LANISTR는 언어, 이미지 및 정형 데이터를 동시에 학습할 수 있는 새로운 MultiModal 학습 프레임워크이다.
Abstact
언어, 이미지, 정형 데이터로부터 학습하기 위한 attention 매커니즘 기반 프레임워크인 LANISTR 제안.
LANISTR의 주요 특징:
- 마스킹 기반 훈련 :
- 단일 모달 및 다중 모달 레벨 : 개별 데이터 유형(단일 모달) 뿐만 아니라 다양한 데이터 유형 (다중 모달)에서도 마스킹 기반 훈련을 적용
- 유사성 기반 다중 모달 마스킹 손실 함수 : 일부 데이터 유형이 없는 대규모 다중 모달 데이터로부터 교차 모달 관계 학습 가능
- 실제 데이터 셋에서의 성능 :
- MIMIC-IV(의료 데이터) & Amazon Product Review (소매 데이터)
- MIMIC-IV는 AUROC 에서 6.6% 개선
- Amazon Product Review는 정확도에서 14% 개선
- 누락된 모달리티에 대한 강건성 :
- 많은 샘플이 누락된 데이터 유형을 가지고 있어도 improvement는 일관됨.
Introduction
인간의 다중 감각 지각에 영감을 받아, 복잡한 추론 작업을 수행할 수 있는 MultiModal 모델을 개발하는 것이 전반적인 목표
다중 모달 학습의 잠재적 이점을 실현하기 위해서는 입력 크기와 데이터 이질성이 증가함에 따라 두 가지 주요 과제를 해결해야 한다.
- 일반화 문제
- 입력 특징의 차원 및 이질성이 증가함에 따라 DNN은 overfitting과 최적 이하의 일반화에 취약해짐 (제한된 데이터셋 훈련 시에)
- 정형데이터에서 더욱 악화됨
- Modality 누락 문제
- 두 개 이상의 모달리티를 넘어 다중 모달 데이터를 처리할 때 두드러짐
LANISTR
비정형 데이터(시각 및 언어)와 정형 데이터(표 형식/시계열 데이터)를 사용한 다중 모달 학습을 위한 새로운 프레임워크 제안
- 유사성 기반 다중 모달 Masking 목표를 통해 단일 모달 마스킹 사전 훈련을 활용하면서 교차 모달 관계를 포함
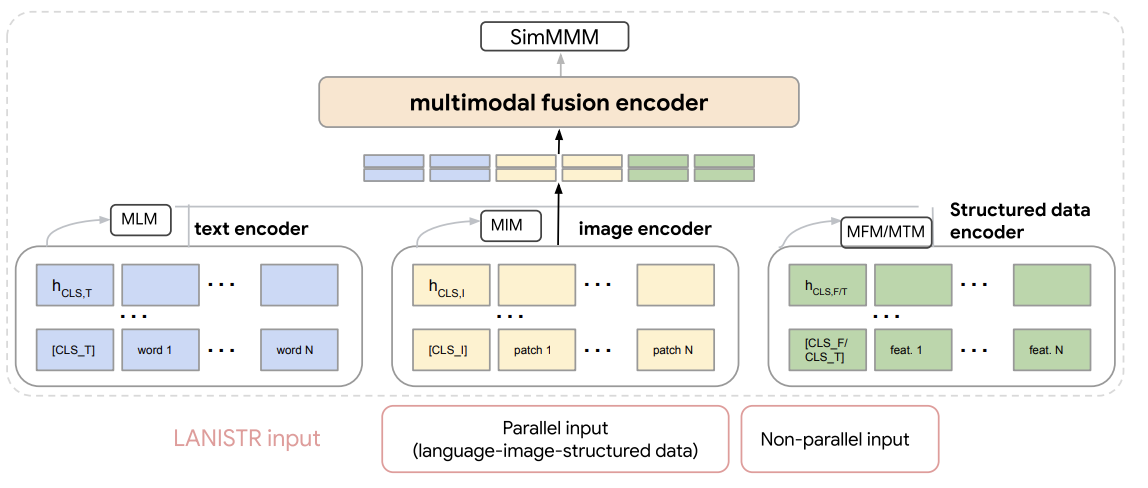
- 모든 Modality가 존재하는 경우 (병렬) & 일부 Modality가 누락된 경우 (비병렬)의 입력 raw mulit-modal 데이터를 처리하고 모달리티별 인코더를 통해 인코딩한다.
