
Pyspark
SparkContext
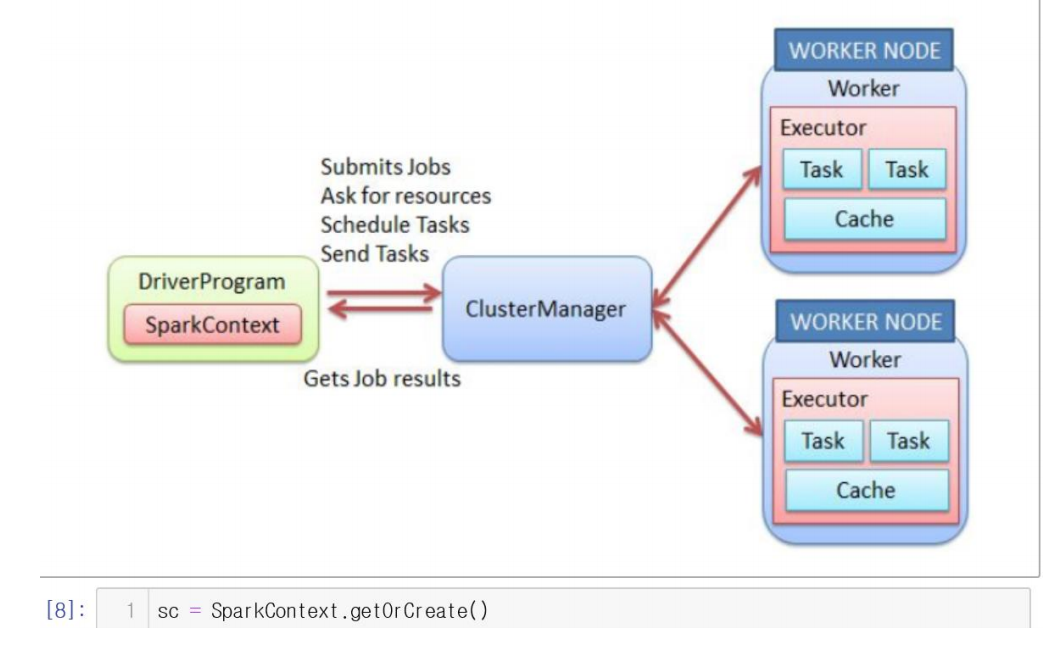
- pyspark를 사용하기 위해서는 SparkContext를 만들어야한다.
- SparkContext를 이용해서 ClusterManager를 통해 Job을 WorkerNode에게 부여한다.
sc = SparkContext.getOrCreate()Creating RDD
RDD를 만드는 방법
1. list, tuple(iterable data)등을 pharallelize 하는 방법
2. 텍스트 파일로 부터 읽어오는 방법
data = sc.parallelize(
[('Amber', 22), ('Alfred', 23), ('Skye', 4), ('Albert', 12), ('Amber', 9)])
print(data)
print(data.collect())ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
[('Amber', 22), ('Alfred', 23), ('Skye', 4), ('Albert', 12), ('Amber', 9)]import numpy as np
rData = [np.random.randn() for _ in range(10)]
print(rData)[1.0928815090185569, 0.6958856344122454, -0.7267994394056201, -1.2007356539509209, -1.505194696446304, 0.9008010881848137, -0.12519191873493543, 1.8390067450370042, 0.13227065528973245, 1.3986604339359077]data = sc.parallelize(rData)
print("data\n", data)
print("all data\n", data.collect())
print("the first 5\n", data.take(5))data
ParallelCollectionRDD[1] at parallelize at PythonRDD.scala:195
all data
[1.0928815090185569, 0.6958856344122454, -0.7267994394056201, -1.2007356539509209, -1.505194696446304, 0.9008010881848137, -0.12519191873493543, 1.8390067450370042, 0.13227065528973245, 1.3986604339359077]
the first 5
[1.0928815090185569, 0.6958856344122454, -0.7267994394056201, -1.2007356539509209, -1.505194696446304]data = sc.parallelize([ ("park", 43), ("kim", 25)])
