Nestjs - Covering Index
이번 포스팅에서는 기존 offset 방식의 페이지네이션의 단점을 보완하고자 커버링인덱스를 적용하면서 알게된 내용을 정리해 보았습니다.
Index
인덱스(Index)는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다.
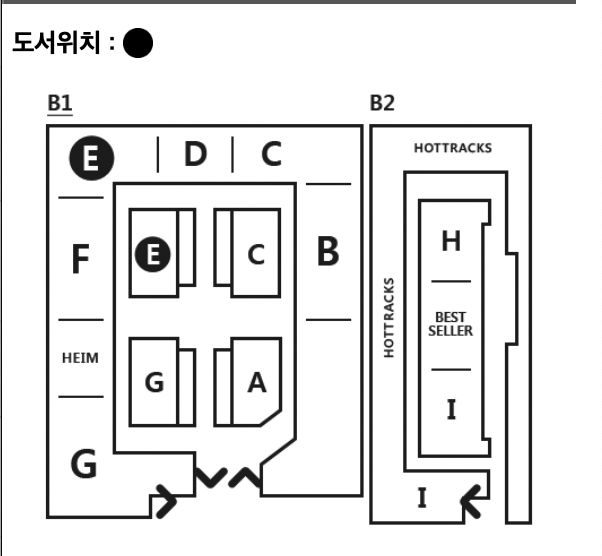 위 그림은 교보문고 강남점의 구조입니다. 위의 서점에서 본인이 원하는 특정 도서를 구입하기 위해 첫번째로 도서를 발견 할 때까지 A에서 H구역 까지 모든 도서를 확인 하는 방법이 있습니다.
위 그림은 교보문고 강남점의 구조입니다. 위의 서점에서 본인이 원하는 특정 도서를 구입하기 위해 첫번째로 도서를 발견 할 때까지 A에서 H구역 까지 모든 도서를 확인 하는 방법이 있습니다.
다른 방법으로는 도서 검색대 입니다. 도서를 검색하면 책이 있는 구역을 안내해줬던 경험이 있으실 것입니다. 특정 도서가 필요한 경우 대부분 검색대를 이용해서 도서의 위치를 찾습니다.
DB에서도 비슷한 방법으로 동작합니다. 책의 위치를 나열하는 대신 인덱스는 하나 이상의 열에 있는 값별로 테이블의 행 위치를 나열합니다. 예를 들어 고객 주문 테이블이 있는 경우 "주문 날짜" 열에 인덱스를 만들 수 있습니다. 이 인덱스는 각 주문의 위치를 주문 날짜별로 나열하므로 날짜별로 주문을 더 빠르게 검색할 수 있습니다.
따라서 도서관의 검색대로 책을 쉽게 찾을 수 있는 것처럼 데이터베이스의 Index로 데이터를 더 빠르게 검색할 수 있습니다. 계속해서 조금 더 깊게 알아보겠습니다.
Architecture
Clustered Index
Index는 크게 Clustered Index와 Non-clustered Index로 나누어진다고 볼 수 있습니다.
Clustered Index는 해당 키 값을 기반으로 테이블 행을 정렬하고 저장합니다. 데이터 행 자체는 한 가지 순서로만 정렬될 수 있으므로 테이블당 클러스터형 인덱스는 하나만 있을 수 있습니다.
PostgreSQL에서는 Cluster와 Clustered Index를 구분하여 사용하고 있습니다.
CLUSTER는PostgreSQL에index_name으로 지정된 인덱스를 기반으로table_name으로 지정된 테이블을 클러스터링하도록 지시합니다. 인덱스는 이미table_name에 정의되어 있어야 합니다.
PostgreSQL의 클러스터링은 인덱스에 의해 정의된 순서에 따라 테이블의 행을 정렬하는 것입니다. 반면 일부 데이터베이스의 Clustered Index는 모든 열을 "인덱스에 저장한다"는 개념입니다.
"인덱스에 데이터를 저장한다"는 것은 인덱스가 기본 테이블의 데이터 위치에 대한 참조뿐만 아니라 인덱싱되는 데이터의 전체 복사본을 포함하고 있음을 의미합니다.
인덱싱되는 데이터의 전체 복사본이 포함하고 있다를 명확하게 하면 인덱스에 기본 테이블의 해당 행 위치에 대한 참조와 함께 인덱싱된 열의 복사본이 포함되어 있음을 의미합니다.
예를 들어 room_id, title, description 열이 있는 room 테이블이 있다면 title 열에 인덱스를 만들면 인덱스에는 room 테이블의 해당 행에 대한 참조와 함께 room 테이블의 모든 행에 대한 title 열 값의 복사본을 포함합니다.
title 열에 검색 조건이 포함된 쿼리가 실행되면 데이터베이스 엔진은 인덱스를 사용하여 전체 room 테이블을 스캔하지 않고도 검색 조건과 일치하는 행을 빠르게 찾을 수 있습니다.
Non-clustered Index
Non-clustered Index는 Clustered Index와 달리 데이터의 물리적 순서를 정하지 않습니다.
