이번 포스팅에서는 커버링인덱스를 공부하던 중 인덱스를 이용한 테이블 조회 중 Index Scan이 아닌 Sequential Scan을 사용해 이유를 알아보고자 PostgreSQL의 테이블 스캔 방식에 대해서 정리 해보았습니다.
Query Plan
PostgreSQL에서 Query Plan은 데이터베이스 관리 시스템이 쿼리를 실행하고 데이터베이스에서 데이터를 검색하는 데 수행되는 단계에 대한 설명을 위해 사용합니다.
쿼리가 PostgreSQL 데이터베이스에 제출되면 Planner는 쿼리를 분석하고 쿼리를 실행하는 데 필요한 작업 순서를 요약한 쿼리 계획을 생성합니다.
SQL문 EXPLAIN을 이용해 쿼리 플랜을 확인할 수 있습니다. ANALYZE을 붙여서 실행 시간 및 구체적인 실행 계획을 분석합니다.
5 methods of PostgreSQL
PostgreSQL에서 데이터를 검색하는데 사용하는 5가지 방법입니다.
Sequential Scan- 필요한 데이터를 검색하기 위해 순서대로 테이블의 모든 행을 읽습니다.Index Scan- 인덱스를 사용하여 필요한 데이터를 빠르게 찾습니다.Index-Only Scan- 테이블에 액세스하지 않고 인덱스에서만 데이터를 검색합니다.Bitmap Index Scan- 여러 인덱스를 사용하여 필요한 데이터를 빠르게 찾습니다.TID Scan- 여기서 데이터베이스는 필요한 행의 튜플 ID(TID)를 사용하여 데이터를 검색합니다.
Setup
DO $$
DECLARE
i INTEGER := 1;
BEGIN
WHILE i < 1000000 LOOP
INSERT INTO "rooms"(title, user_id, description, created_at)
VALUES(CONCAT('title', i), CONCAT(i % 100 + 1)::INTEGER, CONCAT('description', i), now() + i * INTERVAL '1 second');
i := i + 1;
END LOOP;
END $$;검증을 위해 더미 데이터를 백만개를 생성해 주었습니다. 한 유저에 대해 10,000개 방을 생성했습니다.
Sequential Scan
Table Scan이라고도 하는 Sequential Scan(Seq Scan)은 데이터베이스가 테이블의 모든 행을 순서대로 읽어 필요한 데이터를 검색하는 테이블에서 데이터를 읽는 방법입니다. 보통 FullScan방식이라고 불립니다.
EXPLAIN ANALYZE SELECT * FROM rooms WHERE title = 'title10000'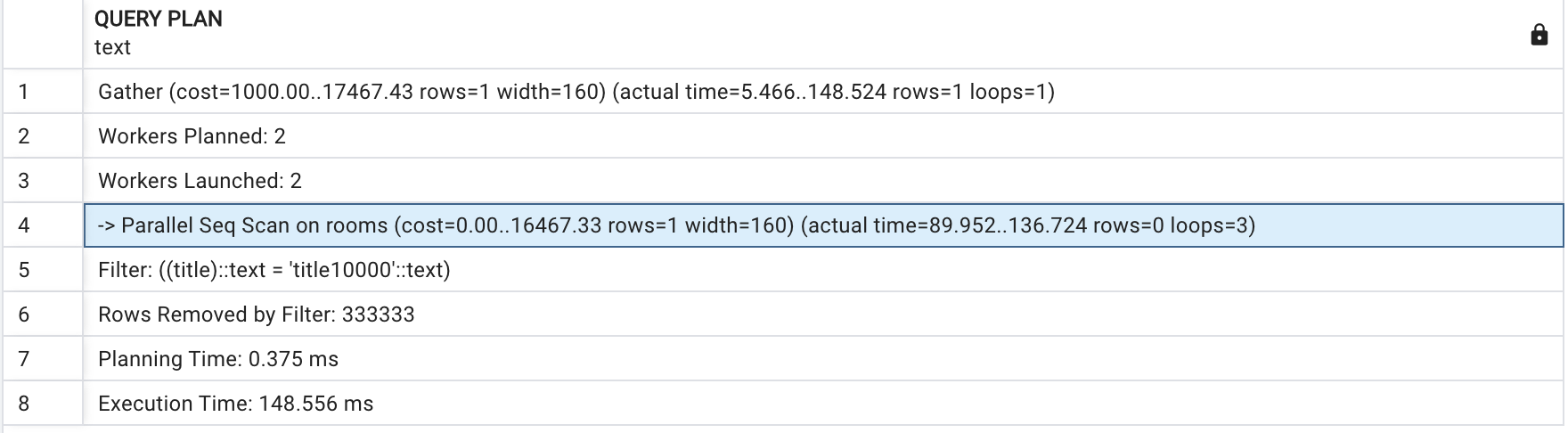
Gather: 여러 병렬 작업자의 결과를 단일 결과 집합으로 결합하는 데 사용되는 연산자입니다.
