
📌 HYPER TEXT TRANSFER PROTOCOL
📖 Hypertext란?
참조링크를 통해, 독자가 다른 문서로 즉각적으로 이동할 수 있는 문서로 순차적 나열적 구조가 아닌, 사용자가 임의로 나열하는 구조를 가진다.
📖 HTTP란?
인터넷 상에서 데이터를 주고 받기 위한 프로토콜
- 클라이언트와 서버 간의 통신 (웹사이트를 로드 하는데 필요한 정보를 요청하는 방법)
- World Wide Web의 통신 방법
- 요청 & 응답 방식의 애플리케이션 계층의 통신
- 단방향성 (하나의 요청에 하나의 응답)
📖 HTTP의 단점
데이터를 평문으로 보낸다
- 도청 및 데이터 변조 + 패킷 가로채기 가능 => HTTPS (Secure)
📖 HTTP method
1. GET
주로 조회에 사용되며, 서버의 데이터를 수정하는데에 사용해서는 안됨
=> 따라서 GET 요청은 멱등성을 가진다. (다 회 시도에 따른 서버의 변경 및 리턴이 바뀌지 않음)
- 조회 정보를 URL의 쿼리 파라미터로 전달
- 요청시 본문(Body) 및 ContextType이 없음
- 캐싱 가능 (캐싱 2번 @Cacheable활용 부분은 후에 추가적으로 redis를 사용하는 부분과 묶어서 글 작성!)
-
클라이언트 캐싱 (백엔드에서는 유도만)
@GetMapping("/items/{id}") fun getItemWithETag( @PathVariable id: Long, request: HttpServletRequest ): ResponseEntity<ItemDto> { val item = itemService.getItem(id) val etag = "\"" + item.hashCode().toString() + "\"" // 클라이언트가 보내온 ETag와 비교 val clientETag = request.getHeader("If-None-Match") if (clientETag != null && clientETag == etag) { return ResponseEntity.status(HttpStatus.NOT_MODIFIED).eTag(etag).build() } return ResponseEntity.ok() .eTag(etag) .cacheControl(CacheControl.maxAge(60, TimeUnit.SECONDS).cachePublic()) .body(item) }
클라이언트 캐싱 상세 과정
- 서버는 ETag를 응답 헤더에 넣어서 보냄
ETag: "123456"
Cache-Control: public, max-age=60- 클라이언트(브라우저 또는 프록시)가 이 응답을 저장하고
이후 다시 같은 URL 요청 시, 클라이언트는 If-None-Match: 부분을 추가
GET /items/1
If-None-Match: "123456"- 서버는 현재 데이터로부터 ETag 생성 (hashCode, 또는 content 기반 hash 등)
[ 예시에서는 단순히 item을 hash처리해서 ETag 생성 ]
val etag = "\"" + item.hashCode().toString() + "\"" [ 클라이언트가 보낸 ETag와 동일한지 확인 하는 코드 ]
if (clientETag == etag) {
return ResponseEntity.status(HttpStatus.NOT_MODIFIED).eTag(etag).build()
}서버는 본문(body)을 전혀 보내지 않고,
HTTP 304 Not Modified 응답만 내려줌.
→ 즉, 클라이언트가 기존에 저장한 데이터를 그대로 사용함!
- @Cacheable을 활용한 서버 측 캐싱 (이후에!!!)