print(data.collect())[('park', 43), ('kim', 25)]Creating RDD from a file
data = sc.textFile("./4.pyspark/test1.txt")
data.take(10)['ROMEO AND JULIET',
'',
'',
'ACT I',
'',
'',
'',
'SCENE I\tVerona. A public place.',
'',
'']Map
- 각각의 RDD에 map 함수를 실행
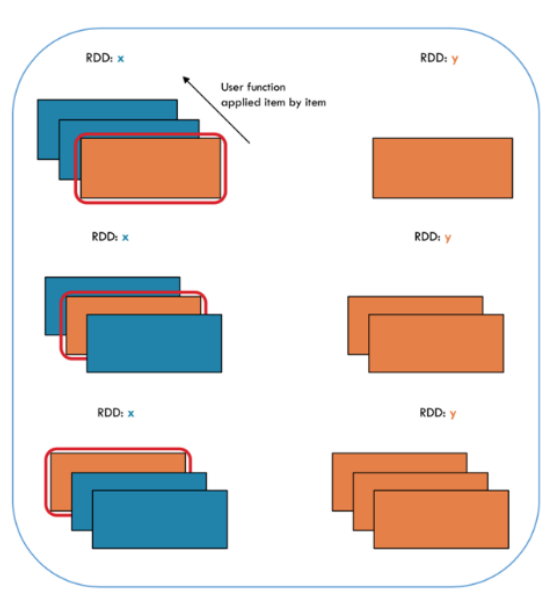
x = sc.parallelize(["b", "a", "c"])
print(x.collect())
print(x)['b', 'a', 'c']
ParallelCollectionRDD[8] at parallelize at PythonRDD.scala:195y = x.map(lambda z: (z,1))
print(y.collect())
print(y)[('b', 1), ('a', 1), ('c', 1)]
PythonRDD[9] at collect at <ipython-input-9-22e842763c77>:2Filter
- 각각의 RDD에 논리식을 적용시켜 그 값이 True인 결과물만 출력
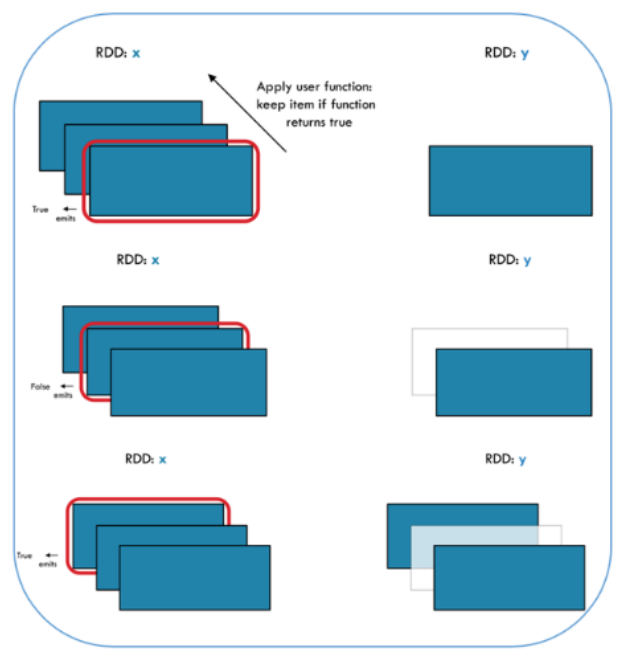
x = sc.parallelize([1,2,3])
y = x.filter(lambda x: x%2 == 1) # keep odd values
print(x.collect())
print(y.collect())[1, 2, 3]
[1, 3]FlatMap
- Map은 튜플을 만들어내는데, FlatMap은 튜플을 만들지않음
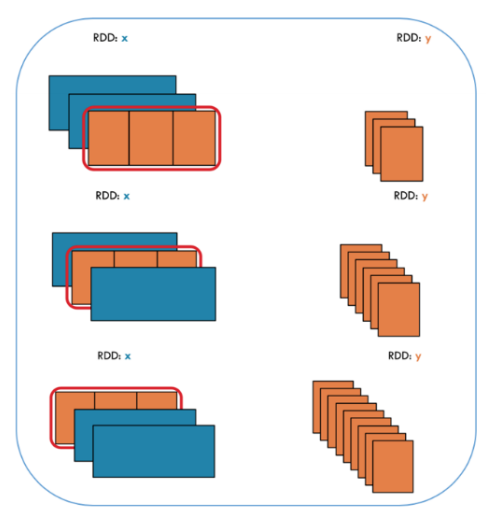
# FlatMap
x = sc.parallelize([1,2,3])
y = x.flatMap(lambda x: (x, x*100, 42))
print(x.collect())
print(y.collect())[1, 2, 3]
[1, 100, 42, 2, 200, 42, 3, 300, 42]# Map
x = sc.parallelize([1,2,3])
y = x.map(lambda x: (x, x*100, 42))
print(x.collect())
print(y.collect())[1, 2, 3]
[(1, 100, 42), (2, 200, 42), (3, 300, 42)]GroupBy
- key 값에 따라 그룹을 지어준다.
- 키 값을 정하는 코드를 줘야한다. ( 키 값이 이미 있는 경우는 제외 )
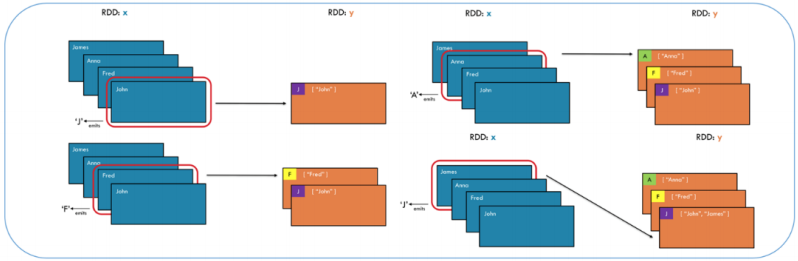
x = sc.parallelize(['Jogn','Fred','Anna', 'James'])
y = x.groupBy(lambda w: w[0]) # 시작문자에 따라 그룹을 짓는다.