Parallel Seq Scan on rooms:PostgreSQL이 테이블에서 병렬Seq Scan을 수행하고 있음을 나타냅니다.
title은 인덱스가 없는 컬럼으로 Parallel Seq Scan을 사용한 것을 관찰할 수 있습니다. Parallel Seq Scan과 Seq Scan의 주요 차이점은 Parallel Seq Scan은 여러 CPU 코어를 사용하여 테이블을 병렬로 읽고 Seq Scan은 단일 CPU 코어를 사용하여 테이블을 순차적으로 읽습니다. 일반적인 경우 Seq Scan은 매우 느린데 데이터의 증가함에 비례해 느려집니다.
인덱스가 없는 경우 뿐만 아니라 인덱스가 있지만 존재하는 모든 행을 검색하는 경우가 있습니다. 글을 진행하며 이 부분에 대해서도 알아 볼 것 입니다.
Index Scan
Index Scan은 데이터베이스가 인덱스를 사용하여 필요한 데이터를 빠르게 찾는 방법입니다. 이 방법은 테이블이 크고 데이터의 크기가 작은 경우의 검색에 효율적일 수 있습니다. 그러나 인덱스를 사용하려면 쿼리에 적절한 인덱스가 존재하고 쿼리가 인덱스를 효율적으로 사용할 수 있어야 합니다.
EXPLAIN ANALYZE SELECT * FROM rooms WHERE id = 10000
Index scan: 인덱스를 사용하여 테이블의 데이터를 스캔하고 있음을 나타냅니다.
using "IDX_0368a2d7...: 테이블을 스캔하는 데 사용되는 인덱스의 이름입니다.
일반적으로 인덱스를 사용하는 것이 특히 큰 테이블의 경우 순차 스캔을 수행하는 것보다 빠릅니다. 그러나 인덱스를 만들고 유지 관리하려면 추가 리소스가 필요하며 테이블에 대한 INSERT, UPDATE 및 DELETE을 수행할때마다 인덱스도 업데이트 되어 변경 사항을 반영해야 하기 때문에 성능에 영향을 미칠 수 있습니다.
EXPLAIN ANALYZE SELECT id FROM rooms WHERE id > 10000;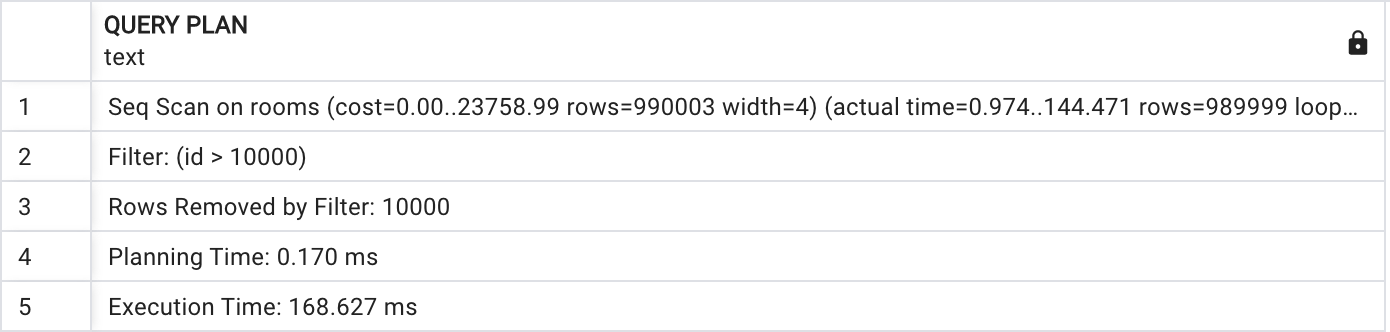
PostgreSQL은 primary key에 대해 인덱스를 자동으로 생성합니다. 위의 경우 인덱스가 존재하는 행을 이용해서 조회를 했지만 Seq Scan을 사용한 모습입니다. Seq Scans 또는 Index Scan이 사용되는지 여부를 결정하기 위해 PostgreSQL은 쿼리를 분석하고 테이블의 크기와 쿼리의 선택도(Selectivity)를 평가합니다. 적절한 인덱스를 사용할 수 있고 쿼리가 인덱스를 사용하기에 충분히 선택적인 경우 Index Scan이 사용됩니다. 그렇지 않으면 Seq Scans이 사용됩니다.