2. POST
주로 새로운 데이터 생성에 사용되며, 부모 리소스의 하위 리소스를 생성하는데 사용
=> 따라서 POST 요청은 멱등성을 가지지 못한다. (동일한 요청이라도, 리소스를 중복으로 만들어 다른 리소스가 생성)
- body를 반드시 포함 (Context-Type도 필수)
- 정상적으로 리소스가 생성될 시 201(Created)로 응답
3. PUT
주로 기존 데이터 수정에 사용
=> 중요!!! PUT 요청은 멱등성을 가진다. (수정은 하나의 리소스를 대상으로 하기 때문에 덮어씌워짐 = 멱등성 보장)
- body에 변경된 데이터 내용을 반드시 포함 (Context-Type도 필수)
- URL을 통해 어떤 리소스 수정할지를 지정해야함 (PUT /member/1)
4. DELETE
기타
-
HEAD (vs GET) : GET과 유사하지만, 헤더만 조회하기 때문에, body데이터가 없어 더 빠른 조회 가능
예시, HEAD /my-profile/image.png 형식이면, GET 방식에 비해 이미지가 존재하는지, 크기가 얼마인지의 정보를 빠르게 얻을 수 있다. -
PATCH (vs PUT) RESTful하게 사용한다면, PUT은 id를 제외 모든 데이터를 덮어씌우고, return을 전체 데이터 / 그에반해 patch는 원하는 속성만 수정하고, return을 수정된 값만 보낸다.
=> 즉 PUT은 이론상 해당 리소스의 모든 데이터가 DTO에 포함되어야 하는게 맞음 -
OPTIONS : 서버에서 지원하는 메서드 목록 확인
-
CONNECT : 프록시 동작의 터널 접속 변경 (프록시 서버 역할)
📖 HTTP 응답 코드

📌 HTTP/1.0
하나의 연결에 하나의 요청을 처리(즉 모든 요청마다 3-HANDSHAKE)
RTT(Round-Trip Time)
클라이언트의 요청에 따라 서버로 응답을 받을 때까지 걸리는 시간 (즉, 왕복 시간)
- 기본적으로 3-HANDSHAKE의 RTT를 1.5
- 요청 또는 응답 1번의 RTT를 1로 보는데
HTTP/1.0에서는 최소 2.5RTT 연결 및 첫 요청까지 매 요청마다 소비 (비효율적)
따라서 이미지를 처리할 때 서버와의 연결을 또 열고, 받는 방식이 매우 부담이 되기 때문에 아래와 같은 방법을 통해 요청을 최소화 함
- 이미지 스플리팅 (하나의 큰 이미지로 받고, 좌표값(css의 postion)으로 나눠서 이미지를 사용)
- 이미지 Base64 인코딩 (이미지를 64진법의 문자열로 인코딩)
=> 현재 사용 중인 url 방식은 이미지 자체를 보내지 않고, 주소값으로 필요할때 재요청 하는 방식 / Base64는 이미지 자체를 인코딩해서 문자열로 통신에 사용하고, 이를 클라이언트가 직접 디코딩하면 이미지 파일로 만들어지는 방식 (미리보기에 많이 사용됨)
📌 HTTP/1.1
keep-alive 옵션을 통해 한번 연결됬을 때 여러 개의 파일 처리(최초 한번의 요청에서 3-HANDSHAKE 이후 통로를 keep-alive로 열어두는 방식)
단점 : Head-of-Line Blocking
📖 HOL Blocking
HTTP/1.1 처리 흐름 (단일 연결) [HTML-CSS-JS...]
HTML 요청
HTML 응답이 완전히 끝나야
CSS 요청 시작
CSS 응답 끝나야
JS 요청 시작
...
리소스 수가 많을수록 요청이 직렬로 병목 발생
=> CSS 전달 과정이 느리게 받아지게 되면, 후에 받는 JS, JPG 등도 다운로드가 지연됨
📌 HTTP/2
📖 SPDY란?
2012년쯤 웹페이지들이 더 많은 리소스로 동적으로 구성되며, 다수의 도메인을 가짐과 동시에, 보안이 중요한 이슈가 되었다. 이에, latency와 보안 측면에서 HTTP를 보완한 SPDY 프로토콜을 GOOGLE에서 발표했다.
-Multiplexing, HTTP 헤더 압축, 바이너리 프로토콜, TLS(Transport Layer Security) 위에서 동작 등의 특징을 가지고 있었지만 HTTP/2로 버전이 업데이트 되며, 현재는 지원이 중단되었다.
