학급 편성 기준 잡기
- 남, 여를 구분하여 3 그룹(학급 수에 따라 다름)의 남여 학생 수를 균형있게 맞춘다.
- 충돌 가능성 있는 학생들은 같은 그룹에 편성되지 않도록 제한 장치가 필요하다.
- 학생들의 성적을 균형있게 배치한다.
ChatGPT를 이용한 기초 코드 작성하기
그룹을 수동으로 편성하는 과정은 주로 다음과 같은 단계를 따릅니다:
- 성적 순 정렬: 학생들의 성적을 기준으로 내림차순 정렬하여 성적이 높은 학생부터 순서를 매깁니다.
- 충돌 체크: 충돌하는 학생들이 같은 그룹에 배정되지 않도록 합니다.
- 성별 균형: 각 그룹에 남녀 학생의 수가 균형을 이루도록 배정합니다.
- 그룹 할당: 위 조건을 만족하면서 번갈아 가며 학생들을 그룹에 할당합니다.
이 과정을 자동화하기 위해 Python 코드를 사용할 수 있습니다. 아래는 학생들을 그룹에 배정하는 간단한 Python 스크립트입니다. 이 스크립트는 성적을 기준으로 학생들을 정렬하고, 충돌하지 않으며 성별이 균형을 이루도록 그룹을 할당합니다.
import pandas as pd
# 학생 데이터
students_data = {
"이름": ["김철수", "서민우"],
"성별": ["
남", "남"],
"성적": [1, 2],
"충돌학생": ["", ""],
}
# 데이터프레임 생성
df = pd.DataFrame(students_data)
# 성적 순으로 학생들 정렬
df_sorted = df.sort_values(by='성적', ascending=False)
# 그룹 할당을 위한 초기 설정
group_assignments = {1: [], 2: [], 3: []}
group_gender_count = {1: {'남': 0, '여': 0}, 2: {'남': 0, '여': 0}, 3: {'남': 0, '여': 0}}
# 충돌 학생을 추적하기 위한 딕셔너리
conflict_tracker = {}
# 그룹 할당
for _, row in df_sorted.iterrows():
name = row['이름']
gender = row['성별']
conflict = row['충돌학생']
# 가능한 그룹 찾기
possible_groups = [1, 2, 3]
if conflict in conflict_tracker:
possible_groups.remove(conflict_tracker[conflict])
# 성별 균형을 맞추기 위해 가능한 그룹 탐색
assigned_group = None
for group in possible_groups:
if group_gender_count[group][gender] < group_gender_count[group]['남' if gender == '여' else '여']:
assigned_group = group
break
# 성별 균형을 맞추지 못하는 경우, 가능한 그룹에서 무작
엑셀 파일에서 학생 데이터를 불러와 그룹을 형성하는 코드로 수정하기
엑셀 파일에서 학생 데이터를 불러와 그룹을 나누는 파이썬 코드를 작성하겠습니다. 이 코드는 다음 단계를 수행합니다:
pandas를 사용하여 엑셀 파일로부터 학생 데이터를 불러옵니다.- 학생들을 성적에 따라 정렬합니다.
- 충돌하는 학생들이 같은 그룹에 포함되지 않도록 합니다.
- 성별 균형을 고려하여 학생들을 그룹에 할당합니다.
먼저, 엑셀 파일의 경로를 정확히 지정해야 합니다. 아래 코드에서 'your_excel_file.xlsx' 부분을 실제 파일 경로로 대체해야 합니다.
import pandas as pd
# 엑셀 파일 경로 설정
excel_file_path = 'your_excel_file.xlsx' # 실제 파일 경로로 변경해주세요.
# 데이터프레임으로 엑셀 파일 읽기
df = pd.read_excel(excel_file_path, sheet_name='Sheet1') # 'Sheet1'을 실제 시트 이름으로 변경해주세요.
