
개요
모의 투자와 뉴스를 통한 경제 교육 플랫폼 프로젝트 진행하면서 뉴스 데이터를 크롤링을 통해 데이터를 가져오려고 한다.
하지만 동적으로 크롤링을 해야 하고, 3시간마다 크롤링을 할 예정이라 매번 함수를 직접 실행시킬 순 없기에 selenium을 통해 크롤링을 할 것이고, aws lambda에 코드를 올려 자동으로 되게 하려고 한다.
1. AWS lambda 새로 작성 함수
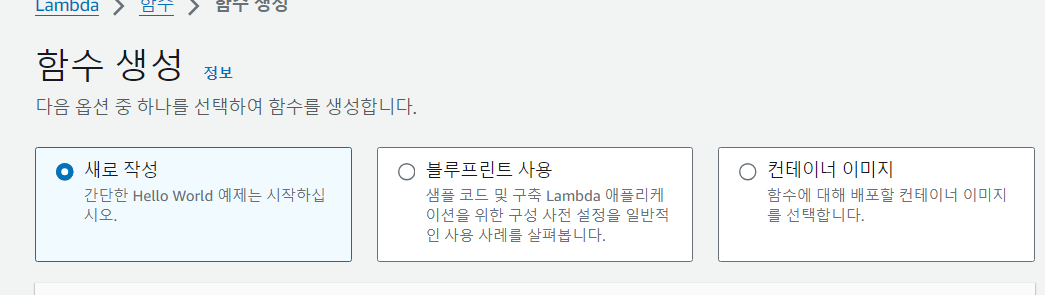
처음 시도한 방식은 새로 작성 방식이다.
이걸 시도한 이유는 BS4로 크롤링 할 때 이 방식으로 했던 경험이 있어서 이 방식을 사용했다.
개발 과정
- 함수 생성
- main 함수 작성
- 계층 설정
1. 함수 생성
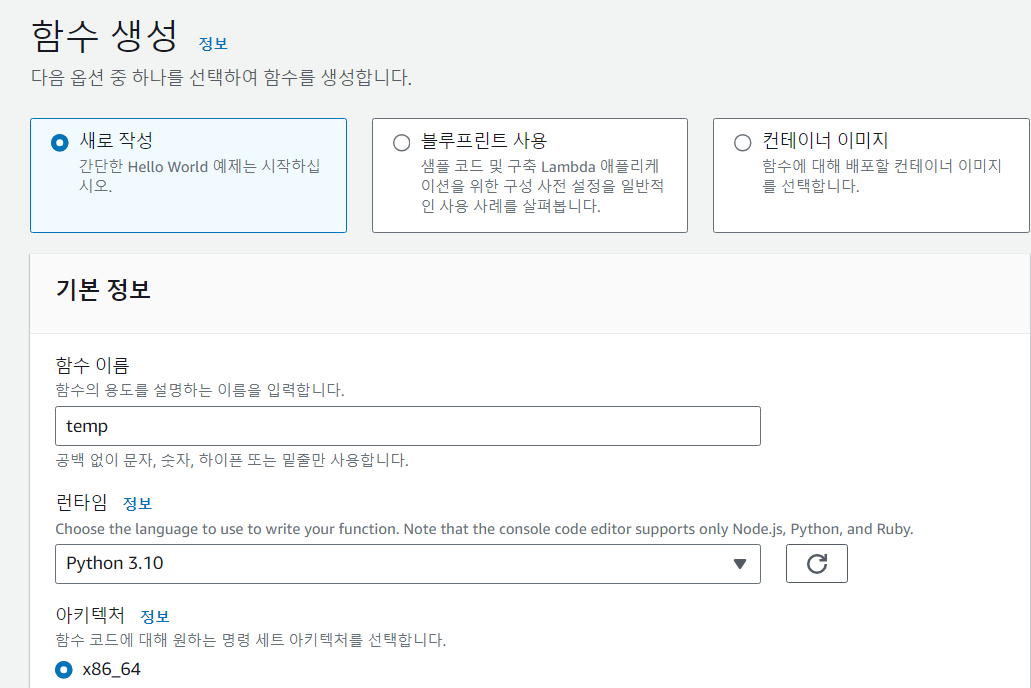
함수 이름 은 사용자가 원하는 이름으로 하고
런 타임 설정은 중복 선택이 가능한데 나는 python을 이용하기 때문에 python을 선택했다. 설정을 다 하고 함수 생성 버튼을 클릭하면 함수가 생성된다.