- 결과로 나온 임베딩은 concatenated된 후 제안된 multimodal fusion encoder에 입력된다.
- multimodal fusion encoder
- attention 매커니즘 기반 구조를 기반으로 구현되며, 투영된 단일 모달 이미지, 텍스트 및 정형 데이터 표현 간의 cross-attention 상호작용을 수행 → 모든 모달리티를 통합 프레임워크에 효과적으로 융합
Contributions & key demonstrations
- multimodal pretraining에서, 사전 훈련을 위해 단일 모달 및 다중 모달 masking 기술에만 기반을 둔 framework를 제안
- 누락된 모달리티가 존재해도 대규모 라벨이 없는 데이터를 사용하는 것이 유용
Related Work
Self-supervised multimodal learning
- Instance discrimination 기반
- Contrastive이나 Matching Prediciton에 기반
- Contrastive learning
- 샘플을 선택하여 긍정/부정 쌍을 구성
- 모델은 대조 목표를 사용하여 두 쌍을 구별하도록 학습
- CLIP : 이미지-텍스트 쌍으로 사전 훈련되어 인상적인 zero-shot 성능을 보여줌 → 다른 모달리티로 확장 (AudioCLIP & VideoCLIP)
- Matching Prediction
- 두 모달리티에서 샘플 쌍이 일치하는지 예측하는 것을 목표
- audio-visual 상관관계 or Image-Text 매칭에 사용
- 두 모달리티에서 샘플 쌍이 일치하는지 예측하는 것을 목표
- Clustering 기반
- 인코딩된 표현에서 cluster assignment을 예측
- 특징 표현을 업데이트하는 반복 과정을 통해 데이터의 기본 구조 학습
- multimodal cluster assignment은 다양한 모달리티가 다양한 assignment를 가질 수 있게 다양성을 증가
- but, 쌍으로 된 모달리티는 완벽하게 일치하지 않는 문제점 존재
- Masked prediction 기반
- Auto-Encoding(BERT) 와 Auto-Regression(GPT) 접근법으로 수행
- Auto-Encoding Masked prediction
- 입력에서 무작위로 마스킹도니 부분을 예측 → 풍부한 의미적 특징 학습
- cross-modal interaction을 이해하도록하여 다른 모달리티를 조건으로 마스킹 신호를 예측
- Intra-modal masking(동일 모달리티 마스킹) : 동일 모달리티 내 포함된 마스킹된 정보 예측
- Auto-regressive masked predictors
- 컴퓨터 비전 & NLP에서 유명
- 이전 토큰 기반으로 다음 마스킹된 토큰을 예측하는 것을 목표
LANISTR
- 각 모달리티의 무작위로 masking된 정보를 reconstruction loss(복원 손실)를 이용하여 모달리티별 자기 인코딩 마스킹 활용.
- 마스킹된 데이터 표현과 마스킹되지 않은 데이터 표현 간의 유사성을 최대화 → 누락된 모달리티 문제를 해결하는 새로운 multimodal masking 목표를 도입
Learning with unstructured and structured data
LLM의 성공 중 정형 데이터를 비정형 텍스트로 변환하여 LLM으로 처리하는 아이디어 제안.
간단한 방법 : 특징 결합 / 복잡한 방법 : 텍스트 생성 모델 사용
문제점
- 텍스트 생성 모델 학습에는 테이블과 텍스트 데이터 쌍 필요 → 계산 비용 많음
- 범주형이 많은 경우, 표 형식 특징을 언어 토큰 시퀀스로 결합하는 것은 시퀀스 길이가 고정되기에 금지
LANISTR
- 표 형식 / 시계열 데이터를 위한 모달리티별 인코더를 아키텍쳐에 포함하여 문제점 극복
- 모든 모달리티에 대한 적절한 표현 인토딩 허용
- AutoGluon : MLP / Transformer 기반의 융합 모델 ⇒ 라벨이 있는 텍스트, 이미지, 표 데이터 학습 가능
Multimodal learning with missing modalities
비병렬, 누락된 모달리티가 있는 데이터로 학습하는 것은 일부 병렬 데이터와 더 많은 양의 비병렬 데이터가 공존하는 일반적인 현실 시나리오를 반영.