print([(k, list(v)) for (k,v) in y.collect()])[('J', ['Jogn', 'James']), ('F', ['Fred']), ('A', ['Anna'])]groupbyKey
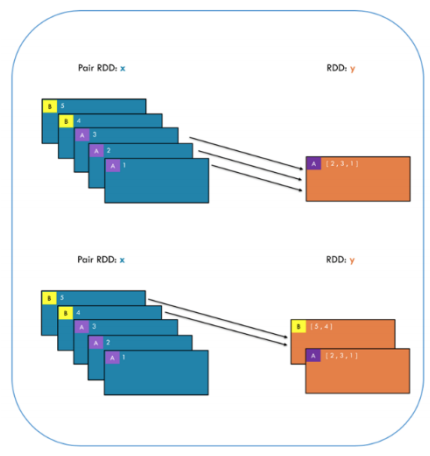
x = sc.parallelize([('B',5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)])
y = x.groupByKey()
print(x.collect())
print(list((k, list(v)) for (k,v) in y.collect()))[('B', 5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)]
[('B', [5, 4]), ('A', [3, 2, 1])]x = sc.parallelize([('B',5), ('B',4), ('A',3), ('A',2), ('A', 1)])
y = x.groupByKey()
print(x.collect())
print(list((j[0], list(j[1])) for j in y.collect()))[('B', 5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)]
[('B', [5, 4]), ('A', [3, 2, 1])]y.collect()[('B', <pyspark.resultiterable.ResultIterable at 0x7fde2cf10f60>),
('A', <pyspark.resultiterable.ResultIterable at 0x7fde2d2ce5f8>)]ReduceByKey vs groupByKey
- ReduceByKey가 GroupByKey보다 성능이 우수하다.
- ReduceByKey의 경우 셔플링을 하기전에 동일한 것들을 먼저 그룹핑을 실시한다. 따라서 셔플링 후에 작업이 줄어들어 성능이 좋아진다.
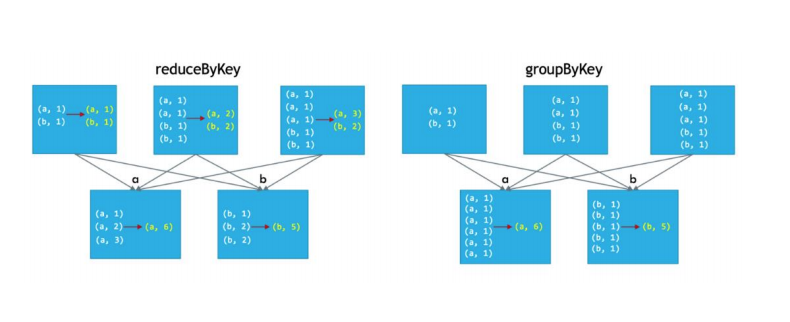
words = ["one", "two", "two", "three", "three", "three"]
wordPairsRDD = sc.parallelize(words).map(lambda x : (x,1))
wordPairsRDD.collect()[('one', 1), ('two', 1), ('two', 1), ('three', 1), ('three', 1), ('three', 1)]# ReduceByKey
wordsCountsWithReduce = wordPairsRDD.reduceByKey(lambda x,y : x+y).collect()
wordsCountsWithReduce[('two', 2), ('three', 3), ('one', 1)]# GroupByKey
wordCountsWithGroup = wordPairsRDD.groupByKey().map(lambda x : (x[0], sum(x[1]))).collect()
wordCountsWithGroup[('two', 2), ('three', 3), ('one', 1)]Partition and mapPartition
- 파티션을 볼 수 있는 명령어 : glom()
어떤식으로 분산이 되어있는지 확인할 수 있다.
data = sc.parallelize(np.arange(20))
print(data.glom().collect())
data1 = sc.parallelize(np.arange(20),5) # 두번째인자에 파티션 갯수를 지정할 수 있다.
print(data1.glom().collect())[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19]]
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15], [16, 17, 18, 19]]print(data.collect())
print(data1.collect())
# 여기서는 변함이 없음.[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]x = sc.parallelize(np.arange(10),2)
def f(iterator):
yield sum(iterator)
y = x.mapPartitions(f) # 파티션에 map펑션을 적용 시킬 수 있다.
# glom() flattens elements on the same partition
print(x.glom().collect())
print(y.glom().collect())[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
[[10], [35]]print(x.collect())
print(y.collect())[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[10, 35]- 파티션 운영을 잘하면 성능을 높일 수 있다.
- 같이 있으므로 데이터 셔플링을 줄일 수 있기 때문에
mapPartitionsWithIndex
- 인덱스를 포함하여 Map 펑션 적용
x = sc.parallelize(np.arange(10),2)
def f(partitionIndex, iterator):
yield (partitionIndex, sum(iterator))
y = x.mapPartitionsWithIndex(f)
# glom() flattens elements on the s ame partition
print(x.glom().collect())
print(y.glom().collect()) # index를 포함하여 출력할 수 있다.[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
[[(0, 10)], [(1, 35)]]
'당신을 한 줄로 소개해보세요'를 이 블로그로 대신 해볼까합니다.