빅데이터시스템_강의노트
1.[빅데이터 시스템] Numpy

mathematical operations 부족, speed가 늦음Numeric PythonAlternative to python list : numpy ArrayCalculations over entire arraysEasy and fastslice가 된 이후에는 인
2.[빅데이터시스템] Linear regression

Linear regression 여러 데이터를 분석해서 오차가 가장 적은 하나의 직선을 구하는 것. 빅데이터, 인공지능에서 중요한 수치로 사용 개념 설명 : 여러 직선을 그릴 수 있
3.[빅데이터시스템] pandas

데이터 분석을 위한 데이터 처리 라이브러리대용량 데이터를 처리하기 위한 함수, 메소드들이 제공 : index와 data로 이루어진 pandas의 데이터구조 : 각각의 인덱스가 series 로 이루어져 있는 pandas의 데이터구조
4.[빅데이터시스템] Pyspark

Pyspark SparkContext pyspark를 사용하기 위해서는 SparkContext를 만들어야한다. SparkContext를 이용해서 ClusterManager를 통해 Job을 WorkerNode에게 부여한다. Creating RDD RDD를 만드는
5.[빅데이터시스템] Word Count / Link Prediction

reduceByKey 를 이용하여 value 들의 합을 구한다.어느 단어가 가장 많이 나왔는지 궁금하면, sort 펑션을 통해 알수 있다.자기 자신을 링크하는 페이지가 많을수록 중요한 페이지라고 생각할 수 있음모든 페이지의 링크수를 계산하여 랭크를 매길 수 있다모든 페
6.[빅데이터시스템] Transformation & Lineage

Transformation Transformation 오퍼레이션을 통해 기존의 RDD에서 새로운 RDD를 만든다. 기존의 RDD에서의 디펜던시가 생기게 된다. spark 시스템에서는 디펜던시를 저장하고 있다가, fault 시 fault tolerance를 수행한다.
7.[빅데이터시스템] DataFrame

DataFrame : 큰 데이터들을 처리하기 위해 사용. 데이터들을 테이블형태로 표현해주고, SQL 문을 통해 데이터를 관리할 수 있다. 여러가지 방법으로 DataFrame을 만들 수 있다. 여기서는 RDD 를 이용해서 데이터프레임을 만드는 것을 설명 ro
8.[빅데이터시스템] DataFrame-2

Temporary Views 데이터프레임을 만든 후, sql를 사용할 수 있도록 만들어 주는 형식. spark session이 끝나고나면 없어진다. DataFrame[id: int, firstName: string, middleName: string,
9.[빅데이터시스템] DataLake
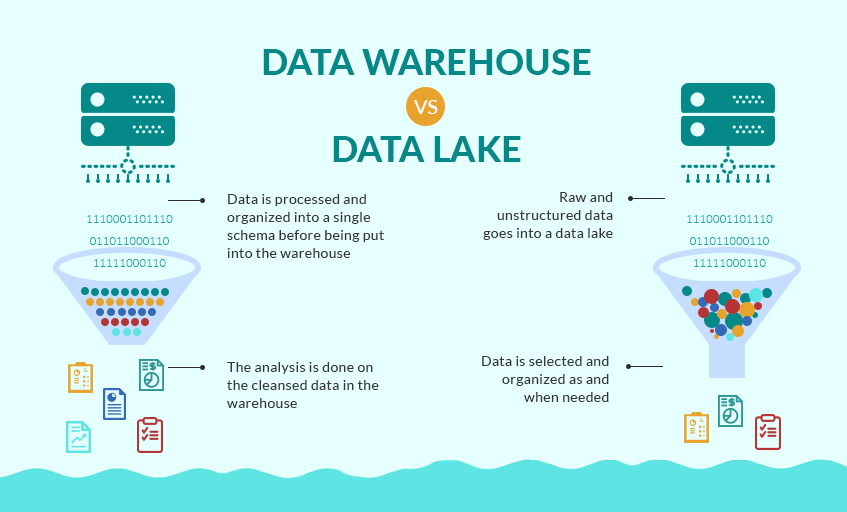
Data Warehouse, Data Lake 데이터를 저장하는 방식 크게 두가지 -> Data Warehouse , Data Lake Data Warehouse 데이터에 대한 스키마를 만들고 스키마에 따라 쿼리를 보내 데이터를 얻는 방식 데이터를 스키마로
10.[빅데이터시스템] SparkSQL

Caching cache없이 명령을 수행했을 때 3.63초가 소요되는 것을 확인할 수 있다. CACHE 키워드를 이용하면 테이블을 메모리에 cache할 수 있게 된다. 우측 자료를 보면 RDD 메모리에 8개의 파티션, 모든 조각들이 cache된 것을 확인할 수 있다