- Transformer
- 누락된 모달리티에 민감
- 혼합 병렬 데이터를 처리하기 위한 self-supervised learning : 병렬 및 비병렬 데이터에 대해 별도의 사전 과제를 적용
- FLAVA
- 모달리티별 인코더를 통해 이미지 전용 및 텍스트 전용 데이터에 대해 masked 이미지 및 언어 모델링을 적용
- multimodal transformer를 통해 쌍으로 된 데이터에 대해 masked multimodal modeling과 contrastive learning을 사용
- UNIMO
- 이미지 전용 데이터에 대해 마스킹된 이미지 모델링, 언어 전용 데이터에 대해 마스킹된 언어 모델링, seq2seq generation 적용
LANISTR
- 병렬 데이터 triplet에서 입력 모달리티를 무작위로 masking하는 방식으로 비병렬 입력과 유사한 임베딩을 강화하여 단일 모달 인코더를 사전 훈련
3. LANISTR : a framework for Language, Image, structured data
3.1 Model Architecture
Fig 1은 모델 아키텍쳐를 개괄적으로 보여주며, 모달리티별 인코더와 융합 메커니즘으로서 multimodal Encoder-Decoder 모듈로 구성
- raw inputs은 text encoder, Image encoder, structured data encoder로 인코딩
- 데이터셋에 따라 표 형식 데이터와 시계열 데이터를 위한 두 개의 별도 정형 데이터 인코더를 가질 수 있음.
- Modality-specific encoder : 모두 attention-based architectures로 선택
- 각 모달리티의 입력에서 임베딩을 얻은 후, concatenated되어 multimodal fusion encoder에 공급
- 입력을 인코딩하여 얻은 hidden state vectors는 모달리티별 인코더를 사용하여 단일 레이어 투영 head로 투영
- results는 multimodal fusion module로 공급
다중 모달 데이터로 기계학습 할 때의 BottleNeck
- 개별 모달리티 간의 cross-modal interaction 반영하는 의미 있는 표현을 추출하는 것
- fusion encoder로서, Transformer 아키텍쳐를 기반으로 하는 cross-attention architecture를 채택하여 cross-modal 관계를 더 잘 파악
3.2 Pretraining objectives
LANISTR는 (1) 단일 모달 masking losses & (2) 유사도 기반 multimodal masking losses를 목표로 사전훈련.
Unimodal self-supervised learning
LANISTR의 모든 unimodal encoder에 대해 일반적인 self-supervised learning strategy으로서 masked signal modeling을 사용
- 단일 모달 인코더의 비병렬 데이터를 사용 가능하게 함
- 마스킹된 입력을 인코더에 공급, 복원/예측 작업을 사용하여 학습
- Masked Language Modeling(LMLM)
- 마스킹된 토큰을 예측하는 작업을 수행하기 위해 텍스트 인코더 (BERT) 위에 분류기 헤드를 통합
- Masked Image Modeling (LMIM)
- Image Encoder로서 attention-based architecture를 채택
- 이미지 마스킹 기반 pre-training 사용
- 이미지의 나머지 부분을 기반으로 마스킹된 이미지 패치를 복원하는 작업 수행
- Masked Feature Modeling (LMFM)
- 표 형식 특징을 인코딩하기 위해 TabNet 채택
- 가시적인 열을 기반으로 누락된 표 형식 특징을 복원하는 작업 수행
- Masked Time series Modeling (LMTM)
- 시계열 Encoder → 일반적인 attention-based Transformer 사용
- 마스킹된 값을 회귀하는 standard self-supervised masked modeling을 목표로 학습
Multimodal self-supervised learning
masked multimodal 데이터 표현과 unmasked multimodal data 표현 간의 유사성을 최대화하는 새로운 masked multimodal learning loss를 제안.