📖 Multiplexing
스트림을 여러개 사용한다.
특정 스트림에서 병목 현상, 패킷 손실이 발생하더라도, 다른 스트림에는 영향을 주지 않게
=> 데이터를 프레임으로 쪼개서 병렬적으로 처리!
=> 단 하나의 데이터를 쪼갠 프레임은 하나의 스트림에서만!
=> 애플리케이션 단계에서의 HOL Blocking은 해결 가능 (TCP 단계에서는 X)
질문 1 : /index.html 파일이 A,B,C 프레임으로 쪼개져서 각 스트림에서 전달된다? => HTTP/2.0단계에서 이 질문의 잘못된 점과 B프레임이 손실 되었을 때 어떻게 처리 될지를 설명하시오!
📖 헤더 압축
HTTP/1.1 문제점
요청마다 중복된 헤더가 계속 전송됨 (예: User-Agent, Cookie, Authorization 등)
리소스가 많은 웹 페이지에서는 → 수십 번 같은 헤더가 반복됨
HPACK(Header Compression for HTTP/2)
클라이언트와 서버가 서로 동일한 헤더 테이블을 가지고 테이블에 이미 존재하는 헤더를 인덱스 번호로 전송하는 방법
허프만 트리
트리 방식을 참고해서 가장 빈도수 많은 문자를 root = 0으로 해서 빈도수가 적은 값을 위로 위치하게 하는 방식
- Prefix-Free Code (접두어가 겹칠 수 없게 = 알아보기 쉬움)
0 01 011 이런식이라면 디코딩 과정에서 어디서 끊어야할지 알 수 없음
따라서 상위 비트가 이전 비트와 겹치지 않게 설계
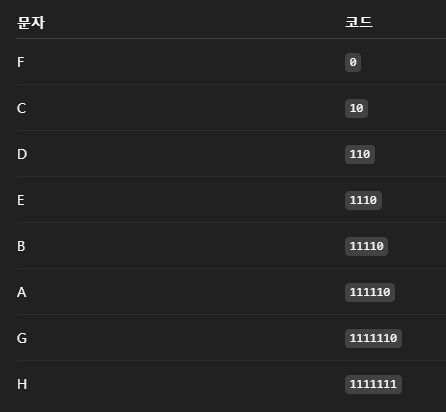
결국 특정 문자의 빈도수 현재 표에서는 F의 빈도수가 높으면 높을 수록 압축률이 높다.
=> HPACK의 index는 이와 같은 방법으로 생성되어 빈도수가 높을 수록 낮은 비트(적은 용량)를 할당하고, 만약 헤더 테이블에 없으면, 현재 테이블에 허프만 트리 방식으로 index를 설계해서, 추가한다.
📖 서버 푸시
기존 HTTP/1.1에서는 HTML -> CSS -> JS -> JPG 순으로 요청이 올때까지 기다려야 했다면, HTML을 요청했을 때, 서버에서 요청을 받기 전에, HTML내에 필요한 CSS, JS, JPG 먼저 전송 가능
📌 HTTP/3 (HTTPS + QUIC)
기존 TCP 사용하던 HTTP/2의 단점을 해결하고자, UDP 방식을 사용하는 HTTP 신규 프로토콜
📖 QUIC(Quick UDP Internet Connections)
이전에 UDP는 TCP에 비해 안정성이 떨어지기 때문에 활용도가 낮다라고 공부한적이 있다. 이를 최신 기술을 통해, UDP의 안정성을 Internet 환경에서 TCP 수준 또는 그 이상으로 만든 것을 QUIC라고 한다.