2. main 함수 작성
함수를 생성하면 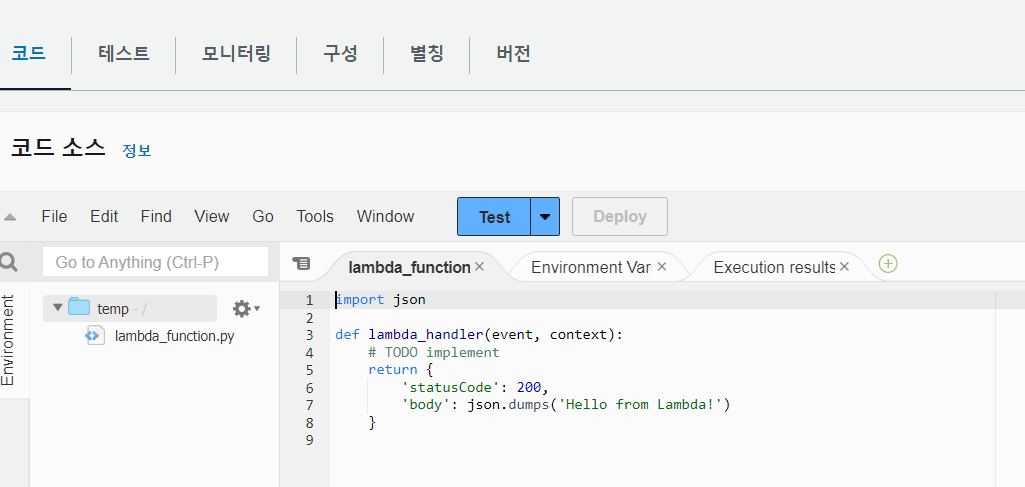
이 창이 나오는데 여기에 본인 코드를 작성하면 된다
작성 후엔 deploy 버튼을 클릭 후에 test 버튼을 클릭해야 본인이 수정한 코드가 test된다.
3. 계층 설정
lambda는 관련 라이브러리, 모듈 등이 지원 되지 않기 때문에 사용자가 해당 코드에서 사용하는 라이브러리, 모듈 등을 직접 넣어줘야 한다.
requirememts.txt 파일에 설치할 항목을 넣고, python 폴더를 꼭 상위 폴더로 해서 압축 시킨 후 계층으로 업로드해야 한다.
이에 관한 설명은 https://velog.io/@aswe0409/TOY-PROJECT-%EA%B3%B5%EC%A7%80%EC%82%AC%ED%95%AD-%EC%95%8C%EB%A6%BC-%EB%B4%87-3 해당 글을 보면 될거 같다.
BUT 셀레니움으로 크롤링 하려면 크롬이랑, 크롬 드라이버가 필요한데 해당 파일들은 용량이 커서 s3에 업로드해서 계층으로 넣어줘야 했다.
하지만 계속 에러가 떠 찾아보니 문제가 발생했고,
https://velog.io/@dbtmddn41/AWS-Lambda%EC%97%90%EC%84%9C-selenium-%ED%81%AC%EB%A1%A4%EB%A7%81
해당 글을 참고 하여 docker를 사용해서 함수를 만들기로 했다.
2. Docker 이미지
개발 과정
- main.py 코딩
- Docker file 만들기
- Docker Image file build
- 로컬에 있는 image ecr에 올리기
- lambda에 docker Image로 함수 만들기
1. main.py 코딩
chrome-deps.txt : chrome 설치에 필요한 yum 패키지 리스트
install-browser.sh : chromebrower 와 chromedriver 설치 스크립트
requirements.txt : pip 패키지 리스트 (필요한것만 추가해서 설치하면 된다.)
Dockerfile
main.py
출처: https://uiandwe.tistory.com/1361 [조아하는모든것:티스토리]
해당 사이트에 들어가면 guthub에 파일이 있는데 해당 파일을 다운 받아서 사용했다.
{
"errorMessage": "init() got an unexpected keyword argument 'executable_path'",
"errorType": "TypeError",
"requestId": "c4ee2c2c-e367-44bc-ae1f-34a46343a274",
"stackTrace": [
" File \"/var/task/main.py\", line 16, in handler\n browser = webdriver.Chrome(executable_path=\"/opt/chromedriver\", options=chrome_options)\n"]
}하지만 해당 문제가 발생했고 검색해보니 (from selenium.webdriver.chrome.service import Service) 이렇게 검색하면 많은 글이 나온다.