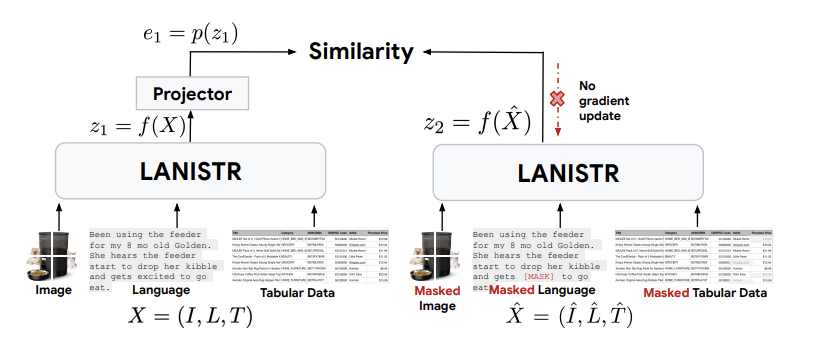
입력 데이터 샘플 형식이라고 가정
( 는 이미지, 언어, 시계열/표 형식의 모달리티 입력을 의미)
입력의 일부를 무작위로 마스킹 ⇒와 같은 masked view
→ 일부 이미지 패치 제거 or 대체
[MASK] 토큰이 있는 텍스트의 하위 단어, 열에 있는 일부 값 마스킹 표 형식의 데이터, 또는 일련의 time event에서 timestep을 제거
- 아키텍쳐는 와 를 두 입력으로 받아들여, unimodal Encoder를 거친 후 multimodal fusion Encoder를 통해 처리.
- Mutlimodal Fusion Encoder 는 unimodal encoder와 달리 다양한 양식에 걸쳐 가중치를 공유
- Fig2는 f가 전체 LANISTR 아키텍쳐를 나타내고, 다중 모달 인코더의 출력을 받아 최종 임베딩으로 투영하는 Projector p가 존재.
- 마스킹된 input의 출력 embedding을 로 정의
- 과 간의 음의 코사인 유사성을 최소화
여기서, 는 L2의 norm . 이를 대칭 함수로 정의하여 total maksing mutlimodal loss를 제안.
Objective :
- 마스킹된 데이터와 마스킹되지 않은 데이터 샘플의 임베딩 간의 cosine 유사성을 최대화하도록 모델을 학습
- cross modal 관계를 학습하는데 더 효과적
LANISTR 사전 훈련을 위한 전체 Objective Function
여기서, 는 사전 훈련 중 각 Loss 구성 요소의 효과를 결정하는 하이퍼 파라미터
3.3 Fine-tuning of LANISTR
대부분의 실제 예시에서는 사전훈련에 사용되는 라벨이 없는 데이터의 양보다 미세조정에 사용되는 라벨이 있는 데이터의 양이 훨씬 적다.
LANISTR에서는 동결된 층과 학습 가능한 층을 제어하여 이를 해결
사전 훈련 후, unimodal Encoder와 multimodal Encoder를 초기화하기 위해 사전 훈련된 가중치를 사용
Downstream 작업을 위해 multimodal encoder와 MLP 분류 모듈을 통합, multimodal encoder와 분류 모듈을 학습하는 동안 unimodal encoder를 동결시킨다. LANISTR의 다용성은 라벨이 있는 데이터가 제공되면 적절한 Head와 목표함수를 통합하여 회귀 또는 검색과 같은 작업으로 확장 가능.