아래는 기존 UDP 방식에서 QUIC가 되며 바뀐점들 + HTTP/2와 비교한 것
- 안정성
TCP처럼 패킷 번호를 부여 손실을 확인하고 재전송 요청
- vs TCP : TCP는 손실된 데이터를 ACK를 통해 확인 즉 뭐가 빠진지는 정확히 판단하지 못하는 반면, QUIC 방식은 송신자 측은 RTO(타이머)방식으로 패킷 재전송 시도 및 빠진 패킷 번호를 수신사측에서 확인하고 재요청
- 흐름제어
수신자는 네트워크 혼잡도를 확인해 TCP처럼 처리 가능량을 송신자에게 전달 (패킷 유실 방지)
like “한 번에 100KB까지만 보내줘”라고 통지
- vs TCP : 연결 전체 단위 뿐만 아니라 스트림 단위까지 두 가지 레벨의 흐름제어
- 복구
TCP 단계의 HOL BLOCKING이 없는 복구
스트림 1: [A][B][C]
스트림 2: [X][Y][Z]
[TCP]
→ 만약 [B] 패킷 손실 → TCP는 전체 순서를 멈추고 B 재전송까지 기다림
→ 스트림 2의 [X], [Y], [Z]도 도착해도 처리 못 함 (HOL 블로킹)
[QUIC]
→ [B] 손실 → QUIC이 [B]만 재요청
→ [X], [Y], [Z]는 스트림 2로 독립 전송 및 처리 가능
→ 전체 처리 지연 없음
결론 QUIC는 UDP로 TCP의 거의 모든 장점을 기술로 구현해낸 방식 (동일한 처리 + 속도 우수)
📖 Zero round-trip time (0-RTT)
한 번 HTTP 연결이 이루어지고 나면, 클라이언트는 더 이상 handshake를 통해 통신 방법을 확인하려 서로를 확인하는 프로세스를 진행하지 않는다 (간결한 통신)
📖 HTTPS가 선택이 아닌 필수
- HTTP/2까지는 선택 사항
- HTTP/3부터는 TLS 1.3을 내장시켰기 때문에 필수
📌 HTTPS
애플리케이션 계층과 전송 계층 사이에 [신뢰 계층] 추가
📖 SSL/TLS
SSL/TLS(신뢰 계층) = 전송 계층에서 보안을 제공하는 프로토콜
1. 보안 세션을 위한 키교환 진행 (handshake의 마지막 부분)
2. 보안 세션동안 cyper suites라는 암호화 알고리즘 리스트를 클라이언트와 서버가 통신
(후에 어떤 알고리즘을 써서 암호화해서 보내고, 풀지를 결정)
3. CA에서 발급한 인증서 기반으로 인증 메커니즘 진행
4. 해싱 등으로 알고리즘
📖 디피-헬만 키 교환 알고리즘
y = g^x * (mod p) => 공개 값을 공유해서 각자 비밀 값과 연산하여, 혼합 값을 공유하면 공통의 암호키를 생성할 수 있는 원리
- 예시) ECDHE (쉽고 안전한 디피-헬만 알고리즘 변형)
클라이언트 서버
개인키: a 개인키: b
공개키: A = a·G 공개키: B = b·G
수신 공개키: B 수신 공개키: A
공통 키: K = a·B 공통 키: K = b·A
=> 중간에서 A, B를 모두 알아도 a나 b를 모르면 K를 연산하기 힘듬
📖 SHA-256
어떤 길이의 값을 입력해도 256비트의 고정된 결과값을 출력하는 알고리즘
내부 과정은 매우 복잡하지만 간단히 설명하면
- 전처리 과정에서 어떠한 데이터든지 확장해서 512비트로 만들고
- 이를 32bit의 8조각으로 쪼개서, 복잡한 연산(비트수는 바뀌지 않음)을 진행
[Merkl–Damgård Algorithm & RoundFunction =복잡한 연산]
=> [입력 블록 512비트] + [현재 상태 256비트] → 새로운 상태 256비트
=> 이 복잡한 연산은 이전 조각을 매개변수로 이용 A,B,C 면 B를 만들 때는 A가 사용되고, B의 값이 업데이트가 된 후에는 C를 만들 때 사용됨
- 이를 다시 이어 붙임 = 256bit 유지
질문 2 : 문자가 512bit를 넘어가면?