# 성적 순으로 학생들 정렬
df_sorted = df.sort_values(by='성적', ascending=False)
# 그룹 할당을 위한 초기 설정
group_assignments = {1: [], 2: [], 3: []}
group_gender_count = {1: {'남': 0, '여': 0}, 2: {'남': 0, '여': 0}, 3: {'남': 0, '여': 0}}
# 충돌 학생을 추적하기 위한 딕셔너리
conflict_tracker = {}
# 그룹 할당
for _, row in df_sorted.iterrows():
name = row['이름']
gender = row['성별']
conflict = row['충돌학생']
# 가능한 그룹 찾기
possible_groups = [1, 2, 3]
if conflict in conflict_tracker:
# 충돌하는 학생이 이미 그룹에 할당된 경우 그 그룹 제외
possible_groups.remove(conflict_tracker[conflict])
# 성별 균형을 맞추기 위해 가능한 그룹 탐색
assigned_group = None
for group in possible_groups:
if group_gender_count[group][gender] < group_gender_count[group]['남' if gender == '여' else '여']:
assigned_group = group
break
# 가능한 그룹이 없으면 첫 번째 그룹 선택
if assigned_group is None:
assigned_group = possible_groups[0]
# 그룹 할당 및 성별 카운트 업데이트
group_assignments[assigned_group].append(name)
group_gender_count[assigned_group][gender] += 1
conflict_tracker[name] = assigned_group
# 결과 출력
for group, students in group_assignments.items():
print(f"그룹 {group}: {students}")
그룹편성시 학생 수를 그룹 수로 나눠 가능한 형평성 있게 배분하는 코드 추가하기
그룹 할당 로직을 수정하여, 각 그룹의 현재 인원 수를 파악하고 인원 수가 가장 적은 그룹에 우선적으로 학생을 할당하는 동시에 성별 균형과 충돌 학생 조건을 고려하도록 코드를 수정하겠습니다.
이를 위해 다음과 같은 접근 방식을 사용할 수 있습니다:
- 각 그룹의 현재 인원 수를 추적합니다.
- 가장 인원이 적은 그룹을 우선적으로 확인하여 할당 가능 여부를 판단합니다.
- 성별 균형과 충돌 학생 조건을 고려하여 할당합니다.
- 가능한 그룹이 없는 경우 다음으로 인원이 적은 그룹을 확인합니다.
아래는 수정된 코드입니다:
import pandas as pd
# 엑셀 파일 경로 설정
excel_file_path = 'your_excel_file.xlsx' # 실제 파일 경로로 변경해주세요.
# 데이터프레임으로 엑셀 파일 읽기
df = pd.read_excel(excel_file_path, sheet_name='Sheet1') # 'Sheet1'을 실제 시트 이름으로 변경해주세요.
# 성적 순으로 학생들 정렬
df_sorted = df.sort_values(by='성적', ascending=False)
# 그룹 할당을 위한 초기 설정
group_assignments = {1: [], 2: [], 3: []}
group_gender_count = {1: {'남': 0, '여': 0}, 2: {'남': 0, '여': 0}, 3: {'남': 0, '여': 0}}
conflict_tracker = {}
total_students = len(df_sorted)
students_per_group = total_students // 3
extra_students = total_students % 3
# 그룹 할당
for _, row in df_sorted.iterrows():
name = row['이름']
gender = row['성별']
conflict = row['충돌학생']
# 할당할 그룹 찾기
assigned_group = None
for _ in range(3):
# 가장 적은 학생 수를 가진 그룹 찾기
min_group = min(group_assignments, key=lambda x: (len(group_assignments[x]), -x))
if len(group_assignments[min_group]) < students_per_group + (1 if min_group == 1 and extra_students > 0 else 0):
if conflict not in group_assignments[min_group] and group_gender_count[min_group][gender] <= group_gender_count[min_group]['남' if gender == '여' else '여']:
assigned_group = min_group
break
# 최적의 그룹을 찾지 못한 경우 다음 그룹으로 이동
del group_assignments[min_group]
# 최적의 그룹을 찾지 못한 경우, 첫 번째 그룹에 할당
if assigned_group is None:
assigned_group = 1
# 그룹 할당 및 성별 카운트, 충돌 학생 추적 업데이트
group_assignments[assigned_group].append(name)
group_gender_count[assigned_group][gender] += 1
conflict_tracker[name] = assigned_group
# 결과 출력
for group, students in group_assignments.items():
print(f"그룹 {group}: {students}")
결과를 2가지 방식의 엑셀로 출력하는 코드 추가하기
출력 결과를 두 가지 다른 형태의 표로 정리하여 엑셀 파일에 출력하는 작업을 진행하겠습니다. 이를 위해 먼저 학생들을 그룹별로 할당한 후, 할당된 그룹 정보를 원본 데이터프레임에 추가합니다. 그런 다음, 요구된 정렬 기준에 따라 데이터를 정렬하고 두 개의 별도 시트로 엑셀 파일에 저장합니다.