4. Experimental Setup
4.1 DataSet
MIMIC-IV
임상 예측 작업을 위한 인기 있는 공개 의료 데이터셋
- 수집된 임상 시계열 데이터, 의료팀의 임상 노트, 첫 48시간 내에 촬영된 마지막 흉부 X선 이미지를 이미지 모달리티로 사용
- 시계열 전처리를 위해 표준 벤치마크 따름
- 이미지 & 텍스트 모달리티 : Masked Image 및 언어 모델링 기법에서 사용되는 일반적인 이미지 변환 및 텍스트 전처리 스키마 이용
- 35.7% 누락 비율
- 5,923개의 Labeled Sample 이용 : 5,298개 Train Data set / 8개 Validation set / 617개 Test Set
Amazon Review Data (2018)
1996년부터 2018년까지 다양한 제품 카테고리에 걸친 리뷰 및 메타데이터 포함
목표 : 제품이 받은 별점을 예측하는 것
- Office products, Fashion, Beauty 카테고리 사용
- 사전 훈련 : Office product 카테고리에서 5,581,312개의 Sample 사용
- Fine-tuning : Fashion & Beauty의 512개 훈련 샘플의 병렬 하위 집합에 중점
- 검증 & 테스트 세트 : 128개 & 256개의 샘플로 구성
- 병렬 데이터의 경우 : Image(판매자 / 사용자가 제공한 시각 자료) , Text(잘린 텍스트 요약 및 512자 이내의 전체 리뷰 포함) , Table (제품 ID, Reviewer ID, 리뷰인증 상태, year, 리뷰 평점 수, timestamp)
4.2 Baseline Model
LateFusion (image + text + tabular/time series)
- 각 Encoder에 대한 projection layer를 사용하여 모달리티별 encoder를 결합하고, 모든 임베딩을 결합한 후 분류기 head에 공급하는 간단한 Fusion Mechanism
- 병렬 라벨이 있는 데이터만 사용하여 모든 Encoder, projection layer 및 classification head를 end-to-end 훈련을 한다.
- 초기화 : 사전훈련된 ViT-B/16 이미지 인코더 & BERT-base uncased 텍스트 인코더 이용
AutoGluon
- 라벨이 있는 이미지, 텍스트 및 표 형식 데이터를 사용하여 다중 모달 모델을 end-to-end 훈련 가능 (NOT series data)
- ViT-B/16 이미지 인코더, BERT 텍스트 인코더 및 MLP 표 형식 데이터 인코더 사용 → 결합하여 MLP 스타일 / 기본 Transformer 융합 인코더에 공급