Non-clustered Index를 사용하면 테이블의 데이터 행의 물리적인 위치에 대한 포인터와 인덱스 키를 저장하는 데이터 구조를 포함합니다.
인덱싱된 열에 대해 쿼리가 실행되면 데이터베이스 엔진은 클러스터 되지 않은 인덱스를 사용하여 쿼리 조건과 일치하는 행을 찾은 다음 인덱스에 저장된 포인터를 기반으로 테이블에서 해당 데이터를 검색합니다.
PostgreSQL은 다른 일반적인 데이터베이스 시스템에서처럼 사용되지 않습니다. Clustered Index의 개념이 없고 모든 테이블은 Heap Table이고 모든 인덱스는 Non-clustered Index입니다.
Type
Bitmap index
비트맵 인덱스를 사용하면 인덱싱된 열의 각 값은 열에 대한 해당 값이 있는 테이블의 행 집합을 나타내는 데 사용되는 비트맵과 연결됩니다. 비트맵의 각 비트는 테이블의 행에 해당하며 1은 행에 열에 대한 인덱싱된 값이 있음을 나타내고 0은 그렇지 않음을 나타냅니다.
인덱싱된 열에 대해 쿼리가 실행될 때 쿼리 조건과 일치하는 테이블의 행 집합을 신속하게 식별하기 위해 비트맵 인덱스가 사용됩니다. AND, OR 또는 XOR과 같은 논리 연산을 사용하여 여러 비트맵을 결합하여 일치하는 행을 효율적으로 식별할 수 있으므로 동일한 열에 여러 조건이 관련된 쿼리에 특히 효율적일 수 있습니다.
요약하면 PostgreSQL의 비트맵 인덱스는 열에 대해 주어진 값을 갖는 테이블의 행 집합을 나타내기 위해 비트맵을 사용하는 일종의 인덱스입니다. 비트맵 인덱스는 특정 유형의 쿼리에 효율적일 수 있지만 데이터 및 쿼리 워크로드의 특정 특성에 따라 다른 유형에 대해서는 덜 효율적일 수 있습니다.
Covering index
PostgreSQL는Index-Only Scan기능을 통해 커버링 인덱스를 처리합니다. 요구 사항은 대부분의RDBMS와 유사합니다. 인덱스 유형이 중요하고(현재btree또는gist인덱스에서만 지원됨) 인덱스는 쿼리에서 요청한 열을 완전히 포함해야 합니다.
setup
async paginationCoveringIndex(offset?: number, limit?: number):Promise<[RoomEntity[], number]> {
const coveringIndexQueryBuilder = this.roomRepository
.createQueryBuilder('cover')
.select(`cover.id`)
.orderBy('cover.id')
.offset(offset)
.limit(limit)
const count = await coveringIndexQueryBuilder.getCount();
const rooms = await this.roomRepository
.createQueryBuilder('rooms')
.innerJoin(`(${coveringIndexQueryBuilder.getQuery()})`, 'cover','rooms.id = cover_id')
.innerJoinAndSelect('rooms.user', 'user')
.select(['rooms', 'user'] )
.getMany();
return [rooms, count];
}저의 경우에는 id 열만 가진 cover라는 테이블을 만들고 room 테이블의 데이터 수에 맞춰 백만개의 데이터를 생성해주었습니다.
SELECT "cover"."id" AS "cover_id" FROM "rooms" "cover" ORDER BY "cover"."id" ASC LIMIT 10 OFFSET 900000LIMIT 10 OFFSET 900000 을 설정해 탐색한 coveringIndexQueryBuilder의 쿼리를 추출 했습니다.

Index-Only Scan을 사용하여 검색한 모습입니다. PostgreSQL의 scan방식을 알아보시려면 이전 포스팅을 방문해 주세요
이렇게 생성한 Sub Query를 Main Query와 innerjoin을 해줍니다.
innerJoin의 첫 번째 인수는 조인할 Sub Query 문자열입니다. 두 번째 인수는 하위 쿼리에 사용할 별칭을 나타내는 문자열인 cover입니다. 세 번째는 조인 조건을 나타내는 문자열입니다. 이 경우 'rooms.id = cover_id'인데, 이는 rooms 테이블의 id와 Sub Query의 cover_id 에 대해 조인을 수행해야 함을 의미합니다.
그다음 innerJoinAndSelect를 사용하여 RoomEntity의 user 속성을 Main query에 조인하고 결과의 각 RoomEntity 객체에 대해 연결된 UserEntity 객체를 로드합니다.
