NLP
언어학 지식에 상관없이 텍스트를 이해하는 통계적인 방법을 사용해 실전 문제를 해결하는 일련의 기술
텍스트 "이해"
주로 텍스트를 계산 가능한 표현으로 변환함으로써 이루어짐
표현은 벡터, 텐서, 그래프, 트리 등과 같이 이산적이거나 연속적으로 조합한 구조
딥러닝
계산 그래프와 수치 최적화 기술을 사용해 데이터에서 표현을 효과적으로 학습하는 기술
파이토치
딥러닝 알고리즘을 구현하는 파이썬 기반의 계산 그래프 프레임워크
지도학습
레이블된 훈련 샘플로 학습함
머신러닝에서 지도 또는 지도 학습은 샘플에 대응하는 타깃의 정답을 제공하는 방식
ex) 문서 분류 작업에서 샘플: 문서, 타깃: 범주형 레이블
ex) 기계 번역에서 샘플: 한 언어의 문장, 타깃: 다른 언어의 문장
입력 데이터에 대한 이해를 바탕으로 지도 학습 시스템을 다음과 같이 그릴 수 있다.
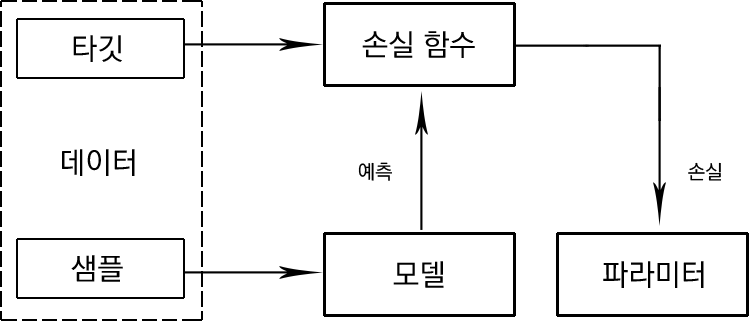
샘플
예측에 사용하는 아이템으로, x로 표시한다. 입력이라고 부르기도 한다.
타깃
샘플에 상응하는 레이블(label)로, 일반적으로 예측되는 대상이다. 머신러닝/딥러닝의 표준적인 표기법에 따라 y로 표시한다. 정답이라고 부르기도 한다.
모델
수학식이나 샘플 x를 받아 타깃 레이블 값을 예측하는 함수이다.
파라미터
가중치라고도 불리며, 모델을 규정한다. 기본적으로 가중치를 의미하는 w로 표기한다.
예측
모델이 추측하는 타깃 값으로, 추정이라고도 부른다. '햇' 표기를 사용해 나타낸다. 예를 들어 타깃 y의 예측은 y 위에 ^를 씌운 형태로 표현한다.
손실 함수
훈련 데이터에 대한 예측이 타깃과 얼마나 멀리 떨어져 있는지 비교하는 함수이다. 타깃과 예측이 주어지면 손실 함수는 손실이라고 부르는 실수 스칼라 값을 계산한다. 손실이 낮을수록 예측을 더 잘하는 모델이다. L로 표기한다.
경사 하강법
지도 학습의 목적은 주어진 데이터셋에서 손실 함수를 최소화하는 파라미터 값을 찾는 것이다. 즉, 방정식에서 근을 찾는 것과 같다.
경사 하강법은 근을 찾는 일반적인 방법으로, 전통적인 경사 하강법의 경우 파라미터의 초기값을 추측한 다음, 손실 함수의 값이 수용할 만한 수렴 조건 아래로 내려갈 때까지 파라미터를 반복해서 업데이트한다.
데이터셋의 크기가 클 경우 메모리 제약에 의해 전통적인 경사 하강법을 적용하는 것은 어렵고, 비용이 많이 들며, 시간도 오래 걸린다.