- 픽셀을 0으로 대체하여 누락된 이미지 처리 가능
FLAVA (Image + text)
- 단일 모달 마스킹 손실, CLIP 스타일의 글로벌 contrastive loss, Image-text 매칭 loss , masked multimodal loss 사용하여 병렬 및 비병렬 데이터 모두에서 학습할 수 있는 vision 및 언어를 위한 기본 모델
- Text & Image Encoder = ViT와 BERT로 구성 → 다중 모달 인코더를 사용하여 이들을 융합
- 표 형식 / 시계열 데이터 사용 불가
CoCa (image + text)
- Contrastive loss와 captioning loss로 훈련된 이미지-텍스트 Encoder-Decoder 기본 모델
- OpenCLIP 라이브러리에서 공개된 체크포인트를 사용하여 이미지, 텍스트 데이터에서 Fine-Tuning
ALBEF
- 강력한 Vision 및 언어 모델으로, 표 형식 없이 / 표 형식 데이터를 모델에 텍스트로 융합하여 사용 가능
- Masking loss를 사용하여 text encoder를 사전 훈련한 후, Image-Text Maching loss와 MoCo 스타일의 이미지-텍스트 Contrastive loss를 사용하여 이미지와 텍스트 모달리티를 정렬
- Image, Text Encoder = ViT, BERT로 구성
- 다중 모달 인코더의 각 레이어에서 cross-attention을 통해 특징 융합
MedFuse (image + time series)
- 독립적으로 사전 훈련된 모달리티별 인코더를 사용하는 간단한 LSTM 기반 융합 메커니즘
- 이미지 (비병렬 흉부 X-ray에서 14가지 질병 분류를 위해 사전훈련된 ResNet-34) & 시계열 (병원 내 사망률 예측을 위해 비병렬 EHR데이터에서 사전훈련된 LSTM) 사용
- 사전 훈련 후, 분류기를 제거하고 Encoder, Projection Layer 및 LSTM Fusion Module을 병렬 이미지 및 시계열 데이터에서 Fine-Tuning
Tab2Txt
- 다른 Baseline model 위에 표 형식 데이터를 Text로 입력하는 방법
- 표 형식 특징을 문자열 형식으로 변환하여 텍스트 입력 앞에 추가하는 방식
- ALBEF와 LANISTR 위에 적용하여 별도의 표 형식 및 시계열 인코더를 사용하는 것이 중요
5. Results and Discussions
5.1 MIMIC-IV 결과
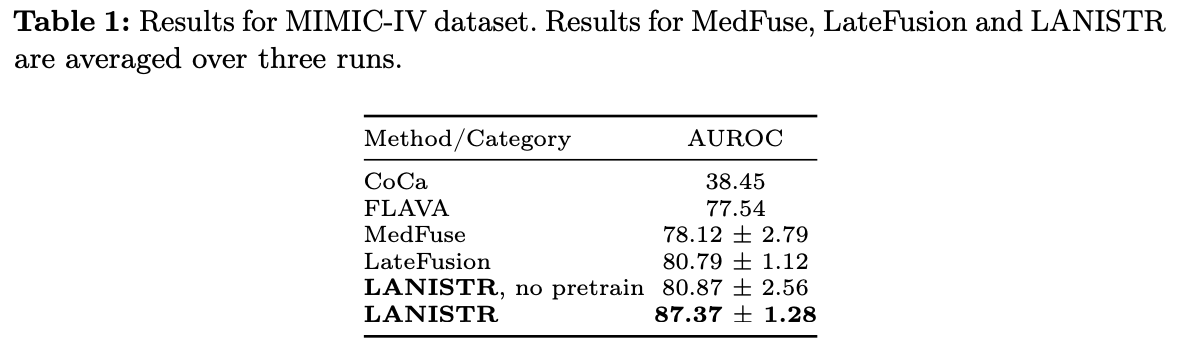