SELECT "rooms"."id" AS "rooms_id", "rooms"."title" AS "rooms_title", "rooms"."description" AS "rooms_description", "rooms"."roomCode" AS "rooms_roomCode", "rooms"."created_at" AS "rooms_created_at", "rooms"."updated_at" AS "rooms_updated_at", "rooms"."user_id" AS "rooms_user_id", "user"."id" AS "user_id", "user"."username" AS "user_username", "user"."password" AS "user_password", "user"."kakao_id" AS "user_kakao_id", "user"."email" AS "user_email", "user"."name" AS "user_name", "user"."gender" AS "user_gender", "user"."phone" AS "user_phone", "user"."birth" AS "user_birth", "user"."profile_image" AS "user_profile_image", "user"."created_at" AS "user_created_at", "user"."updated_at" AS "user_updated_at" FROM "rooms" "rooms" INNER JOIN (SELECT "cover"."id" AS "cover_id" FROM "rooms" "cover" ORDER BY "cover"."id" ASC LIMIT 10 OFFSET 900000) "cover" ON "rooms"."id" = cover_id INNER JOIN "user" "user" ON "user"."id"="rooms"."user_id"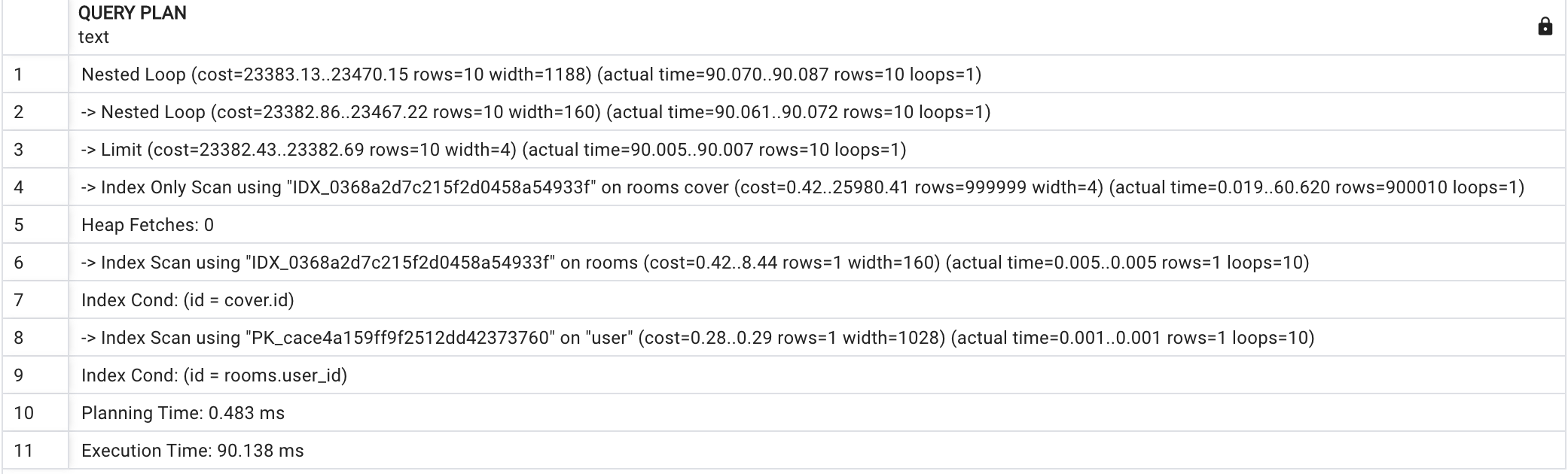
async getAllRoom(offset?: number, limit?: number) {
const [items, count] = await this.roomRepository.findAndCount({
skip: offset,
take: limit,
});
return { items, count };
}
위는 Typeorm의 레포지토리를 이용해 만든 기존의 방법입니다.
 같은 결과를 보여주지만 쿼리 수와 실행 시간이 차이 나는 것을 확인할 수 있습니다.
같은 결과를 보여주지만 쿼리 수와 실행 시간이 차이 나는 것을 확인할 수 있습니다.
Test
Offset이 9000, 90000, 900000인 상황을 가정하고 소요 시간을 측정해 보겠습니다. 20명의 사용자로 100번의 동시요청을 ApacheBench를 이용해 진행했습니다.
| offset | findAndCount | covering index |
|---|---|---|
| 9000 | 10.805 seconds | 1.576 seconds |
| 90000 | 11.405 seconds | 1.656 seconds |
| 900000 | 15.195 seconds | 2.065 seconds |
Conclusion
커버링 인덱스를 적용하기 위해 인덱스의 개념, 구조, 타입을 알아보았고 기존 페이지네이션 방식과의 성능 비교를 통해 효율성을 확인할 수 있었습니다. 커버링 인덱스를 사용하는 것은 유용한 최적화 기술이 될 수 있습니다.
그러나 커버링 인덱스의 효율성은 특정 데이터베이스의 특정 쿼리 패턴 및 데이터 분포에 따라 달라진다는 점은 주의해 두어야 합니다. 경우에 따라 더 큰 인덱스 구조를 유지 관리하는 오버헤드로 인해 기존 인덱스보다 느릴 수 있습니다.
참고
Database index - wikipedia
Cluster - Docs.postgresql
Overview of Clusters - oracle
커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
Cluster and Non cluster index in PostgreSQL - stackoverflow
BoardsQueryRepository - godtaehee Github
POSTGRES COVERING INDEXES AND THE VISIBILITY MAP