확률적 경사 하강법은 경사 하강법의 근사 버전이다. 데이터 포인트를 하나 또는 일부를 랜덤하게 선택하고, 그레이디언트를 계산한다. 데이터 포인트를 하나만 사용하는 것을 순수 SGD, 여러 개 사용하는 것을 미니배치 SGD라고 한다.
순수 SGD의 경우 업데이트에 잡음이 많아 수렴이 매우 느리므로, 실전에서는 사용하지 않는 편이다. 일반적인 SGD 알고리즘의 수렴 속도를 높이는 여러 가지 파생 알고리즘이 생겼다.
원-핫 표현
0 벡터에서 시작해 문장이나 문서에 등장하는 단어에 상응하는 원소를 1로 설정한다.
문장을 token으로 나누고 구두점을 무시한 다음, 모두 소문자로 바꾸면 어휘 사전의 크기가 정해진다. 크기가 n이라면, 각 단어를 n차원 원-핫 벡터로 표현할 수 있다.
구, 문장, 문서의 원-핫 벡터는 이를 구성하는 단어의 원-핫 표현을 단순하게 논리합한 것이다.
TF (문서 빈도)
구, 문장, 문서의 TF 표현은 단순히 소속 단어의 원-핫 표현을 합해 만든다.
TF 표현에서 각 원소는 해당 단어가 문장(말뭉치)에 등장하는 횟수이다.
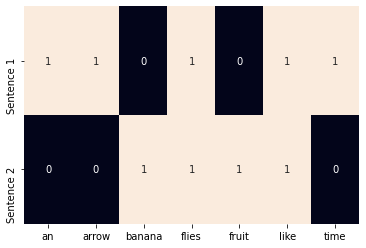
다음 코드는 사이킷 런을 사용하여 원-핫 벡터 또는 이진 표현을 만드는 예제다.
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
corpus = ['Time flies like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
vocab = one_hot_vectorizer.get_feature_names()
sns.heatmap(one_hot, annot = True,
cbar = False, xticklabels=vocab,
yticlabels=['Sentence 1', 'Sentence 2'])실행 결과는 다음과 같다.
TF-IDF
TF의 경우 등장 횟수에 비례하여 단어에 가중치를 부여한다. 하지만 흔한 단어는 특정 문서의 관련한 정보를 담고 있는 경우가 많지 않다. 오히려 희귀한 단어가 그 문서의 특징을 더 잘 나타낼 때가 많다. 이럴 경우에 사용하는 것이 역문서 빈도 즉, TF-IDF이다.
IDF는 벡터 표현에서 흔한 토큰의 점수를 낮추고, 드문 토큰의 점수를 높인다.
토큰 w의 IDF(w)는 말뭉치 하나를 다음과 같이 정의한다.
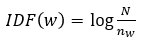
TF-IDF 점수는 TF와 IDF를 곱한, TF(w) * IDF(w)이다.
즉, 매우 흔한 단어는 IDF(w)가 0이므로 TF-IDF 점수 역시 0이 된다. 따라서 이 단어는 제외된다. 반면에 아주 드물게 등장하는 단어는 IDF가 최댓값인 log N이 된다.
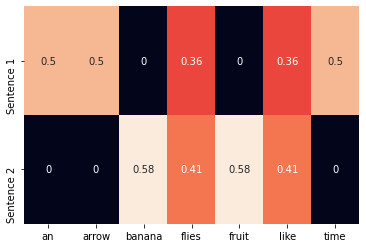
다음 코드는 사이킷 런을 사용해 TF-IDF 표현을 만드는 것이다.
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab,
yticklabels=['Sentence 1', 'Sentence 2'])실행 결과는 다음과 같다.
딥러닝의 주 목적은 표현 학습이므로, TF-IDF와 같은 경험적인 방법으로 입력을 인코딩하지 않는다. 주로 정수 인덱스를 사용한 원-핫 인코딩과 특수한 '임베딩 룩업' 층으로 신경망의 입력을 구성한다.