아래는 전체 프로세스를 수행하는 코드입니다:
import pandas as pd
# 엑셀 파일 경로 설정
excel_file_path = 'your_excel_file.xlsx' # 실제 파일 경로로 변경해주세요.
# 데이터프레임으로 엑셀 파일 읽기
df = pd.read_excel(excel_file_path, sheet_name='Sheet1') # 'Sheet1'을 실제 시트 이름으로 변경해주세요.
# 이하 그룹 할당 로직 ...
# ...
# 그룹 정보를 원본 데이터프레임에 추가
df['새 그룹'] = ''
for group, students in group_assignments.items():
for student in students:
df.loc[df['이름'] == student, '새 그룹'] = group
# 결과 표1 (반/번호/이름/성별/새 그룹) - 반과 번호 기준 오름차순 정렬
result_table1 = df.sort_values(['반', '번호'])
# 결과 표2 (새 그룹/반/번호/이름/성별) - 새 그룹과 이름 기준 오름차순 정렬
result_table2 = df[['새 그룹', '반', '번호', '이름', '성별']].sort_values(['새 그룹', '이름'])
# 엑셀 파일로 결과 저장
with pd.ExcelWriter('grouped_students.xlsx') as writer:
result_table1.to_excel(writer, index=False, sheet_name='Grouped by Class')
result_table2.to_excel(writer, index=False, sheet_name='Grouped by New Group')
print("그룹 편성 결과가 엑셀 파일로 저장되었습니다.")
이 코드는 먼저 원본 데이터프레임에 새 그룹 정보를 추가한 후, 두 가지 정렬 기준에 따라 별도의 테이블을 생성합니다. 그런 다음, 이들을 각각 다른 시트로 갖는 하나의 엑셀 파일로 저장합니다.
grouped_students.xlsx 파일이 생성되며, 이 파일에는 'Grouped by Class'와 'Grouped by New Group'라는 두 개의 시트가 포함됩니다.
주의: 코드를 실행하기 전에 your_excel_file.xlsx를 실제 엑셀 파일 경로로, Sheet1을 실제 시트 이름으로 변경해야 합니다.
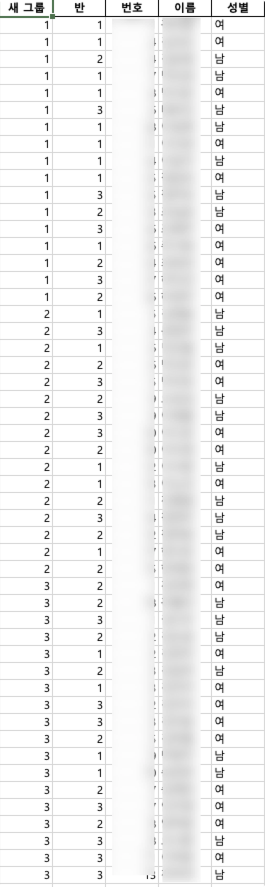
결과 엑셀파일(현재 학급 기준 시트)

결과 엑셀파일(신규 학급 기준 시트)