- CoCa : 이미지와 텍스트로만 미세조정 → 38.54%만 달성
- 텍스트 생성 작업에서 뛰어남 but, 텍스트와 이미지 모달리티만 사용한 사망률 예측에서는 성능이 낮음
- FLAVA : 텍스트와 이미지로만 미세조정 → 77.54% ekftjd
- MedFuse : 특별히 설계된 시계열과 이미지 모달리티를 사용하는 최첨단 Mutlimodal model → 78.12%
- LateFusion : Transformer 기반 인코더 사용 → 80.79% 달성
- MedFuse에 사용된 ResNet 및 LSTM 인코더에 비해 더 발전된 인코더와 더 많은 모달리티의 사용 효과를 보여줌
- 사전훈련 없는 LANISTR : 80.87%
- 라벨이 없는 데이터로 LANISTR 사전 훈련 시, 87.37% 향상
5.2 Amazon 제품 리뷰 결과
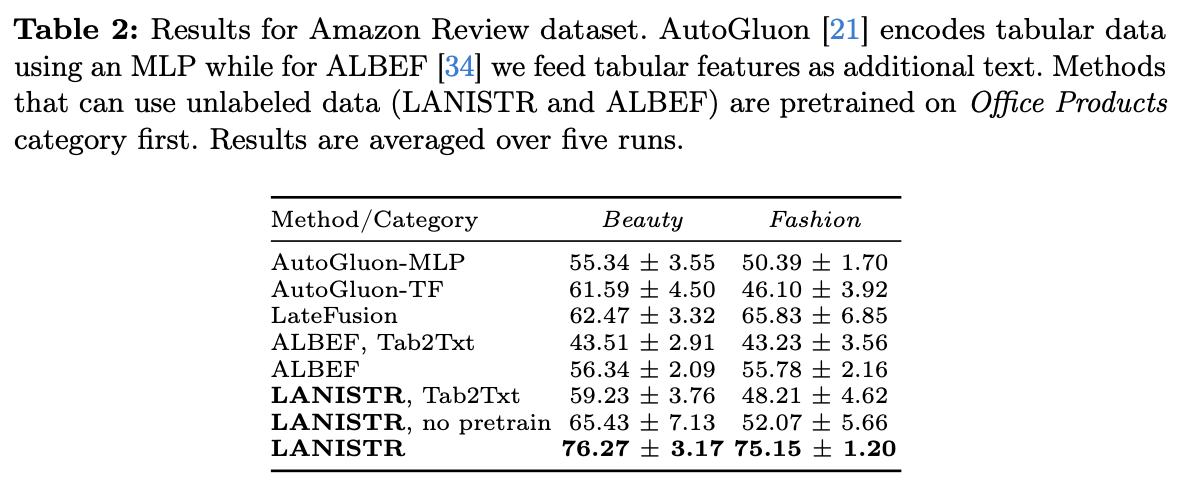
- ALBEF : 이미지 텍스트 데이터를 사전훈련에 사용하는 유일한 모델 → 56.34%
- (1) 이미지 & 텍스트 모달리티로만 사용한 Original
- (2) Tab2Txt를 기준으로 정의
- AutoGluon : MLP + Transformer 기반 융합 사용 → 55.34% / 61.59%
- LateFusion : TabNet을 표 형식 인코더로 사용 & 작은 MLP Fusion Mechanism → 62.47%
- LANISTR + Tab2Txt : LANISTR보다 낮은 정확도 달성 ⇒ 비정형 및 정형 데이터를 별도로 처리하는 중요성을 입증
5.3 Ablation studies 소거 연구
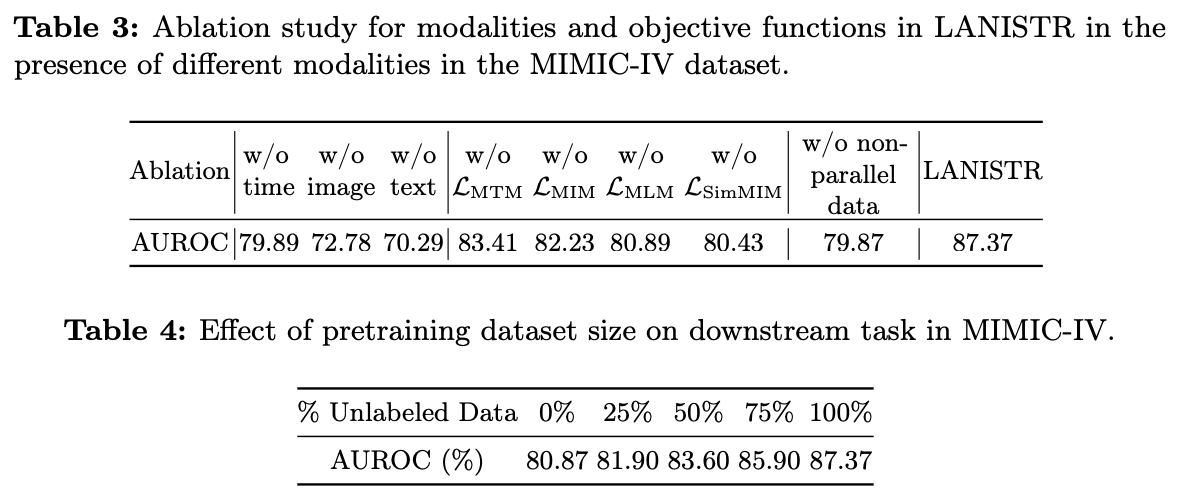
다양한 모달리티의 이점
- 특정 모달리티를 사용하지 않을 때, 그와 관련된 Masking loss도 사전훈련에서 제거된다.
- Text Modality를 제외하면 AUROC가 70.29%로 가장 낮음
- 특징 데이터셋에서 각 모달리티의 정보 중요성을 강조
단일 모달 vs. 다중 모달 자기지도 학습
- 사전 훈련 목표에서 SimMMM과 MLM의 생략은 가장 큰 성능저하를 초래
- MTM 소거는 가장 적은 영향을 미쳤으며, MIM이 그 다음
부분적으로 사용 가능한 모달리티로부터의 학습
- 비병렬 데이터를 제외하면 LANISTR 성능에 비해 AUROC가 6.34% 감소
- LANISTR가 모달리티 간의 관계를 효과적으로 구축하고 모달리티의 부재를 이점으로 활용함을 의미
사전 훈련 데이터셋의 크기 영향
- 크기가 클수록 downstream task가 향상됨
- 라벨이 없는 데이터를 일관되게 사용 가능
