 표시
- 각 변수에 대해서는 히스토그램(혹은 density plot) 표시
- 시간이 오래 걸림
sns.pairplot(iris, hue = 'species')
plt.show()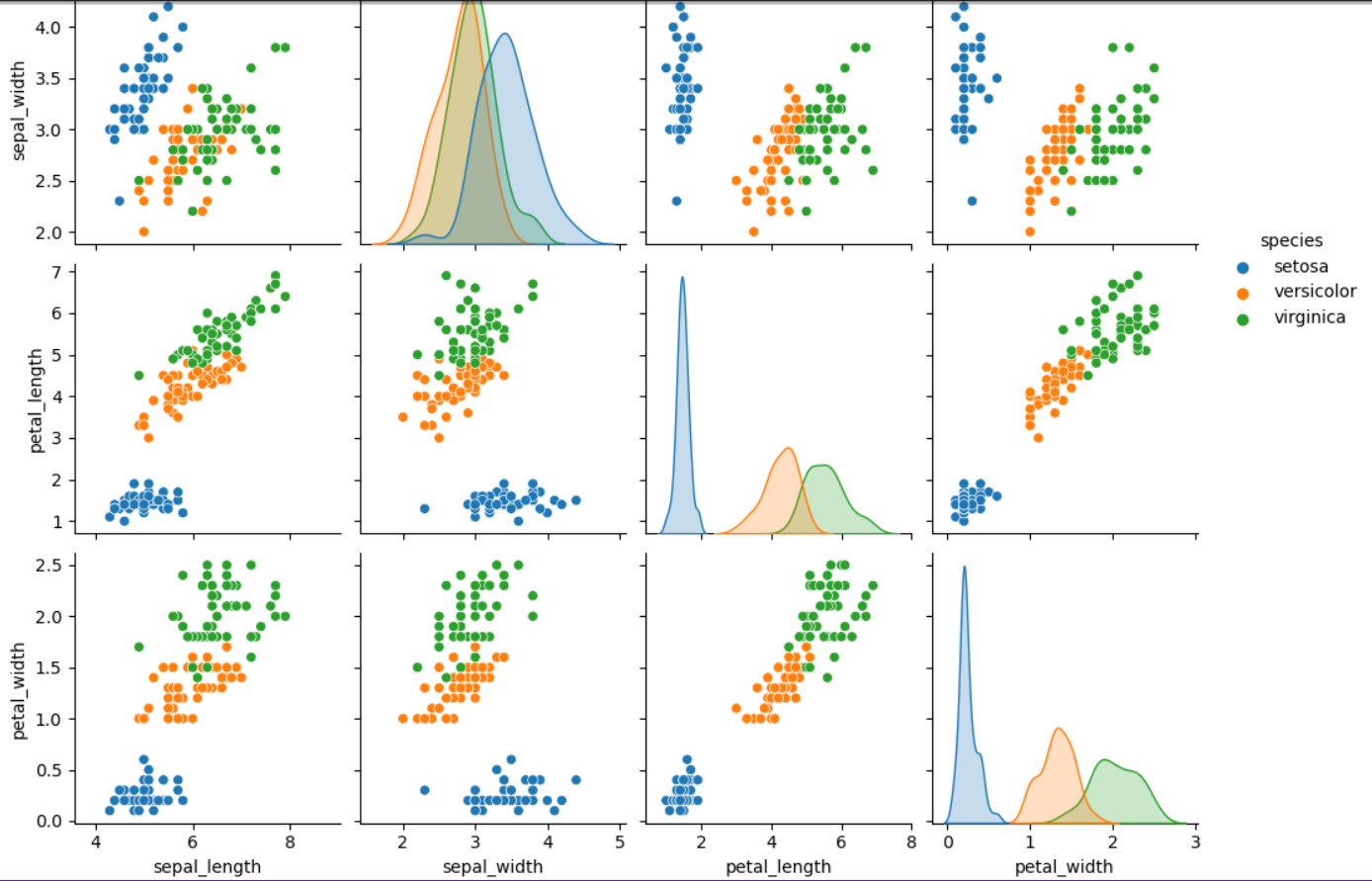
heatmap : 두 범주 집계 시각화
https://seaborn.pydata.org/generated/seaborn.heatmap.html
- 두 범주를 집계한 결과를 색의 농도로 표현해주는 그래프
- 집계(groupby)와 피봇(pivot)을 먼저 만들어 주어야 함
- 여러 범주를 갖는 변수 비교 시 유용
temp1 = titanic.groupby(['embarked','pclass'], as_index = False)['alive'].count()
temp2 = temp1.pivot('embarked','pclass', 'alive')
sns.heatmap(temp2, annot = True)
plt.show()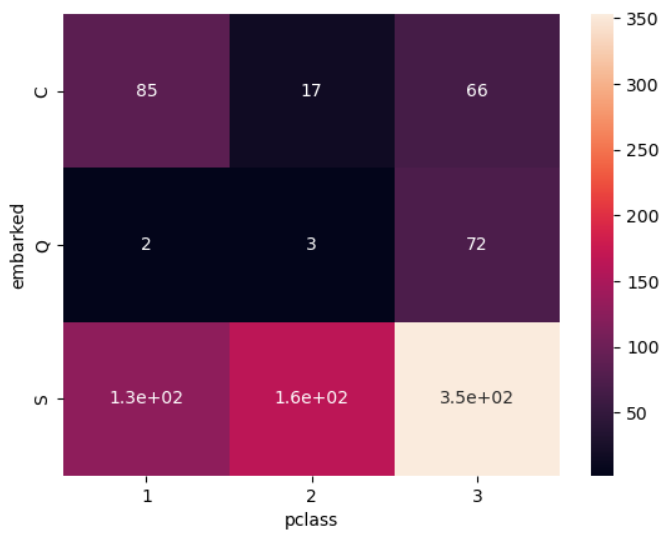
# parameter 이용해 값을 정수로, 구간 간격을 살짝 벌려서 그리려면?
sns.heatmap(temp2, annot = True, fmt = 'd', linewidth = .2)
plt.show()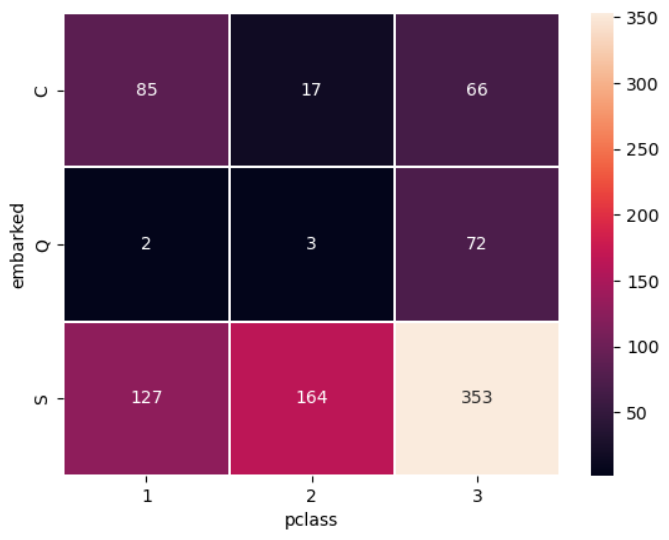
데이터 분석에 자주 이용되는 도표 몇 가지를 대표적으로 기록해보았는데, 앞으로 각 plot마다 변경할 수 있는 parameter에는 무엇이 있는지, 또 어떤 조건에서 주로 사용되는지 하나씩 저장해보려 한다.