Index-Only Scan
Index-Only Scan은 인덱스만 스캔하고 테이블 데이터를 건드리지 않는다는 점을 제외하면 인덱스 스캔과 매우 유사합니다. 이는 쿼리의 SELECT 및 WHERE 절 모두에 인덱싱된 열이 포함된 경우에만 가능합니다.
EXPLAIN ANALYZE SELECT id FROM rooms WHERE id = 10000;
PostgreSQL은 테이블이 잘 정리되지 않은 경우 Index-Only Scan 대신 Index Scan을 수행을 선택할 수 있습니다. 예를들면 테이블 및 인덱스에서 일부 대규모 DELETE/INSERT가 업데이트 되지 않은 경우입니다. Index-Only Scan은 인덱스가 실제로 shared_buffers에 캐시되기 때문에 I/O 및 시간 측면에서 매우 빠를 수 있습니다.
Bitmap Heap Scan & Bitmap Index Scan
Bitmap Index Scan은 인덱스를 스캔하여 비트맵을 생성하고 Bitmap Heap Scan은 비트맵을 사용하여 테이블을 스캔합니다. 두 기술을 함께 사용하여 인덱스를 이용한 테이블에서 데이터를 효율적으로 검색할 수 있습니다.
CREATE INDEX user_id_idx on rooms USING BTREE(user_id)user_id에 대해 BTREE Index를 생성해 주었습니다.
EXPLAIN ANALYZE SELECT * FROM rooms WHERE rooms.user_id = 50
Bitmap And & Or