이 오류는 webdriver.Chrome() 초기화 시 executable_path라는 인수가 더 이상 지원되지 않기 때문에 발생합니다. Selenium의 최신 버전에서는 executable_path 인수를 사용하지 않고, sevice 객체를 사용하여 ChromeDriver 경로를 설정해야 합니다.
그래서 service 객체를 이용하기 위해
from selenium.webdriver.chrome.service import Service
service = Service(executable_path="/opt/chromedriver")
해당 코드를 추가했다.
import os
import json
import time
import logging
import boto3
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException, TimeoutException, ElementClickInterceptedException
from datetime import datetime, timedelta
def handler(event, context):
chrome_options = Options()
chrome_options.binary_location = "/opt/chrome/chrome"
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--single-process")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko")
chrome_options.add_argument('window-size=1392x1150')
chrome_options.add_argument("disable-gpu")
service = Service(executable_path="/opt/chromedriver")
driver = webdriver.Chrome(service=service, options=chrome_options)
"""
#TODO: 사용자 로직
"""
return {
"statusCode": 200,
}2. DockerFile 만들기
FROM public.ecr.aws/lambda/python:3.9 AS stage
RUN yum install -y -q sudo unzip
ENV CHROMIUM_VERSION=1002910
# Install Chromium
COPY install-browser.sh /tmp/
RUN /usr/bin/bash /tmp/install-browser.sh
FROM public.ecr.aws/lambda/python:3.9 AS base
COPY chrome-deps.txt /tmp/
RUN yum install -y $(cat /tmp/chrome-deps.txt)
# Install Python dependencies for function
COPY requirements.txt /tmp/
RUN python3 -m pip install --upgrade pip -q
RUN python3 -m pip install -r /tmp/requirements.txt -q
COPY --from=stage /opt/chrome /opt/chrome
COPY --from=stage /opt/chromedriver /opt/chromedriver
// 크롬과 크롬드라이버는 /opt에 설치하는것을 볼수 있다.
# copy main.py
COPY main.py /var/task/
// 사용할 파일들은 /var/task에 넣어야 한다!!!! (람다 특성상 다른위치에 있으면 실행되지 않는다.)
WORKDIR /var/task
CMD [ "main.handler" ]
3. Docker file build
도커 파일 빌드시엔 로컬에서 작업중이기 때문에 git bash를 이용했고
docker build --platform linux/x86_64 -t "이미지이름" -f Dockerfile .linux/x86_64 -t 해당 코드를 꼭 넣어줘야 람다에서 작동이 된다.
4. docker image AWS ECR에 올리기
우선 ECR은 AWS에서 제공하는 Docker Hub와 비슷한 개념으로, Amazon Elastic Container Registry의 약자로 안전하고 확장 가능하고 신뢰할 수 있는 AWS 관리형 컨테이너 이미지 레지스트리 서비스. Docker Hub와 동일하다고 볼 수 있지만 장점으로는 S3로 Docker Image를 관리하므로 고가용성을 보장하고, AWS IAM 인증을 통해 이미지 push/pull에 대한 권한 관리가 가능하다.
우선 ECR 레포지토리를 생성하면
해당 창이 생긴다
푸시 명령 보기를 클릭해
git bash에서 순서대로 입력하면 도커 이미지 파일이 AWS ecr로 push가 된다.
5. lambda 함수 생성
다시 lambda로 돌아가서
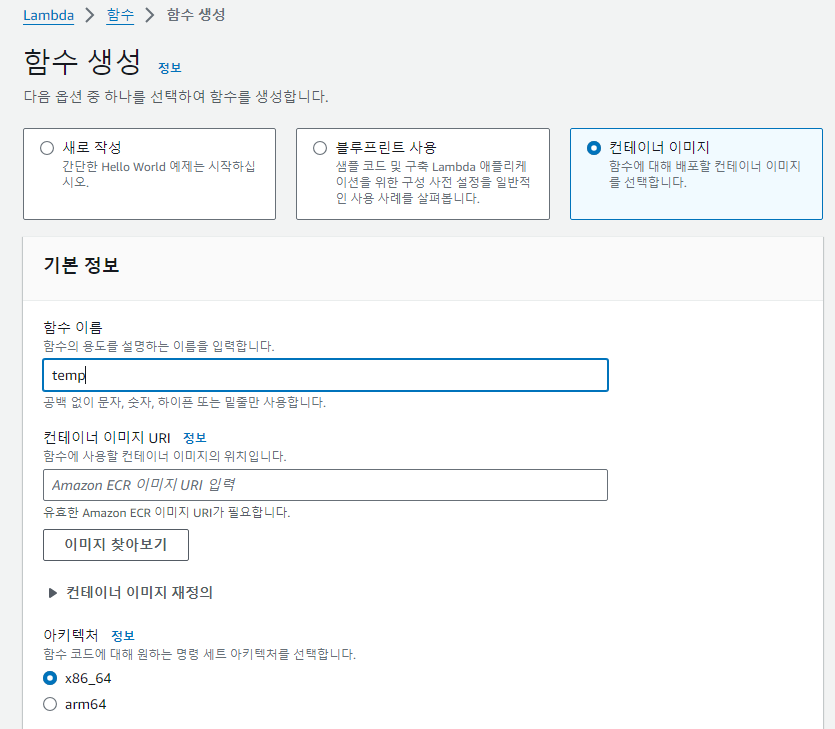
컨테이너 이미지로 변경하고
컨테이너 이미지 URI에서 방금 업로드 한 이미지를 업로드 하고 함수를 생성하면 끝이 난다.
