HTML의 요소를 가져올 때 getElementsById()를 이용하기도 하고, 때로는 querySelector()를 이용하기도 합니다. 이 두개는 무엇이 다르고 무엇이 같을까요?
단일 결과인 경우
getElementById()
먼저 getElementById()를 살펴봅시다.
특정 id값을 찾고, 해당 요소를 리턴합니다. 해당 요소가 없다면 null을 반환합니다.
querySelector()
querySelector는 일치하는 요소들 중 가장 첫 번째로 나온 엘리먼트를 리턴합니다. 일치하는 요소가 없다면 null 을 반환합니다.
다수 결과인 경우
두 개의 함수 모두 여러 개의 결과를 가져올 수 있습니다. 다만, 다수의 결과를 포함해야 하니 이 상황에 더욱 적합한 getElementByClassName과 querySelectorAll로 비교합시다.
많이들 알고 계시겠지만, (스포하자면) 둘 다 index로 결과에 접근할 수 있습니다! 유사 배열이기 때문입니다.
간단한 HTML, JavaScript 코드를 작성해서 직접 확인해봅시다.
<div class="App">
<div id="one" class="test"></div>
<div id="two" class="test"></div>
<div id="three" class="test"></div>
</div>const testQuery = document.querySelectorAll('.test');
const testElement = document.getElementsByClassName('test');
console.log('testQuery', testQuery);
console.log('testElement', testElement);getElementByClassName
특정 className을 가진 요소를 찾고, 해당 요소를 NodeList 로 리턴합니다.
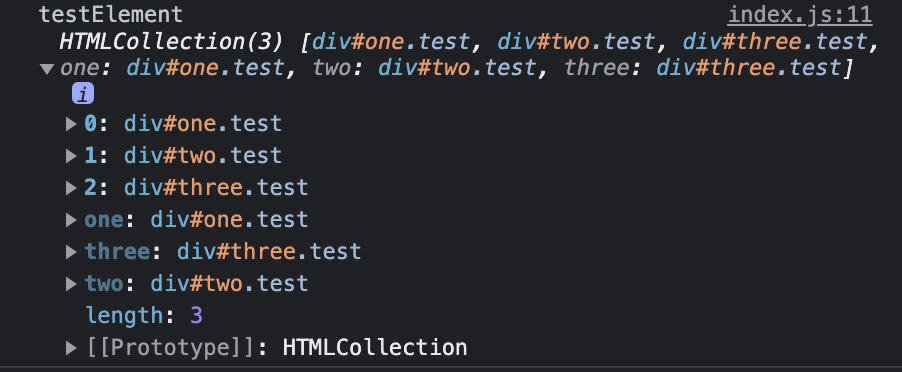
HTMLCollection은 구성요소를 이름과 인덱스로 동시에 직접 노출합니다.
순수 숫자 인덱스와 띄어쓰기는 지원하지 않습니다. testElement.one 과 같은 접근은 가능하지만, testElement.1 과 같은 접근, 그리고 ‘o ne’과 같은 이름도 사용할 수 없습니다.
물론 testElement[1] 과 같은 배열의 인덱스로 접근은 가능합니다.
https://developer.mozilla.org/ko/docs/Web/API/HTMLCollection
대신 namedItem() 같은 메소드를 이용할 수는 있습니다.
querySelectorAll
일치하는 요소들 모두를 HTMLCollection 으로 리턴 합니다.
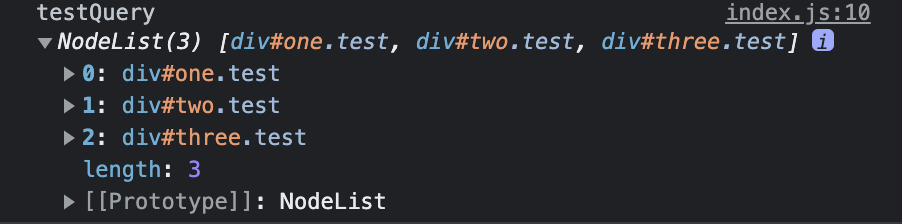
NodeList 이기 때문에 forEach 등 NodeList에서만 사용할 수 있는 여러 메소드를 사용할 수 있습니다. 하지만, 요소에 인덱스로만 접근이 가능합니다.
결과물은 정적으로, DOM이 변경될 경우에도 collection의 내용에는 영향을 주지 않습니다.
결론
querySelector보다 getElementID가 더 빠릅니다. 벤치마크 테스트를 실행하면, getElementById가 약 1.2배 더 빠르다고 합니다.
지원하는 브라우저의 범위도 더 넓습니다.
(출처 - https://bobbohee.github.io/2021-02-12/getelementbyid-versus-queryselector)
하지만, querySelector는 나중에 나온 기능이기 때문에, 지원 범위는 적어도 구체적인 요소를 선택할 때 더 좋을 수 있습니다. (요소를 선택할 때 구체적인 조건을 넣을 수 있기 때문에)