bitmap은 단일 매치 뿐만 아니라 복합 인덱스 결합에도 이점을 가지고 있습니다.
EXPLAIN ANALYZE SELECT * FROM rooms WHERE rooms.id > 100000 and rooms.user_id = 50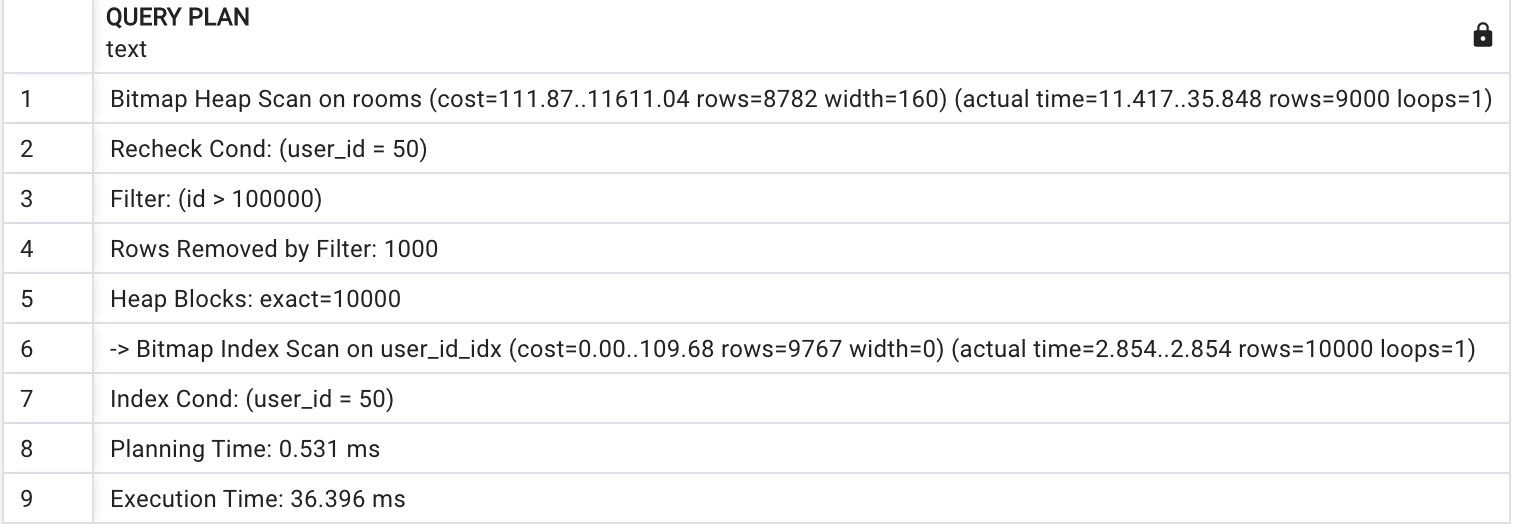
EXPLAIN ANALYZE SELECT * FROM rooms WHERE rooms.id = 100000 or rooms.user_id = 50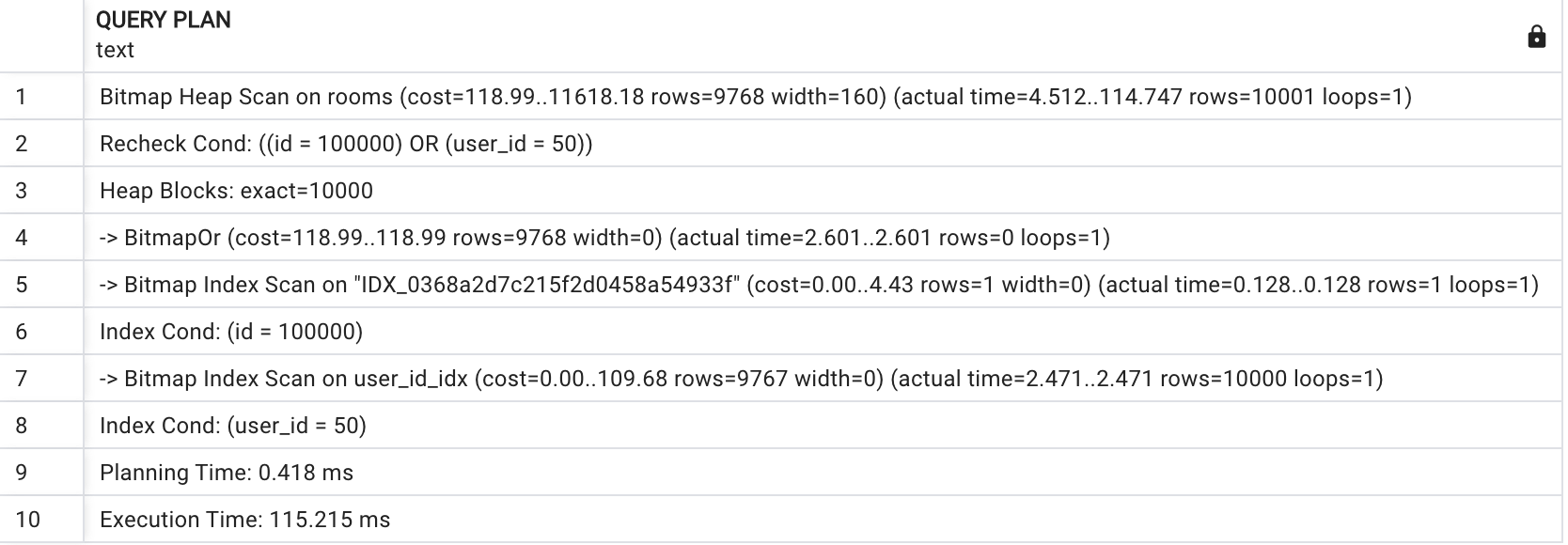
EXPLAIN ANALYZE SELECT * FROM rooms WHERE rooms.id < 100000 and rooms.user_id = 50 조건의 범위를 줄이자
조건의 범위를 줄이자 Index Scan을 이용하는 모습입니다.
Conclusion
여러 상황에서 특정 유형의 스캔을 이용하는지 알아 보았습니다. 핵심사항은 데이터베이스 쿼리를 최적화하려면 데이터 크기, 쿼리의 복잡성 및 사용 가능한 시스템 리소스와 같은 다양한 요소를 신중하게 고려해야 한다는 것입니다. 최상의 성능을 얻으려면 올바른 검색 방법을 선택하고 적절한 인덱스를 생성하고 워크로드 및 사용 패턴을 기반으로 데이터베이스 구성을 조정하는 것을 고려해야 합니다.
참고
Analyzing Scans in PostgreSQL
[PG] 쿼리 실행 계획 분석하기 - Table Scan
64.3. Index Scanning
15.1. How Parallel Query Works