람다 초기 설정 용량은 너무 적게 설정 되어 있기 때문에
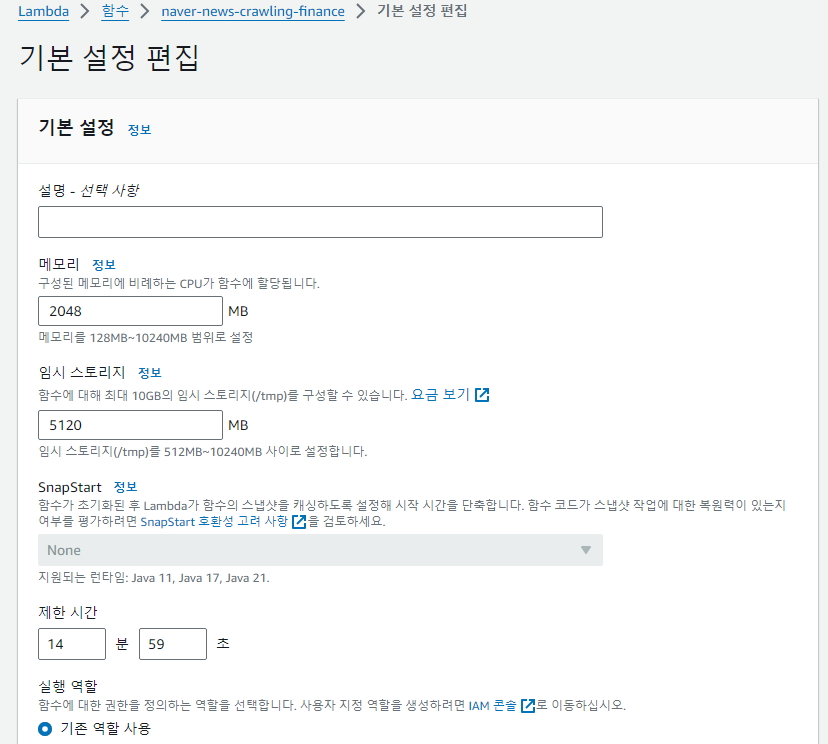
기본 설정 편집에 들어가 설정을 직접 바꿔줘야 한다
람다 함수의 제한시간은 최대 15분이다.
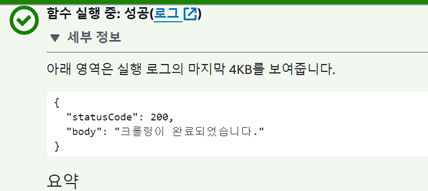
회고
이거 하느라 약 3일 정도 걸린 거 같다. 이유는 초기 설정과, 배포 과정에서 시행착오 때문이다.
처음에 AWS Lambda에 코드를 직접 업로드하는 방법을 시도했는데, 할 수 있을 거란 생각에 여러 번 시도했지만, lambda의 제약사항을 고려하지 못하고 계속 시도하면서 오래 걸렸다.
또한, service 객체를 사용해야 한다는 점을 늦게 알아 오래 걸렸다.
마지막으로 로컬 환경에서 코드가 잘 실행되었기 때문에, AWS lambda에서도 문제없을 거라 생각해 코드를 한 번에 업로드 한 점이다.
AWS lambda에 하나씩 기능을 올리고 테스트하면서 했어야 했는데..
결국 이 방식을 사용하면서 문제를 금방 해결할 수 있었다.
다음 글은 해당 코드로 크롤링 한 데이터를 AWS S3에 저장하는 것이다.
